-
BERT和ViT简介
BERT和ViT简介
BERT(Bidirectional Encoder Representations from Transformers)是一个语言模型;而VIT(Vision Transformer)是一个视觉模型。两者都使用了Transformer的编码器:
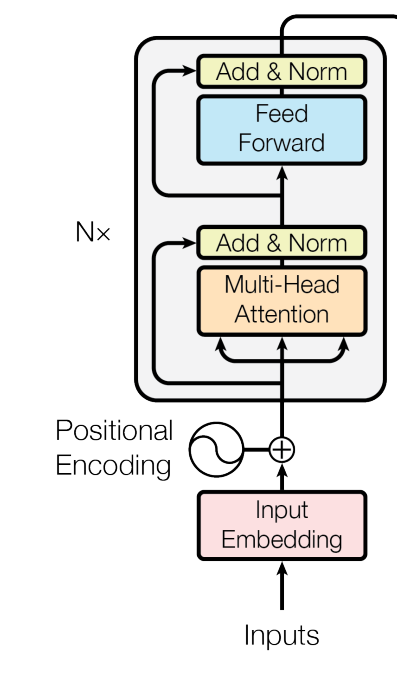
BERT
BERT输入文本的词向量,输出文本的语义表示。预训练的BERT可以用于各种语言处理任务。
BERT的预训练:
(1)任务1:Masked Language Model(MLM)
-
内容:句子填空。
-
目的:训练模型对句子的深层双向表示,即既可从左到右推断句子中的词也可以从右到左推断。
-
方法:
对一个句子随机用掩码[MASK]挖空。

然后将句子输入BERT得到其表示:

最后将[MASK]对应的表示输入一个多类别线性分类器预测填空:

(2)任务2: Next Sentence Prediction (NSP)
-
内容: 判断两个句子是否连接在一起。
-
目的: 训练模型理解句子之间的关系。
-
方法:

不同的句子(例如“醒醒吧”和“你没有妹妹”)用[SEP]标志符隔开,与[CLS]一起输入BERT。 [CLS]对应的表示会输入一个二分类器,判断两个句子是否是连接在一起的。注意,BERT内部是多头自注意力,[CLS]可以放在句子任意位置,最终都能获得其他输入的信息。
使用预训练的BERT:
(1)输入一个句子,输出类别:

其中线性分类器(Linear Classifier)是从头开始训练的,而BERT微调(Fine-tune)参数。(2)输入一个句子,对句子中的每个词汇进行分类(例如动词、名词、代词等等)。
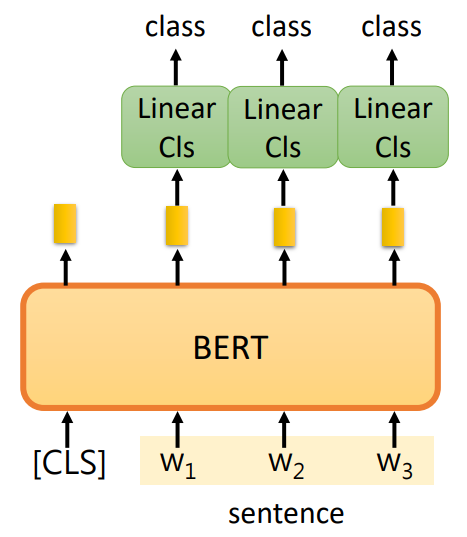
同理,其中线性分类器是从头开始训练的,而BERT微调(Fine-tune)参数。
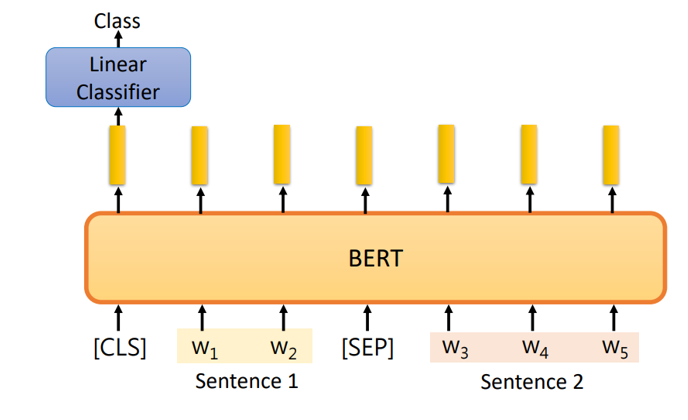
(3)输入两个句子,输出一个类别(例如,判断两个句子是否有指定的某种关系)。
(4)阅读理解:输入文章(Document)和一些问题(Query),输出问题的回答。

输出 ( s , e ) (s,e) (s,e)表示文章中第 s s s个词和(包括)第 e e e个词之间的内容。例如:


使用两个可训练参数向量分别与document对应的表示做点乘,然后经过Softmax选择最高概率的位置。
起始位置(橙色参数向量) 结束位置 (蓝色参数向量) 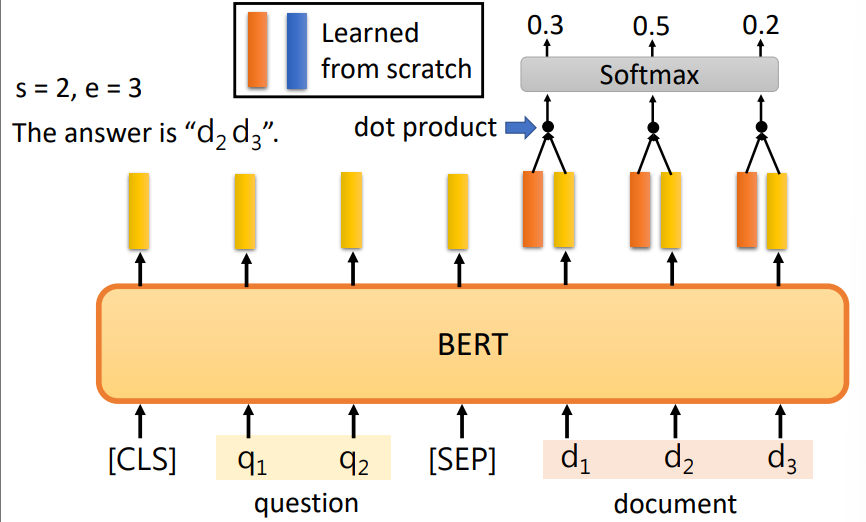

ViT
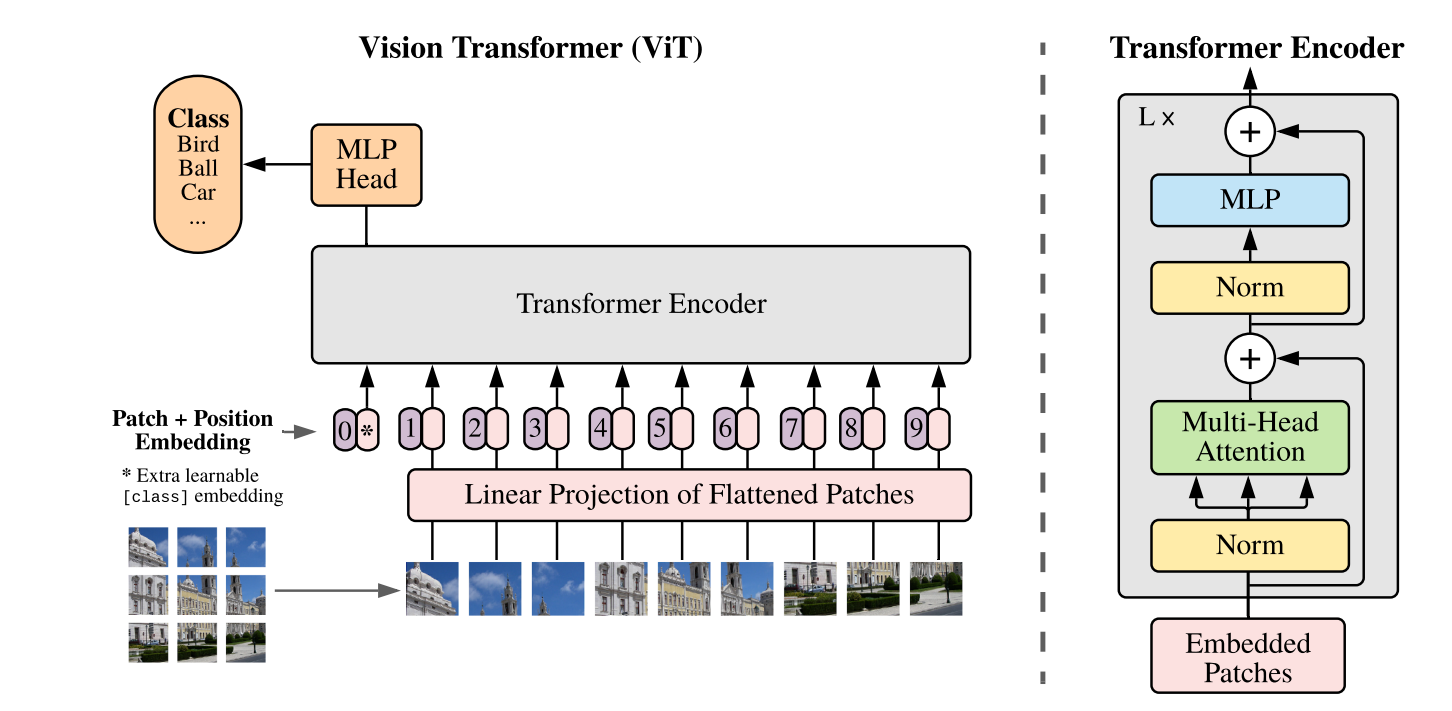
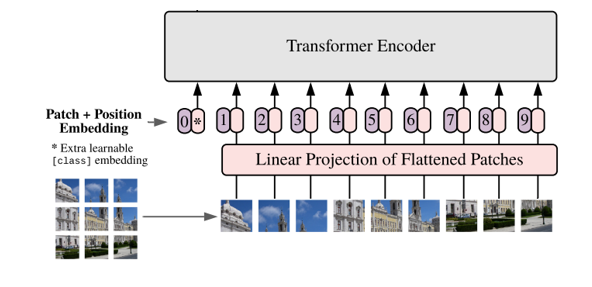
VIT与BERT一样,也使用了Transformer的编码器,但因为它处理的是图像数据,所以在输入部分需要对图像做一些特殊处理:VIT将输入的图片分块并向量化,从而可以使用与词向量相同的编码模型。(1) 把图像分成序列的小块(patch),每个小块相当于句子的一个词。

