-
利用pytorch可以实现手写字体的识别吗 基于深度学习算法
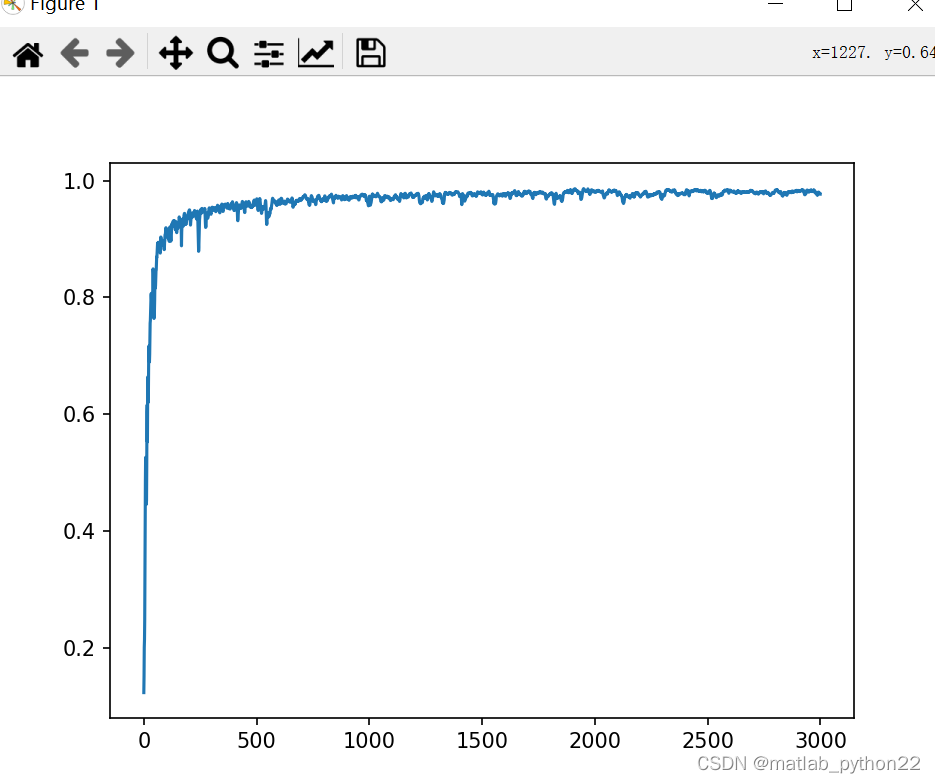
图 深度学习算法的结果图
目录
基本情况

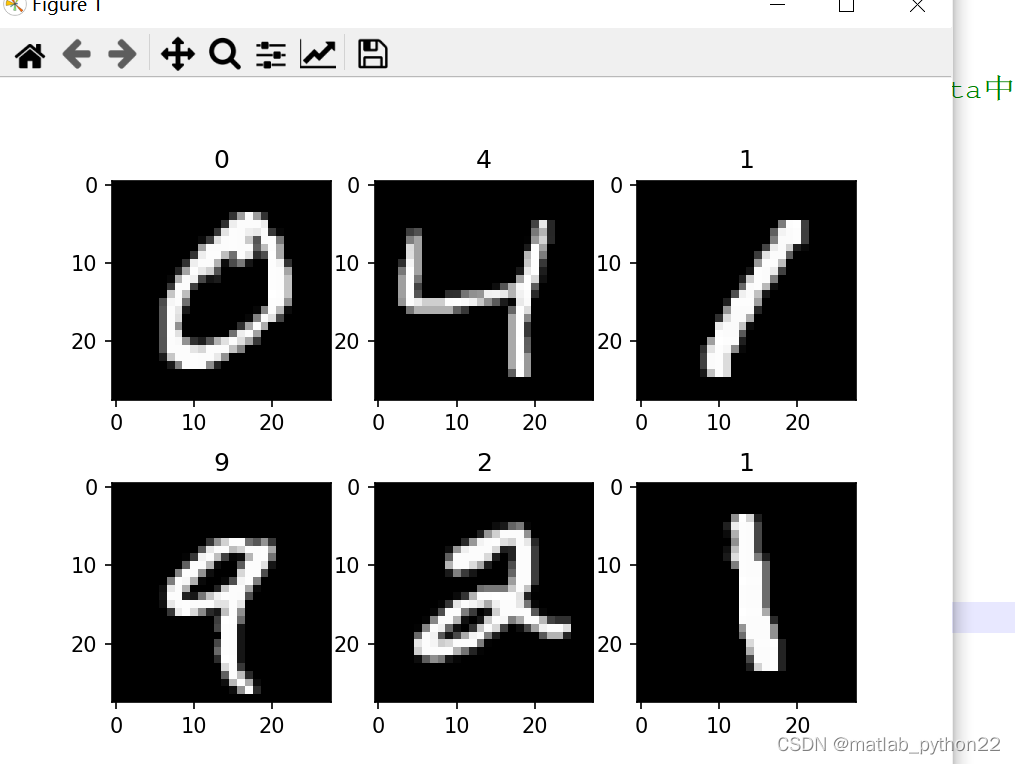

代表了手写字体的数据

可以看出来 数学字体原始有60000个样本,每一个样本的大小是28*28的大小,通道为1,不是三通道的数值
常规深度学习的结果数据
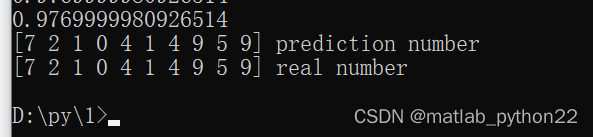
手写字体的真是标签和预测的标签是一样的 证明效果较好
model= CNN(
(conv1): Sequential(
(0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(out): Linear(in_features=1568, out_features=10, bias=True)
