-
Redis (二)
十、主从复制
10.1 概念
主机数据更新后根据配置和策略, 自动同步到备机的 master/slaver 机制。
Master 以写为主,Slave 以读为主,主从复制节点间数据是全量的。
作用:
- 读写分离,性能扩展
- 容灾快速恢复

10.2 主从步骤
- 启动主机Master
- 启动从机Slave
- 从机上执行slaveof host port 绑定主从关系
127.0.0.1:6379> slaveof 127.0.0.1 6380Master查看主从关系:
- 127.0.0.1:6380> info replication
- # Replication
- role:master
- connected_slaves:2
- slave0:ip=127.0.0.1,port=6381,state=online,offset=193283,lag=0
- slave1:ip=127.0.0.1,port=6379,state=online,offset=193283,lag=0
- master_failover_state:no-failover
- master_replid:ef1cef04653e6e7e36e329f687892ac9107f1fa1
- master_replid2:439a4f1c1d3c6a60068376a11ffcecc4bbc2d48b
- master_repl_offset:193283
- second_repl_offset:48028
- repl_backlog_active:1
- repl_backlog_size:1048576
- repl_backlog_first_byte_offset:979
- repl_backlog_histlen:192305
Slave查看主从关系:
- 127.0.0.1:6379> info replication
- # Replication
- role:slave
- master_host:127.0.0.1
- master_port:6380
- master_link_status:up
- master_last_io_seconds_ago:0
- master_sync_in_progress:0
- slave_read_repl_offset:191512
- slave_repl_offset:191512
- slave_priority:100
- slave_read_only:1
- replica_announced:1
- connected_slaves:0
- master_failover_state:no-failover
- master_replid:ef1cef04653e6e7e36e329f687892ac9107f1fa1
- master_replid2:0000000000000000000000000000000000000000
- master_repl_offset:191512
- second_repl_offset:-1
- repl_backlog_active:1
- repl_backlog_size:1048576
- repl_backlog_first_byte_offset:189866
- repl_backlog_histlen:1647
普通主从关系的Master/Slave的上线/下线(非哨兵模式)
- 主机下线后,从机仍然可用,但不会产生新的主机
- 主机恢复后,主从关系不变
- 从机下线后,移除主从关系,但不影响主机与其他从机的主从关系
- 从机重启后,需手动执行slaveof,重新绑定主从关系
薪火相传
主从关系允许传递,即一个服务器即可作为从机也可以作为其他从机的主机。
降低真正主机的同步压力。
但同步时延会更长。

