-
100天精通Python(爬虫篇)——第44天:requests库大总结

每篇前言
-
🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!


一、request模块大总结
本文主要学习
requests这个http模块,该模块主要用于发送请求获取响应,该模块有很多的替代模块,比如说urlib模块, 但是在工作中用的最多的还是requests模块,requests的代码简洁 易懂,相对于臃肿的urlib模块,使用requests编写的爬虫代码将会更少, 而且实现某-功能将会简单。因此建议大家掌握该模块的使用1. 下载安装
1. window电脑点击
win键+ R,输入:cmd
2. 安装
requests,输入对应的pip命令:pip install requests,我已经安装过了出现版本就安装成功了
2. 常用属性或方法
方法/属性 说明 response = requests.get(url)发送请求获取的响应对象(最常用) response = requests.post(url)发送请求获取的响应对象 response.url响应的url;有时候响应的ur1和请求的urI并不一致 response.status_ code响应状态码,如:200,404 response.request.headers响应对应的请求头 response. headers响应头 response.request.cookies响应对应请求的cookie; 返回cookieJar类型 response.cookies响应的cookie (经过了set- cookie动作; 返回cookieJar类型) response.json()自动将json字符串类型的响应内容转换为python对象 (dict or list) response.text返回响应的内容,str类型 response.content返回响应的内容, bytes类型 简单代码实现:通过requests向百度首页发送请求,获取该页面的源码
import requests # 目标网址 url = "http://www.baidu.com/" # 发送请求获取响应 response = requests.get(url) # 查看响应对象的类型 print(type(response)) # 查看响应状态码 print(response.status_code) # 查看响应内容的类型 print(type(response.text)) # 查看cookies print(response.cookies) # 查看响应的内容 print(response.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
输出结果:
<class 'requests.models.Response'> 200 <class 'str'> <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]> <!DOCTYPE html> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ–°é—»</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产å“</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å ³äºŽç™¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度å‰å¿ 读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ„è§å馈</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html> b'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b\xef\xbc\x8c\xe4\xbd\xa0\xe5\xb0\xb1\xe7\x9f\xa5\xe9\x81\x93</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>\xe6\x96\xb0\xe9\x97\xbb</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>\xe5\x9c\xb0\xe5\x9b\xbe</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>\xe8\xa7\x86\xe9\xa2\x91</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>\xe8\xb4\xb4\xe5\x90\xa7</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>\xe7\x99\xbb\xe5\xbd\x95</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">\xe7\x99\xbb\xe5\xbd\x95</a>\');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">\xe6\x9b\xb4\xe5\xa4\x9a\xe4\xba\xa7\xe5\x93\x81</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>\xe5\x85\xb3\xe4\xba\x8e\xe7\x99\xbe\xe5\xba\xa6</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>\xe4\xbd\xbf\xe7\x94\xa8\xe7\x99\xbe\xe5\xba\xa6\xe5\x89\x8d\xe5\xbf\x85\xe8\xaf\xbb</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>\xe6\x84\x8f\xe8\xa7\x81\xe5\x8f\x8d\xe9\xa6\x88</a> \xe4\xba\xacICP\xe8\xaf\x81030173\xe5\x8f\xb7 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3. response.text和response.content的区别:
response.text:- 类型:str
- 解码类型: requests模块自动根据HTTP头部对响应的编码作出有根据的推测,推测的文本编码
response.content:- 类型:bytes
- 解码类型:没有指定,执行挑选
通过对response.content进行decode,来解决中文乱码:
