-
TiDB 6.0:让 TSO 更高效丨TiDB Book Rush
本文作者:h5n1,TiDB爱好者,目前就职于联通软件研究院,asktug 主页
1. 前言
TiDB 作为一个分布式数据库,计算节点 tidb server 和存储节点 tikv/tiflash server 有着近乎线性的扩展能力,当资源不足时直接在线扩容即可。但作为整个集群大脑的 PD 节点因为只有 leader 提供服务,不能向其他组件一样通过扩展节点而提高处理能力。
目前 TSO 分配的主要问题:
-
TSO 分配由 PD Leader 节点提供,大量请求下会导致 Leader 节点 CPU 利用率增高,影响事务延迟。
-
PD Follower 节点基本处于空闲状态,系统资源利用率较低。
-
TiDB 跨数据中心访问 PD Leader 时,数据中心间的延迟导致事务延迟增加。
为提升 TSO 的处理性能针对部分场景 TiDB 引入了 TSO Follower Proxy、RC Read TSO 优化、Local TSO 等特性,通过扩展 PD 处理能力和减少 TSO 请求的方式,提升整体吞吐量,降低事务延迟。
2. TSO
TSO 是一个单调递增的时间戳,由 PD leader 分配。TiDB 在事务开始时会获取 TSO 作为 start_ts、提交时获取 TSO 作为 commit_ts,依靠 TSO 实现事务的 MVCC。TSO 为 64 位的整型数值,由物理部分和逻辑部分组成,高 48 位为物理部分是 unixtime 的毫秒时间,低 18 位为逻辑部分是一个数值计数器,理论上每秒可产生 262144000(即 2 ^ 18 * 1000)个 TSO。

