-
Java回顾-Collection-Set-HashSet/LinkedHashSet/TreeSet的对比
一、Set集合
1.Set接口的框架:
|----Collection接口:单列集合,用来存储一个一个的对象
|----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”
|----HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值
|----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历,对于频繁的遍历操作,LinkedHashSet效率高于HashSet.
|----TreeSet:可以按照添加对象的指定属性,进行排序。1. Set接口中没有额外定义新的方法,使用的都是Collection中声明过的方法。
2. 要求:1)向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()
2)重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
3)重写两个方法的小技巧:对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。2.无序性、不可重复性
1.无序性:-不等于随机性!存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据哈希值
2.不可重复性:保证添加的元素按照equals()判断时不能返回true,即相同的元素只能添加一个
三.HashSet原理简析
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),我们需要判断: 数组此位置上是否已经有元素?
1.此位置没有其他元素,则元素a添加成功-情况一
2.此位置上有其他元素b,或以链表形式存在多个元素,则比较元素a与b的hash值,
若hash值不相同则添加成功;-情况二
3.若hash值相同,则调用元素a所在类的equals()方法:
equals() 返回true,则a添加失败
equals() 返回false,则a添加成功-情况三
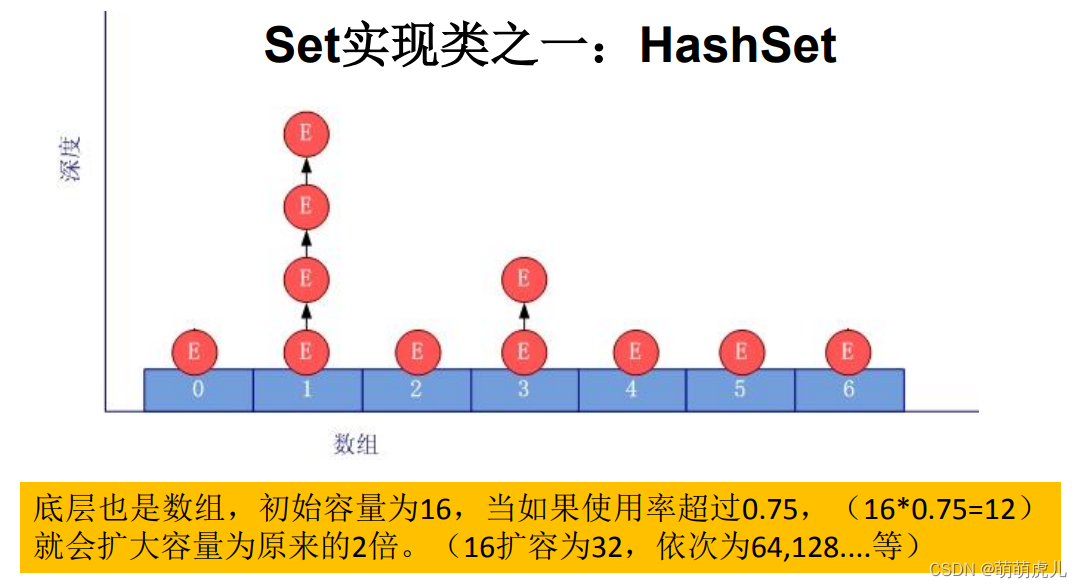
-对于添加成功的情况2和情况3而言:元素a与已经存在指定索引位置上数据以链表的方式存储。在jdk 8 :原来的元素在数组中,指向元素a。HashSet底层就是数组+链表的结构。
注:其实Set底层调用了HashMap的结构,只是元素都赋给了key,把value屏蔽掉了,所有元素的value都等于一个new出来的无意义对象。
四、LinkedHashSet原理简析
与HashSet类似,不同之处在于,在添加数据的同时,每个数据还添加了两个引用,记录此数据的前一个数据和后一个数据,这使得元素看起来是以插入顺序保存的

五、TreeSet原理简析
-向TreeSet中添加的数据,必须是相同类的对象
-如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口
-TreeSet和后面要讲的TreeMap采用红黑树的存储结构

-特点:有序,查询速度比List快
-遍历时要指定排序方式。两种排序方式:自然排序(实现Comparable接口)、定制排序(Comparator)。默认是自然排序
1.自然排序
比较两个对象是否相同的标准为:compareTo()返回0.不再是equals().
当需要把一个对象放入 TreeSet 中,重写该对象对应的 equals() 方法时,应保证该方法与 compareTo(Object obj) 方法有一致的结果:如果两个对象通过 equals() 方法比较返回 true,则通过 compareTo(Object obj) 方法比较应返回 0
- //按照姓名从大到小排列,年龄从小到大排列
- @Override
- public int compareTo(Object o) {
- if(o instanceof User){
- User user = (User)o;
- int compare = -this.name.compareTo(user.name);//比较名字
- if(compare != 0){
- return compare;
- }else{
- return Integer.compare(this.age,user.age);//名字相等就按年龄排序
- }
- }else{
- throw new RuntimeException("输入的类型不匹配");
- }
- }
- @Override
- public boolean equals(Object o) {
- System.out.println("User equals()....");
- if (this == o) return true; //是同一个对象
- if (o == null || getClass() != o.getClass()) return false;//不是一个类的
- User user = (User) o;
- if (age != user.age) return false;//比较年龄
- return name != null ? name.equals(user.name) : user.name == null;//比较名字
- }
- @Override
- public int hashCode() { //return name.hashCode() + age;
- int result = name != null ? name.hashCode() : 0;
- result = 31 * result + age;
- return result;
- }
为什么计算hashcode的时候乘31呢?
选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的 “冲突”就越少,查找起来效率也会提高。(减少冲突)
并且31只占用5bits,相乘造成数据溢出的概率较小。
31可以 由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化。(提高算法效率)
31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有1来整除!(减少冲突)
2.定制排序比较两个对象是否相同的标准为:compare()返回0.不再是equals().
如果元素所属的类没有实现Comparable接口,或不希望按照升序(默认情况)的方式排列元素或希望按照 其它属性大小进行排序,则考虑使用定制排序。
利用int compare(T o1,T o2)方法,比较o1和o2的大小:如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2。
要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器
- //按照年龄从小到大排列
- @Override
- public int compare(Object o1, Object o2) {
- if(o1 instanceof User && o2 instanceof User){
- User u1 = (User)o1;
- User u2 = (User)o2;
- return Integer.compare(u1.getAge(),u2.getAge());
- }else{
- throw new RuntimeException("输入的数据类型不匹配");
- }
- }
-
相关阅读:
2024全国水科技大会暨高氨氮废水厌氧氨氧化处理技术论坛(四)
华为研发工程师编程题
09 Ubuntu安装FreeCAD
C/C++文档编辑器
sd卡视频被删怎么恢复呢?
React 入门:key 的作用及使用方法技巧
mysql之order by工作原理
个人前端编程技巧总结
Vue2项目练手——通用后台管理项目第六节
『力扣每日一题10』:字符串中的单词数
- 原文地址:https://blog.csdn.net/weixin_62427168/article/details/125469640
