-
图 - 06 关键路径
写在前面:
我们上一讲详细的讲述了拓扑排序的实现,为了就是给这一讲打下基础,因为这一讲我们将会讲关键路径,它就要用到拓扑排序的知识。什么是关键路径?
关键路径和最短路径不同,它反而去找最长路径,这种意义何在呢,我们来看个例子。
假设小明小王小李参与一个大项目,这个大项目需要他们三个共同完成,也就是说这三人缺一人这项目都完成不了。现在这个大项目上面规定他们在半年内完成,假如小明小李分到的任务比较轻,在截止日期前就完成了,但是小王的任务比较难,快到期了都还没完成。这时候就算小明小李完成了这个大项目仍然无法提交,需要等小王那一部分完成了才可以提交,换句话说这个大项目最终花费的时间由完成时间最久的小王来决定。
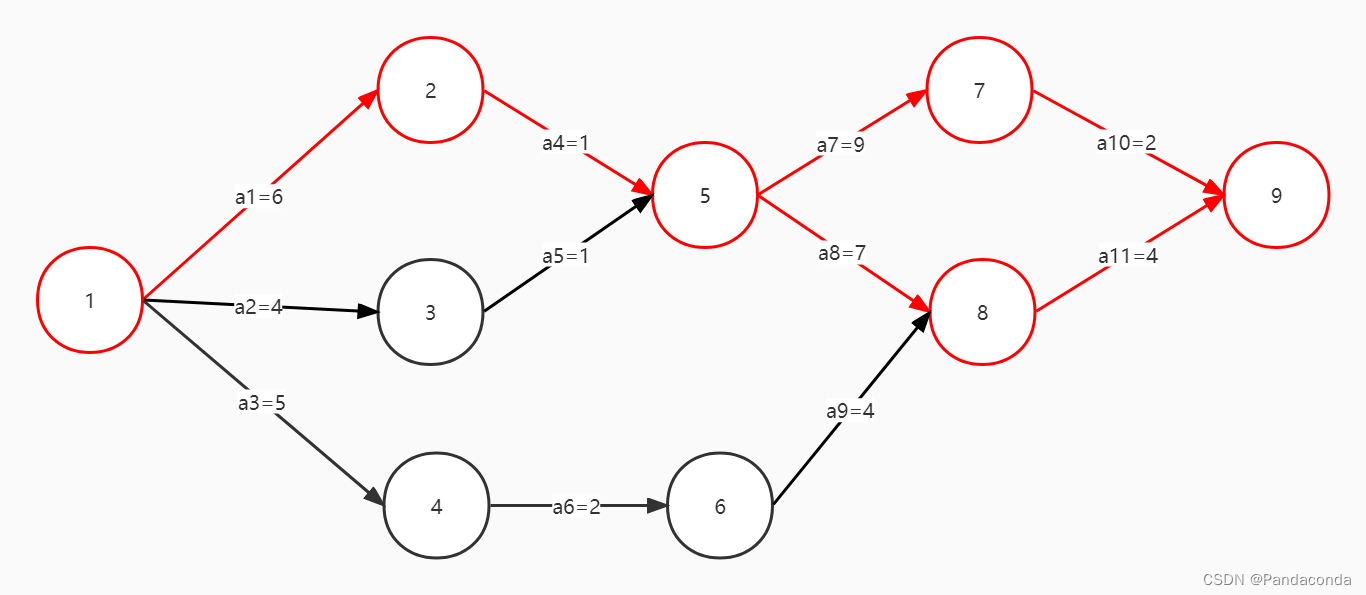
还是拿图来说话,下列事件 9 需要由事件 1 开始,等待 11 个活动全部发生才能到达。所以可以发现,到达事件 9 所需要花费的最长时间就是 6 + 1 + 9 + 2 = 18 。
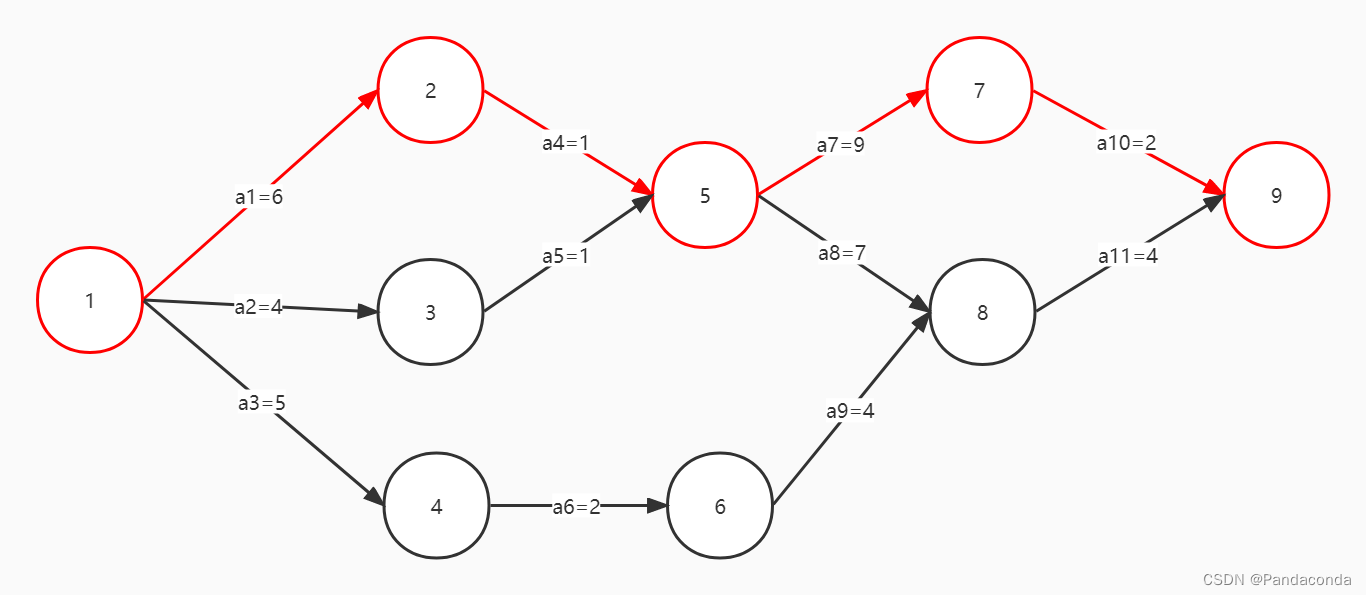
所以关键路径就是要找到那一条花费最多的路径,其实上面这个例子就已经体现了关键路径在我们日常生活中的应用了。
前置知识
ETV
ETV(Earliest Time Of Vertex): 事件最早发生时间,就是结点的最早发生时间。
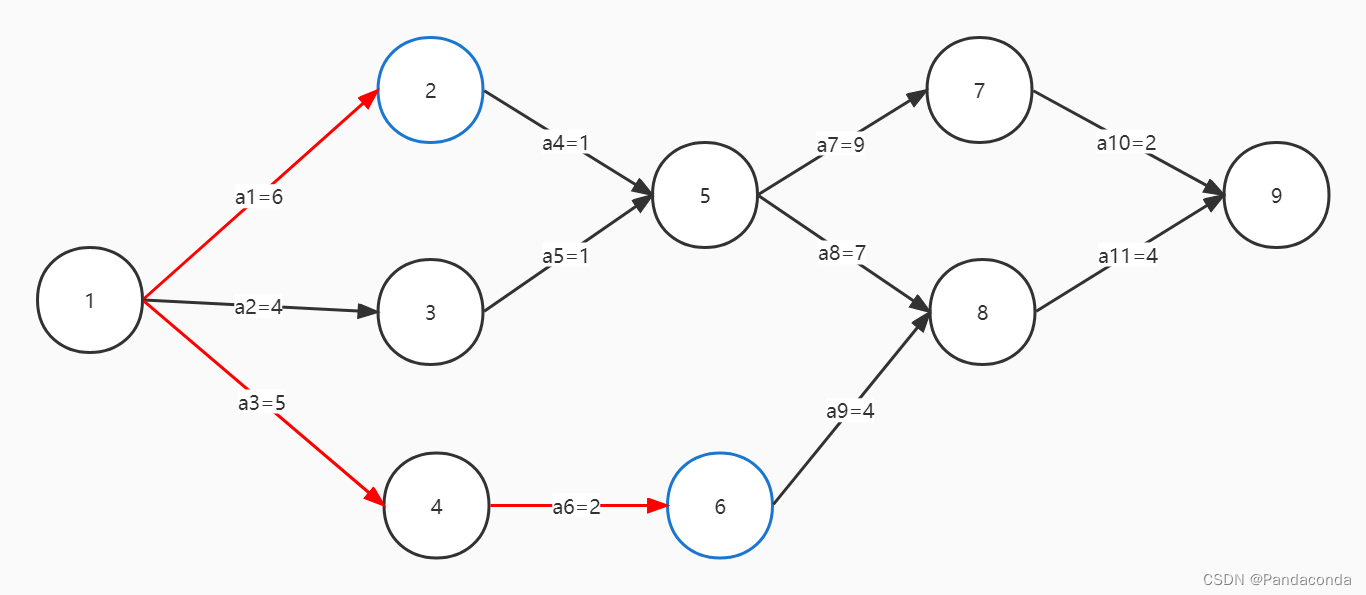
上图中,事件 2 最早开始时间就是 6 ,表示只有当活动 a1 发生之后才能开始事件 2 ;同理事件 6 则需要活动 a5 和 a6 都发生了才能开始,故其最早开始时间就是 2 + 5 = 7 。需要注意的是,事件的最早发生时间一定是从源点到该结点进行计算的。
另外,最早发生时间并不是说最短路径,比如上面的事件 5 ,要等待活动 a4 和 a5 都完成后才能开始,所以它的最早发生时间反而是取最长的路径即 6 + 1 = 7 ,这里需要注意一下,很容易绕晕。
LTV
LTV(Latest Time Of Vertex): 事件最晚发生时间,就是每个结点对应的事件最晚需要开始的时间,如果超出此时间将会延误整个工期。
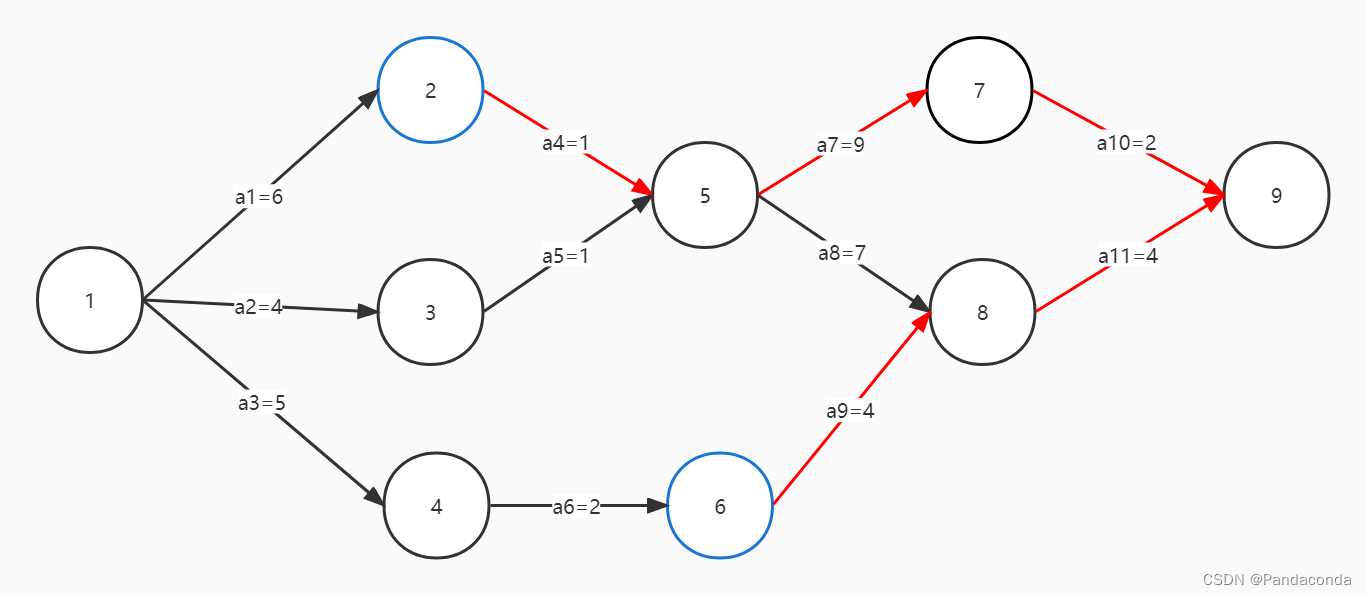
上面得到的关键路径是(1 , 2 , 5 , 7 , 9)且长度为 18 ,之所以要提这个是因为计算最晚发生时间要用到这个。上面计算最早发生时间是从源点开始计算,而这里则是从终点倒推回去进行计算。
上图中,事件 2 的最晚发生时间是 18 - 2 - 9 - 1 = 6 ,咋一看好像和最早发生时间一毛一样,这是因为在关键路径上的事件的最早发生时间是等于最晚发生时间的,这有什么用呢,我们再来看一个事件。
