-
Hbase TimeStamp的妙用
项目场景:
我们用hbase储存了所有需要实时查询的表,通过Spark-phoenix-jdbc的方式实时从kafka消费数据,写入到hbase里面,为了方便快速查寻,我们维护了一个最新的样本数据表,通过写phoenix-sql的方式查询当前最新的数据,提供给业务
基本架构:
问题
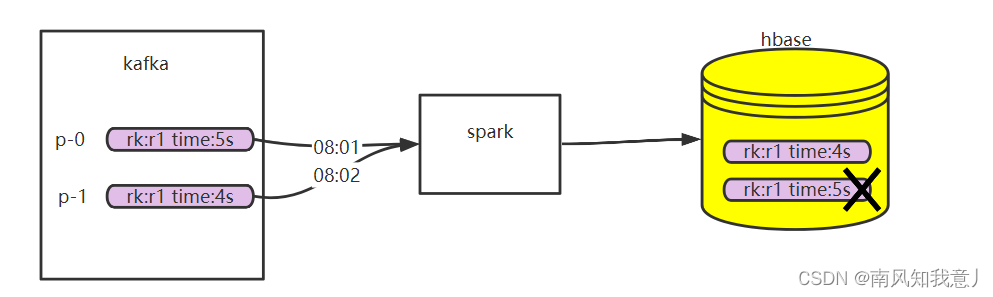
实时写入时,需要考虑数据更新的顺序,要做到spark消费kafka里的数据是按照时间顺序消费的,不然可能5s的数据会被4s(迟到/不同分区)来的数据覆盖;
实时写入
-
实时写入的顺序,大都由CDC(canal、debezium等)控制。针对每一条数据的更新,CDC都会对“表名+主键”进行Hash,路由到Kafka对应的分区。
-
其实针对某个表某条记录的更新,消费时是有严格的顺序的。
-
但如果后期更改kafka分区个数,就会稍微麻烦点。
-
如果不停服更新,就意味着同一条记录的不同更新,分布在不同的分区,也就不能保证严格的顺序,
插入Phoenix表就会出现覆盖的问题。
-
如果停服更新,就需要先停掉CDC,等消费者把数据消费完,然后再调整分区,启动消费者,这样才能避免相互覆盖的问题。
-
实时写入还有一个潜在的问题,那就是数据丢失。不管是网络抖动,还是组件的健壮性,都会造成数据丢失。一旦发生数据丢失,就需要校验、补数的逻辑。
解决方案:
思路
熟悉HBase的读者一定知道,HBase插入或更新数据的时候是可以指定时间戳(版本号)的,而且HBase查询时默认显示时间戳最大的数据。那如果Phoenix在根据主键写入数据时,能把该条数据的更新时间写入HBase的时间戳字段,就能解决相互覆盖的问题了
其实每一条更新都是数据的一个版本。如果写入时能指定时间戳,就意味着指定了数据的版本,无论每个更新到达的顺序是怎样的,Phoenix读取时都会读取最新的数据。
如果能实现,那么Kafka重新设定分区个数和离线补数将不再需要考虑覆盖的问题。Hbase Timestamp
看下hbase put方法的源码,其实是有个参数可以指定ts的,默认是数据添加时的时间戳,是一个单调递增的值
/** * Add the specified column and value, with the specified timestamp as * its version to this Put operation. * @param family family name * @param qualifier column qualifier * @param ts version timestamp * @param value column value * @return this */ public Put addColumn(byte [] family, byte [] qualifier, long ts, byte [] value) { if (ts < 0) { throw new IllegalArgumentException("Timestamp cannot be negative. ts=" + ts); } List<Cell> list = getCellList(family); KeyValue kv = createPutKeyValue(family, qualifier, ts, value); list.add(kv); return this; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
timestamp有个特性, 就是同一条记录, 写入的后续记录的timestamp必须大于等于之前的,否则就不会生效.
有了这样的特性,我们就可以手动定制这个timestamp字段, 把这个值设置为Event Time而不是默认时间或者Process Time, 这样就可以保证数据的最终一致性.
正常情况下, 老消息先到, 正常.