response.content.decode():默认utf-8response.content.decode('GBK')
常见的编码字符集
utf-8gbkgb2312asci(读音:阿斯克码)iso-8859-1
代码演示:
import requests # 目标网址 url = "http://www.baidu.com/" # 发送请求获取响应 response = requests.get(url) # 手动设置编码格式 response.encoding = 'utf8' # 打印源码的str类型数据 print(response.text) # response.content是存储的bytes类型的响应数据,进行decode操作 print(response.content.decode('utf-8'))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
运行结果:
<!DOCTYPE html> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html> <!DOCTYPE html> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>- 1
- 2
- 3
- 4
- 5
4. 发送带headers参数请求
1)查看浏览器请求头
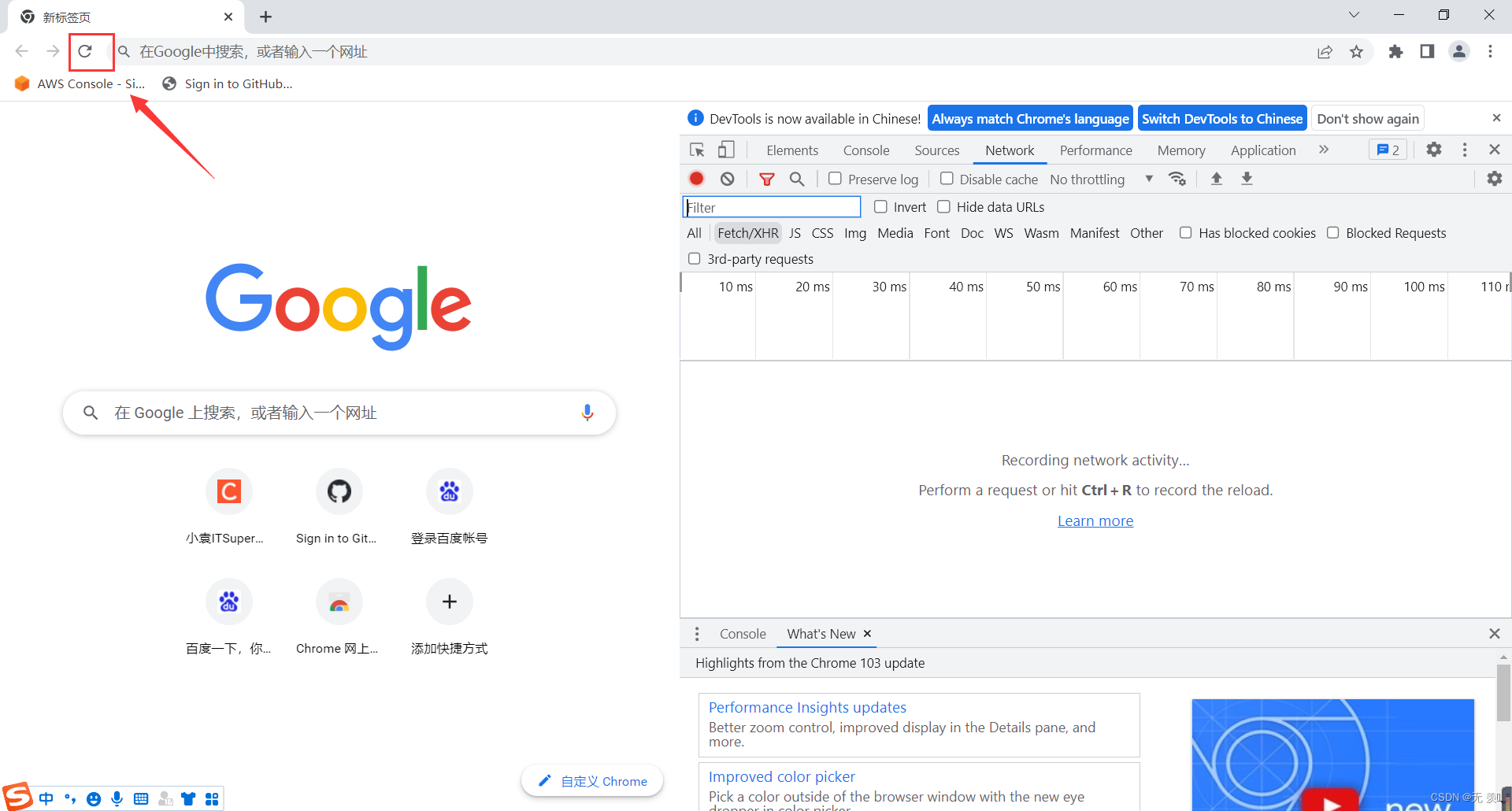
- 1. 打开谷歌浏览器 》右键检查 》点击左上角刷新网页
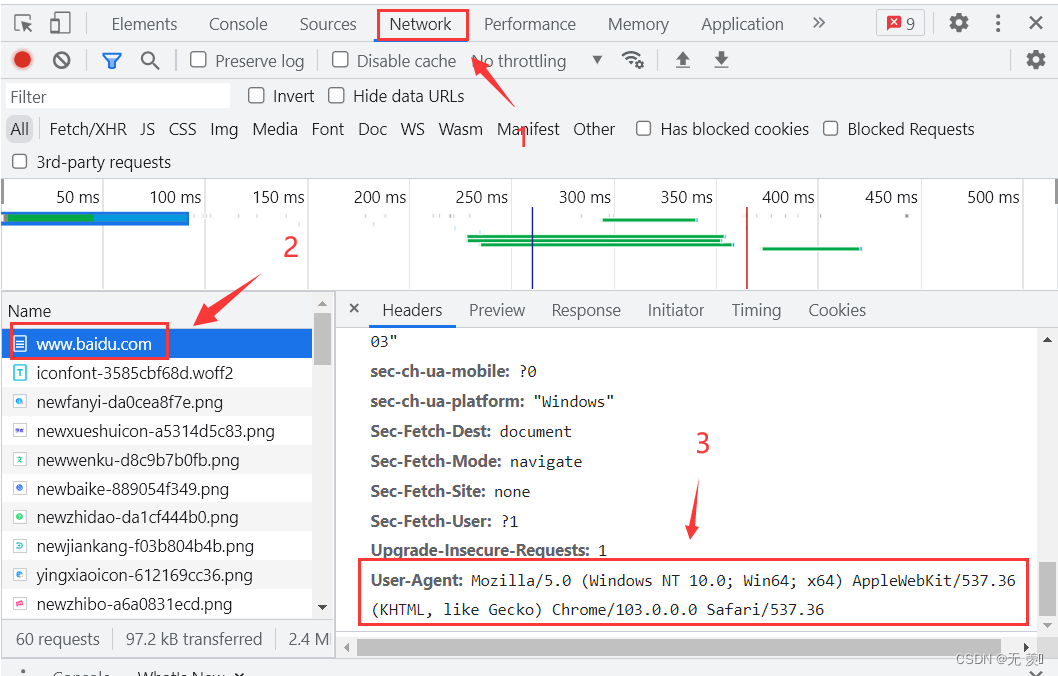
- 2. 点击Network 》找到对应的网址 》往下翻找到User-Agent并复制
2)代码说明
requests.get(ur1, headers=headers)- 1
- headers参 数接收字典形式的请求头
- 请求头字段名作为key,字段对应的值作为value
3)代码实现:
import requests # 目标网址 url = "http://www.baidu.com/" # 构建请求头字典,最重要的就是User-Agent # 如果需要其他请求头,就在headers字典中加上 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'} # 发送请求获取响应 response = requests.get(url,headers=headers) print(response.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
运行结果:整个网页源码:
5. 发送带参数请求
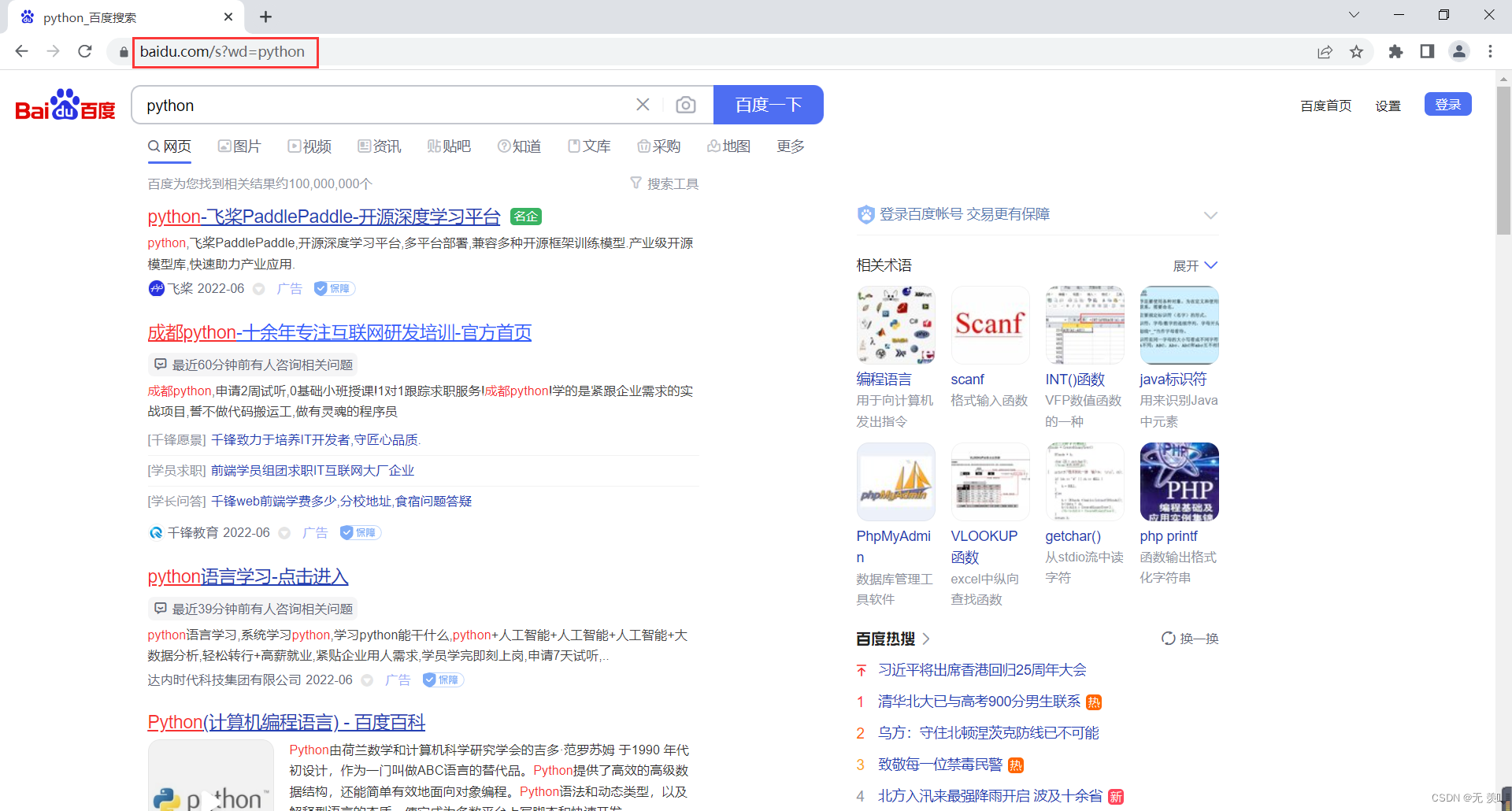
如何删除网页地址中多余参数?
- 百度搜:python,可以看到url地址特别复杂

- 通过一个一个删除参数并刷新,最终得到
第一种方法:网址中带参数
import requests # 目标网址 url = "https://www.baidu.com/s?wd=python" headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'} # 发送请求获取响应 response = requests.get(url,headers=headers) print(response.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
