-
Kernel Modules Versus Applications
Before we go further, it's worth underlining the various differences between a kernel module and an application. 在我们进一步讨论之前,有必要强调内核模块和应用程序之间的各种差异。
While most small and medium-sized applications perform a single task from beginning to end, every kernel module just registers itself in order to serve future requests, and its initialization function terminates immediately. In other words, the task of the module's initialization function is to prepare for later invocation of the module's functions; it's as though the module were saying, "Here I am, and this is what I can do." The module's exit function (hello_exit in the example) gets invoked just before the module is unloaded. It should tell the kernel, "I'm not there anymore; don't ask me to do anything else." This kind of approach to programming is similar to event-driven programming, but while not all applications are event-driven, each and every kernel module is. Another major difference between event-driven applications and kernel code is in the exit function: whereas an application that terminates can be lazy in releasing resources or avoids clean up altogether, the exit function of a module must carefully undo everything the init function built up, or the pieces remain around until the system is rebooted. 虽然大多数中小型应用程序从头到尾执行单个任务,但每个内核模块只是注册自己以服务未来的请求,并且其初始化函数立即终止。换句话说,模块初始化函数的任务是为以后调用模块函数做准备;就好像模块在说,“我在这里,这就是我能做的。”模块的退出函数(示例中的 hello_exit)在模块卸载之前被调用。它应该告诉内核,“我不在那里了;不要让我做任何其他事情。”这种编程方法类似于事件驱动编程,但并非所有应用程序都是事件驱动的,但每个内核模块都是。事件驱动应用程序和内核代码之间的另一个主要区别在于退出函数:虽然终止的应用程序可以懒惰地释放资源或完全避免清理,但模块的退出函数必须小心地撤消 init 函数建立的所有内容,或者碎片仍然存在,直到系统重新启动。
Incidentally, the ability to unload a module is one of the features of modularization that you'll most appreciate, because it helps cut down development time; you can test successive versions of your new driver without going through the lengthy shutdown/reboot cycle each time. 顺便说一句,卸载模块的能力是您最欣赏的模块化特性之一,因为它有助于缩短开发时间; 您可以测试新驱动程序的连续版本,而无需每次都经历漫长的关机/重启周期。
As a programmer, you know that an application can call functions it doesn't define: the linking stage resolves external references using the appropriate library of functions. printf is one of those callable functions and is defined in libc. A module, on the other hand, is linked only to the kernel, and the only functions it can call are the ones exported by the kernel; there are no libraries to link to. The printk function used in hello.c earlier, for example, is the version of printf defined within the kernel and exported to modules. It behaves similarly to the original function, with a few minor differences, the main one being lack of floating-point support. 作为程序员,您知道应用程序可以调用它未定义的函数:链接阶段使用适当的函数库解析外部引用。 printf 是这些可调用函数之一,在 libc 中定义。 另一方面,模块只链接到内核,它唯一可以调用的函数是内核导出的函数; 没有要链接的库。 例如,前面 hello.c 中使用的 printk 函数是内核中定义并导出到模块的 printf 版本。 它的行为与原始函数相似,但有一些细微差别,主要区别在于缺乏对浮点的支持。
Figure 2-1 shows how function calls and function pointers are used in a module to add new functionality to a running kernel. 图 2-1 显示了如何在模块中使用函数调用和函数指针向正在运行的内核添加新功能。
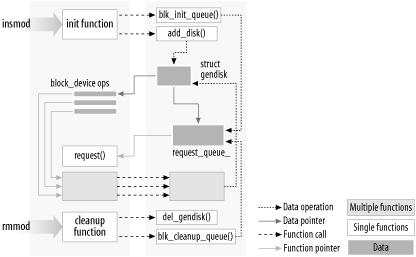
Figure 2-1. Linking a module to the kernel
Because no library is linked to modules, source files should never include the usual header files, <stdarg.h> and very special situations being the only exceptions. Only functions that are actually part of the kernel itself may be used in kernel modules. Anything related to the kernel is declared in headers found in the kernel source tree you have set up and configured; most of the relevant headers live in include/linux and include/asm, but other subdirectories of include have been added to host material associated to specific kernel subsystems. 因为没有库链接到模块,源文件不应该包含通常的头文件,<stdarg.h> 和非常特殊的情况是唯一的例外。 只有实际上是内核本身一部分的函数才能在内核模块中使用。 任何与内核相关的内容都在您设置和配置的内核源代码树中的头文件中声明; 大多数相关的头文件都存在于 include/linux 和 include/asm 中,但是 include 的其他子目录已添加到与特定内核子系统相关联的主机材料中。
The role of individual kernel headers is introduced throughout the book as each of them is needed. 整本书都介绍了各个内核头文件的作用,因为它们都是必需的。
Another important difference between kernel programming and application programming is in how each environment handles faults: whereas a segmentation fault is harmless during application development and a debugger can always be used to trace the error to the problem in the source code, a kernel fault kills the current process at least, if not the whole system. We see how to trace kernel errors in Chapter 4. 内核编程和应用程序编程之间的另一个重要区别在于每个环境如何处理错误:虽然分段错误在应用程序开发期间是无害的,并且始终可以使用调试器将错误追溯到源代码中的问题,但内核错误会杀死 如果不是整个系统,至少是当前进程。 我们将在第 4 章看到如何跟踪内核错误。
-
相关阅读:
RT-Thread系列09——ETH网口设备
nvm 新老项目需要不同版本node 可以安装nvm切换node版本
JavaScript -- 三种循环语句的介绍及示例代码
C语言学习记录(十五)C预处理器和C库
pyside6安装
白盒测试之测试用例设计方法
PDF水印怎么加?分享三个添加水印小妙招
全网最全超详细.htaccess语法讲解
ThinkPHP 8.x MVC 数据库用户增加功能demo实现
Redis特性与应用场景
- 原文地址:https://blog.csdn.net/mounter625/article/details/125501133