事件 6 的最晚发生时间是 18 - 4 - 4 = 10 ,这就比它的最早发生时间要大了,也就是说事件 6 它完全可以放个 3 天假再去完成也能赶上事件 9 最晚发生的时间。
ETE
ETE(Earliest Time Of Edge): 活动的最早开工时间,就是弧的最早发生时间。
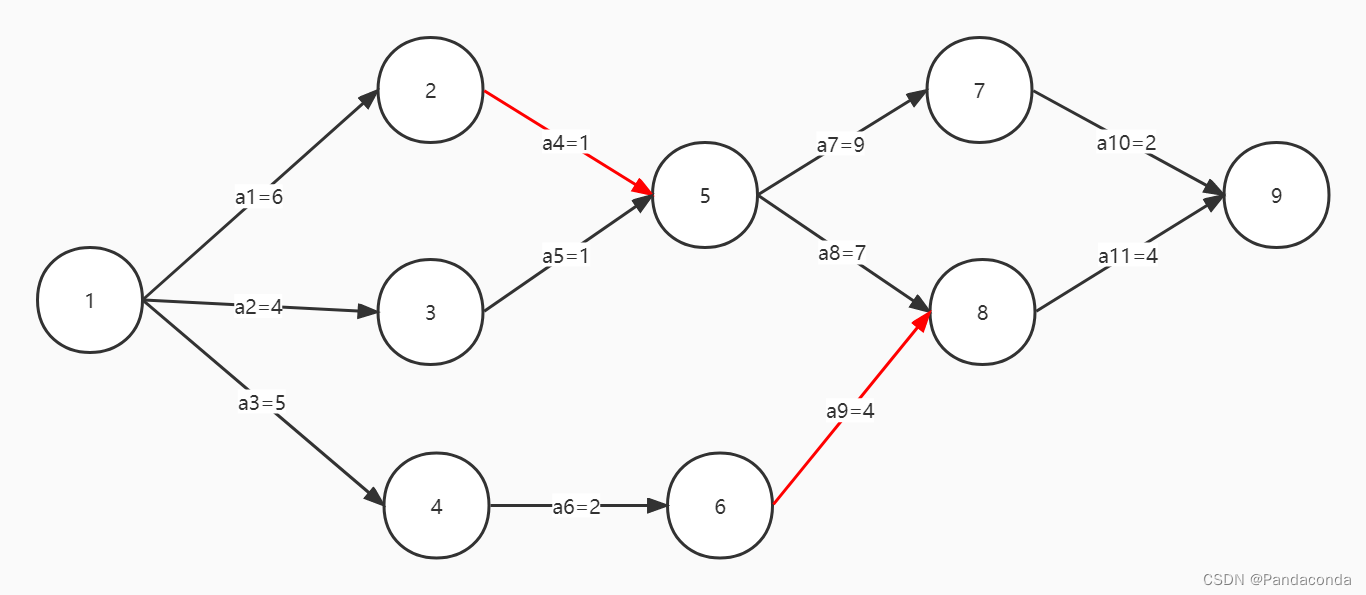
上图中,活动 a4 的最早开始时间是事件 2 的最早开始时间 6 ;同理,活动 a9 的最早开始时间是事件 6 的最早开始时间 7 。
不难发现,活动的最早开始时间就是事件的最早开始时间。
LTE
LTE(Lastest Time of Edge): 活动的最晚开工时间,就是不推迟工期的最晚开工时间。
上图中,活动 a4 的最晚发生时间是事件 5 的最晚发生时间减去 a4 所花费的时间即 7 - 1 = 6 ;同理活动 a9 的最晚发生时间是事件 8 的最晚发生时间减去 a9 所花费的时间即 14 - 4 =10 。
通过观察可以发现,只要我们计算出 ETV 和 LTV 就可以得到 ETE 和 LTE 。但是要注意的是,关键路径得到的是活动的集合,而不是事件的集合,所以在计算完ETV 和 LTV 后,还要计算 ETE 和 LTE 。
关键路径算法
关键路径的求得实际上就要用到刚刚讲的这四个概念 ETV ,LTV ,ETE ,LTE ,我们只需要最后判断 ETE 是否等于 LTE ,如果相等则是关键路径的一条,输出就好了。为了更清楚的讲解,我们还是从头开始一步步的画图来看。
忘了或不清楚拓扑排序的小伙伴可以回顾一下上一讲内容:
当然,为了更清楚讲解关键路径,我在这里还会带大家走一遍拓扑排序的步骤。
通过拓扑排序获得ETV
第一步:建立对应的邻接表。
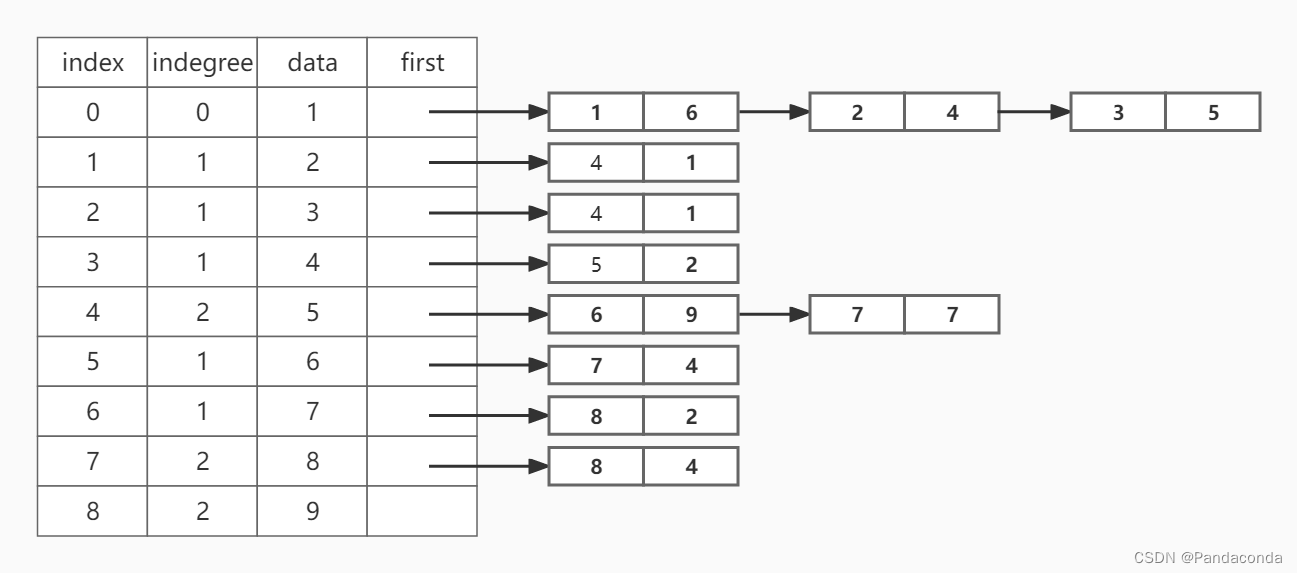
同时将 ETV 数组中的数据设为 0 。

第二步:将入度为 0 的结点 1 入栈。
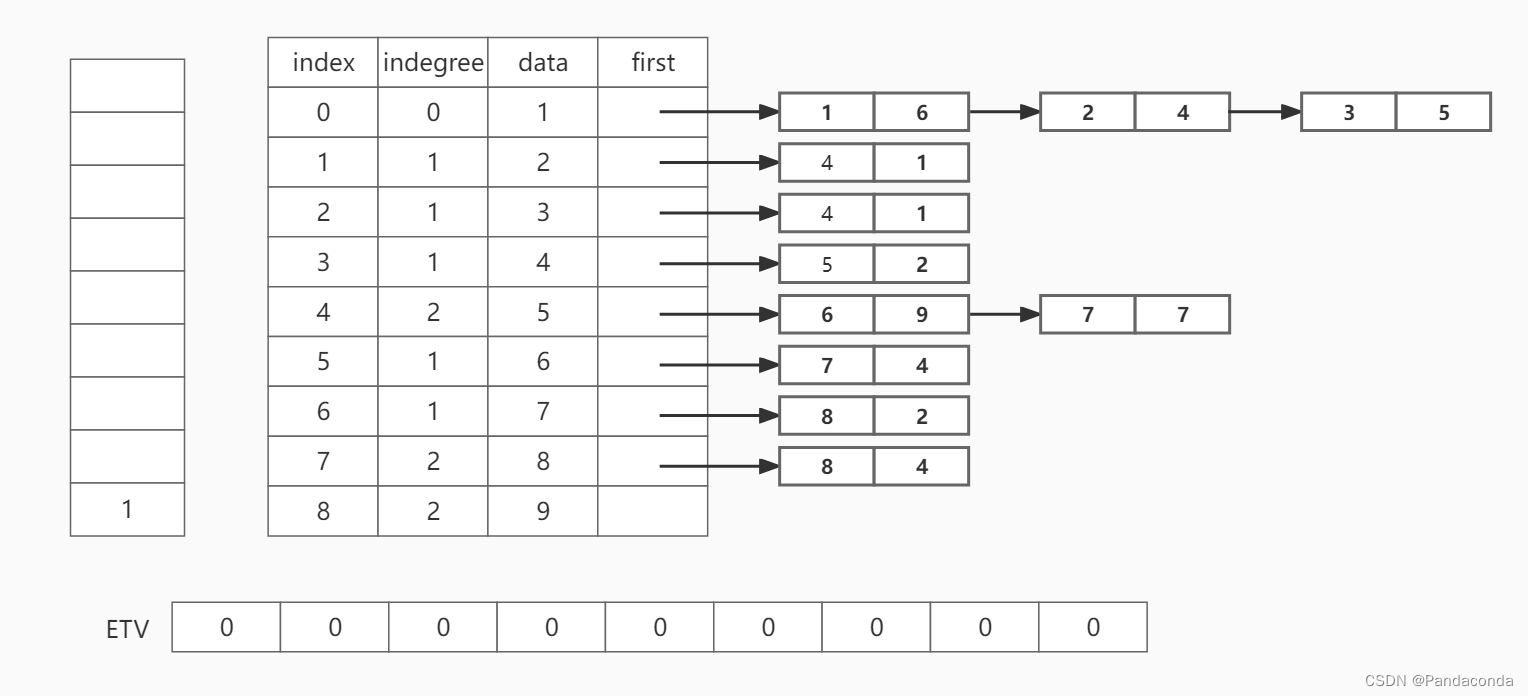
第三步:将结点 1 出栈,并遍历以它为尾的结点,即结点 2 ,结点 3 和结点 4 ,将它们的入度都减 1 ,并判断入度是否为 0 。
遍历 index = 1 的结点 2 ,将其入度减 1 ,发现为 0 则入栈,判断 ETV[0] + w(1,2) 是否大于 ETV[1] , 发现大于,则将 ETV[1] 更新为 ETV[0] + w(1,2) = 6;同理遍历 index = 2 的结点 3 ,将结点3入栈,并将 ETV[2] 更新为 4 ;遍历 index = 3 的结点 4 ,将结点 4 入栈,并将 ETV[3] 更新为 5 。
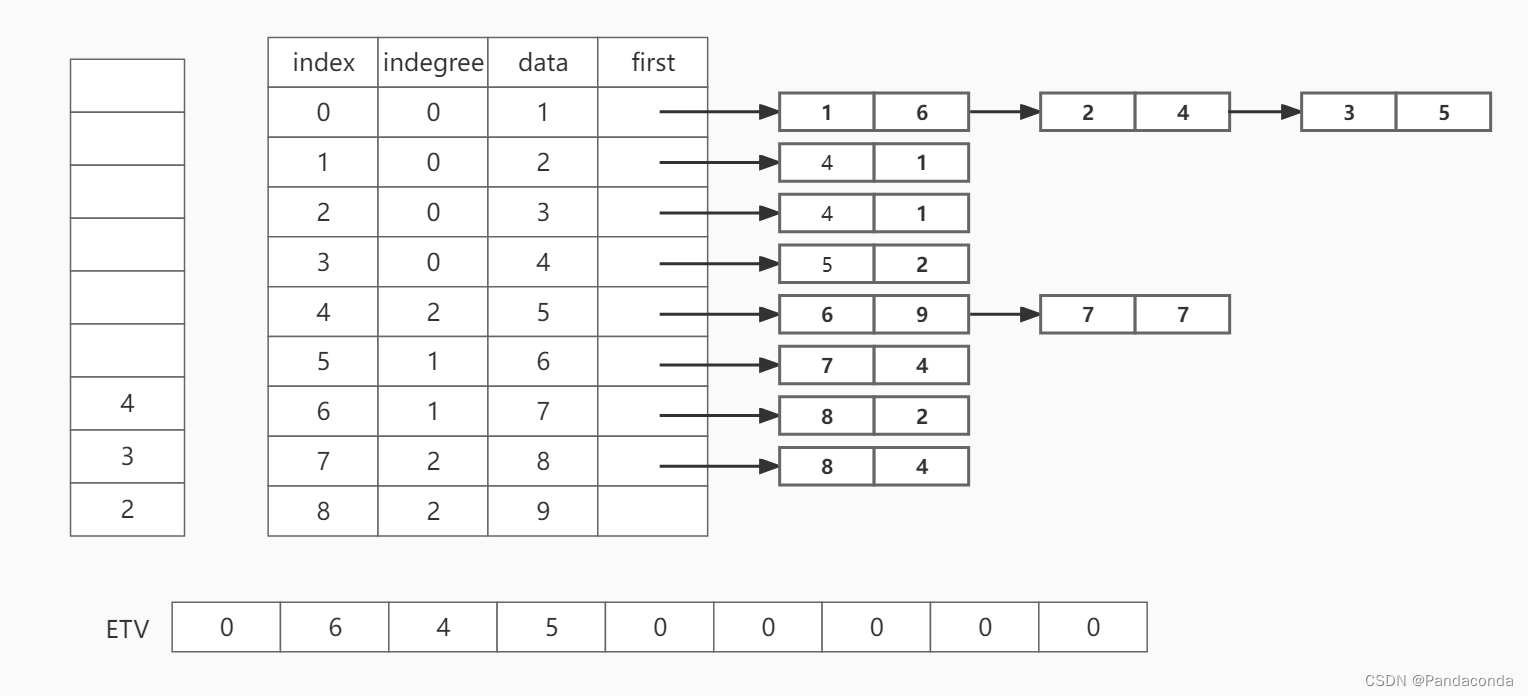
第四步:弹出栈顶元素 4 并遍历结点 4 的邻接结点 6 ,将结点 6 的入度减 1 ,并将 ETV[5] 更新为 ETV[3] + w(4,6),即为 7 。