为保证性能 PD 并不会每次为一个请求生成一个 TSO,而是会预先申请一个可分配的时间窗口,时间窗口是当前时间和当前时间+3 秒后的 TSO,并保存在 etcd 内,之后便可以从窗口中分配 TSO。每隔一定时间就会触发更新时间窗口。当 PD 重启或 leader 切换后会从 etcd 内获取保存的最大 TSO 开始分配,以保证 TSO 的连续递增。
3. Follower Proxy
默认情况下 TSO 请求由 PD leader 处理,TiDB 内部通过 PD Client 向 PD leader 发送请求获取 TSO,PD client 并不会将收到的请求立刻发送给 PD leader ,而将同一时刻收到的所有请求打包发送给 PD leader,然后由 PD leader 返回一批 TSO。由于仅有 leader 提供服务,tidb server 数量较多时会有较多的 PD Client 和 PD Leader 建立连接,导致切换处理连接请求时 CPU 消耗较高。同时 follower 节点仅通过 raft 同步数据和提供选举等功能,基本处于空闲状态。
在 5.3.0 版本引入 TSO Follower Proxy 功能,当开启后 tidb 的 PD Client 会随机选择一个 PD 节点(包括 leader 和 follower )发送 TSO 请求,PD Follower 会作为一个代理服务将收到的一批请求按照默认情况下 PD Client 处理 TSO 方式打包发送给 leader 处理,以进一步减少 PD Client 和 PD Leader 的交互次数以及 PD leader 的连接数,以此降低 leader 的 CPU 负载。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IMpqCUk9-1656300380513)(https://tidb-blog.oss-cn-beijing.aliyuncs.com/media/1654048816(1)]-1654048828624.jpg)
通过设置全局变量 tidb_enable_tso_follower_proxy 为 true 即可开启 PD follower 的 TSO 代理功能,该功能适用于 tidb server 数量较多并发请求很高,PD leader 因高压力的 TSO 请求而达到 CPU 瓶颈,导致 TSO RPC 请求的延迟较高的场景。
4. RC Read TSO 优化
Read-Commited 隔离级别需要在悲观事务模式下,在悲观事务中每个 SQL 执行时会从 PD 获取 TSO (for_update_ts) 用于一致性读、冲突检测等,每个 SQL 相当于一个 Snapshot-Isolation 的’小事务’,相比乐观事务模式悲观事务产生的 TSO 请求会更多,在整个事务期间如果能在不破坏事务一致性和隔离性的情况下减少 tso 请求次数,就能够降低 PD 的负载和事务延迟,从而提升整体性能。
6.0 版本中对 RC 事务中的 SELECT 语句 TSO 请求做了优化,使用一种乐观方式获取 TSO ,仅当遇到新版本后才会获取最新的 TSO 读取数据,通过减少读操作从 PD 获取 TSO 的请求次数,从而降低查询延迟,提升读写冲突较小场景的 QPS。该特性由 tidb_rc_read_check_ts 变量控制,默认为 off,开启该功能设置为 on 即可。
优化后 select 语句处理基本过程如下:
-
Select 语句执行时不从 PD 获取 TSO 作为 for_update_ts,而是使用上一个有效的 TSO 作为 for_update_ts(即为 read_ts)。如果是事务中的第一个语句则是 start_ts,否则是上一个 SQL 的 for_update_ts。
-
构建执行计划并执行,发送到 tikv 的数据读取请求(pointget、coprocessor)会带上 RcReadCheckTS 标志。
-
数据读取请求使用前面获得的 read_ts 做一致性读取,并将数据返回 tidb server。
-
TiKV 会检查返回的数据是否有更新版本,如果有更新的版本则返回 WriteConflict 错误,否则返回数据后正常结束执行。
-
如果此时 tidb 还未向 client 发送数据则会从 PD 获取最新的 TSO 作为 for_update_ts 重新执行整个查询,否则会向 client 返回错误。
从上面的过程可以看出当遇到新版本后会导致 tidb server 使用正常的流程重新获取 TSO 和执行 SQL,在读写冲突的情况下会降低性能使得事务执行时间延长。如果已经有部分数据返回 client 的话会导致报错 SQL 执行失败,虽然通过增加 tidb_init_chunk_size 变量大小延迟 tikv 返回数据时间,可以降低一些上述错误发生的情况,但仍然不是一个根本解决方式。
5. Local TSO
在多数据中心场景下 PD leader 位于某个数据中心内,数据中心间的延迟会造成 TSO 请求延迟增加,如果能够在数据中心内完成 TSO 请求和分配则可以大大降低 TSO 请求延迟。基于此 tidb 引入了 Local TSO (实验功能),PD 中设计 2 个 TSO allocator 角色:local tso allocator 和 global tso allocator,相应的事务也被分成了本地事务 local transaction 和全局事务 global transaction 两种。
- Local TSO
当通过 enable-local-tso 启用后数据中心内的 PD 会选出一个节点作为 local tso allocator 用于分配 TSO,该节点作为 local tso 分配的 leader 角色( PD 角色仍为 follower )。当事务操作的数据仅涉及到本数据中心的数据时,则判断为本地事务,向本地 tso allocator 申请 local tso。
每个数据中心分配自己的 local tso,相互之间是独立的,为避免不同数据中心分配了相同的 TSO,PD 会设置 local tso 中的逻辑时间低几位做后缀,不同的数据中心使用不同的值,同时这些信息会持久化记录到 PD 内。
- Global TSO
当事务操作的数据涉及到其他数据中心时则为全局事务,此时需要向 PD leader 申请 global tso, PD leader 作为 global tso allocator。当未启用 local-tso 功能时,仍按原来的逻辑所有数据中的 TSO 请求由 PD leader 负责处理。
为保证 local tso 和 global tso 的线性增长,global tso allocator 和 local tso allocator 会进行 max_tso 同步:
-
Global tso allocator 收集所有 local tso allocator 的最大 local tso。
-
从所有 local tso 中选出一个最大的 local tso 作为 max_tso 下发到 local allocator。
-
如果 max_tso 比自己的大则更新 TSO 为 max_tso,否则直接返回成功。
Local tso 的使用需要考虑不同的数据中心处理不同的业务,同时要结合 PlacementRules in SQL 将表根据业务规则按数据中心进行分布,同时可设置 txn_scope 变量为 local/global 用于人为控制获取 global tso 还是 local tso.
基本配置步骤 (目前不支持 Local TSO 回退为 Global TSO 模式):
- PD、TiKV、TiDB server 均需要根据实际部署设置 label,为保证高可用每个 DC 的 PD 数量应>1。
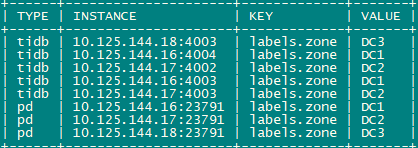

