-
Hadoop集群安装,mysql安装,hive安装
1、Hadoop集群安装
下载安装包
第一步:上传压缩包并解压
将我们重新编译之后支持snappy压缩的hadoop包上传到第一台服务器并解压
第一台机器执行以下命令
cd /kkb/soft/
tar -zxvf hadoop-2.6.0-cdh5.14.2_after_compile.tar.gz -C ../install/
第二步:查看hadoop支持的压缩方式以及本地库
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2 bin/hadoop checknative
如果出现openssl为false,那么所有机器在线安装openssl即可,执行以下命令,虚拟机联网之后就可以在线进行安装了
yum -y install openssl-devel
第三步:修改配置文件
修改core-site.xml
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim core-site.xml
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://node01:8020</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas</value>
- </property>
- <!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
- <property>
- <name>io.file.buffer.size</name>
- <value>4096</value>
- </property>
- <!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
- <property>
- <name>fs.trash.interval</name>
- <value>10080</value>
- </property>
- </configuration>
修改hdfs-site.xml
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim hdfs-site.xml
- <configuration>
- <!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
- <!-- 集群动态上下线
- <property>
- <name>dfs.hosts</name>
- <value>/kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/accept_host</value>
- </property>
- <property>
- <name>dfs.hosts.exclude</name>
- <value>/kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/deny_host</value>
- </property>
- -->
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>node01:50090</value>
- </property>
- <property>
- <name>dfs.namenode.http-address</name>
- <value>node01:50070</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value>
- </property>
- <!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas</value>
- </property>
- <property>
- <name>dfs.namenode.edits.dir</name>
- <value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits</value>
- </property>
- <property>
- <name>dfs.namenode.checkpoint.dir</name>
- <value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name</value>
- </property>
- <property>
- <name>dfs.namenode.checkpoint.edits.dir</name>
- <value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- <property>
- <name>dfs.blocksize</name>
- <value>134217728</value>
- </property>
- </configuration>
修改hadoop-env.sh
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/kkb/install/jdk1.8.0_141修改mapred-site.xml
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim mapred-site.xml
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.job.ubertask.enable</name>
- <value>true</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>node01:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>node01:19888</value>