异常情况下, 新消息先到, 老消息在写入时,因为timestamp太小, 写不进去
Phoenix Row timestamp
Phoenix v4.6现在提供了一种将 HBase 的本机行时间戳映射到 Phoenix 列的方法。但是有一些限制:
- 只有主键中的TIME, DATE, TIMESTAMP, BIGINT, UNSIGNED_LONG类型的字段才能设置成ROW_TIMESTAMP
- 只能有一个主键列能被设置成ROW_TIMESTAMP
- ROW_TIMESTAMP标志的字段不能为null值
- 只有在建表的时候,某一列才能被设置成ROW_TIMESTAMP
- ROW_TIMESTAMP标志的列不能为负数
除了上面使用上的限制,还有应用场景的限制。根据上面的描述,ROW_TIMESTAMP字段有以下几种形式。

我们来看下各个形式的优劣
- 业务主键在前。无论ROW_TIMESTAMP字段如何取值,都可以通过业务主键1进行单点查询,即在知道业务主键1的情况下是可以通过前缀精确快速的查询的。
- ROW_TIMESTAMP字段在前。如果不知道某条数据对应的ROW_TIMESTAMP字段值,则无法通过主键查询;如果通过业务主键可以映射ROW_TIMESTAMP字段值,虽然可以通过主键查询,但该字段将无法修改。因为修改就意味着当前记录删除,重新插入。
- 只有ROW_TIMESTAMP字段。在一些时序数据比较常见,也就是没有业务主键,不会也不便通过主键查询,一般都是范围扫描。
其实官方提供的ROW_TIMESTAMP字段实现,最大的问题就是原有记录不能更新,只能删除、然后插入,这就极大的限制了它的应用场景。
官方Sample
示例模式:
CREATE TABLE DESTINATION_METRICS_TABLE (CREATED_DATE DATE NOT NULL, METRIC_ID CHAR(15) NOT NULL, METRIC_VALUE LONG CONSTRAINT PK PRIMARY KEY(CREATED_DATE ROW_TIMESTAMP, METRIC_ID)) SALT_BUCKETS = 8;- 1
- 2
- 3
- 4
- 5
- 6
//这将 CREATION _ DATE 的值设置为在相应的绑定参数中指定的值。 UPSERT INTO DESTINATION_METRICS_TABLE VALUES (?, ?, ?)- 1
- 2
//-这将 CREATION _ DATE 的值设置为服务器端时间 UPSERT INTO DESTINATION_METRICS_TABLE (METRIC_ID, METRIC_VALUE) VALUES (?, ?)- 1
- 2
//-这会将 CREated _ DATE 的值设置为从 SOURCE _ METRICS _ TABLE 中选择的日期 UPSERT INTO DESTINATION_METRICS_TABLE (CREATED_DATE, METRICS_ID, METRIC_VALUE) SELECT DATE, METRICS_ID, METRIC_VALUE FROM SOURCE_METRICS_TABLE- 1
- 2
//这将目标表中的 create _ date 的值设置为服务器时间戳。 UPSERT INTO DESTINATION_METRICS_TABLE (METRICS_ID, METRIC_VALUE) SELECT METRICS_ID, METRIC_VALUE FROM SOURCE_METRICS_TABLE- 1
- 2
测试了一下
CREATE TABLE USDP.LZX_TABLE_L ( "scan_time" TIMESTAMP NOT NULL, "rk" VARCHAR NOT NULL, "i"."engine_name" VARCHAR CONSTRAINT PK PRIMARY KEY("scan_time" ROW_TIMESTAMP, "rk") )column_encoded_bytes=0; -- 2022-05-18T11:05:52.263 UPSERT INTO USDP.LZX_TABLE_L VALUES (1645381363000, '000_lzx', 'hr_scan'); --2022-02-21 02:22:43 UPSERT INTO USDP.LZX_TABLE_L VALUES (1645381362000, '000_lzx', 'hr_scan') ;--2022-02-21 02:22:42- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
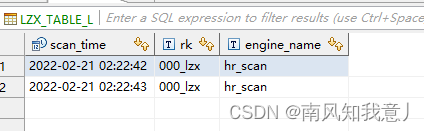
因为Phoenix的限制 并不能很好的映射hbase 的time stamp,因为只有主键中的TIME, DATE, TIMESTAMP, BIGINT, UNSIGNED_LONG类型的字段才能设置成ROW_TIMESTAMP,所以插入记录都会保留下来,其实这样也可以完成需求,只是有些麻烦
SELECT * FROM USDP.LZX_TABLE_Z WHERE "rk" = '000_lzx' ORDER BY "scan_time" DESC LIMIT 1;- 1

总结:
最终我们还是没有通过Phoenix的方式去插入,而是利用了hbase的这个特性,使用put方法去插入的,然后在phoenix内建立该表视图,虽然视图是只读的,但是无所谓我们这个表 只用来做查询需求用的。
-
-
相关阅读:
【数据结构与算法】一套链表 OJ 带你轻松玩转链表
【C++】缺省参数与函数重载
Java-API简析_java.net.Inet6Address类(基于 Latest JDK)(浅析源码)
Ubuntu安装boost
读书笔记:《Effective Modern C++(C++14)》
常见加密算法C#实现(一)
跟运维学 Linux - 03
超实用!你不得不知道的7款项目管理神器
MindSpore手写数字识别体验
谁拥有穿越周期的眼光?
- 原文地址:https://blog.csdn.net/Lzx116/article/details/125470247