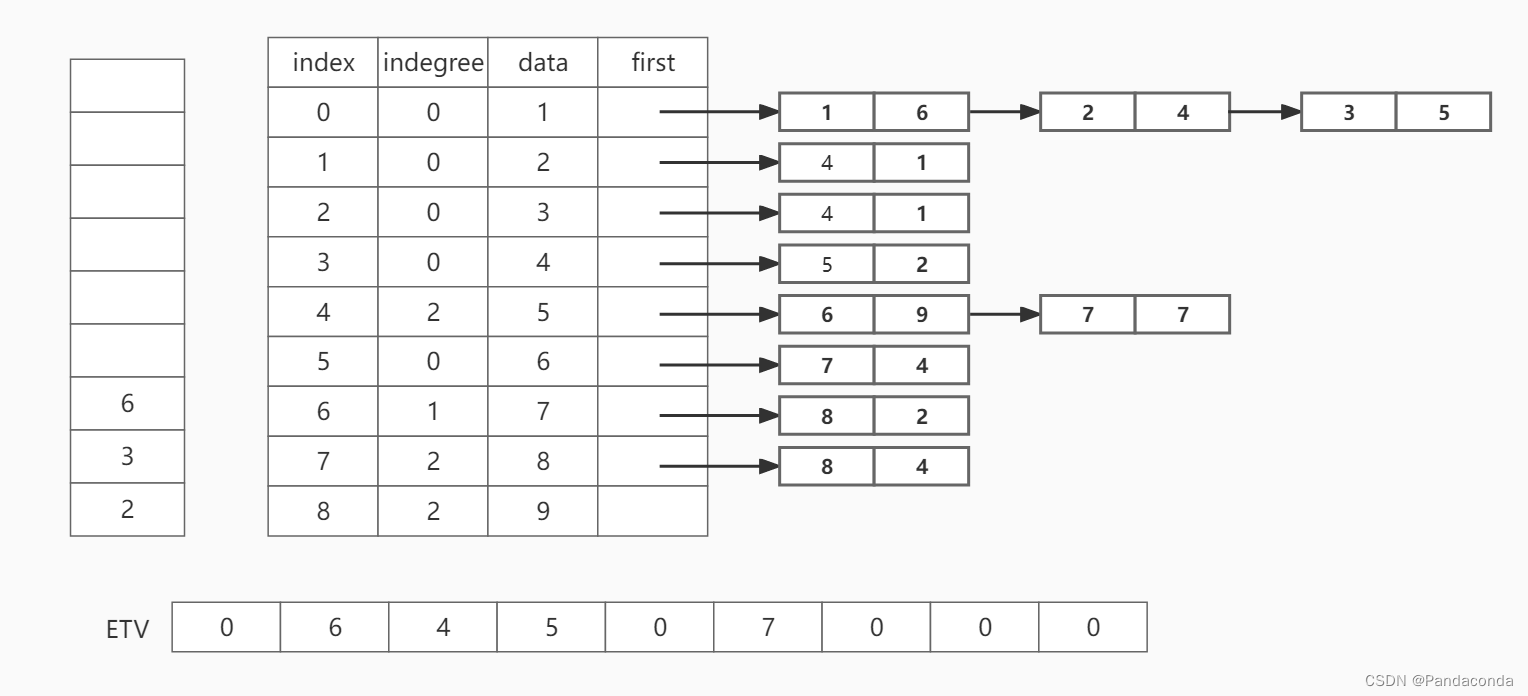
第五步:弹出栈顶元素 6 并遍历邻接结点 8 。
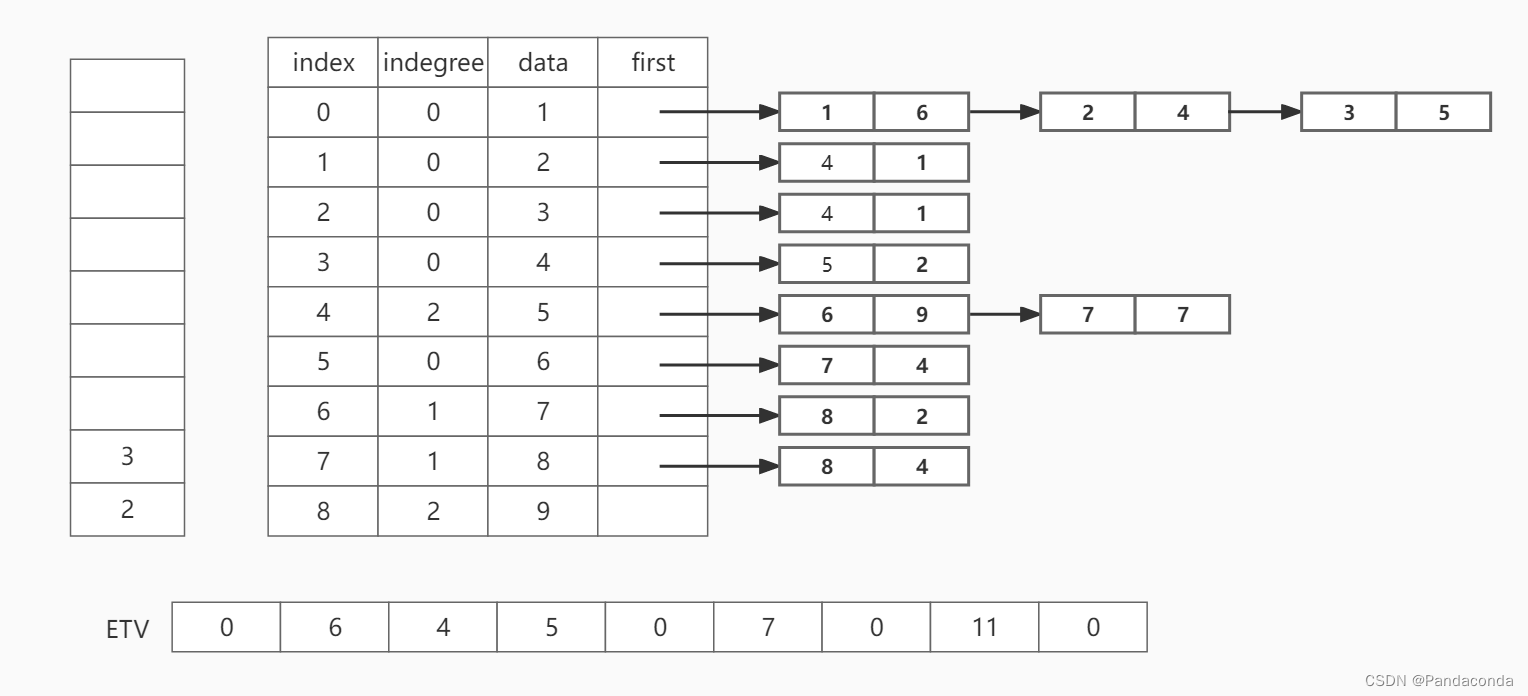
第六步:弹出栈顶元素 3 ,并遍历邻接结点 5 。
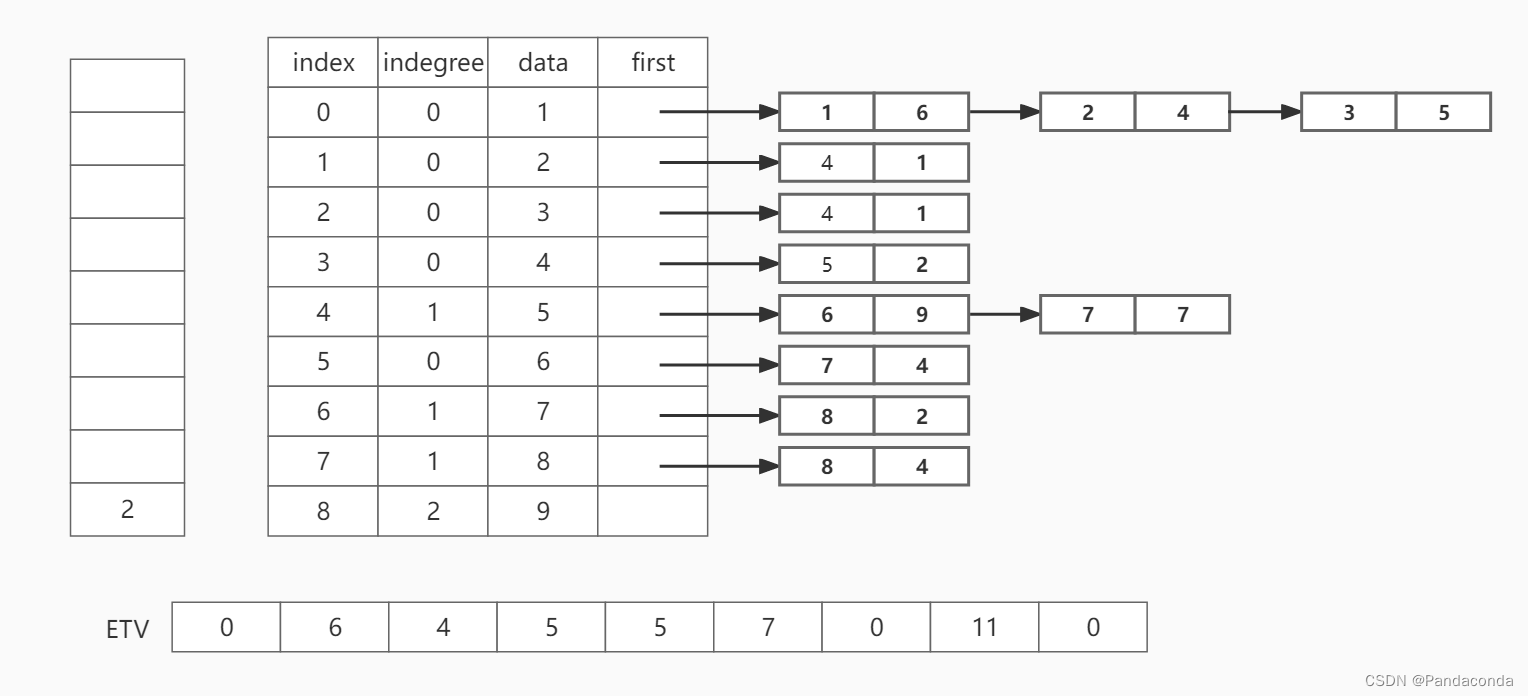
第七步:弹出栈顶元素 2,并遍历邻接结点 5 。
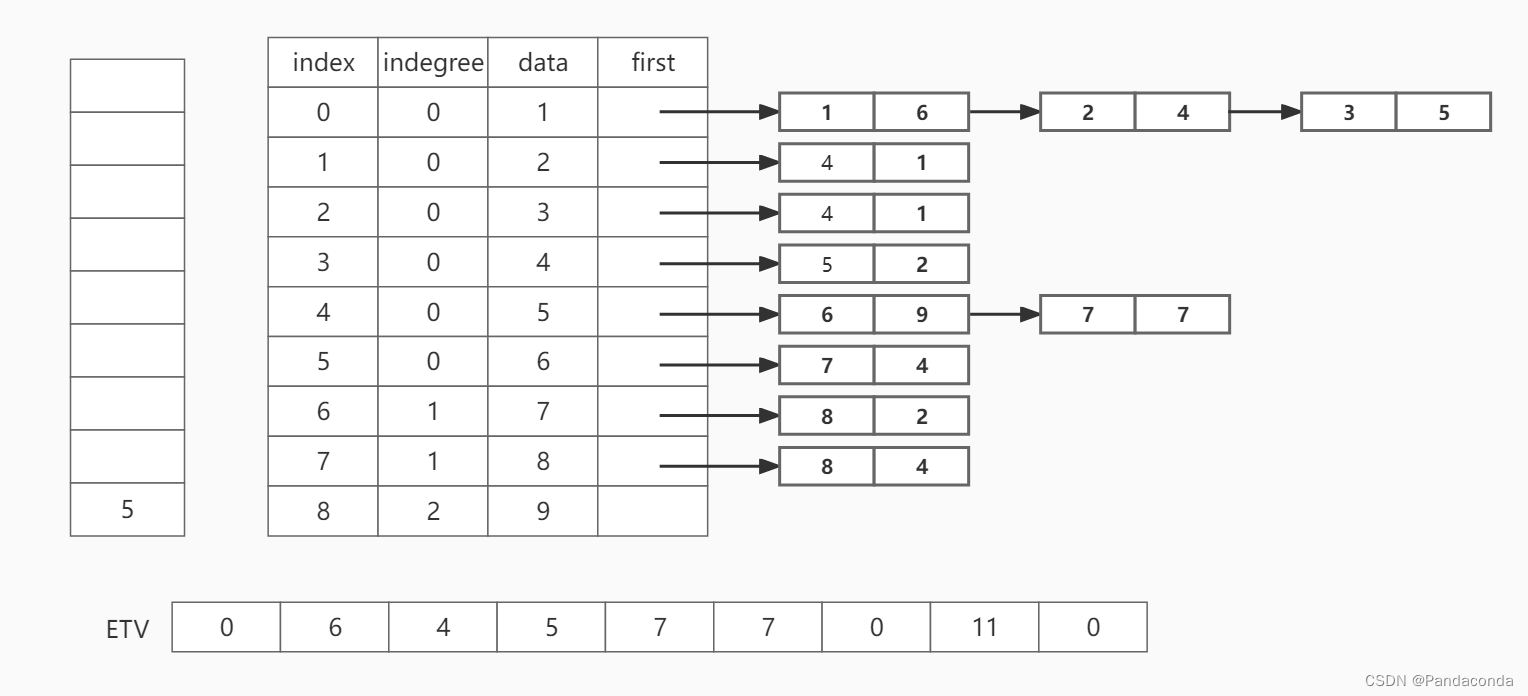
第八步:弹出栈顶元素 5 ,并遍历结点 5 的邻接结点 7和 结点 8 。
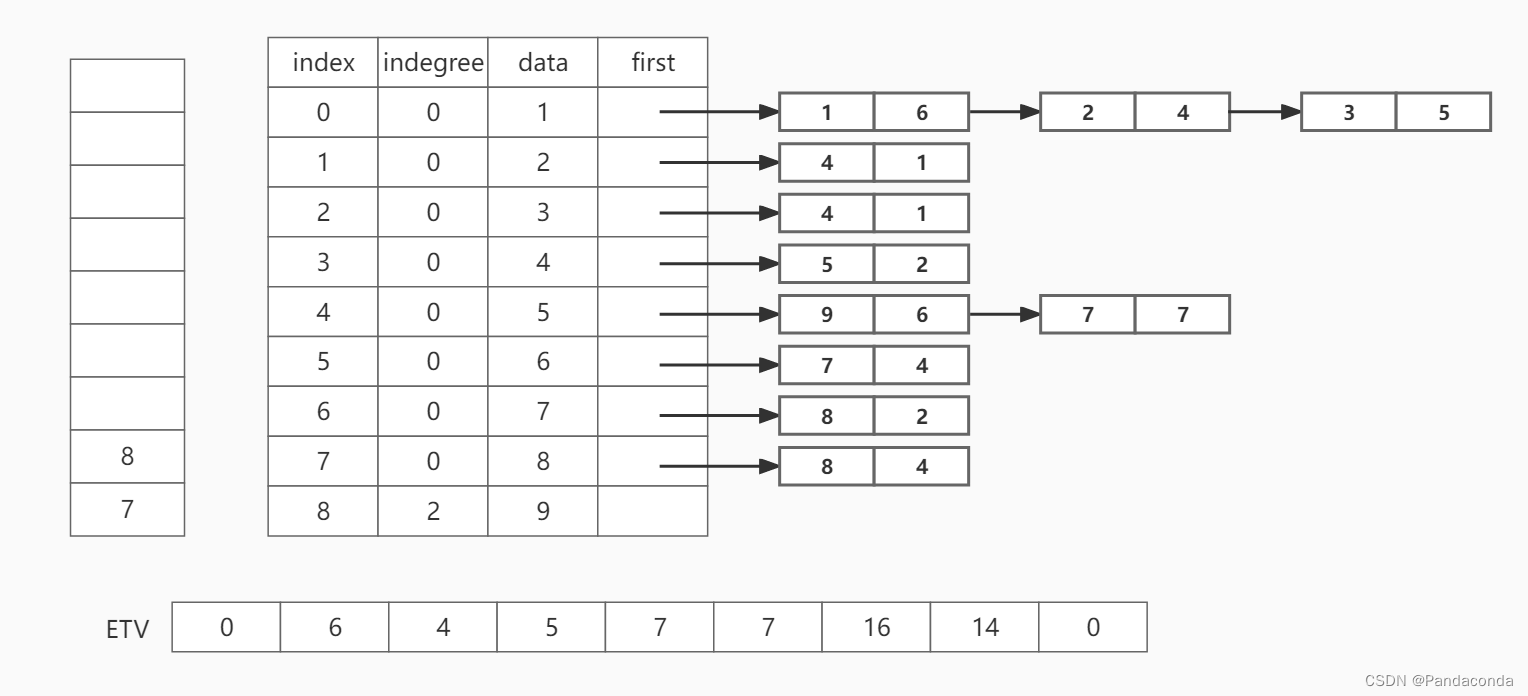
第九步:弹出栈顶元素 8 ,并遍历邻接结点 9 。
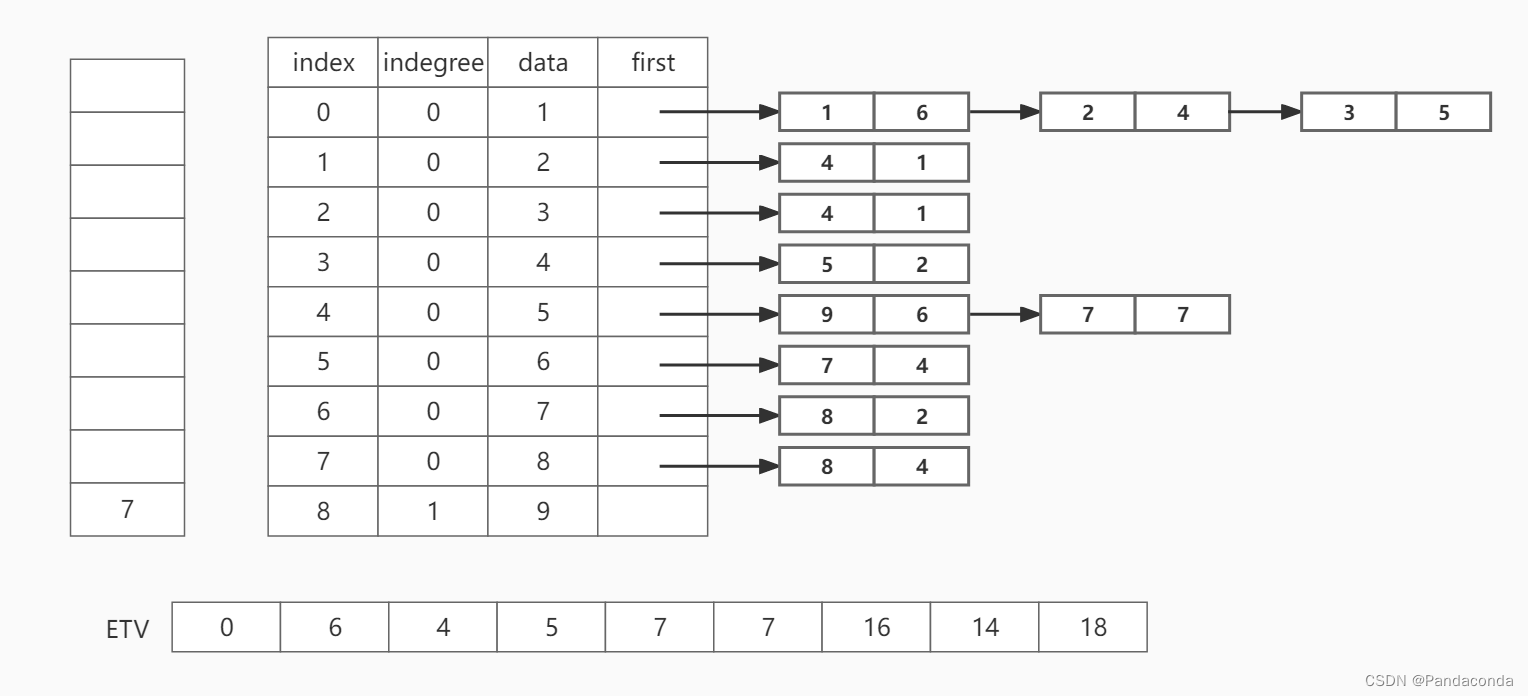
第十步:弹出栈顶元素 7 ,并遍历邻接结点 9 。
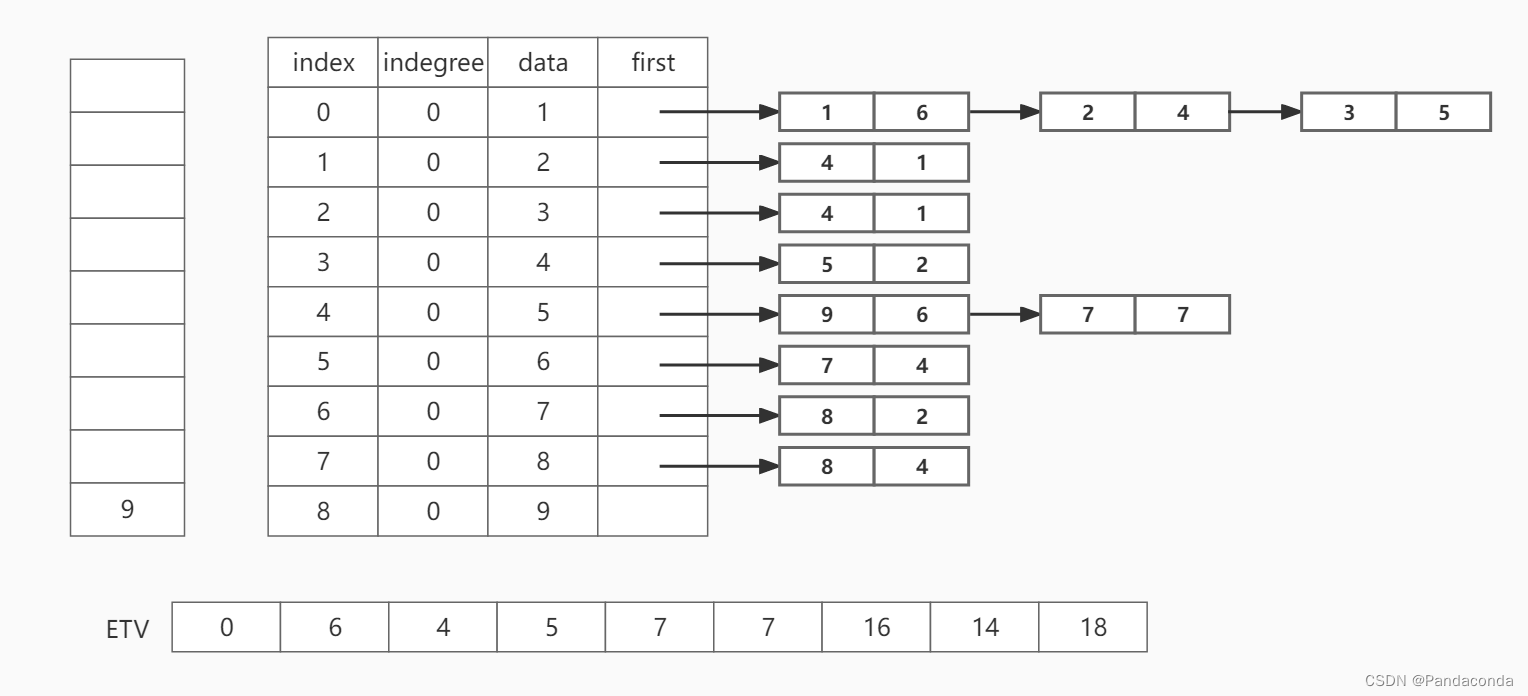
第十一步:将栈顶元素 9 出栈。
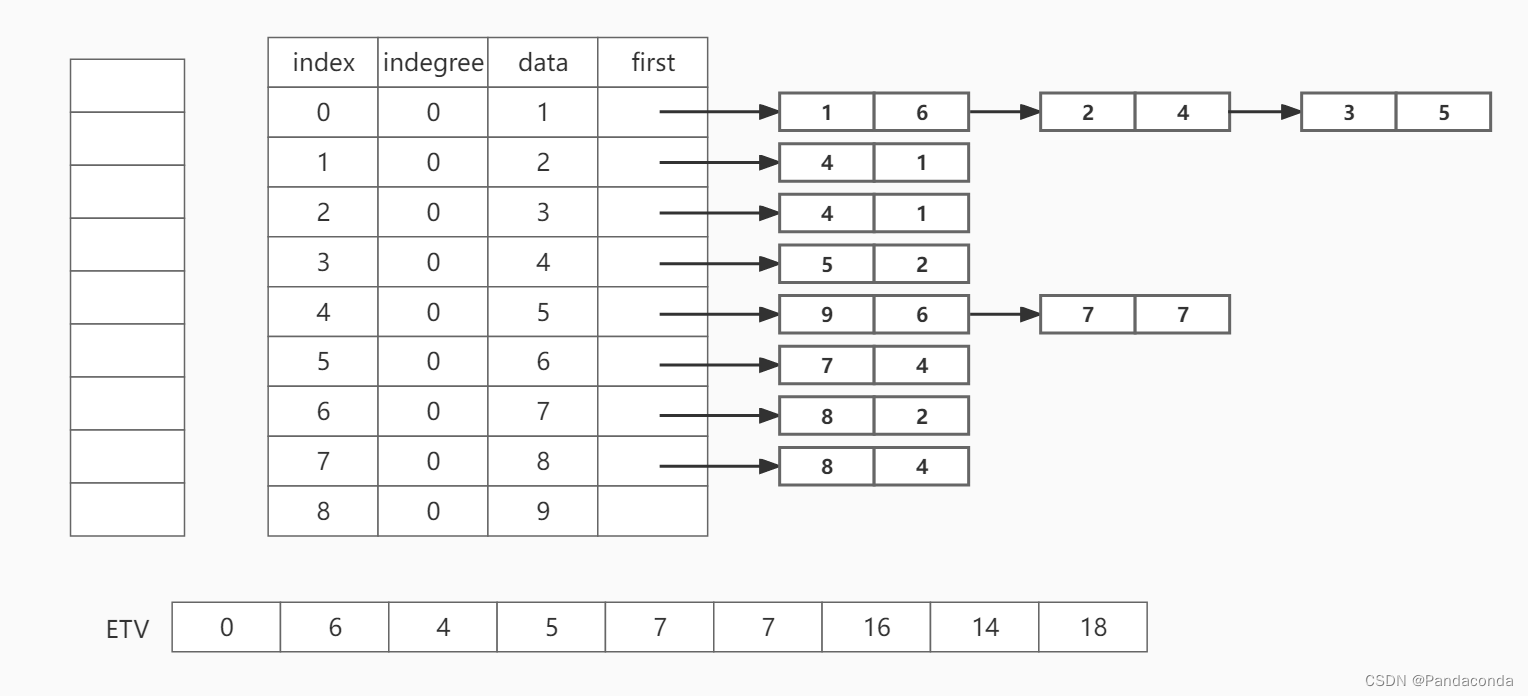
其中,我们将拓扑排序过程中的出栈序列依次入栈,即拓扑排序结束时,我们相应的保存了一个出栈序列(1 , 4 , 6 , 3 , 2 , 5 , 8 , 7 , 9),用于逆向计算事件的最晚发生时间:
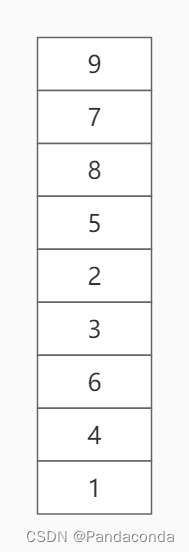
根据ETV推断LTV
上面我们得到了 ETV 的数组,现在可以开始计算 LTV 了,要计算每个结点的最晚开始时间,我们先将 LTV 数组所有元素初始化为到最终结点的时间 18 。

接着,我们就按照上面栈的顺序进行出栈操作。
第一步:将栈顶元素 9 出栈,什么事情都不用做。
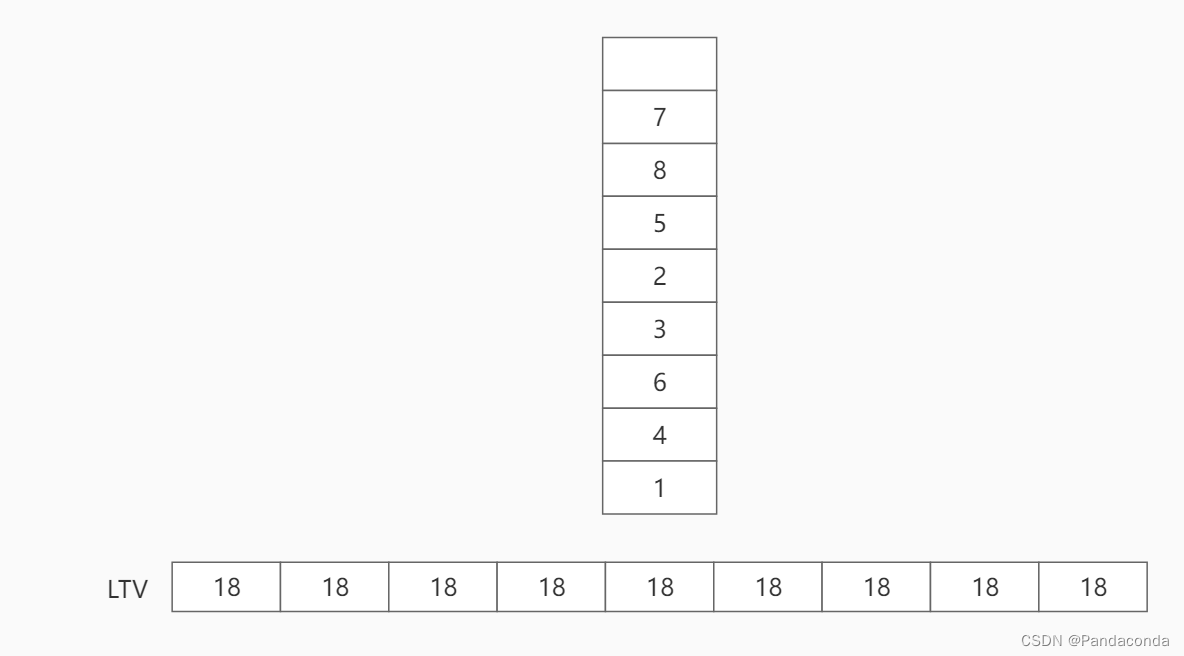
第二步:将结点 7 出栈,并判断 LTV[6] 与 LTV[8] - w(7, 9)的大小,将 LTV 更新为 LTV[8] - w(7, 9) = 16 。
因为是求最晚开始时间,所以我们从终点往前找最长的路径。由于我们已经知道了终点的开始时间是 18 ,故后面结点往前计算时要找最长的那条边,这样才能保证终点能在 18 开始。
试想一下,如果沿着较短的一条边回去当做前面结点的最晚开始时间,而该结点卡在这个最晚开始时间开始,就会导致该结点后面较长的一条边无法在 18 的时间内完成。这里有点绕,大家可以从图中终点往前计算试试。
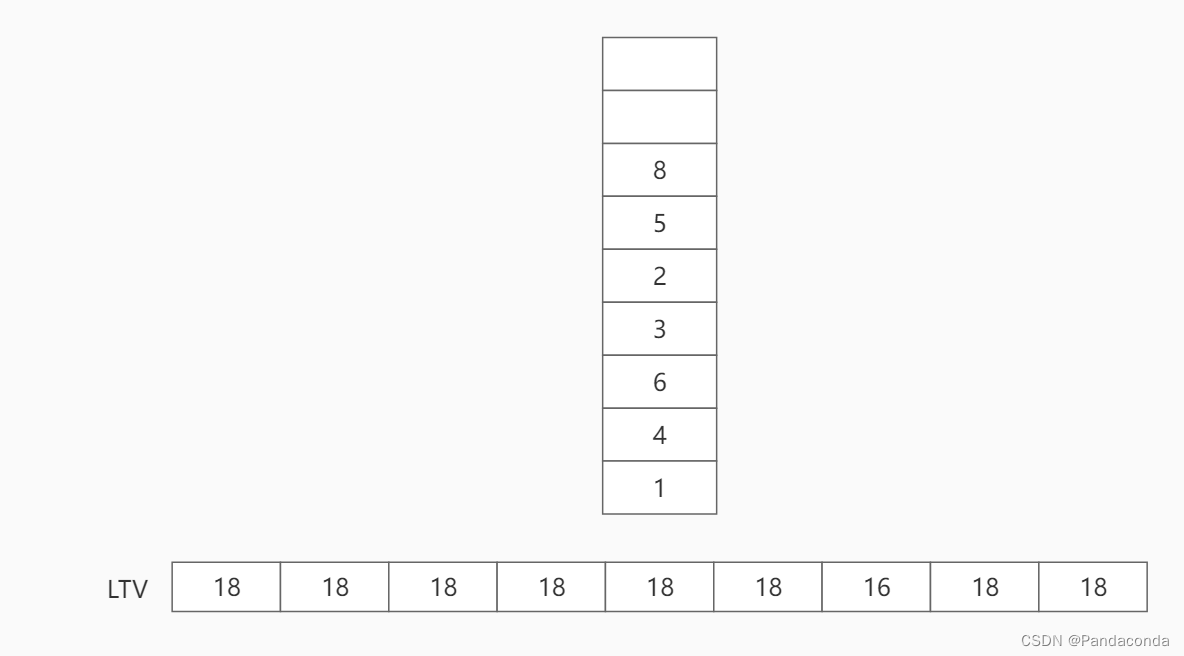
第三步:将结点 8 出栈,更新 LTV[7] 为 LTV[8] - w(8, 9)= 14。
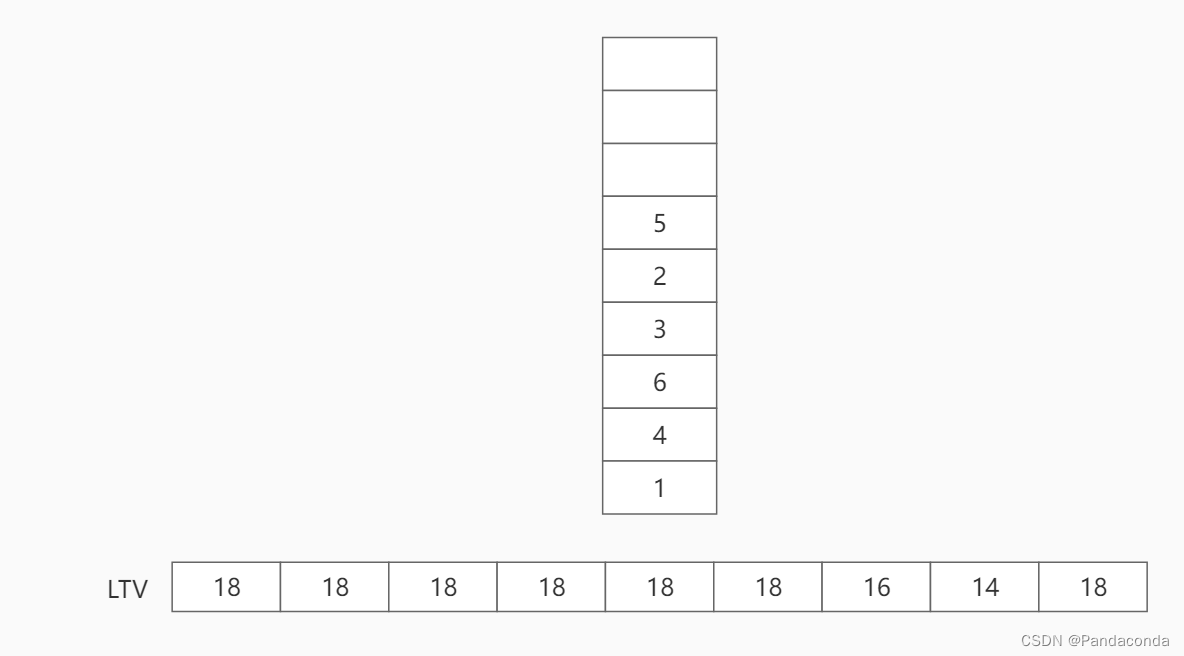