- </property>
- </configuration>
修改yarn-site.xml
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim yarn-site.xml
- <configuration>
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>node01</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
修改slaves文件
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim slaves
- node01
- node02
- node03
第四步:创建文件存放目录
第一台机器执行以下命令
node01机器上面创建以下目录
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits第五步:安装包的分发
第一台机器执行以下命令
cd /kkb/install/
scp -r hadoop-2.6.0-cdh5.14.2/ node02:$PWD
scp -r hadoop-2.6.0-cdh5.14.2/ node03:$PWD第六步:配置hadoop的环境变量
三台机器都要进行配置hadoop的环境变量
三台机器执行以下命令
vim /etc/profile
export HADOOP_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH配置完成之后生效
source /etc/profile
第七步:集群启动
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。(在其bin目录下)
bin/hdfs namenode -format或者bin/hadoop namenode –format
第8步、脚本一键启动
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
启动集群
node01节点上执行以下命令
- 第一台机器执行以下命令
- cd /kkb/install/hadoop-2.6.0-cdh5.14.2/
- sbin/start-dfs.sh
- sbin/start-yarn.sh
- sbin/mr-jobhistory-daemon.sh start historyserver
- 停止集群:
- sbin/stop-dfs.sh
- sbin/stop-yarn.sh
启动成功就能访问下面网址
hdfs集群访问地址
http://192.168.52.100:50070/dfshealth.html#tab-overview
yarn集群访问地址
http://192.168.52.100:8088/cluster
jobhistory访问地址:
第二、MySQL在线安装
学习Hive课程时,需要先安装mysql
安装到第三个节点node03上
使用root用户,在CentOS 7服务器的/kkb/soft路径下执行以下命令
cd /kkb/soft/
yum -y install wget
1、使用wget命令下载mysql的rpm包
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
-i 指定输入文件
-c 表示断点续传
2、安装mysql
[root@node03 soft]# yum -y install mysql57-community-release-el7-10.noarch.rpm
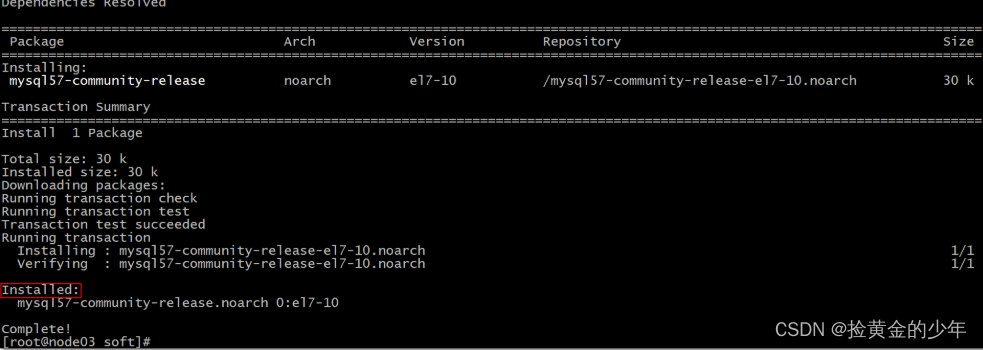
3、安装mysql server
这步可能会花些时间,需要在线下载,视网速而定;然后再安装;安装完成后就会覆盖掉之前的mariadb
[root@node03 soft]# yum -y install mysql-community-server
如果安装出现错误
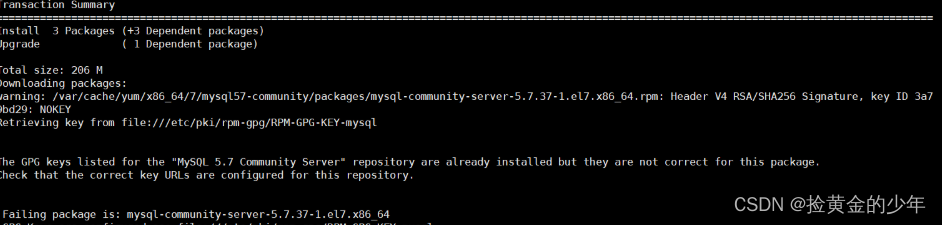
报错原因:这是由于MySQL GPG 密钥已过期导致的问题,解决出处需要运行命令, 以2022年为例
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
先运行这个命令,再运行2,3步骤
4、设置mysql
4.1 mysql服务
-
首先启动MySQL服务
[root@node03 soft]# systemctl start mysqld.service
-
查看mysql启动状态
[root@node03 soft]# systemctl status mysqld.service
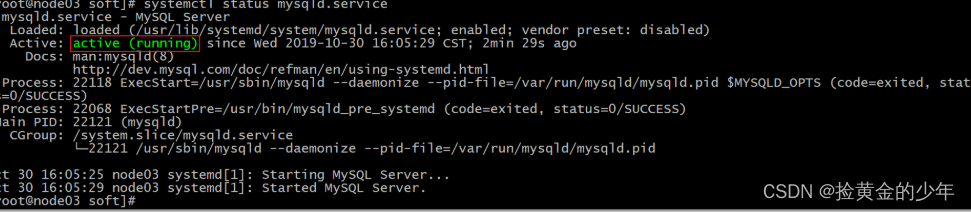
4.2、修改密码
获取临时密码
grep "password" /var/log/mysqld.log
登录MySQL
mysql -uroot -p
设置密码策略为LOW,此策略只检查密码的长度
set global validate_password_policy=LOW;
设置密码最小长度
set global validate_password_length=6;
设置root密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
开启MySQL远程连接权限
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
flush privileges;退出
exit;
3、Have安装
1、解压文件
[hadoop@node03 ~]$ cd /kkb/soft/