)
0.10350000113248825神经网络的基本构架
可以看出 卷积层两个 激活层两个 最大的池化两个 全连接层一个
改进
改进网络的深度
)
self.conv2=nn.Sequential(#卷积层2
nn.Conv2d(16,32,5,1,2),
nn.ReLU(),#激活函数,加了一层卷积层
nn.MaxPool2d(2),#池化层,筛选重要的部分
)
self.out=nn.Linear(32*7*7,10)#
self.out1=nn.Linear(10,10)#
self.out2=nn.Linear(10,10)#改变了深度,这个属于新的方式
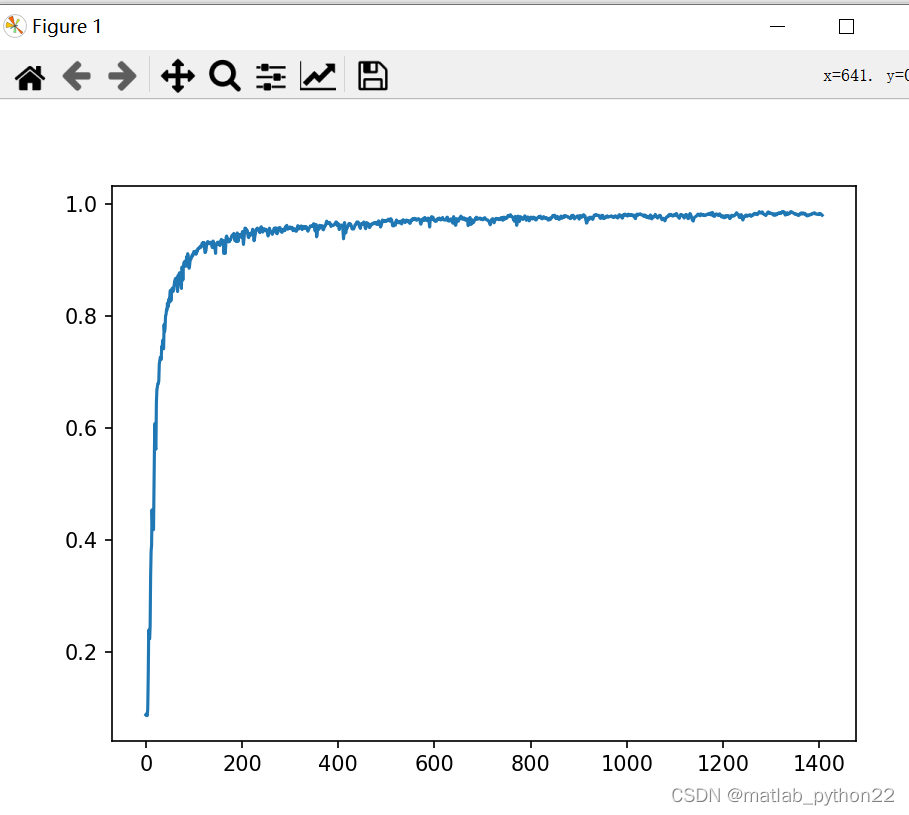
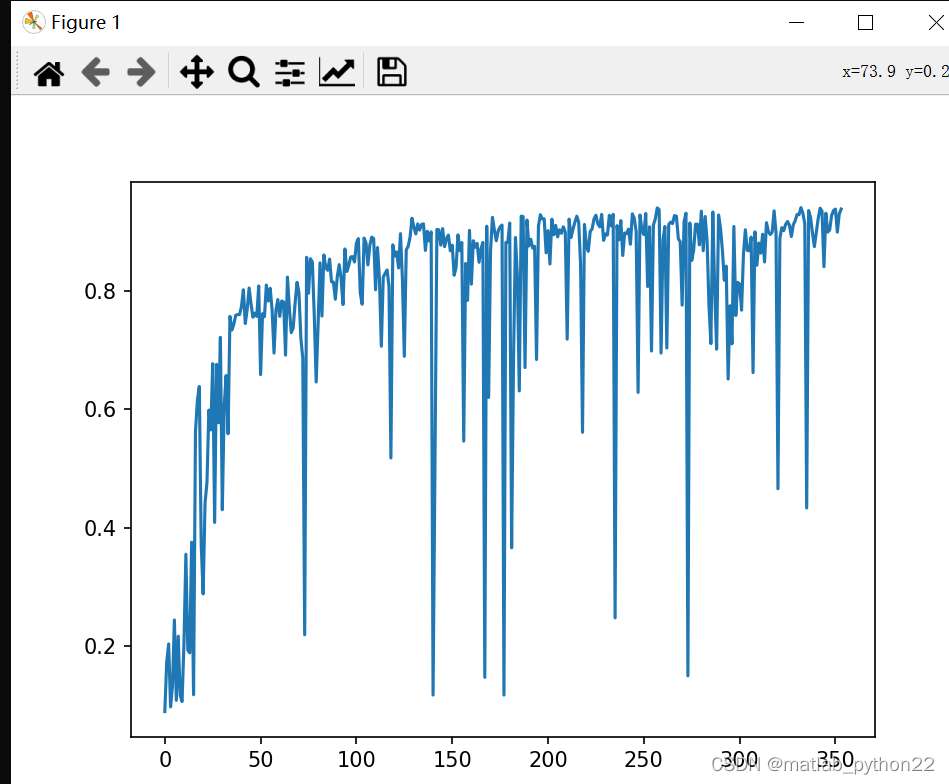
代表了经过改变网络深度的形式下,得到的acc的曲线图
改进网络的层数
有原来的两层架构改变为三层架构,转变为三个卷积层