第四步:将结点 5 出栈,并遍历结点 5 的邻接结点 7 和 8 。用邻接结点 7 的 LTV 值减去活动 a7 的值,并与结点 5 的 LTV 值进行比较,将 LTV[4] 更新为 7 ;同理用邻接结点 8 的 LTV 值减去活动 a8 的值,并与结点 5 的值进行比较,发现相等不做更新。
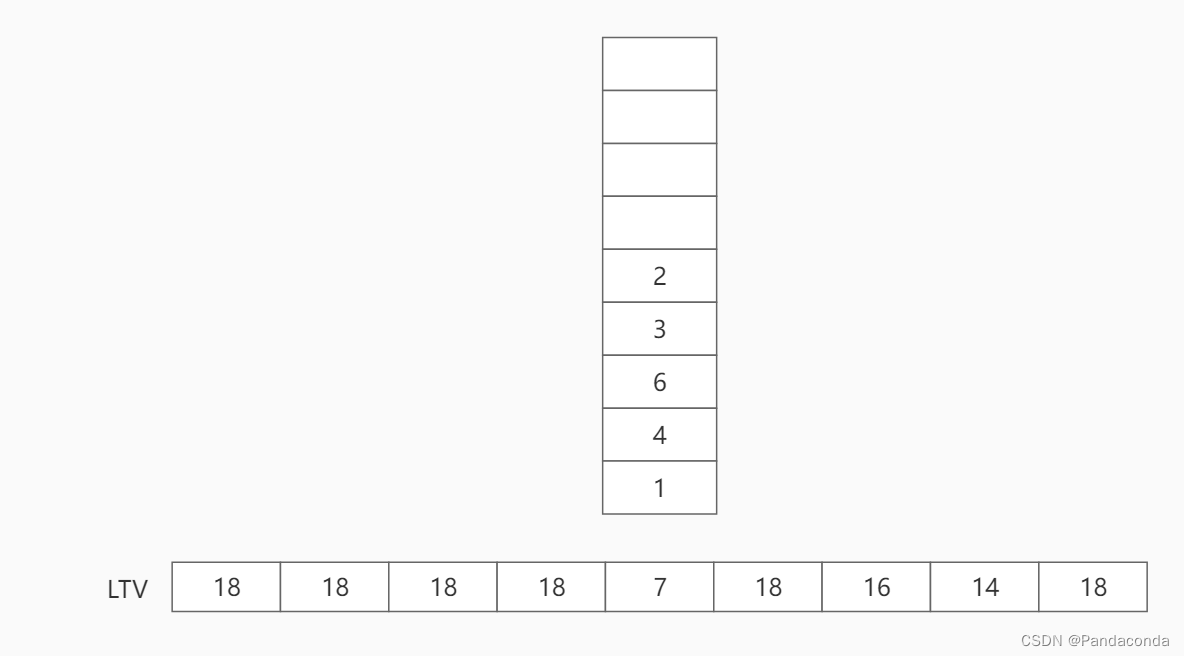
第五步:弹出栈顶结点 2 ,并遍历结点 2 的邻接结点 5 ,用结点 5 的 LTV(最晚发生时间)减去活动 a4 所需时间,即为 6 ,将结点 2 的 LTV[1] 更新为 6 。
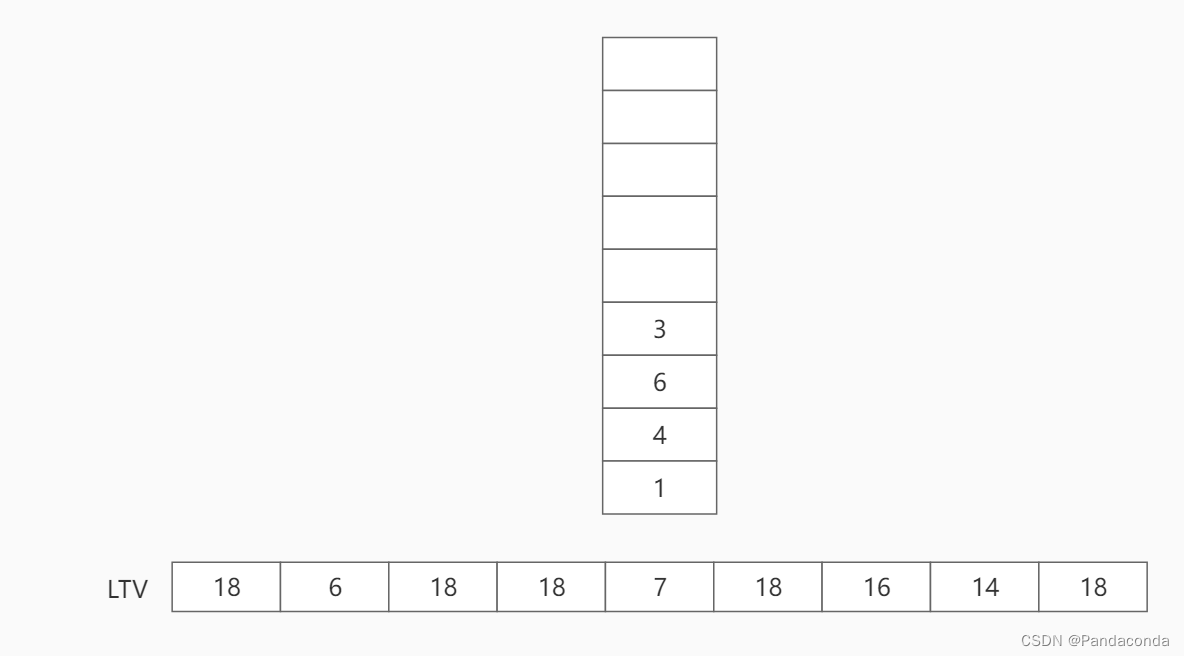
第六步:弹出栈顶结点 3 ,并更新结点 3 的最晚发生时间。
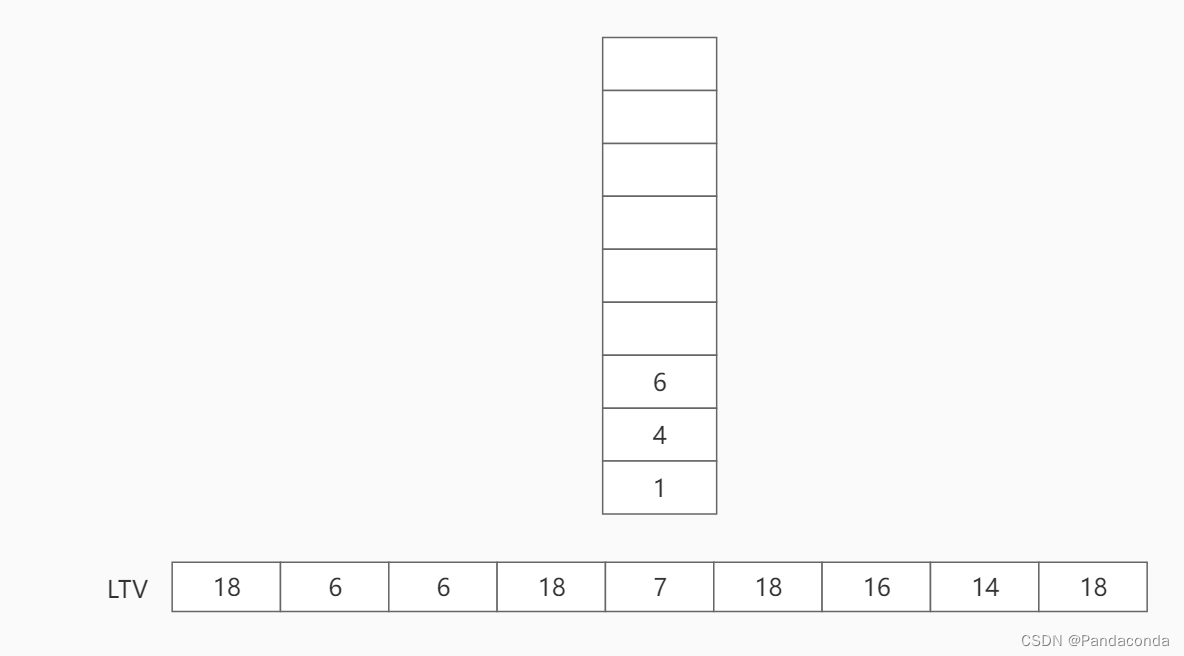
第七步:弹出栈顶结点 6 ,并更新结点 6 的最晚发生时间。
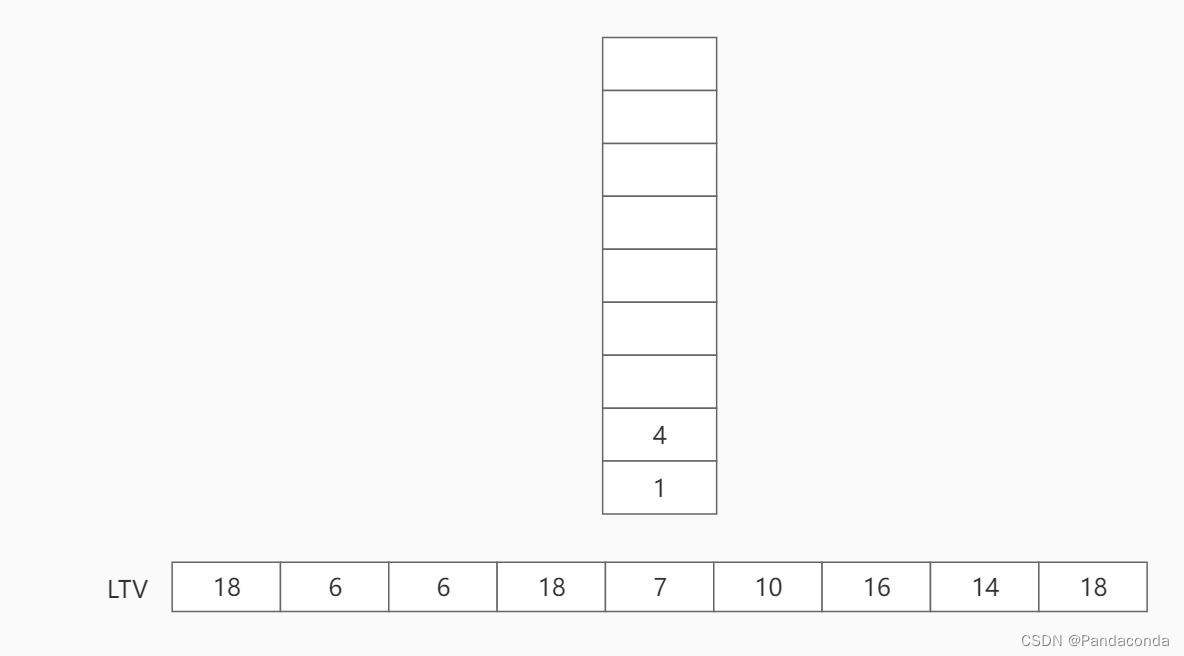
第八步:弹出栈顶结点 4 ,并更新结点 4 的最晚发生时间。
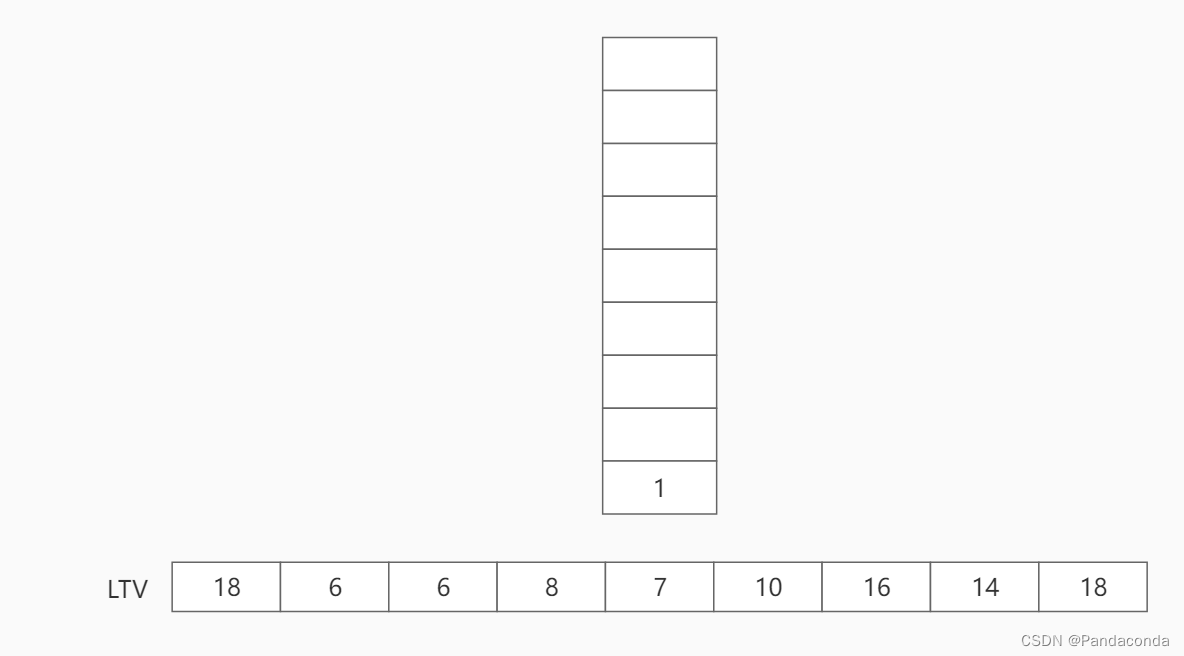
第九步:弹出栈顶元素 1 并更新其最晚发生时间。使用结点 2 的最晚发生时间 6 减去活动 a1 所需时间 6 等于 0 ,与结点 1 的最晚时间相比较并更新为 0 。需要说明,事实上源点 的最晚发生时间与最早发生时间都为 0 ,毋庸置疑 。
此时我们得到每个事件(结点)的最早发生时间和最晚发生时间,但关键路径是活动的集合,所以接下来我们用事件的最早发生时间和最晚发生时间计算出活动(弧)的最早与最晚发生时间即可。
计算活动的最早与最晚开始时间
第一步:从源点 1 开始,遍历源点的邻接结点 2 ,将弧 <1 , 2> 上的活动 a1 的最早发生时间更新为源点 1 的最早发生时间 0 ,将活动 a1 的最晚发生时间更新为结点 2 的最晚发生时间 6 减去活动 a1 所需要的时间 6 ,即为 0 。判断活动 a1 的最早发生时间与最晚发生时间是否相等,如果相等则为关键活动,并输出。
同理遍历源点 1 的邻接结点 3 和结点 4 ,并更新弧 a2 和 a3 的最晚开始时间与最早开始时间。
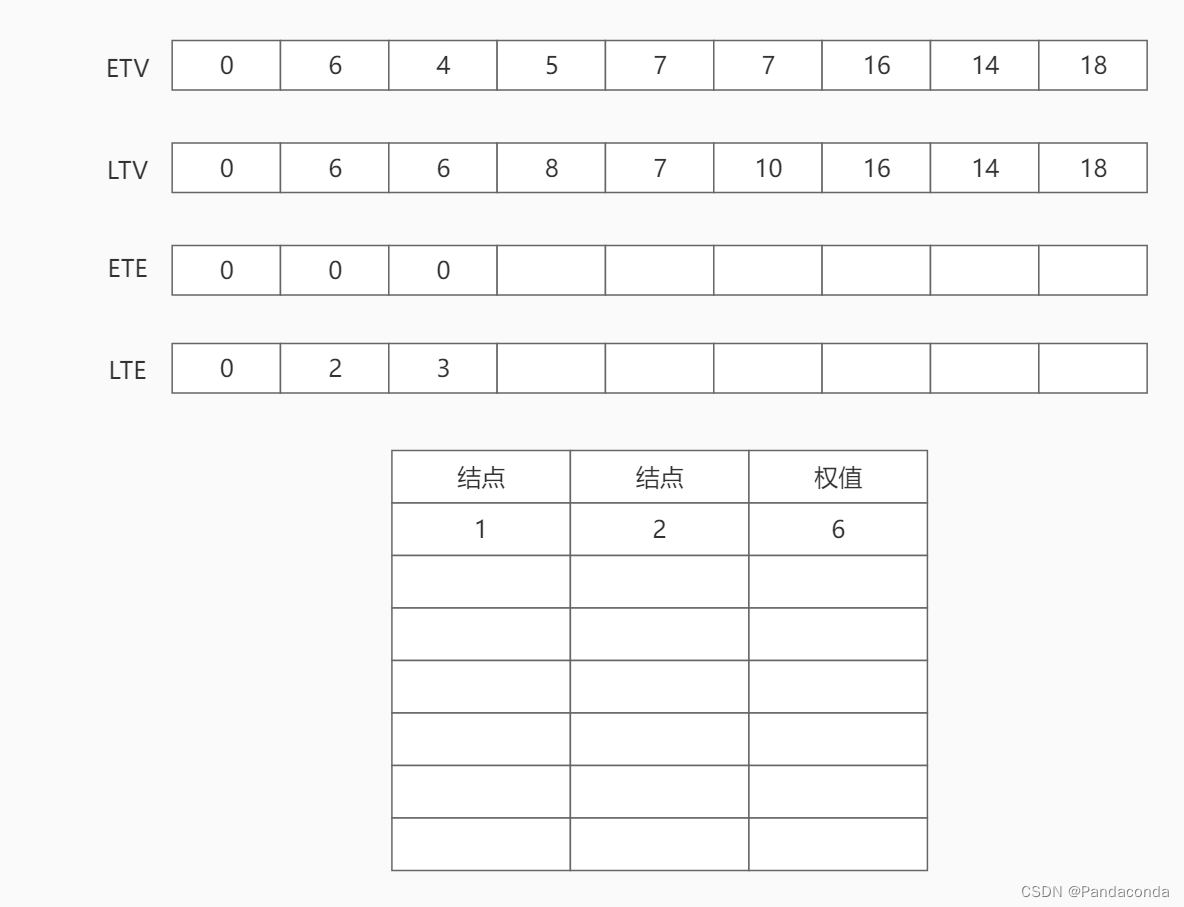
第二步:访问结点 2,遍历结点 2 的邻接结点 5 。将活动 a4 的最早发生时间更新为结点 2 的最早发生时间,将活动 a4 的最晚发生时间更新为结点 5 的最晚发生时间 7 减去活动 a4 所需时间 1 ,即为 6 。
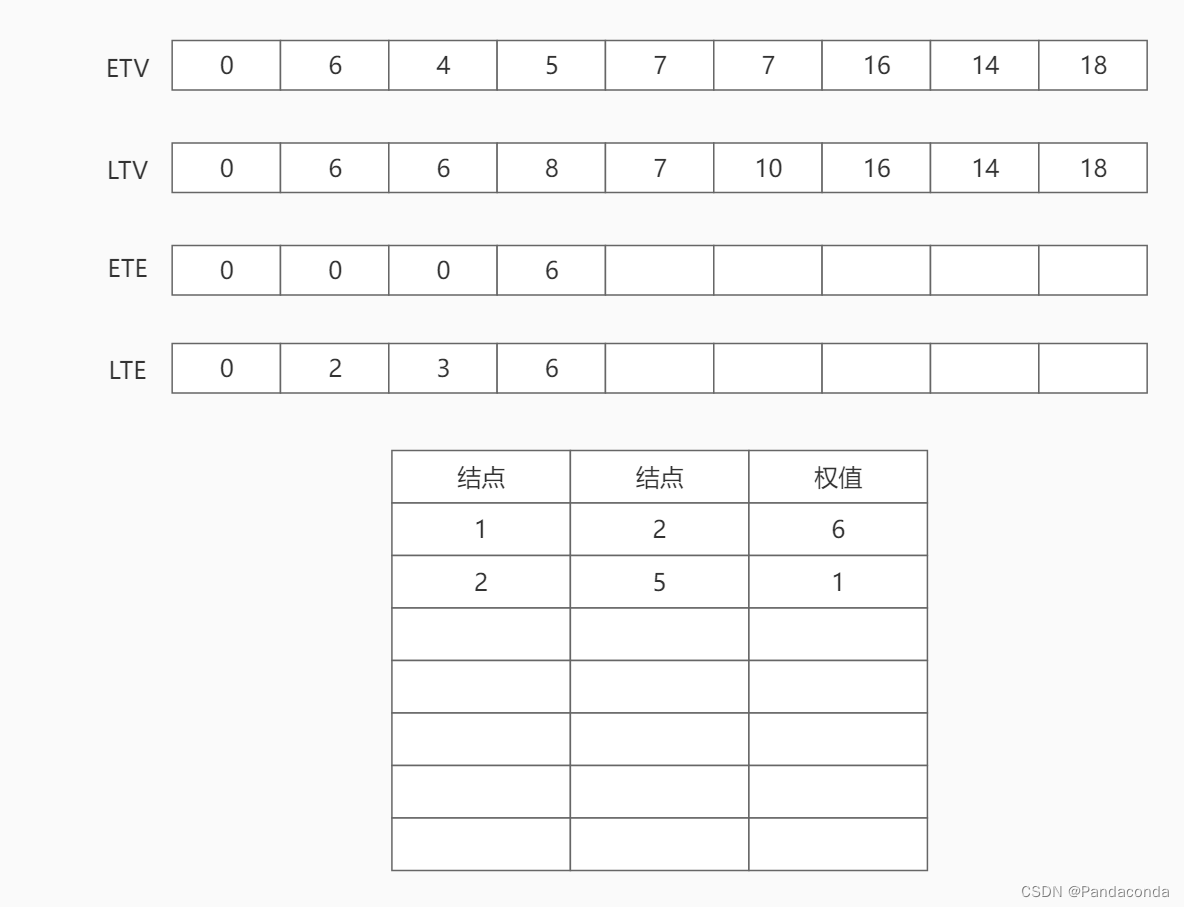
第三步:访问结点 3 ,遍历结点 3 的邻接结点 5 。将活动 a5 的最早发生时间更新为结点 3 的最早发生时间 4 ,将活动 a5 的最晚发生时间更新为结点 5 的最晚发生时间 7 减去活动 a5 所需时间 1 ,即为 6 。