(2)将小块拉平(flatten)成一个向量并使用线性变换矩阵对其进行线性映射。

(3)与上文BERT的[CLS]一样,VIT也添加了这样一个类别向量:*。然后为每个向量添加位置信息。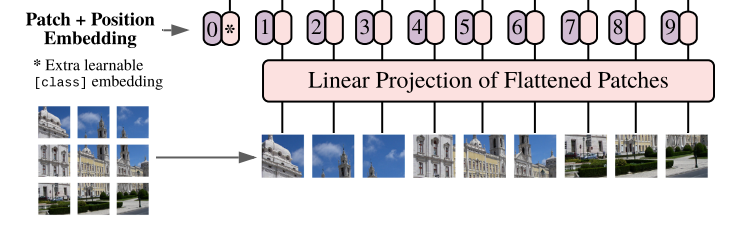
(4)输入Transformer 编码器
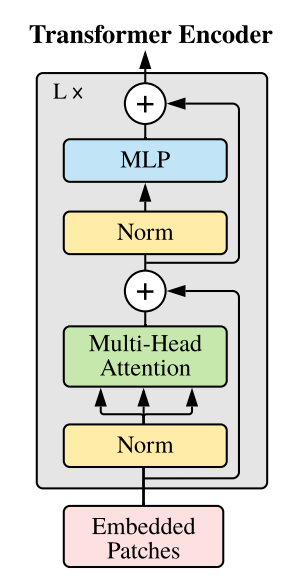
(5)最后是分类,与BERT同理。
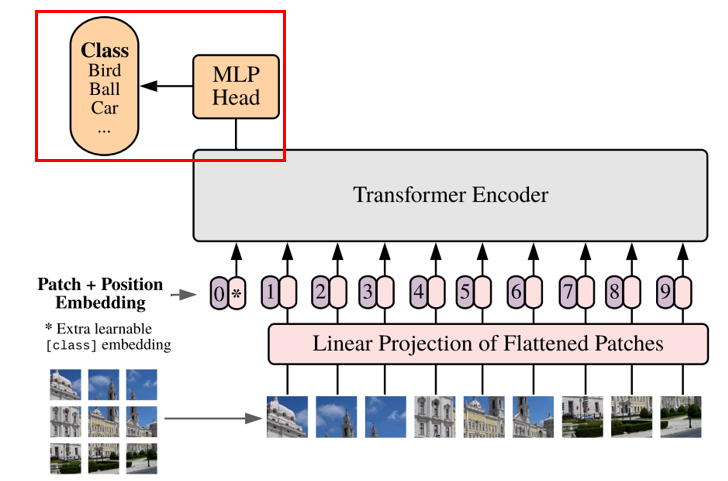
注意,VIT的预训练任务也是分类。
[1] 机器学习,李宏毅 ,http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML19.html
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding h ttps://arxiv.org/pdf/1810.04805v2.pdf
[3] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE https://arxiv.org/abs/2010.11929
-
-
相关阅读:
【Shell编程】Shell中的正则表达式
并发编程day01
配置nginx动静分离全步骤
吴恩达《机器学习》6-1->6-3:分类问题、假设陈述、决策界限
win部署CRM
sql 时间函数
(c语言)位操作符
模拟电路总结
Gof23-创建型-工厂-单例-抽象工厂-建造-原型以及UML的绘制
音乐播放
- 原文地址:https://blog.csdn.net/weixin_44378835/article/details/125428022