-
【JVM】G1垃圾回收器简述
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
为什么不使用CMS?
之前介绍CMS是以响应停顿时间最短为目的,是垃圾收集器中的里程碑,CMS分为Background和Foreground, Background为正常模式,整个回收过程分为4步:初始标记,并发标记,重新标记,并发清除,为了避免全量扫描的大数据量,在并发标记过程后Eden区容量达到2M,存在预标记阶段,当占用空间达到Eden的50%终止这个阶段进入重新标记;Foreground为并发失败进入的错误环境,执行状态为单线程。
尽管CMS的响应停顿时间很好,但是忽略了吞吐量,在单线程或者双线程状态下CMS的使用状态也不佳,因为双线程并发的时候,分为一个业务线程和一个垃圾回收线程,也存在CPU的调度导致频繁的上下文切换,因此有效率损耗问题。
其次,在可终止的预标记阶段,如果没有发生minor GC,CMS会停顿极限时间为5s;而进入foreground也表示CMS需要进行Full GC;
综上:CMS的缺点在于他的并发失败,停顿不可预测以及吞吐量较低。
G1概述
G1的目的:Garbage First,也就是垃圾优先原则,也就是空间方面的关注点。同时照顾到停顿时间以及吞吐量。
G1对内存空间重新定义,不再以物理空间分为Old和Young,而是在逻辑上将内存划分为若干Region,内存中默认Region为2048个,每个Region的大小为1M~32M
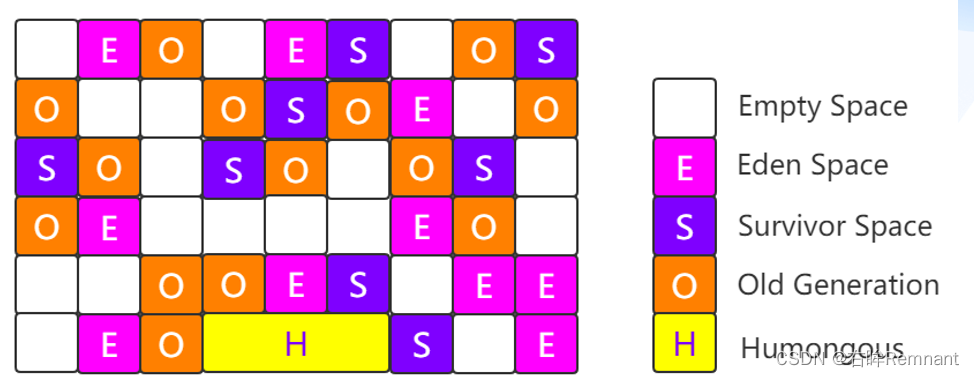
对象分为:自由对象(Empty),新生代(Eden, Survivor),Old区和大对象
Region对于自身的角色是不固定的,即可能在下次分配空间的时候角色从Old变为E或者其他JDK11之后有一类特殊的分区,叫做归档分区,关闭归档分区以及开放归档分区
TLAB:线程本地分配内存, 在G1中分配对象内存的时候,由于G1是并发处理的垃圾收集器,同一时间可能由高并发,这就涉及了数据的并发安全问题需要全局锁保证数据安全,但是会带来效率上的下降。
TLAB是Eden区上的一部分区域(1%),在分配内存的时候首先判断TLAB上是否能够分配,如果不可以,会选择TLAB外的Region区域进行分配,如果还是空间不足进行Full GC。其他概念
RSet:应用集,是G1中对与记忆集的实现,类比CMS中的卡表。
在G1中,假设有A Region, Rset会记录其他Region执行A的记录;
Q:这样做的优势是什么?
A:假设如果有O区对象指向Y区(感觉相反情况也类似),在对新生代回收的时候,还需要对O区进行一次遍历,间接的成为了全量扫描,而通过Rset可以记录到:设这里Y区对象就是A,因此Rset中的记录为O区引用,这样只需要扫描Rset就可以知道所有的引用情况了,不需要全量扫描。没深入研究的部分:稀疏表,粗粒度位图,细粒度位图
-
相关阅读:
习练真气运行法必须从调整呼吸入手
Java程序设计——Swing UI 容器(一)
深入理解LInux ELF可执行程序
理解「跨域(源)」和「跨网站」的差异与联系
【去除若依首页】有些小项目不需要首页,去除方法
【golang】go app 优雅关机 Graceful Shutdown How?
EasyRecovery适用于Windows和Mac的专业硬盘恢复软件
小程序--分包加载
数据可视化大屏设计
面试官:说一下 MyBatis 缓存机制?
- 原文地址:https://blog.csdn.net/qq_45888932/article/details/125465068