x=self.conv1(x)
x=self.conv2(x) #(batch,32,7,7)
x=self.conv3(x) #(batch,32,7,7)
x=x.view(x.size(0),-1) #(batch,32*7*7)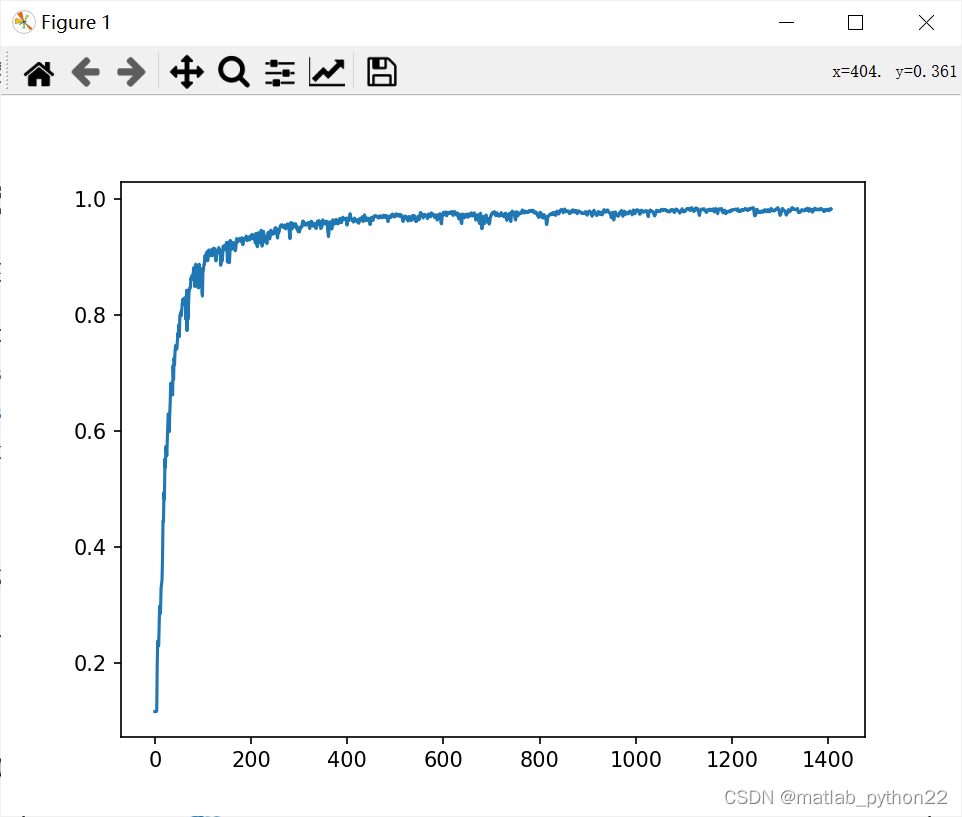
0.9815000295639038
0.9800000190734863
0.9790000319480896
0.9805000424385071
0.9825000762939453
0.9820000529289246
0.9805000424385071
0.9815000295639038
0.9830000400543213
0.9830000400543213
0.9830000400543213
0.9830000400543213
0.9805000424385071