- 开启库或表级 Placement Rules in SQL,根据地域和业务关系进行调度。
CREATE PLACEMENT POLICY dc1_leader LEADER_CONSTRAINTS="DC1" FOLLOWER_CONSTRAINTS="DC1,DC2,DC3" FOLLOWERS=2; Alter table new_order PARTITION p0 PLACEMENT POLICY dc1_leaders;- 设置 PD 参数 enable-local-tso=on 使用 tiup reload 重启 PD 开启 Local TSO 功能。启用之后可通过 pd-ctl -u pd_ip:pd_port member 中 tso_allocator_leaders 项内容查看每个中心的 local tso allocator leader。

6. 测试
6.1 测试环境

6.2 TSO Follower Proxy
在 1024 线程下使用 sysbench 对 6 张 1 亿记录表在开启 TSO Follower Proxy 前后的 TPS 和平均延迟如下:

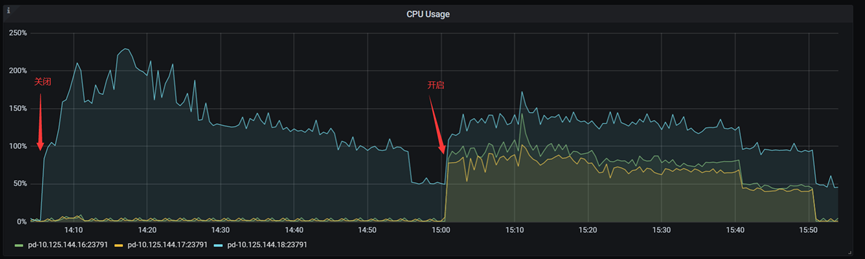
测试期间 TSO Follower Proxy 关闭和开启时的 CPU 利用率:
6.3 RC Read TSO
使用 tiup-bench 测试不同线程下开启 tidb_rc_read_check_ts 前后的 TPCC,可以看到开启该功能后对 TPCC 有一定提升,但随着线程数增加冲突增多 TPCC 出现下降情况。

通过 TiDB –> PD Client –> PD Client CMD OPS 监控可以看到 256 线程下开启 tidb_rc_read_check_ts 后 PD client 中等待 TSO 的次数明显降低。

6.4 Local TSO
Local TSO 作为实验功能尚需完善,TPCC 测试中当开启该功能后出现大量报主键重复错误。

7. 总结
为提升 TSO 的扩展性和效率,TiDB 进行了大量的优化工作,但这些优化有确定的场景,需要结合业务和实际情况考虑,否则盲目开启有可能会造成 QPS 降低、延迟增高的情况:
对于 Follower TSO Proxy 适合于由于 PD Leader CPU 繁忙导致的 TSO 获取延迟的场景,通过开启 Follower Proxy 后降低 leader 的压力。
RC Read TSO 优化适合于读多写少的场景,如果数据冲突严重反而会造成性能下降。
Local TSO 作为 TiDB 分布式授时方案从理论上能够解决因数据中心间的延迟造成的 TSO 延迟,不过目前实验功能尚有一些问题。
-
-
相关阅读:
信息安全技术
手把手带你搭建第一个SpringCloud项目(二)
北汽蓝谷:业绩承压,极狐难期
《幸福之路》罗素(读书笔记)
力扣100题-07-三数之和
手绘二维码
Netty(四)- NIO三大组件之Selector
springboot集成swagger3.0
9.1 运用API创建多线程
Vue事件处理器:事件绑定基础、事件修饰符:stop、prevent、capture、self、once;
- 原文地址:https://blog.csdn.net/TiDB_PingCAP/article/details/125480817