-
深度学习——BRNN和DRNN
双向循环神经网络(Bidirectional RNN)
双向 RNN 模型可以让你在序列的某点处不仅可以获取之前的信息,还可以获取未来的信息
why we need BRNN?
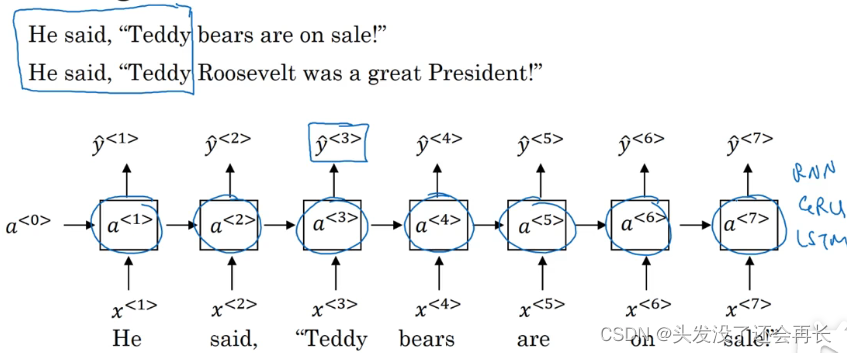
这个网络有一个问题,在判断第三个词 Teddy(上图编号 1 所示)是不是人名的一部分时,光看句子前面部分是不够的,为了判断𝑦^<3>(上图编号 2 所示)是 0 还是 1,除了前3 个单词,你还需要更多的信息,因为根据前 3 个单词无法判断他们说的是 Teddy 熊,还是前美国总统 Teddy Roosevelt,所以这是一个非双向的或者说只有前向的 RNN。我刚才所说的总是成立的,不管这些单元(上图编号 3 所示)是标准的 RNN 块,还是 GRU 单元或者是LSTM 单元,只要这些构件都是只有前向的。how can BRNN solve this problem?
输入只有 4 个,𝑥<1>到𝑥<4>。从这里开始的这个网络会有一个前向的循环单元叫做𝑎⃗⃗ <1>,𝑎⃗⃗ <2>,𝑎⃗⃗ <3>还有𝑎⃗⃗ <4>,我在这上面加个向右的箭头来表示前向的循环单元,这四个循环单元都有一个当前输入𝑥输入进去,得到预测的𝑦<1>,𝑦<2>,𝑦<3>和𝑦<4>。
这里有个𝑎⃖⃗⃗<1>,左箭头代表反向连接,𝑎⃖⃗⃗<2>反向连接,𝑎⃖⃗⃗<3>反向连接,𝑎⃖⃗⃗<4>反向连接,所以这里的左箭头代表反向连接。
给定一个输入序列𝑥<1>到𝑥<4>,这个序列首先计算前向的𝑎⃗⃗ <1>,然后计算前向的𝑎⃗⃗ <2>,接着𝑎⃗⃗ <3>,𝑎⃗⃗ <4>。而反向序列从计算𝑎⃖⃗⃗<4>开始,反向进行,计算反向的𝑎⃖⃗⃗<3>。你计算的是网络激活值,这不是反向而是前向的传播,而图中这个前向传播一部分计算是从左到右,一部分计算是从右到左。计算完了反向的𝑎⃖⃗⃗<3>,可以用这些激活值计算反向的𝑎⃖⃗⃗<2>,然后是反向的𝑎⃖⃗⃗<1>,把所有这些激活值都计算完了就可以计算预测结果了。
