-
机器学习5-线性分类器,Knn算法,朴素贝叶斯分类器,文本挖掘
一. 分类
1.1 分类的意义
- 传统意义下的分类: 生物物种
- 预测: 天气预报
- 决策: yes or no
1.2 分类与聚类的差别
图片来源:
https://www.zhihu.com/question/42044303/answer/470589507

1.3 分类和聚类常用的算法

分类算法:
- K近邻(KNN)
- 逻辑回归
- 支持向量机
- 朴素贝叶斯
- 决策树
- 随机森林
聚类算法 :
- K均值(K-means)
- FCM(模糊C均值聚类)
- 均值漂移聚类
- DBSCAN
- DPEAK
- Mediods
- Canopy
1.4 线性判别法的例子
以天气预报为例。
代码:
G=c(1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2) x1=c(-1.9,-6.9,5.2,5.0,7.3,6.8,0.9,-12.5,1.5,3.8,0.2,-0.1,0,2.7,2.1,-4.6,-1.7,-2.6,2.6,-2.8) x2=c(3.2,0.4,2.0,2.5,0.0,12.7,-5.4,-2.5,1.3,6.8,6.2,7.5,14.6,8.3,0.8,4.3,10.9,13.1,12.8,10.0) a=data.frame(G,x1,x2) plot(x1,x2) text(x1,x2,G,adj=-0.5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
测试记录:

用一条直线来划分训练集(这条直线一定存在吗?)
然后根据待测点在直线的哪一边决定它的分类代码:
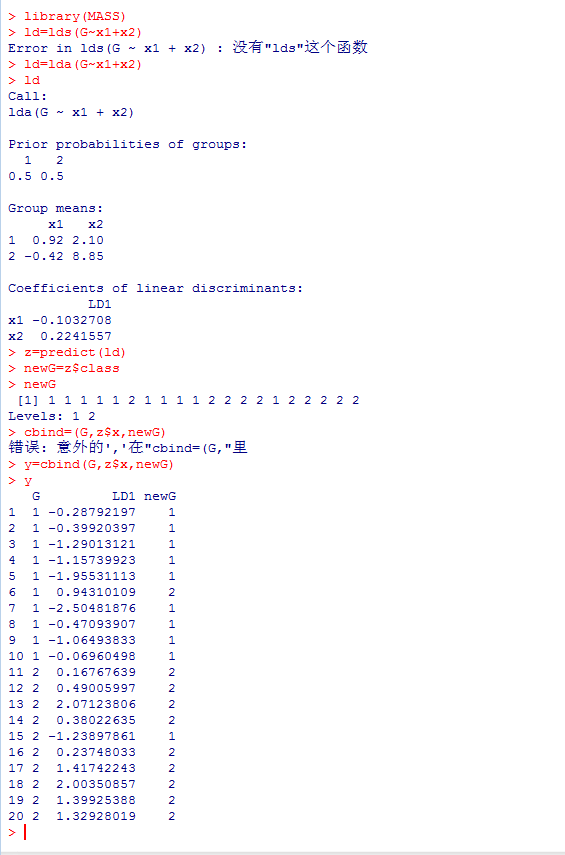
library(MASS) ld=lda(G~x1+x2) ld z=predict(ld) newG=z$class newG y=cbind(G,z$x,newG) y- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
二. 文本挖掘典型场景
2.1 网页自动分类

2.2 垃圾邮件判断
朴素贝叶斯分类器,使用的最频繁
先分词,然后判定垃圾邮件朴素贝叶斯分类 变量彼此之间没有联系,互不影响

2.3 评论自动分析

2.4 通过用户访问内容判别用户喜好
用户流失预警:

用户标签系统:

三. 贝叶斯信念网络
贝叶斯信念网络 区别于 朴素贝叶斯,各个变量之间存在某种关联关系,这种情况其实更贴合实际应用场景。



贝叶斯推理:


-
相关阅读:
【算法刷题 | 贪心算法03】4.25(最大子数组和、买卖股票的最佳时机|| )
10.图像高斯滤波的原理与FPGA实现思路
JavaScript——JSON
【精品】Springboot 接收发送日期类型的数据
基于Redis的简易延时队列
【无标题】
Softing新发布的dataFEED OPC Suite Extended V5.22版本支持OPC UA反向连接功能,为数据集成提供额外的安全保障
P35 JTree树
Docker的简介及安装
XS-Leaks(跨站点泄漏)攻击和预防
- 原文地址:https://blog.csdn.net/u010520724/article/details/125496207