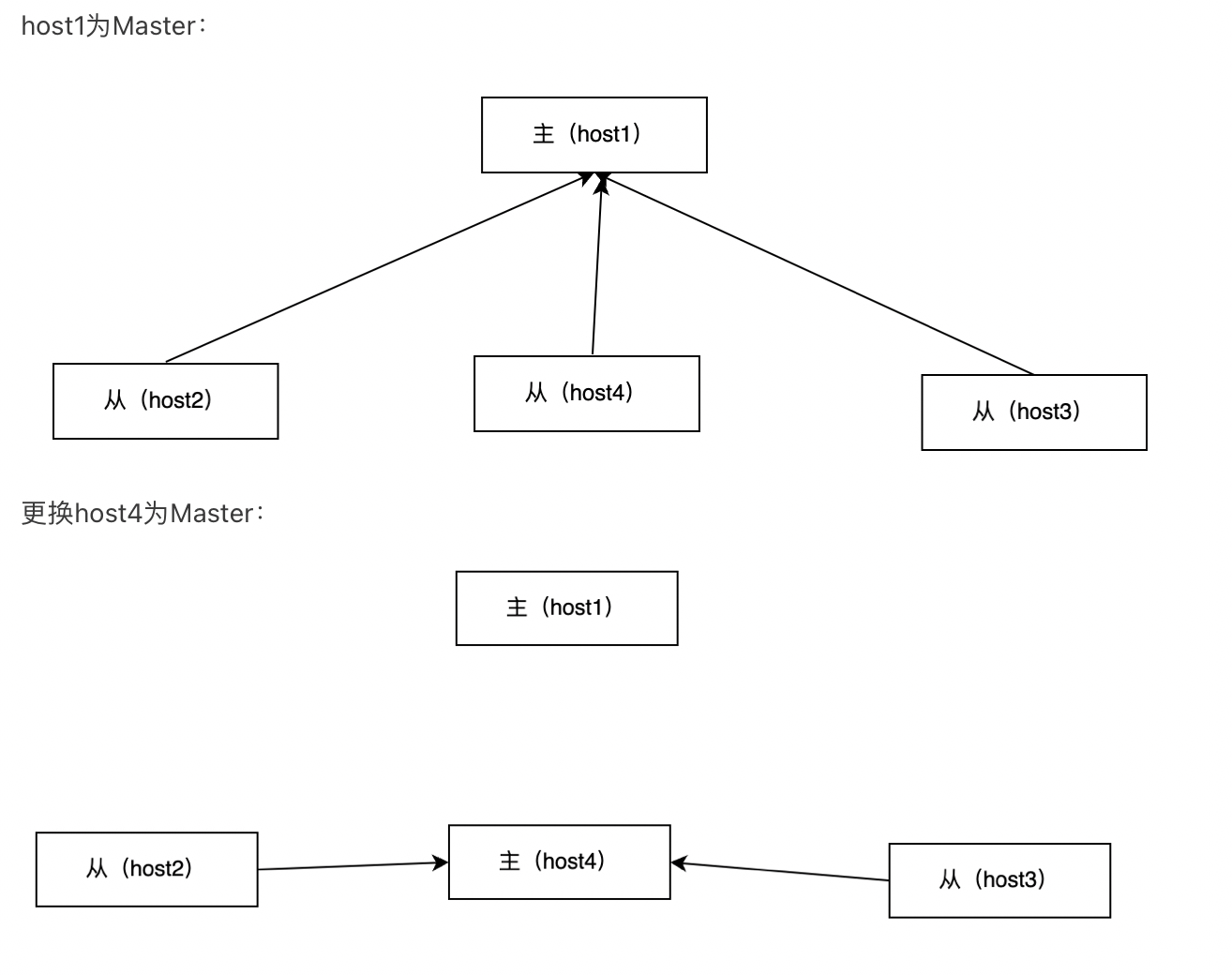
反客为主
非哨兵模式下,当Master下线后,不会自动产生新的Master。
若想使用新的Master,则需要手动的执行如下操作:
- 选择一个Slave,执行slaveof no one,使其成为Master
- 在其他的Slave中,执行slaveof [master] [port],绑定新的主从关系。
示例:
10.3 主从复制原理
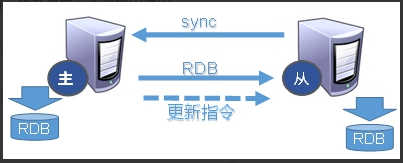
- Slave 启动成功连接到 master 后会发送一个 sync 命令;
- Master 接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master 将传送整个数据文件到 slave,以完成一次完全同步。
- 全量复制:slave 服务器在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master 继续将新的所有收集到的修改命令依次传给 slave,完成同步。
- 但是只要是重新连接 master,一次完全同步(全量复制) 将被自动执行。
10.4 哨兵模式 (sentinel)
哨兵模式是反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。

当主机挂掉,根据如下三个条件由从机选举产生新的主机:
- 优先级:在 redis.conf 中默认 slave-priority 100,值越小优先级越高。
- 偏移量:指获得原主机数据最全的概率。
- runid:每个 redis 实例启动后都会随机生成一个 40 位的 runid。
原主机重启后会变为从机。