举个例子,为了预测结果,你的网络会有如𝑦^<𝑡>,𝑦^<𝑡> = 𝑔(𝑊𝑔[𝑎⃗⃗ <𝑡> , 𝑎⃖⃗⃗<𝑡>] + 𝑏𝑦)。比如你要观察时间 3 这里的预测结果,信息从𝑥<1>过来,流经这里,前向的𝑎⃗⃗ <1>到前向的𝑎⃗⃗ <2>,这些函数里都有表达,到前向的𝑎⃗⃗ <3>再到𝑦^<3>,所以从𝑥<1>,𝑥<2>,𝑥<3>来的信息都会考虑在内,而从𝑥<4>来的信息会流过反向的𝑎⃖⃗⃗<4>,到反向的𝑎⃖⃗⃗<3>再到𝑦^<3>,这样使得时间 3 的预测结果不仅输入了过去的信息,还有现在的信息,这一步涉及了前向和反向的传播信息以及未来的信息。这就是双向循环神经网络,并且这些基本单元不仅仅是标准 RNN 单元,也可以是 GRU单元或者 LSTM 单元。事实上,很多的 NLP 问题,对于大量有自然语言处理问题的文本,有LSTM 单元的双向 RNN 模型是用的最多的。所以如果有 NLP 问题,并且文本句子都是完整的,首先需要标定这些句子,一个有 LSTM 单元的双向 RNN 模型,有前向和反向过程是一个不错的首选
深层循环神经网络(Deep RNNs)
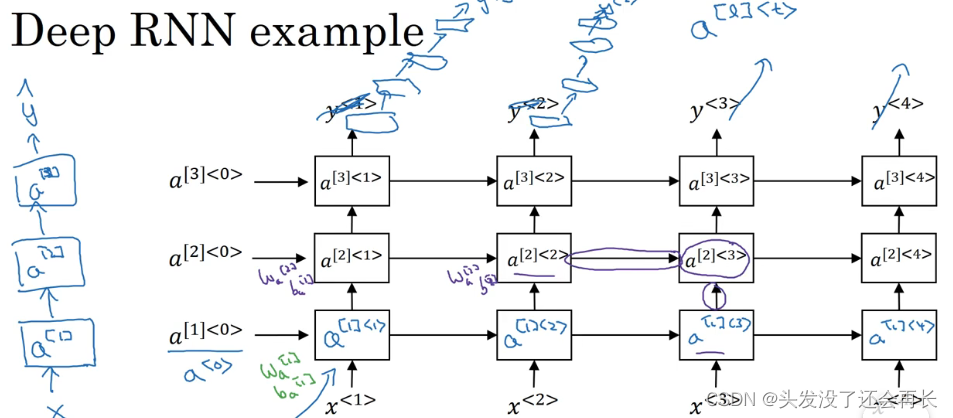
用𝑎[1]<0>来表示第一层,所以我们现在用𝑎[𝑙]<𝑡>来表示第 l 层的激活值,这个表示第𝑡个时间点,这样就可以表示。第一层第一个时间点的激活值𝑎[1]<1>,这(𝑎[1]<2>)就是第一层第二个时间点的激活值,𝑎[1]<3>和𝑎[1]<4>。然后我们把这些堆叠在上面,这就是一个有三个隐层的新的网络。
看看这个值𝑎[2]<3>是怎么算的。
激活值𝑎[2]<3>有两个输入,一个是从下面过来的输入,还有一个是从左边过来的输入,𝑎[2]<3> = 𝑔(𝑊𝑎[2][𝑎[2]<2>, 𝑎[1]<3>] + 𝑏𝑎[2]),这就是这个激活值的计算方法。参数𝑊𝑎[2]和𝑏𝑎[2]在这一层的计算里都一样,相对应地第一层也有自己的参数𝑊𝑎[1] 和𝑏𝑎[1]。 -
相关阅读:
Wireshark在多媒体开发中的使用
mysql 位操作
[C++] 小游戏 斗破苍穹 2.2.1至2.11.5全部版本(上) zty出品
Clion-MinGW编译后的exe文件添加ico图标
js介绍及内置功能函数、数据类型、变量
手把手教你maven的安装与配置(windows)
kafka配置sasl
10_那些格调很高的个性签名
加快网站收录 3小时百度收录新站方法
Java面试个人简历
- 原文地址:https://blog.csdn.net/m0_51474171/article/details/125502014