-
jvm05
jvm参数
标准参数
-version
-heple
-server
-cp

-x参数
非标准参数,也就是在jdk各个版本中可能会变动
-Xint释放执行
-Xcomp 第一次使用就编译成本地代码
-Xmixed混合模式,JVM自己来决定
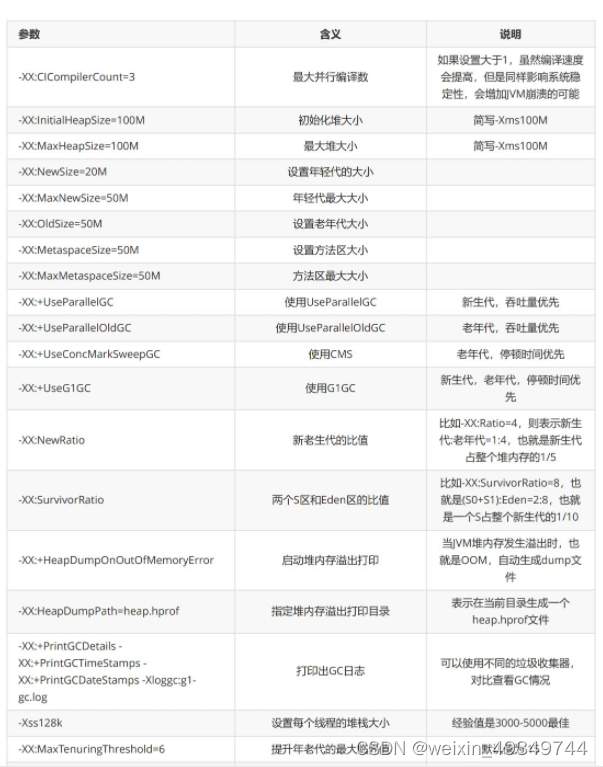
-xx参数
a.Boolean类型
格式:-XX:[±] +或-表示启动用或禁用name属性
比如:–XX:+UseConcMarkSweepGC 表示启动CMS类型的垃圾回收器
–XX:+UseGlGC 表示启用G1类型的垃圾回收器
b.非Boolean类型
格式:-XX=表示name属性的值是value
比如:-XX:MaxGCPauseMillis=500其他参数
-Xms1000M等于-XX:InitialHeapSize=1000M
-Xmx1000M等于-XX:MaxHeapSize=1000M
-Xss100等于-XX:ThreadStackSize=100
所以这块也相当于是-XX类型的参数查看参数
java-XX;+PrintFlagsFinal -version>flags.txt


值得注意是=表示默认值,“:=”表示被用户或jvm修改的值
要想查看某个进程具体参数的值,可以使用jinfo,这块后面聊
一般要设置参数,可以先查看一下当前参数是什么,然后进行修改设置参数的常见方式
开发工具设置比如idea,eclipse
运行jar包的时候:java -XX:+UseG1GCxxx.jar
web容器比如tomcat,可以在脚本中的进行设置
通过jinfor实时调用某个java进程的参数(参数只有被标记为manageable的flags可以被实时修改)
实践和单位换算
1Byte(字节)=8bit(位)
1kb=1024Byte(字节)
1MB=1024KB
1GB=1024MB
1TB=1024GB
(1)设置堆内存大小和参数打印
-Xmx100M -Xms100M -XX:+PrintFlagsFinal
(2)查询+PrintFlagsFinal的值
:=true
(3)查询堆内存大小MaxHeapSize
:=104857600
(4)换算
104857600(Byte)/1024=102400(KB)
102400(kB)/1024=100MB
(5)结论
104857600是字节单位常用参数含义

垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现
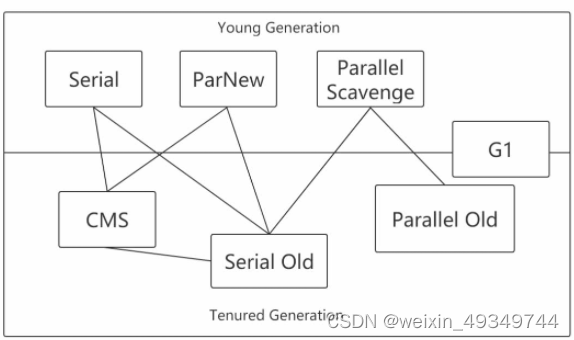
serial
Serial收集器是最基本,发展历史最悠久的收集器,曾经(在jdk1.3.1之前)是虚拟机新生代收集的唯一选择。
它是一种单线程收集器,不仅仅意味着它只会使用一个CPU或者一条收集线程去完成垃圾收集工作,更重要的是其在进行垃圾收集的时候需要暂停其他线程
优点:简单高效,拥有很高的单线程收集效率
缺点:收集过程需要暂停所有线程
算法:复制算法
适用范围:新生代
应用:Client模式下的默认新生代收集器
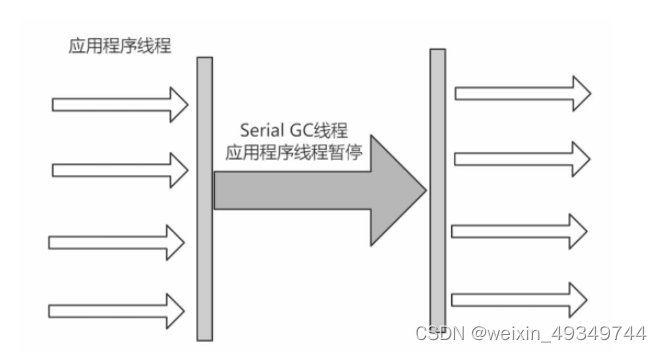
Serial Old
Serial Old收集器是Serial收集器的老年代版本,也是一个单线程收集器,不同的是采用“标记-整理算法”,运行过程和Serial收集器一样。
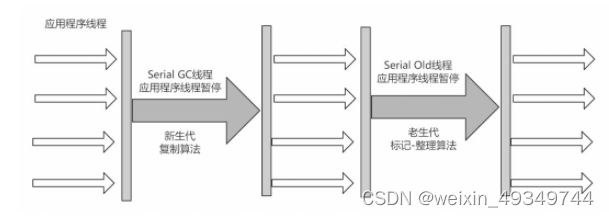
ParNew
可以把这个收集器理解为Serial收集器的多线程版。
优点:在多cpu时,比Serial效率高。
缺点:收集过程暂停所有应用程序线程,单cpu时比Serial效率差
算法:复制算法
适合范围:新生代
应用:运行在Server模式下的虚拟机中首选的新生代收集器
Parallel Scavenge
Parallel Scavenage收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器,看上去和ParNew一样,但是Parallel Scanvernge更关注系统的吞吐量
吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)
比如虚拟机总共运行1000分钟,垃圾收集时间用了1分钟,吞吐量=(100-1)/100=99%。
若吞吐量越大,意味着垃圾收集的时间越短,则用户代码可以充分利用CPU资源,尽快完成程序的运算任务。
-XX:MaxGCPauseMillis控制最大的垃圾收集停顿时间
-XX:GCTimeRatio直接设置吞吐量的大小。Parallel Old
Parallel Old收集器是Parallel Scavengel收集器的老年代版本,使用多线程和标记-整理算法进行垃圾回收,也是更加关注系统的吞吐量。
CMS
官网:https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/cms.html#concurrent_mark_sweep_cms_collector
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。
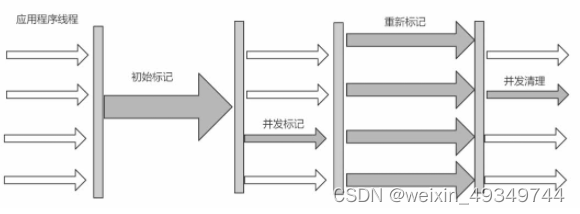
采用的是标记-清除算法,整个过程分为4步
(1)初始标记 CMS initial mark 标记GC Roots直接关联对象,不用Tracing,速度很快
(2)并非标记 CMS concurrent mark 并行GC
Roots Tracing
(3)重新标记 CMS remark 修改并发标记因为用户程序变动的内容
(4)并发清除 CMS concurrent sweep 清除不可达对象回收空间,同时有新垃圾产生,留着下次清理称为浮动垃圾
由于整个过程中,并发标记和并发清理,收集器线程可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发地执行的
优点:并发收集,低停顿
缺点:产生大量空间碎片,并发阶段会降低吞吐量,还会并发失败
backgroud模式为正常模式执行上述的CMS GC流程
forefroud模式为Full GC模式
相关参数:
开启CMS垃圾收集器
-XX:+UseConcMarkSweepGC
//默认开启,与-XX:CMSFullGCsBeforeCompaction配合使用
-xx:+UseCMSCompactAtFullCollection
//默认0 几次Full GC后开始整理
-XX:CMSFullGCsBeforeCompaction=0
//辅助CMSInitiatingOccupancyFraction的参数,不然CMSInitiatingOccupancyFraction只会使用一次就恢复自动调,也就是开启手动调整
-XX:+UseCMSInitiatingOccupancyOnly
取值0-100,按百分比回收
-XX:CMSInitiatingOccupancyFraction默认-1
注意:CMS并发GC不是“full GC".HotSpot VM里面对
concurrent collection和full collection 有明确的区别。所有带有”FullCollection“字样的vm参数都是跟真正的full GC相关,而跟CMS并发GC无关的 -
相关阅读:
10 通用同步异步收发器(USART)
经典论文-MobileNet V1论文及实践
数据结构与算法 | 图(Graph)
JavaScript用浏览器书签制作插件(爬虫)
Go语言的其他高级特性
从 Solana 课程顺利毕业获得高潜岗位,他的 Web3 开发探险之旅
交叉编译链的问题
MySQL高级-读写分离-分库分表
python多线程系列—Event对象(六)
关于JVM的参数类型
- 原文地址:https://blog.csdn.net/weixin_49349744/article/details/125477267