步骤:
- 主从启动仍同上述步骤相同
- 需新增哨兵节点
新增哨兵监控配置:
- vi sentinel.conf
- sentinel monitor mymaster 127.0.0.1 6379 1
启动哨兵:
redis-sentinel sentinel.conf10.4 复制延时
由于所有的写操作都是先在 Master 上操作,然后同步更新到 Slave 上,所以从 Master 同步到 Slave 机器有一定的延迟。
当系统很繁忙的时候,延迟问题会更加严重,Slave 机器数量的增加也会使这个问题更加严重。
- 当主节点和从节点第一次连接时,会把生成的RDB文件全量复制给从节点。
- 期间,可能主节点会收到写命令等修改数据,这时主节点会用缓冲区来记录这些写命令,然后等到RDB文件发送完成后再把缓冲区的写命令发送给从节点。
- 如果有多个从节点,则可以通过从节点复制给从节点的方式来减轻主节点的压力。
- 如果主从同步的时候,网络断开了,则可以根据偏移量来进行增量复制,从而保证主从数据一致性。
不保证强一致性,但保证了最终一致性,提高吞吐量。
十一、集群
11.1 概念
Redis 集群(包括很多小集群)实现了对 Redis 的水平扩容,即启动 N 个 redis 节点,将整个数据库分布存储在这 N 个节点中,每个节点存储总数据的 1/N,即一个小集群存储 1/N 的数据,每个小集群里面维护好自己的 1/N 的数据。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
该模式的 redis 集群特点是:分治、分片。
11.2 搭建及启停
11.2.1 搭建集群
1、配置redis.conf中的端口、进程文件等信息
保证进程端口不冲突即可。
- port 6379
- pidfile "/var/run/redis_6379.pid"
- dbfilename "dump_6379.rdb"
2、设置redis.conf集群相关配置项
- cluster-enabled yes
- cluster-config-file nodes-6379.conf
- cluster-node-timeout 15000
3、正常启动redis服务
redis-server redis_6379.conf4、创建集群环境
所有redis服务启动后,在任一服务器中创建redis集群环境。
(注意此处是为了模拟所以IP都在同一台服务器上)
redis-cli --cluster create --cluster-replicas 1 10.21.176.206:6377 10.21.176.206:6378 10.21.176.206:6379 10.21.176.206:6387 10.21.176.206:6388 10.21.176.206:6389启动成功信息:
- ...
- [OK] All nodes agree about slots configuration.
- >>> Check for open slots...
- >>> Check slots coverage...
- [OK] All 16384 slots covered.
11.2.2 连接
一旦创建了集群环境,再使用默认的连接方式,虽然可以成功连接,但操作会失败。
需以集群的方式连接:
redis-cli -c -h 10.21.176.206 -p 6379连接后即可查看集群信息:
10.21.176.206:6378> cluster nodes集群信息,展示了主从关系及插槽分配
- a4f8c0d2fc5945c5d40313cb2a5d1b319326348d 10.21.176.206:6377@16377 master - 0 1656124082792 1 connected 0-5460
- a81763fb76280d1e4531ab386f2a17c5153edab3 10.21.176.206:6379@16379 master - 0 1656124081000 3 connected 10923-16383
- cb073f3dba5f3d275c8932241e4d0321af2b188f 10.21.176.206:6389@16389 slave 86acdf59984c3e947bb7e741d885bcae8c1f6bb6 0 1656124082000 2 connected
- 86acdf59984c3e947bb7e741d885bcae8c1f6bb6 10.21.176.206:6378@16378 myself,master - 0 1656124080000 2 connected 5461-10922
- 13c71f711488c4dc0577d7c62f3f6c62ee88acc8 10.21.176.206:6387@16387 slave a81763fb76280d1e4531ab386f2a17c5153edab3 0 1656124081779 3 connected
- a832ebaee968cea9f2c9c1a05f2a962881589469 10.21.176.206:6388@16388 slave a4f8c0d2fc5945c5d40313cb2a5d1b319326348d 0 1656124082000 1 connected
11.2.3 关闭集群
关闭集群仅需关闭每一个节点服务即可。
注意要保证每个节点都关闭,否则会影响再次创建集群环境。
11.2.4 往集群中添加节点
往已有集群中再添加节点,大致分为如下几步:
1、添加master
加入集群
redis-cli --cluster add-node [节点ip:port] [集群中任意节点ip:port]手动分配slot
新加的节点没有分配任何slot,需要手动将已有节点的插槽slot分配给新加的节点。
redis-cli --cluster reshard ...2、若添加从机,则需要指明主机
redis-cli --cluster add-node [节点ip:port] [master节点ip:port] --cluster-slave --cluster-master-id [masterid]11.3 集群数据分配
redis cluster 如何分配节点