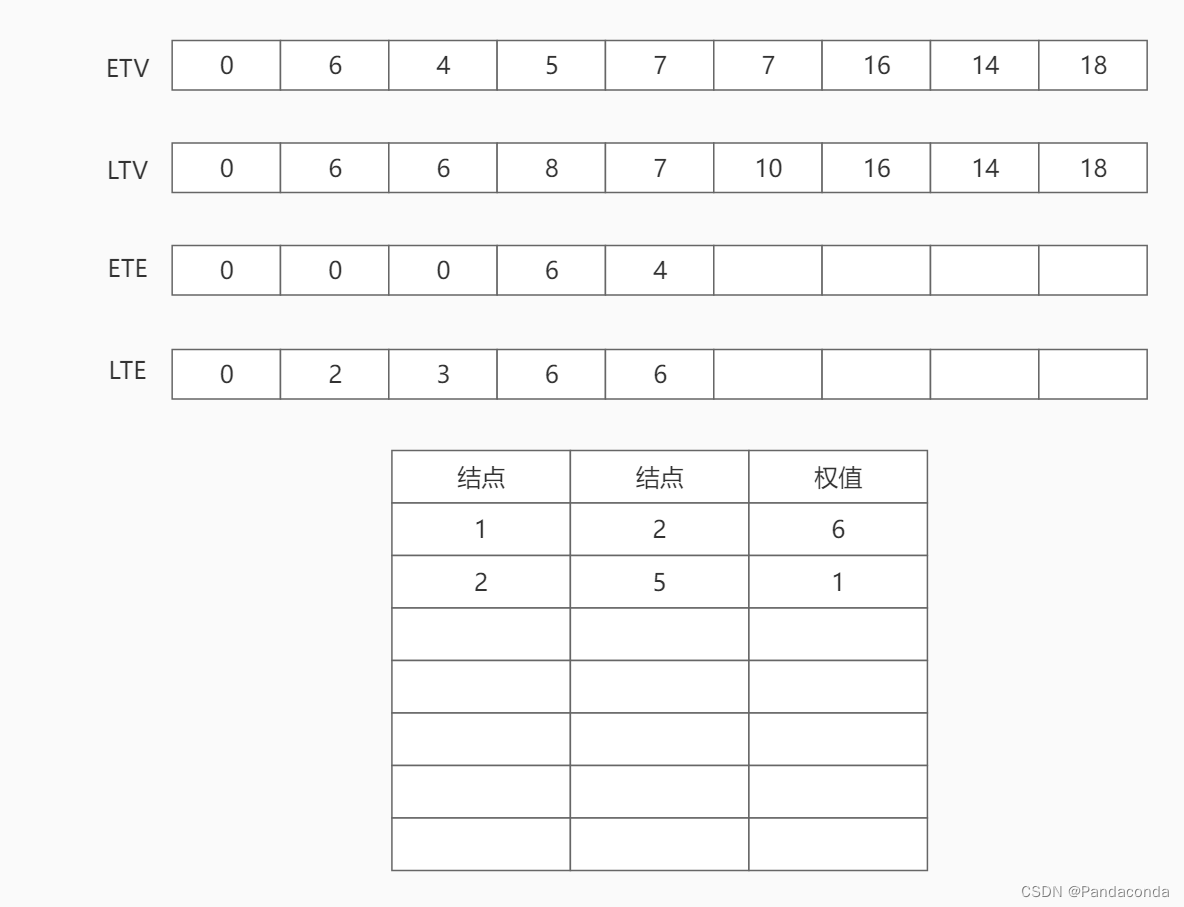
第四步:访问结点 4 ,遍历该结点的邻接结点 6 ,将活动 a6 的最早发生时间更新为结点 4 的最早发生时间 5 ,活动 a6 的最晚发生时间为结点 6 的最晚发生时间10 减去活动 a6 所需要的时间 2 ,即为 8 。
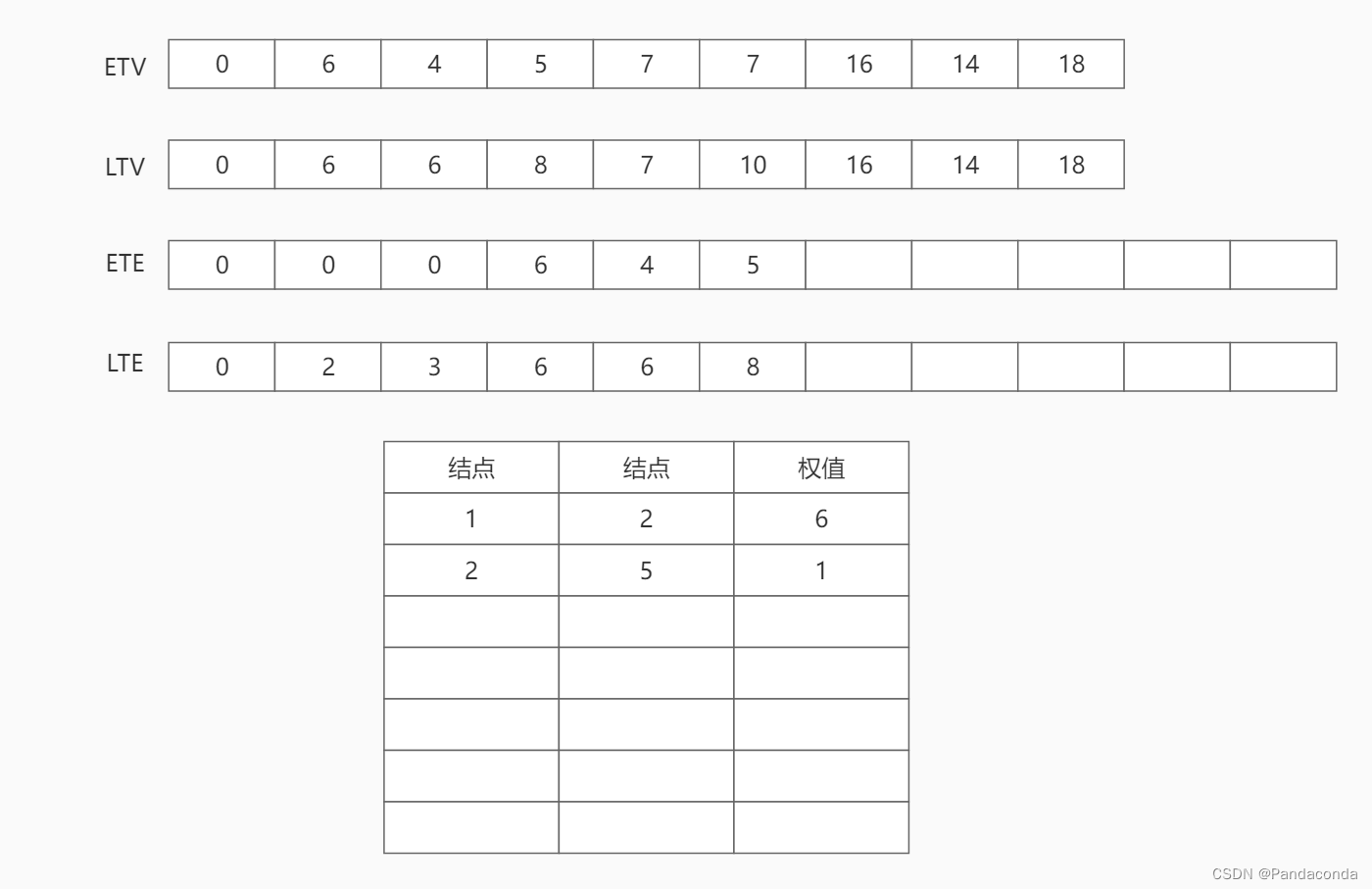
第五步:访问结点 5 ,并分别遍历该结点的邻接结点 7 和结点 8 。将活动 a7 和 a8 的最早发生时间更新为时间结点 5 的最早发生时间 7 ,最晚发生时间也更新为 7 。
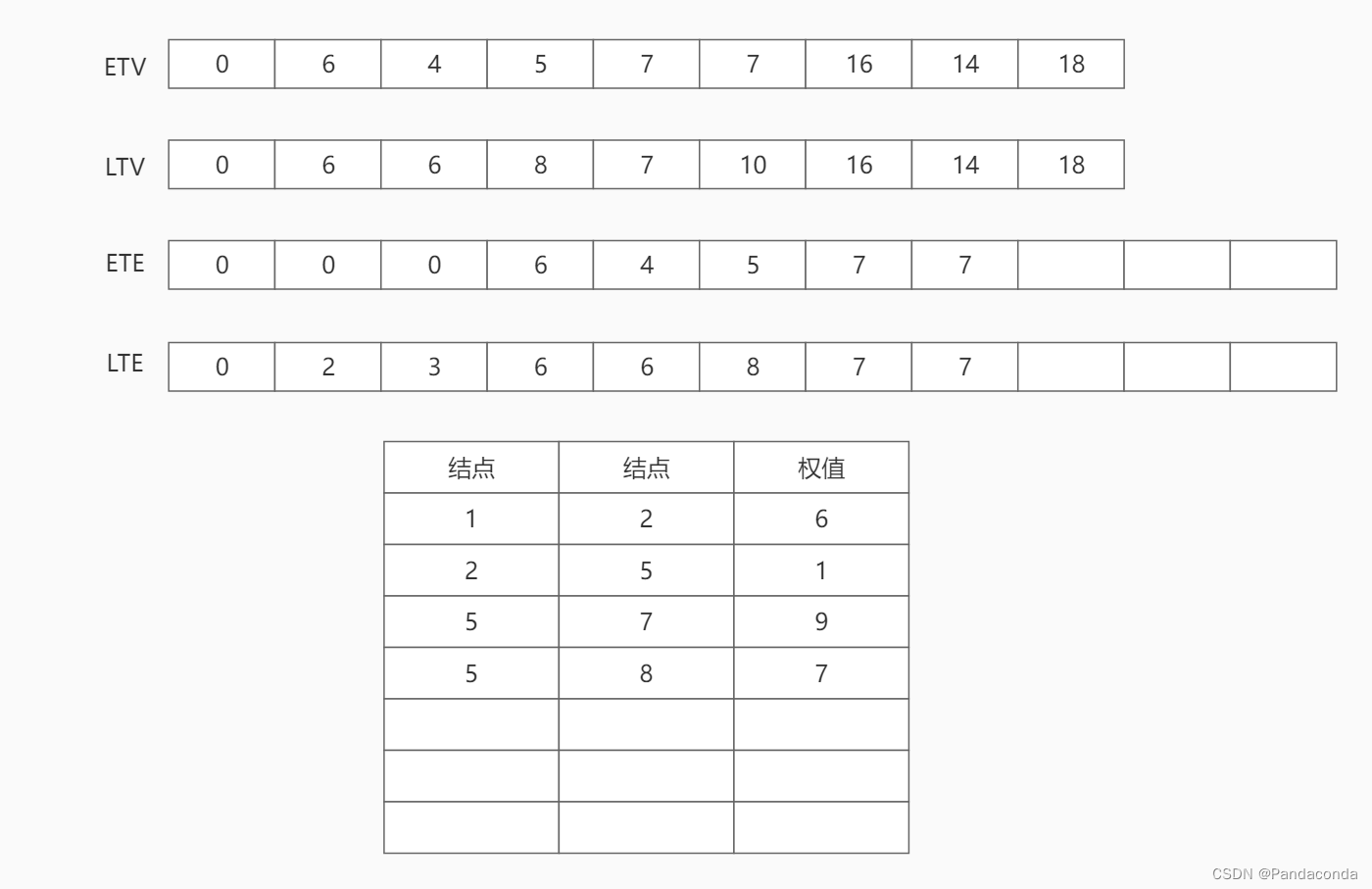
第六步:访问结点 6 ,并遍历该结点的邻接结点 8 ,将活动 a9 的最早发生时间更新为结点 6 的最早发生时间 7 ,最晚发生时间更新为结点 8 的最晚发生时间 14 减去活动 a9 所需时间 4 ,即为 10 。
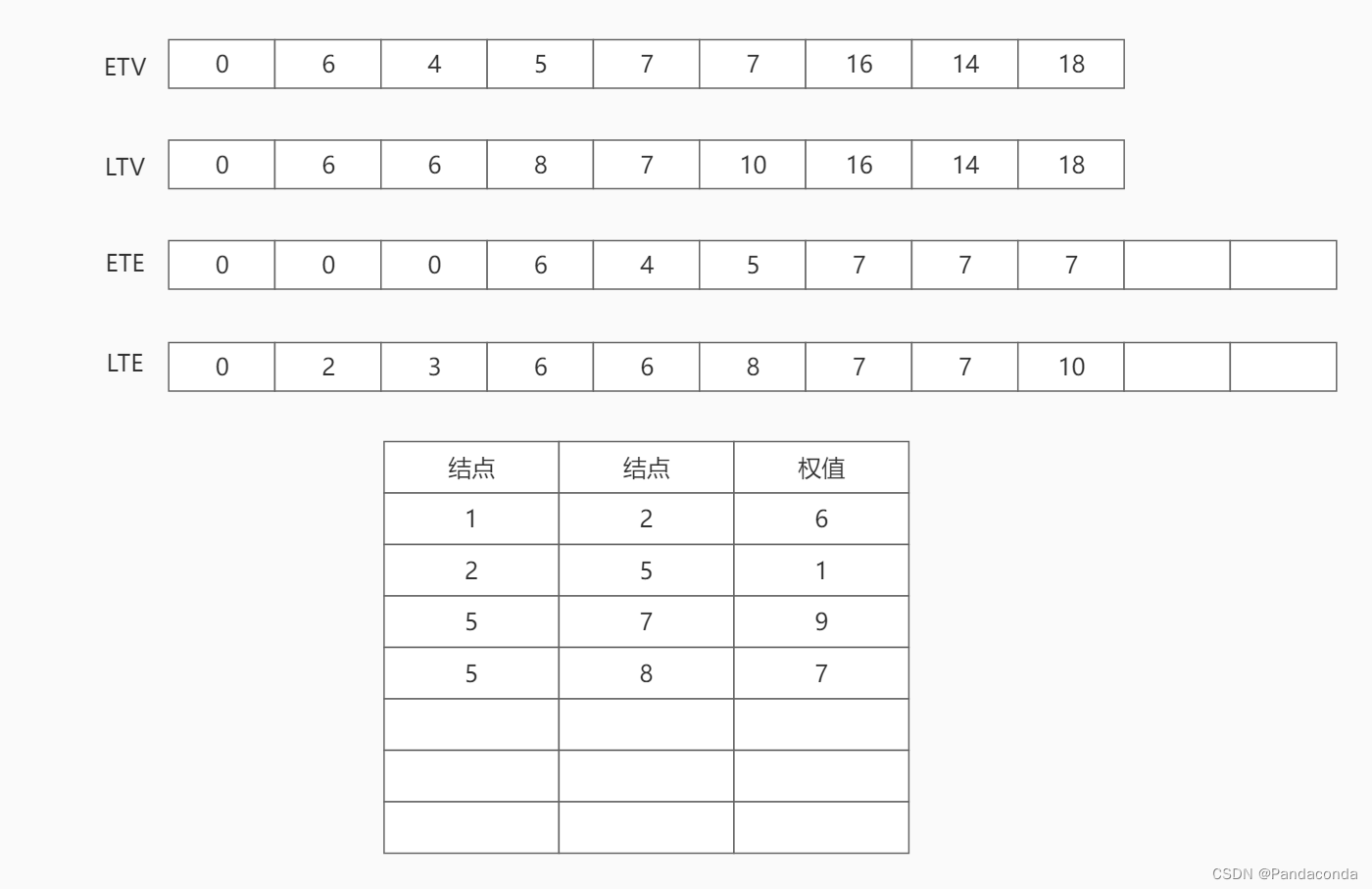
第七步:访问结点 7 ,更新活动 a10 的最早发生时间和最晚发生时间。
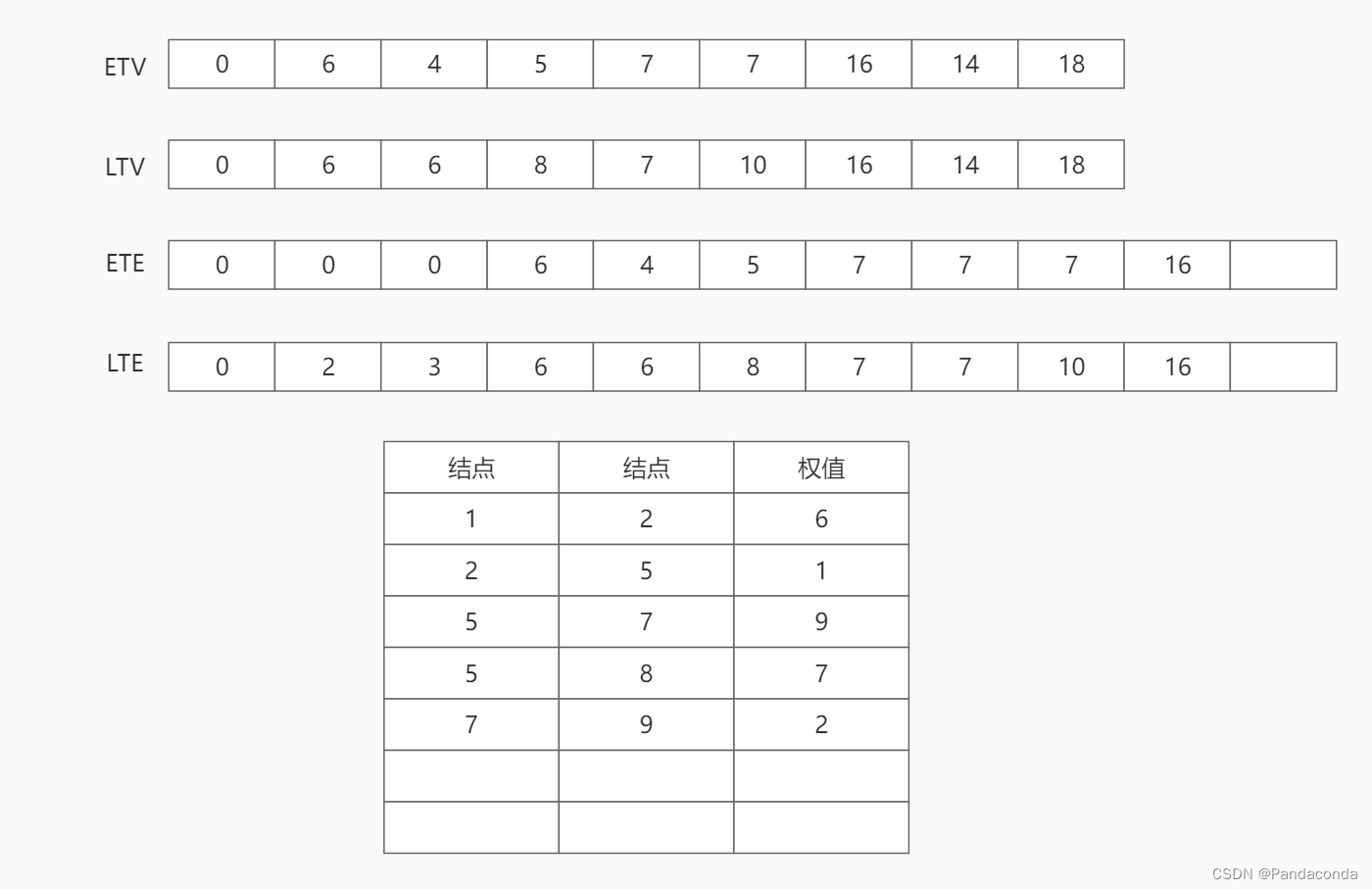
第八步:访问结点 8 ,更新活动 a11 的最早发生时间和最晚发生时间。
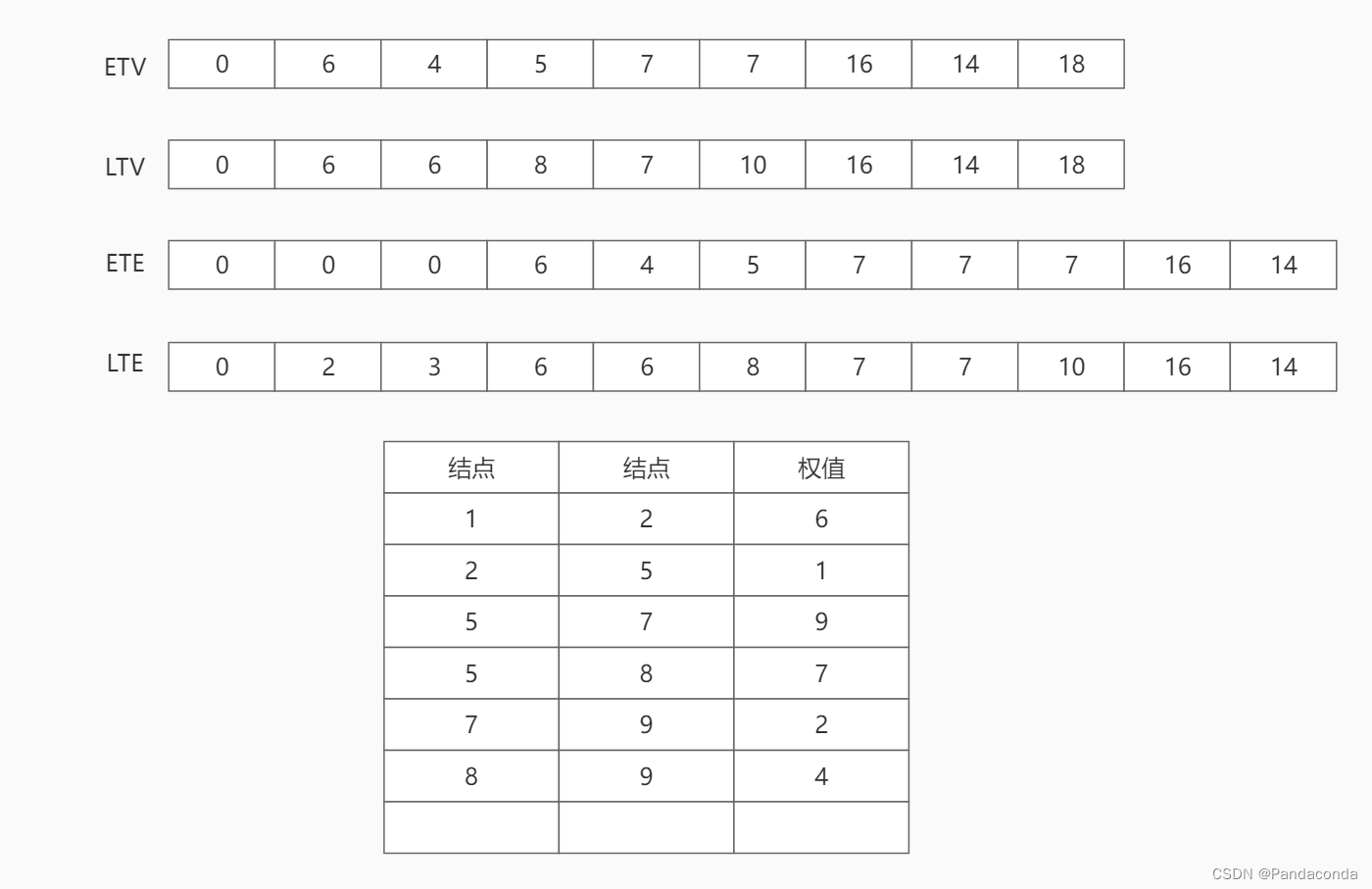
第九步:访问结点 9 ,没有邻接顶点,并且已经到终点,遍历结束。
这样,我们就获得了最终的关键路径:
全部代码
这里我们仍然是手动模拟栈,拓扑排序套用上一讲的代码,同时在其中加上更新事件最早开始时间的代码。
#include <bits/stdc++.h> using namespace std; #define MAXVERTIES 20 #define OK 1 #define ERROR 0 int indegree[MAXVERTIES] = { 0 }; //用于存储入度信息 /* 9 1 2 3 4 5 6 7 8 9 11 1 2 6 1 4 5 1 3 4 2 5 1 3 5 1 4 6 2 5 7 9 5 8 7 6 8 4 7 9 2 8 9 4 */ //定义结点 struct VexNode { int data; int weight; VexNode *next; }; //定义弧 struct ArcNode { int data; VexNode *firstacr = NULL; }; //定义邻接表 struct GraphList { ArcNode arclist[MAXVERTIES]; int vexnum, arcnum; }; //定义栈 