第二种方式:通过
params构造参数字典import requests # 目标网址 url = "https://www.baidu.com/s?" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'} # 请求参数是一个字典 kw = {'wd': 'python'} # 发送请求的时候设置参数字典,获取响应 response = requests.get(url, headers=headers, params=kw) print(response.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
6. 在headers参数中携带cookie
网站经常利用请求头中的Cookie字段来做用户访问状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求。Cookie具有时效性过一段时间需要更换
-
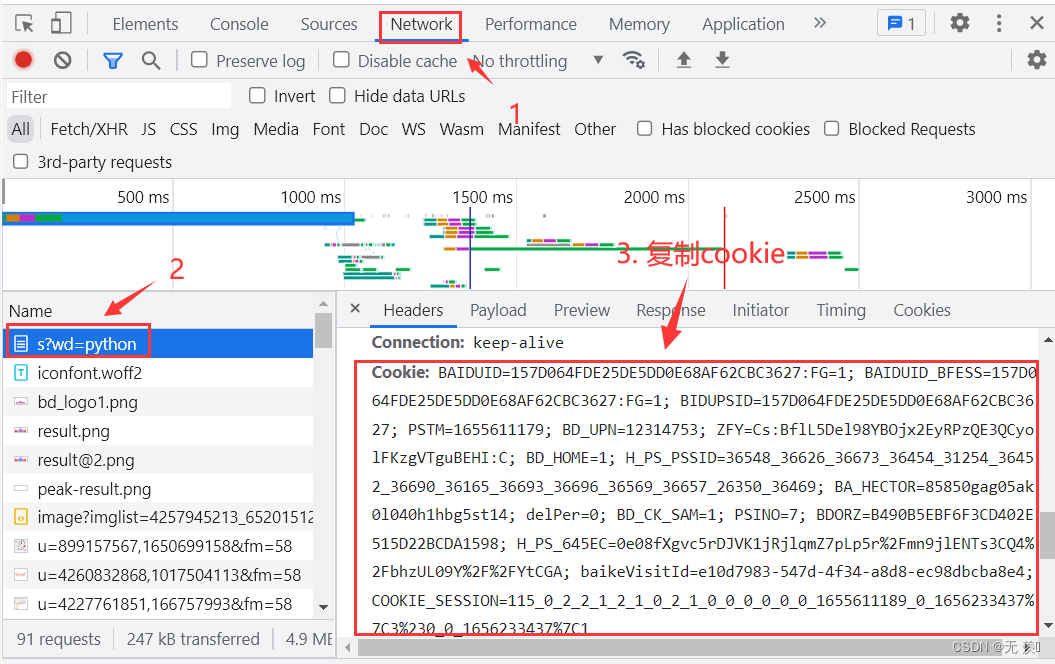
1. 打开谷歌浏览器 》右键检查 》点击左上角刷新网页
-
2. 点击Network 》找到对应的网址 》往下翻找到
Cookie并复制
-
3. 在headers字典中添加
cookie参数headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36', 'Cookie': 'BAIDUID=157D064FDE25DE5DD0E68AF62CBC3627:FG=1; BAIDUID_BFESS=157D064FDE25DE5DD0E68AF62CBC3627:FG=1; BIDUPSID=157D064FDE25DE5DD0E68AF62CBC3627; PSTM=1655611179; BD_UPN=12314753; ZFY=Cs:BflL5Del98YBOjx2EyRPzQE3QCyolFKzgVTguBEHI:C; BD_HOME=1; H_PS_PSSID=36548_36626_36673_36454_31254_36452_36690_36165_36693_36696_36569_36657_26350_36469; BA_HECTOR=85850gag05ak0l040h1hbg5st14; delPer=0; BD_CK_SAM=1; PSINO=7; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_645EC=0e08fXgvc5rDJVK1jRjlqmZ7pLp5r%2Fmn9jlENTs3CQ4%2FbhzUL09Y%2F%2FYtCGA; baikeVisitId=e10d7983-547d-4f34-a8d8-ec98dbcba8e4; COOKIE_SESSION=115_0_2_2_1_2_1_0_2_1_0_0_0_0_0_0_1655611189_0_1656233437%7C3%230_0_1656233437%7C1' }- 1
- 2
- 3
- 4
7. 超时参数timeout的使用
在平时网.上冲浪的过程中,我们经常会遇到网络波动,这个时候,一个请求等了很久可能任然没有结果。在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错。
1.超时参数timeout的使用方法