redis-cli --cluster create --cluster-replicas 1 10.21.176.206:6377 10.21.176.206:6378 10.21.176.206:6379 10.21.176.206:6387 10.21.176.206:6388 10.21.176.206:6389- 一个集群至少要有三个主节点
- 选项 –cluster-replicas 1 :表示我们希望为集群中的每个主节点创建一个从节点。
- 分配原则尽量保证每个主数据库运行在不同的 IP 地址,每个从库和主库不在一个 IP 地址上。
什么是 slots
一个 Redis 集群包含 16384 (2的14次方)个插槽(hash slot),数据库中的每个键都属于这 16384 个插槽的其中一个。
集群使用公式 CRC16 (key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16 (key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
- 节点 A 负责处理 0 号至 5460 号插槽。
- 节点 B 负责处理 5461 号至 10922 号插槽。
- 节点 C 负责处理 10923 号至 16383 号插槽。
在集群中录入值
在 redis-cli 每次录入、查询键值,redis 都会计算出该 key 应该送往的插槽,如果不是该客户端对应服务器的插槽,redis 会报错,并告知应前往的 redis 实例地址和端口。
redis-cli 客户端提供了 –c 参数实现自动重定向。如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。不在一个 slot 下的键值,是不能使用 mget,mset 等多键操作。
集群中常用命令
- //计算插槽
- 127.0.0.1:6379> cluster keyslot k1
- (integer) 12706
- //查看插槽中的键数(仅当此插槽段分配给当前主机时有效)
- 127.0.0.1:6379> cluster countkeysinslot 12706
- (integer) 1
11.4 故障恢复
主从恢复
主节点下线,从节点会自动升为主节点。(注意:timeout秒后)
主机下线后再恢复,再上线后会变成从机。
集群故障
如果所有某一段插槽的主从节点都宕掉,redis 服务是否还能继续?
- 如果某一段插槽的主从都挂掉,而 cluster-require-full-coverage 为 yes ,那么整个集群都挂掉。
- 如果某一段插槽的主从都挂掉,而 cluster-require-full-coverage 为 no ,那么该插槽数据全都不能使用也无法存储。
11.5 Jedis连接
- public void clusterDemo(){
- //连接任意节点即可
- HostAndPort hostAndPort = new HostAndPort("10.21.176.206", 6379);
- JedisCluster jedisCluster = new JedisCluster(hostAndPort);
- jedisCluster.set("name", "test1");
- String name = jedisCluster.get("name");
- System.out.println(name);
- }
11.6 总结
Redis 集群优点
- 实现扩容
- 分摊压力
- 无中心配置相对简单
Redis 集群不足
- 多键操作是不被支持的。
- 多键的 Redis 事务是不被支持的,lua 脚本不被支持。
- 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至 redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
十二、应用问题解决
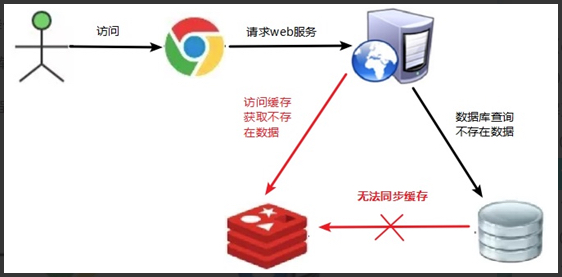
12.1 缓存穿透
问题描述
key 对应的数据在数据源并不存在,每次针对此 key 的请求从缓存获取不到,请求都会压到数据源(数据库),从而可能压垮数据源。
比如用一个不存在的用户 id 获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
缓存穿透发生的条件:
- 应用服务器压力变大
- redis 命中率降低
- 一直查询数据库,使得数据库压力太大而压垮
其实 redis 在这个过程中一直平稳运行,崩溃的是我们的数据库(如 MySQL)。
缓存穿透发生的原因:黑客或者其他非正常用户频繁进行很多非正常的 url 访问,使得 redis 查询不到,压力给到数据库。
解决方案
- 对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟。
- 设置可访问的名单(白名单):使用 bitmaps 类型定义一个可以访问的名单,名单 id 作为 bitmaps 的偏移量,每次访问和 bitmap 里面的 id 进行比较,如果访问 id 不在 bitmaps 里面,进行拦截,不允许访问。
- 采用布隆过滤器:布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量 (位图) 和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
- 进行实时监控:当发现 Redis 的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务。
12.2 缓存击穿
问题描述
key 对应的数据存在,但在 redis 中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端数据库加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端数据库压垮。
缓存击穿的现象:
- 数据库访问压力瞬时增加,数据库崩溃
- redis 里面没有出现大量 key 过期
- redis 正常运行
缓存击穿发生的原因:redis 某个 key 过期了,大量访问使用这个 key(热门 key)。