struct Stack { int Sacklist[MAXVERTIES] = { 0 }; int top = -1; }; //入栈操作 void Push(Stack &S, int key) { if (S.top == MAXVERTIES) { cout << "栈已满!" << endl; return; } S.top++; S.Sacklist[S.top] = key; } //出栈操作 int Pop(Stack &S) { if (S.top == -1) { cout << "栈为空!" << endl; return -1; } int temp = S.Sacklist[S.top]; S.top--; return temp; } //获取结点在数组中的下标 int Location(GraphList &G, int key) { for (int i = 0; i < G.vexnum; i++) { if (G.arclist[i].data == key) { return i; } } return -1; } //创建图 void CreatGraph(GraphList &G) { cout << "请输入顶点数:" << endl; cin >> G.vexnum; cout << "请输入顶点信息:" << endl; for (int i = 0; i < G.vexnum; i++) { cin >> G.arclist[i].data; } cout << "请输入弧数:" << endl; cin >> G.arcnum; cout << "请输入弧端点信息:" << endl; for (int i = 0; i < G.arcnum; i++) { int v1, v2, w; cin >> v1 >> v2 >> w; int Location1 = Location(G, v1); int Location2 = Location(G, v2); VexNode *new_node = new VexNode; new_node->weight = w; new_node->data = Location2; new_node->next = G.arclist[Location1].firstacr; G.arclist[Location1].firstacr = new_node; indegree[Location2]++; } } //拓扑排序 int TopoSort(GraphList &G, int *topolist, int *etv) { Stack S; int topo = 0; //先找到一个入度为0的结点入栈 for (int i = 0; i < G.vexnum; i++) { if (indegree[i] == 