response = requests.get(ur1, timeout=3)- 1
2. timeout=3 表示:发送请求后,3秒钟内返回响应,否则就抛出异常
3. 实战代码:
import requests # 目标网址 url = "https://www.baidu.com/" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36' } try: response = requests.get(url, headers=headers, timeout=10) # 超时设置为10秒 except: for i in range(4): # 循环去请求网站 response = requests.get(url, headers=headers, timeout=20) if response.status_code == 200: break html_str = response.text- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
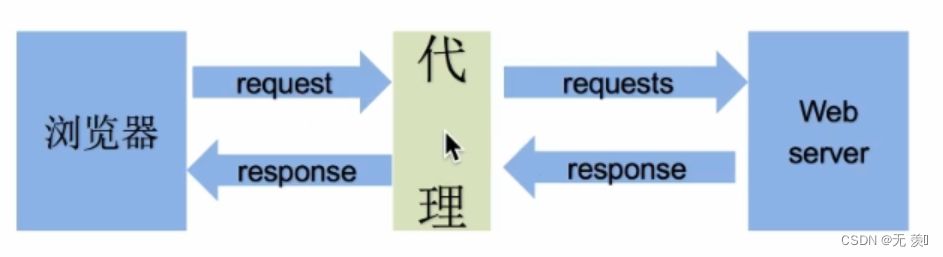
8. proxies代理参数的使用
为了让服务器以为不是同一个客户端在请求;为了防止频繁向一个域名发送请求被封ip,所以我们需要使用代理ip
语法:
response = requests.get(url, proxies=proxies)- 1
proxies的形式: 字典
proxies = { "http": "http://12.34.5679:9527", "https": "https://12.34.5679:9527", }- 1
- 2
- 3
- 4
注意:如果proxies字典中包含有多个键值对,发送请求时将按照ur地址的协议来选择使用相应的代理ip
9. 发送post请求
requests模块发送post请求函数的其它参数和发送get请求的参数完全一 致
语法格式:
response = requests.post(url, data) # data参数接收一个字典- 1
如何找到data表单?
-
以百度翻译为例:找到对应的请求,点击Payload,展开Form data表单

-
代码中构造data字典
import requests url = "https://fanyi.baidu.com/" data = { 'query': '爱' } response = requests.post(url) print(response.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
返回完整的网页
-
-
相关阅读:
jeesite实现excel导入功能(保姆级图文教程)
取代 Mybatis Generator,这款代码生成神器配置更简单,开发效率更高!
前端入职配置新电脑!!!
如何找到攻击数据包中的真实IP地址?
240701_昇思学习打卡-Day13-Vision Transformer图像分类
探索AI视频生成新纪元:文生视频Sora VS RunwayML、Pika及StableVideo——谁将引领未来
JDK安装配置
特斯拉全自动驾驶(FSD)系统发展与解析
你写过的最蠢的代码是?——后端篇
医疗IT系统安科瑞隔离电源装置在医院的应用
- 原文地址:https://blog.csdn.net/yuan2019035055/article/details/125469852