解决方案
key 可能会在某些时间点被超高并发地访问,是一种非常 “热点” 的数据。
- 预先设置热门数据:在 redis 高峰访问之前,把一些热门数据提前存入到 redis 里面,加大这些热门数据 key 的时长。
- 实时调整:现场监控哪些数据热门,实时调整 key 的过期时长。
- 使用锁:
- 就是在缓存失效的时候(判断拿出来的值为空),不是立即去 load db。
- 先使用缓存工具的某些带成功操作返回值的操作(比如 Redis 的 SETNX)去 set 一个 mutex key。
- 当操作返回成功时,再进行 load db 的操作,并回设缓存,最后删除 mutex key;
- 当操作返回失败,证明有线程在 load db,当前线程睡眠一段时间再重试整个 get 缓存的方法。

12.3 缓存雪崩
问题描述
key 对应的数据存在,但在 redis 中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端数据库加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端数据库压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多 key 缓存,前者则是某一个 key 正常访问。

缓存失效瞬间:

解决方案
- 构建多级缓存架构:nginx 缓存 + redis 缓存 + 其他缓存(ehcache 等)。
- 使用锁或队列:用加锁或者队列的方式来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上,该方法不适用高并发情况。
- 设置过期标志更新缓存:记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际 key 的缓存。
- 将缓存失效时间分散开:比如可以在原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
12.4 分布式锁
12.4.1 问题描述
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程的特点以及分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的 Java API 并不能提供分布式锁的能力。为了解决这个问题就需要一种跨 JVM 的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题。
分布式锁主流的实现方案:
- 基于数据库实现分布式锁
- 基于缓存(Redis 等)
- 基于 Zookeeper
根据实现方式,分布式锁还可以分为类 CAS 自旋式分布式锁以及 event 事件类型分布式锁:
- 类 CAS 自旋式分布式锁:询问的方式,类似 java 并发编程中的线程获询问的方式尝试加锁,如 mysql、redis。
- 另外一类是 event 事件通知进程后续锁的变化,轮询向外的过程,如 zookeeper、etcd。
每一种分布式锁解决方案都有各自的优缺点:
- 性能:redis 最高
- 可靠性:zookeeper 最高
12.4.2 使用 redis 实现分布式锁

- setnx:通过该命令尝试获得锁,没有获得锁的线程会不断等待尝试。
- set key ex 3000nx:设置过期时间,自动释放锁,解决当某一个业务异常而导致锁无法释放的问题。但是当业务运行超过过期时间时,开辟监控线程增加该业务的运行时间,直到运行结束,释放锁。
- uuid:设置 uuid,释放前获取这个值,判断是否自己的锁,防止误删锁,造成没锁的情况。
Java示例:
- public static void testLock() throws InterruptedException {
- Jedis jedis = new Jedis("127.0.0.1", 6379);
- //1、声明唯一uuid
- String lockValue = UUID.randomUUID().toString();
- //2、尝试获取锁
- SetParams nx = new SetParams().ex(2).nx();
- String lock = jedis.set(lockKey, lockValue, nx);
- System.out.println(lock);
- if ("OK".equals(lock)) {
- //3、获取得到就处理业务,处理完成后释放锁
- value++;
- //4、释放锁 (避免业务处理时长 > 过期时间,导致删掉其他线程的锁)
- if (lockValue.equals(jedis.get(lockKey))) {
- //★★
- jedis.del(lockKey);
- }
- } else {
- //5、获取不到则睡眠一会再次尝试
- Thread.sleep(1000);
- testLock();
- }
- }
注意一下两点:
- 创建锁时要同时设置过期时间。否则若创建完锁后,连接断掉未设置过期时间,会导致其他线程始终无法获取到锁。
- 释放锁时要判断是否是当前线程加的锁值。避免因业务超时锁自动释放后,误删除掉其他线程的锁。
即使保证了如上两点,★★处仍有可能误删其他线程的锁:锁值是当前线程添加的,符合删除条件。但准备删除的一瞬间,若锁到达超时时间自动释放,且被其他线程获取到并加锁,则删除时会误删掉其他线程的锁。