0) { Push(S, i); } } while (S.top != -1) { int vx = Pop(S); topolist[topo++] = G.arclist[vx].data; //记录拓扑序列 VexNode *temp = G.arclist[vx].firstacr; //遍历出栈元素的所有邻接结点 while (temp != NULL) { int index = temp->data; indegree[index]--; //入度减1 //如果入度为0,则入栈 if (indegree[index] == 0) { Push(S, index); } //同时更新事件的最早开始时间(连接它的所有活动都完成了的最早时间) if (temp->weight + etv[vx] > etv[index]) { etv[index] = temp->weight + etv[vx]; } temp = temp->next; } } topolist[topo] = -1; //如果拓扑序列中的元素个数等于图中元素个数,则图中无环,否则图中有环 if (topo == G.vexnum) { return OK; } else { return ERROR; } } //关键路径 void CriticalPath(GraphList &G, int *etv, int *ltv, int *topolist) { int ete, lte; //活动的最早开始时间和最晚开始时间 //初始化ltv数组,使数组中的值都为终点的最早开始时间 for (int i = 0; i < G.vexnum; i++) { ltv[i] = etv[G.vexnum - 1]; } int top = G.vexnum - 1; VexNode *temp = NULL; //将得到的拓扑序列依次取出,用数组模拟栈故从最后一个元素往前遍历 while (top > 0) { int get_index = Location(G, topolist[--top]); temp = G.arclist[get_index].firstacr; //遍历出栈结点的所有邻接结点 while (temp != NULL) { //更新事件的最晚开始时间(该时间从该时间开始,完成后续所有活动后会刚好在终点截止期限到达) if (ltv[temp->data] - temp->weight < ltv[get_index]) { ltv[get_index] = ltv[temp->data] - temp->weight; } temp = temp->next; } } //计算活动的最早开始时间和最晚开始时间并输出 cout << "关键路径为:" << endl; for (int i = 0; i < G.vexnum; i++) { //遍历所有边 