[hadoop@node03 soft]$ tar -xzvf hive-1.1.0-cdh5.14.2.tar.gz -C /kkb/install/2、修改配置文件
1、修改==配置文件hive-env.sh==
进入到Hive的安装目录下的conf文件夹中
[hadoop@node03 soft]$ cd /kkb/install/hive-1.1.0-cdh5.14.2/conf/
2、重命名hive-env.sh.template
mv hive-env.sh.template hive-env.sh
3、修改hive-env.sh
vim hive-env.sh
修改此文件中HADOOP_HOME、HIVE_CONF_DIR的值(根据自己机器的实际情况配置)
#配置HADOOP_HOME路径
export HADOOP_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2/#配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/kkb/install/hive-1.1.0-cdh5.14.2/conf4、 修改==配置文件hive-site.xml==(conf目录下默认没有此文件,vim创建即可 )
vim hive-site.xml
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&characterEncoding=latin1&useSSL=false</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.jdbc.Driver</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>root</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>123456</value>
- </property>
- <property>
- <name>hive.cli.print.current.db</name>
- <value>true</value>
- </property>
- <property>
- <name>hive.cli.print.header</name>
- <value>true</value>
- </property>
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>node03</value>
- </property>
- </configuration>
5、修改==日志配置文件hive-log4j.properties==
创建hive日志存储目录
mkdir -p /kkb/install/hive-1.1.0-cdh5.14.2/logs/
重命名生成文件hive-log4j.properties
[hadoop@node03 conf]$ pwd
/kkb/install/hive-1.1.0-cdh5.14.2/conf
[hadoop@node03 conf]$ mv hive-log4j.properties.template hive-log4j.properties
[hadoop@node03 conf]$ vim hive-log4j.properties # 修改文件修改此文件的hive.log.dir属性的值
#更改以下内容,设置我们的hive的日志文件存放的路径,便于排查问题
hive.log.dir=/kkb/install/hive-1.1.0-cdh5.14.2/logs/
3、拷贝mysql驱动包
-
上传mysql驱动包,如
mysql-connector-java-5.1.38.jar到/kkb/soft目录中 -
由于运行hive时,需要向mysql数据库中读写元数据,所以==需要将mysql的驱动包上传到hive的lib目录下==
[hadoop@node03 ~]$ cd /kkb/soft/
[hadoop@node03 soft]$ cp mysql-connector-java-5.1.38.jar /kkb/install/hive-1.1.0-cdh5.14.2/lib/4、配置Hive环境变量
[root@node03 soft]# vim /etc/profile
末尾添加如下内容
export HIVE_HOME=/kkb/install/hive-1.1.0-cdh5.14.2
export PATH=$PATH:$HIVE_HOME/bin切换回hadoop用户,并source
[root@node03 soft]# su hadoop
[hadoop@node03 soft]$ source /etc/profile5、 验证安装
-
==hadoop集群已启动==
-
==mysql服务已启动==
-
在node03上任意目录启动hive cli命令行客户端
[hadoop@node03 ~]$ hive
show databases;
-
相关阅读:
Jquery 通过class名称属性,匹配元素
钡铼技术有限公司R40路由器工业4G让养殖环境监控更高效
地球红薯地中秋圆《乡村振兴战略下传统村落文化旅游设计》——世界旅行季许少辉八月新书辉少许
在类库中使用ASP.NET Core API
Jenkins权限控制与job编排
CMake中configure_file的使用
非常好用的C# .Net开源高性能跨平台内网穿透工具FastTunnel 香橙派orangepi
查看当前设备是否启用SR-IOV
大数据平台之Spark
第二章_Windows用户管理_实验案例_配置服务器的用户级组账户
- 原文地址:https://blog.csdn.net/weixin_43288858/article/details/125445404