鉴于上述可能,可采用LUA脚本方式:
- public static void testLock() throws InterruptedException {
- Jedis jedis = new Jedis("127.0.0.1", 6379);
- //1、声明唯一uuid
- String lockValue = UUID.randomUUID().toString();
- //2、尝试获取锁
- SetParams nx = new SetParams().ex(2).nx();
- String lock = jedis.set(lockKey, lockValue, nx);
- System.out.println(lock);
- if ("OK".equals(lock)) {
- //3、获取得到就处理业务,处理完成后释放锁
- value++;
- //4、释放锁
- String script = "if redis.call('get', KEYS[1]) == KEYS[2] then return redis.call('del', KEYS[1]) else return 0 end";
- String sha1 = jedis.scriptLoad(script);
- Object result = jedis.evalsha(sha1, 2, lockKey, lockValue);
- System.out.println(result);
- } else {
- //5、获取不到则睡眠一会再次尝试
- Thread.sleep(1000);
- testLock();
- }
- }
12.4.3 RedLock
Redlock 是一种算法,Redlock 也就是 Redis Distributed Lock,可用实现多节点 redis 的分布式锁。
RedLock 官方推荐,Redisson 完成了对 Redlock 算法封装。
此种方式具有以下特性:
- 互斥访问:即永远只有一个 client 能拿到锁。
- 避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使锁定资源的服务崩溃或者分区,仍然能释放锁。
- 容错性:只要大部分 Redis 节点存活(一半以上),就可以正常提供服务
RedLock 原理(了解)
- 获取当前 Unix 时间,以毫秒为单位。
- 依次尝试从 N 个实例,使用相同的 key 和随机值获取锁。在步骤 2,当向 Redis 设置锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为 10 秒,则超时时间应该在 5-50 毫秒之间。这样可以避免服务器端 Redis 已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试另外一个 Redis 实例。
- 客户端使用当前时间减去开始获取锁时间(步骤 1 记录的时间)就得到获取锁使用的时间。当且仅当从大多数(这里是 3 个节点)的 Redis 节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key 的真正有效时间等于有效时间减去获取锁所使用的时间(步骤 3 计算的结果)。
- 如果因为某些原因,获取锁失败(没有在至少 N/2+1 个 Redis 实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的 Redis 实例上进行解锁(即便某些 Redis 实例根本就没有加锁成功)。
13 新版功能
6.0之后版本添加的功能。
13.1 ACL 访问控制列表
Access Control List功能允许设置用户可以执行的命令和键。
比如:
- //查看当前acl权限列表
- 127.0.0.1:6379> acl list
- 1) "user default on nopass ~* &* +@all"
- //查看当前用户
- 127.0.0.1:6379> acl whoami
- "default"
添加acl:
- 127.0.0.1:6379> acl setuser xiang on >xiang ~cache:* +get
- OK
切换用户后,该用户访问受限
- 127.0.0.1:6379> auth xiang xiang
- 127.0.0.1:6379> get cache
- (error) NOPERM this user has no permissions to access one of the keys used as arguments
- 127.0.0.1:6379> get cache:
- (nil)
13.2 IO多线程
简介
IO 多线程其实指客户端交互部分的网络 IO 交互处理模块 多线程,而非执行命令多线程。
Redis6 执行命令依然是单线程。
原理架构
Redis 6 加入多线程,但跟 Memcached 这种从 IO 处理到数据访问多线程的实现模式有些差异。Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。之所以这么设计是不想因为多线程而变得复杂,需要去控制 key、lua、事务,LPUSH/LPOP 等等的并发问题。整体的设计大体如下:

另外,多线程 IO 默认也是不开启的,需要再配置文件中配置:
- io-threads-do-reads yes
- io-threads 4
14 总结
加油加油!
-
相关阅读:
【SQL刷题】Day10----SQL高级过滤函数专项练习
ffmpeg的基本功能介绍
服务器中毒的原因以及如何预防
Node.js 实战 第2章 Node 编程基础 2.3 用module.exports 微调模块的创建
Rliger | 完美整合单细胞测序数据(部分交集数据的整合)(三)
字符串的创建及常用方法大全
Java中的局部变量和成员变量的区别
2022.07月总结
挑战算法题:四数之和
你了解TLS协议吗?
- 原文地址:https://blog.csdn.net/guaituo0129/article/details/125462711