for (temp = G.arclist[i].firstacr; temp != NULL; temp = temp->next) { ete = etv[i]; lte = ltv[temp->data] - temp->weight; //如果活动的最早开始时间等于最晚开始时间,则该事件是关键路径上的一点 if (ete == lte) { cout << "V" << G.arclist[i].data << "->V" << G.arclist[temp->data].data; cout << " 权值为" << temp->weight << endl; } } } } int main() { GraphList GL; CreatGraph(GL); //拓扑序列数组以及事件的最早开始时间数组 int topolist[MAXVERTIES] = { 0 }, etv[MAXVERTIES] = { 0 }; int vx = TopoSort(GL, topolist, etv); //得到拓扑序列 if (!vx) { cout << "有环!" << endl; } else { int ltv[MAXVERTIES]; CriticalPath(GL, etv, ltv, topolist); } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
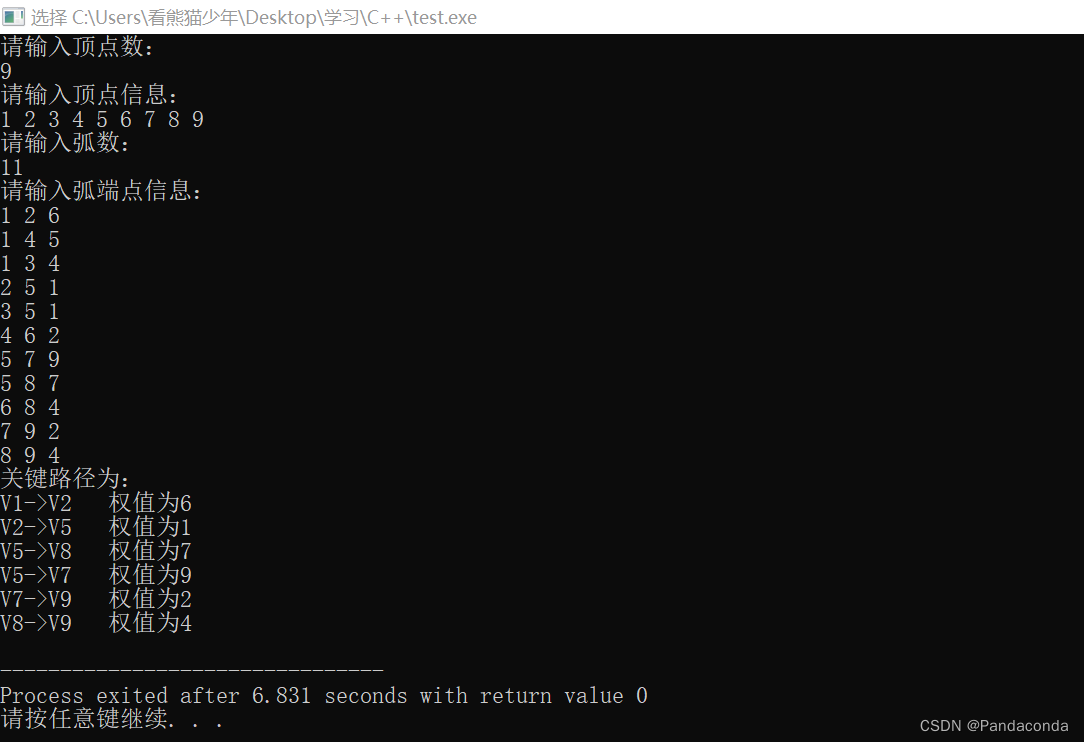
应用与总结
关键路径可以去应用在不同的地方:
(1)完成整个工程需要多少时间,就像我开头举的项目那个例子一样。
(2)哪些活动是影响该工程的关键,也就是找出完成时间最多的那个。
我们可以利用关键路径,对工程中关键的事件压缩时间从而使整个工程的进度加快。当然,也可以从其它非关键事件抽出一些人力和物力投入到关键事件中,合理利用资源从而均衡整个工程项目,使项目节奏处于比较完美的推进状态。
另外,知道工程的关键路径,对于非关键的事件也可以适当的摸摸鱼 doge ~
如果大家有什么问题的话,欢迎在下方评论区进行讨论哦~
-
相关阅读:
无人机集群路径规划MATLAB:孔雀优化算法POA求解无人机集群三维路径规划
数据结构-----哈夫曼树和哈夫曼编码
TypeORM 框架
【C++】-- STL之unordered_map/unordered_set详解
个人秋招面经——腾讯
自动化专业之半导体行业入门指南
说说考研调剂都有哪些具体要求?
PPT文档图片设计素材资源下载站模板源码/织梦内核(带用户中心+VIP充值系统+安装教程)
springboot 事务注解
C++(Chapter 3)
- 原文地址:https://blog.csdn.net/Newin2020/article/details/125396615
