-
FlinkSQL自定义UDATF实现TopN
1.UDATF定义
Table aggregate functions(表聚合函数)多进多出(先聚合后炸裂),聚合过程如下图。
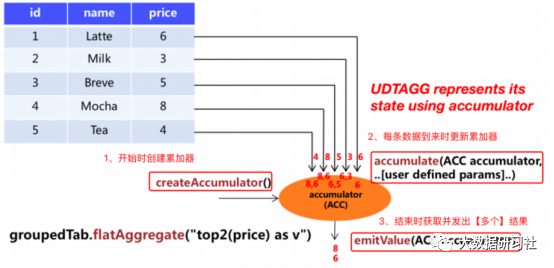
Table Aggregate functions聚合炸裂函数实现的核心步骤如下。
(1)继承TableAggregateFunction
(2)必须覆盖createAccumulator
(3)提供1个或者多个accumulate方法,一般就1个,实现更新累加器逻辑
(4)提供emitValue(...)或者emitUpdateWithRetract(...),实现获取计算结果的逻辑
(5)retract方法在OVER windows上才是必须的
(6)merge有界聚合以及会话窗⼝和滑动窗口聚合都需要(对性能优化也有好处)
(7)emitValue有界窗⼝聚合是必须的,无界场景用emitUpdateWithRetract可以提高性能
(8)如果累加器需要保存大的状态,可以使用org.apache.flink.table.api.dataview.ListView或者org.apache.flink.table.api.dataview.MapView以使⽤Flink状态后端,必须跟flatAggregate搭配使用。
2.数据集格式
学生学科考试成绩数据集如下所示:
1, "zhangsan","Chinese","90"
1, "zhangsan","Math","74"
1, "zhangsan","English","88"
2, "lisi","Chinese","86"
2, "lisi","Math","96"
2, "lisi","English","92"
3, "mary","Chinese","59"
3, "mary","Math","99"
3, "mary","English","100"
第一列表示学生ID,第二列表示学生姓名,第三列表示学科,第四列表示成绩。
3.自定义UDATF
FlinkSQL自定义UDATF函数对学生考试成绩进行聚合炸裂操作,按照科目分组统计成绩排前Topn的学生,具体实现代码如下所示。
public class FlinkUdatfFunction {
public static void main(String[] args) {
//1.获取table执行环境
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2.构造数据源
Table scores = tEnv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.INT()),
DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("course", DataTypes.STRING()),
DataTypes.FIELD("score", DataTypes.DOUBLE())
),
row(1, "zhangsan","Chinese","90"),
row(1, "zhangsan","Math","74"),
row(1, "zhangsan","English","88"),
row(2, "lisi","Chinese","86"),
row(2, "lisi","Math","96"),
row(2, "lisi","English","92"),
row(3, "mary","Chinese","59"),
row(3, "mary","Math","99"),
row(3, "mary","English","100")
).select($("id"), $("name"),$("course"),$("score"));
//3.注册表
tEnv.createTemporaryView("scoresTable",scores);
//4.注册函数
tEnv.createTemporarySystemFunction("Top2Func", new Top2Func());
// 5.Table API调用:使用call函数调用已注册的UDF
tEnv.from("scoresTable")
.groupBy($("course"))
//必须在flatAggregate中调用
.flatAggregate(call("Top2Func",$("score")).as("score","rank"))
.select($("course"),$("score"),$("rank"))
.execute()
.print();
}
/**
* 可变累加器的数据结构
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Top2Accumulator {
/**
* top 1的值
*/
public Double topOne = Double.MIN_VALUE;
/**
* top 2的值
*/
public Double topTwo = Double.MIN_VALUE;
}
//自定义UDATF
public static class Top2Func extends TableAggregateFunction<Tuple2<Double, Integer>, Top2Accumulator> {
//初始化累加器
@Override
public Top2Accumulator createAccumulator() {
return new Top2Accumulator();
}
//数据累加
public void accumulate(Top2Accumulator acc, Double value) {
if (value > acc.topOne) {
acc.topTwo = acc.topOne;
acc.topOne = value;
} else if (value > acc.topTwo) {
acc.topTwo = value;
}
}
//数据局部合并
public void merge(Top2Accumulator acc, Iterable<Top2Accumulator> it) {
for (Top2Accumulator otherAcc : it) {
accumulate(acc, otherAcc.topOne);
accumulate(acc, otherAcc.topTwo);
}
}
//数据输出
public void emitValue(Top2Accumulator acc, Collector<Tuple2<Double, Integer>> out) {
if (acc.topOne != Double.MIN_VALUE) {
out.collect(Tuple2.of(acc.topOne, 1));
}
if (acc.topTwo != Double.MIN_VALUE) {
out.collect(Tuple2.of(acc.topTwo, 2));
}
}
}
}
4.运行结果
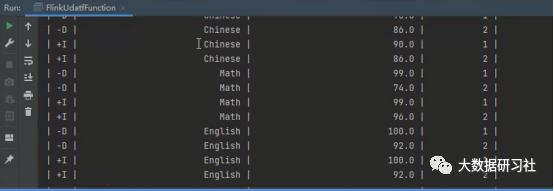
FlinkSQL自定义UDATF函数之后,使用注册的Top2Func函数对学生考试成绩聚合炸裂之后的效果如下所示。
-
相关阅读:
基于音频指纹的听歌识曲系统
C# 日志框架Serilog使用
CS224N第二课作业--word2vec与skipgram
只需根据接口文档,就能轻松开发 get 和 post 请求的脚本,你会做吗?
kafka第三课-可视化工具、生产环境问题总结以及性能优化
11链表-迭代与递归
SSD【目标检测篇】
easyNmon使用汇总
C语言常用的字符串函数(含模拟实现)
这款“三无产品“ 值得曝光...
- 原文地址:https://blog.csdn.net/dajiangtai007/article/details/125500106