-
galeracluster高可用集群异常恢复
以三个节点为例
- 如果其中一个或两个节点被手动停止,需要恢复时,在对应节点直接启动mysql即可(实际测试中,节点异常宕机重启同样适用)
systemctl start mysqld- 1
- 如果三个节点都被手动停止,需要恢复时,先查看grastate.dat文件,比较文件中的seqno编号,使用最高级的节点作为引导节点,一般为最后一个停止的节点。否则可能丢失数据。
# 在配置的datadir目录下 cat /var/lib/mysql/grastate.dat- 1
- 2
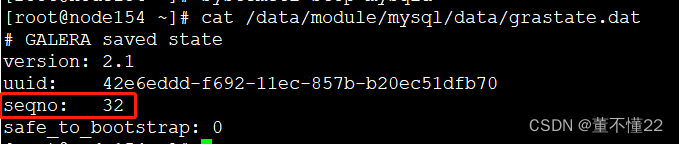
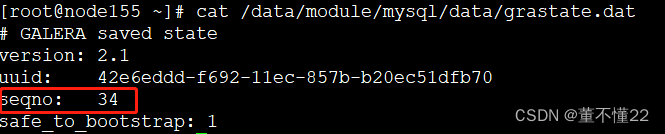

三个节点seqno 分别为32、34、33.所以需要选择seqno为34的node155节点作为引导节点。
在node155节点 执行mysqld_bootstrap --wsrep-new-cluster- 1
node155启动成功后,在其他节点启动Mysql
systemctl start mysqld- 1
- 集群三节点同时宕机异常,需要恢复时
先查看grastate.data文件
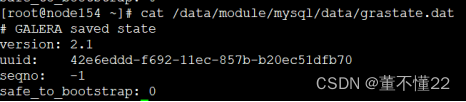


异常宕机导致所以节点seqno都为-1,无法选择哪一台为最佳引导节点
再查看记录,三台节点都执行
mysqld --wsrep-recover



所以node156为28,是最大的,是最佳引导节点
从node156启动集群。
如果safe_to_bootstrap = 0
先将safe_to_bootstrap: 0 改为safe_to_bootstrap: 1
Node156 执行命令 mysqld_bootstrap --wsrep-new-cluster
登录node156 mysql,发现无法正常使用
此时查看集群状态,处于无主状态
SHOW STATUS LIKE ‘%wsrep_cluster%’;
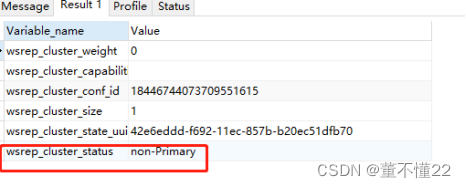
设置主组件
SET GLOBAL wsrep_provider_options=‘pc.bootstrap=YES’;
此时node156恢复正常
其他两个节点正常启动mysql即可
systemctl start mysqld -
相关阅读:
Mysql知识进阶
[ACNOI2022]物品
MATLAB嵌套循环
Hyaluronic acid-siRNA透明质酸修饰核糖核酸|peptide–siRNA 多肽偶连RNA/DNA核酸(齐岳PNA修饰物)
Docker+K8s基础(重要知识点总结)
Python按照拼音顺序给数组排序
【无标题】
【机器学习】基于卷积LSTM的视频预测
每个人都可以用的开源微信机器人
一、安装GoLang环境和开发工具
- 原文地址:https://blog.csdn.net/github_39319229/article/details/125505061