0.9810000658035278
0.9825000762939453
0.983500063419342
0.9845000505447388
0.983500063419342上述代表了 准确率的曲线数值
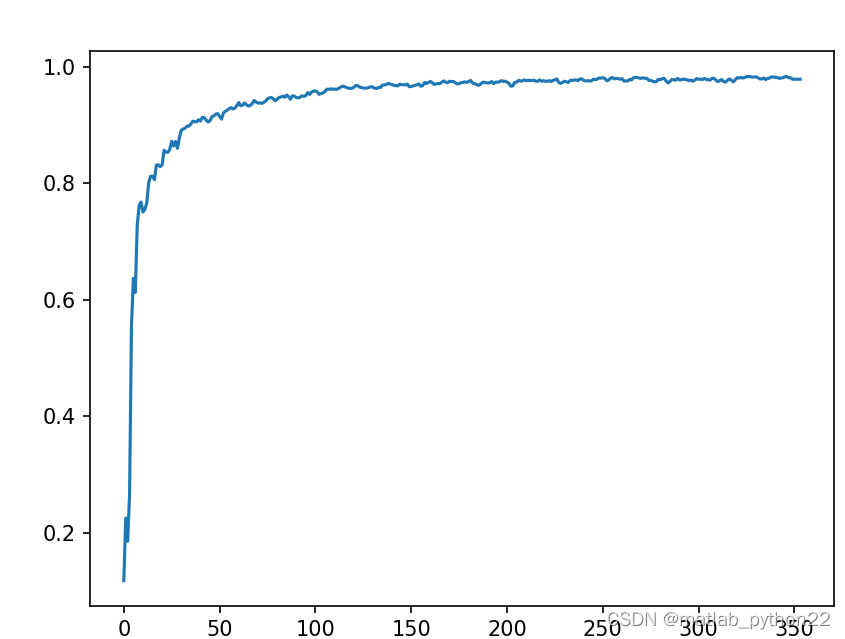
改变参数
调整bathcsize的结果如下
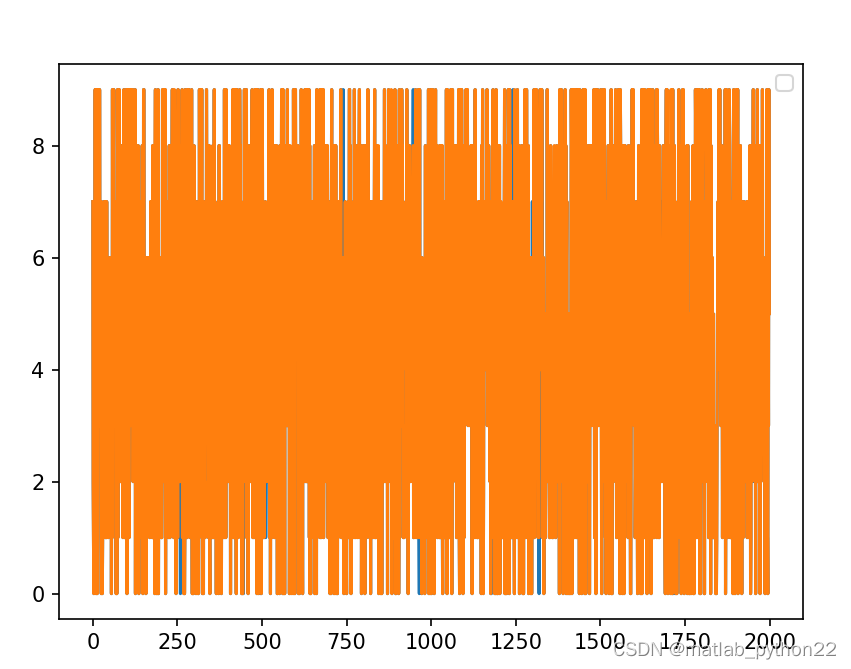
这是测试集合 真实的标签和预测的标签的结果
此图表示btachsize=256的结果
改变优化器
cam注意力机制模块
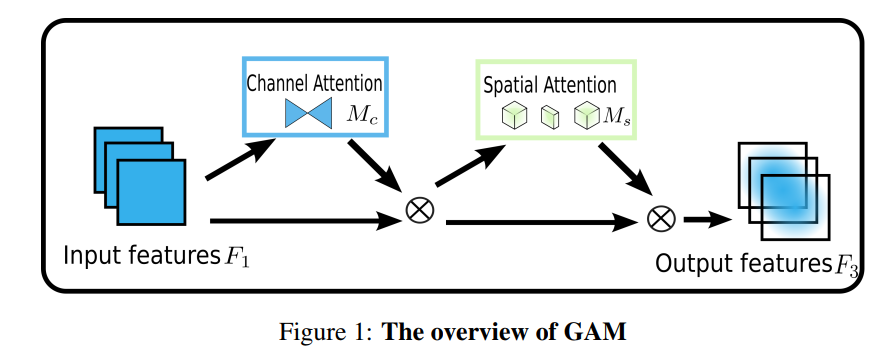
文的目标是设计一种注意力机制能够在减少信息弥散的情况下也能放大全局维交互特征。作者采用序贯的通道-空间注意力机制并重新设计了CBAM子模块。整个过程如图1所示,并在公式1和2。给定输入特征映射F1∈RC×H×W ,中间状态F2 和输出F3 定义为:
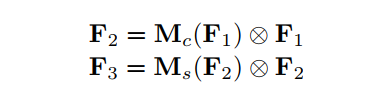
其中Mc 和Ms 分别为通道注意力图和空间注意力图;⊗ 表示按元素进行乘法操作。
目前 在接入cam之后的准确率下降
详细见到4.py的代码 比较的麻烦 还在找原因查找到底哪里出错
-
相关阅读:
java计算机毕业设计师大家教中心管理系统源程序+mysql+系统+lw文档+远程调试
OSSCore 开源解决方案介绍
数学建模学习(97):花授粉算法(FPA)寻优
程序员是职业病高发群体,别天真的以为只有秃头那么简单,才不是呢。
H5使用a标签时,在ios app中无法跳转
文件包含漏洞
Qt窗体设计的布局
Redis持久化机制分析
Pytorch GPU模型推理时间探讨
python+cuda编程(二)
- 原文地址:https://blog.csdn.net/matlab_python22/article/details/125482800