-
Mysql高级篇学习总结7:Mysql数据结构-Hash索引、AVL树、B树、B+树的对比
1、Mysql数据结构选择分析
上一篇介绍了介绍了B+树的索引方式,其实还有其他的索引方式,本篇就来了解下,顺便看一下innoDB当时为什么没有选择其他的索引方式,而是选择了B+树作为默认的索引方式。
1.1 全表遍历
PASS,这个就不用比较了。
1.2 Hash结构
Hash算法是通过某种确定性算法(比如MD5, SHA1, SHA2, SHA3)将输入转变为输出。相同的输入永远可以得到相同的输出。
加速查找速度的数据结构,常见的有2类:
- 树。比如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度为O(log2n)
- 哈希。比如HashMap,查询/插入/修改/删除的平均时间复杂度为O(1)
Hash结构效率很高,那为什么索引结构要设计成树型呢?
- Hash索引只能满足等于(=),不等于(!=),和IN的查询。如果进行范围查询,那么哈希型的索引就会退化为O(n),而树型特性依然能保持O(log2n)的时间复杂度。
- Hash索引还有一个缺陷,它的数据存储是没有顺序的。在order by的情况下,Hash索引还需要对数据重新排序。
- 对于联合索引的情况下,Hash值是将联合索引键合并后来计算hash的,无法对单独的一个键或者几个索引键进行查询。
- 虽然等值查询,hash索引的效率会更高。但是如果索引列重复值如果很多,那么效率就会降低。因为hash冲突时,需要遍历桶的行指针来进行比较,找到查询的关键字,非常耗时。
Hash索引使用存储引擎情况如下表,只有Memory存储引擎支持。

Mysql的Memory存储引擎支持Hash索引,如果需要用到查询的临时表时,可以选择Memory存储引擎。然后把某个字段设置为Hash索引,当字段的重复度低,并且经常需要进行等值查询的时候,采用Hash索引是个不错的选择。
另外,InnoDB本身虽然不支持Hash索引,但是它提供了自适应Hash索引(Adaptive Hash Index)。比如某个数据经常被访问,那么InnoDB就会将这个数据页的地址存放到Hash表中。这样下次再进行相同的检索条件时,就可以直接找到这个页面的所在位置了。
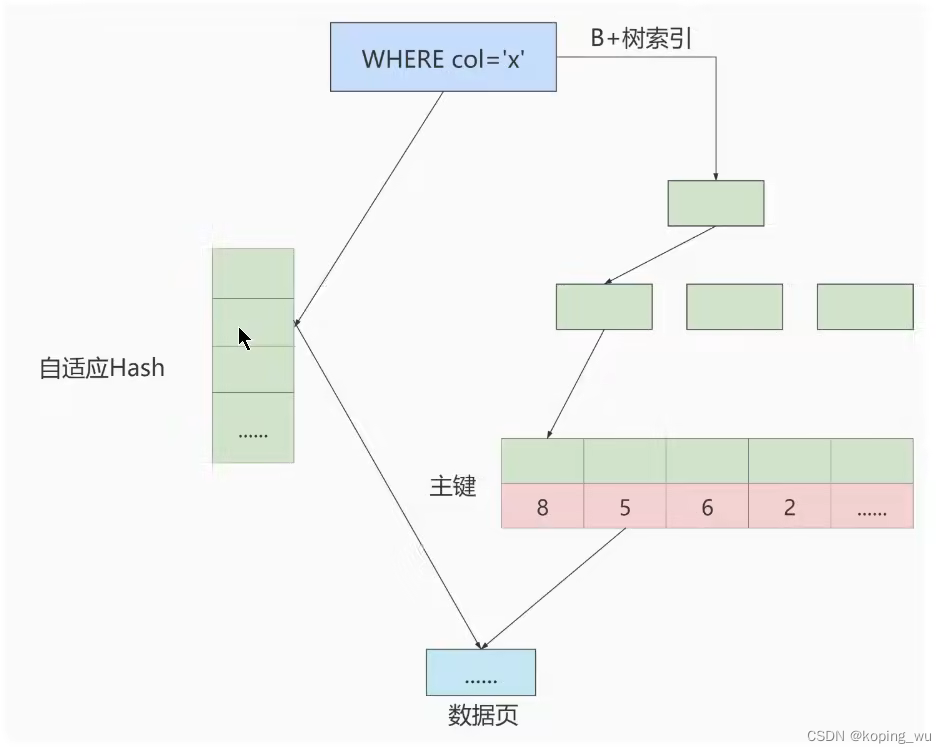
可以通过innodb_adaptive_hash_index变量来查看是否开启了自适应Hash:mysql> show variables like '%adaptive_hash_index'; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | innodb_adaptive_hash_index | ON | +----------------------------+-------+ 1 row in set (0.33 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.2 二叉搜索树
1、二叉搜索树的特点
- 一个节点只有2个子节点
- 左子节点<本节点,右子节点>=本节点
2、查找规则 - 如果key等于根节点,返回根节点的用户数据记录
- 如果key大于根节点,则在右子树中找
- 如果key小于根节点,则在左子树中找
二叉搜索树的缺点是在特别情况下,查找数据的时间复杂度会退化为O(n)。比如下图:
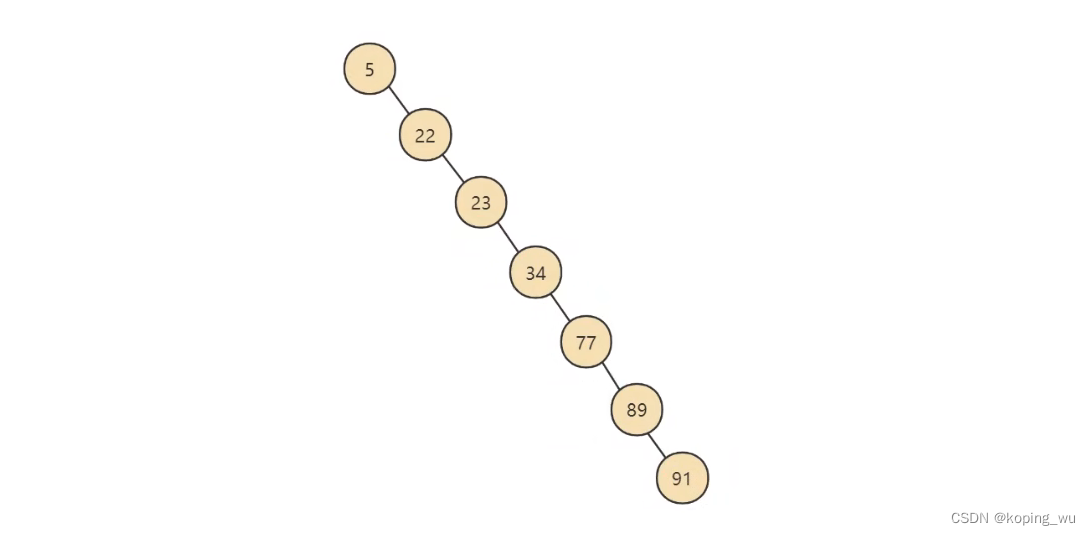
为了避免上图的情况,当然核心是为了减少磁盘I/O的次数,就需要尽量降低树的高度。
1.3 AVL树
为了解决上面二叉搜索树退化为链表的问题,又提出了平衡二叉搜索树(Balanced Binary Tree),又称为AVL树:
它是一颗空树,或者它的左右两个子树的高度差不超过1,并且左右两个子树都是一颗平衡二叉树。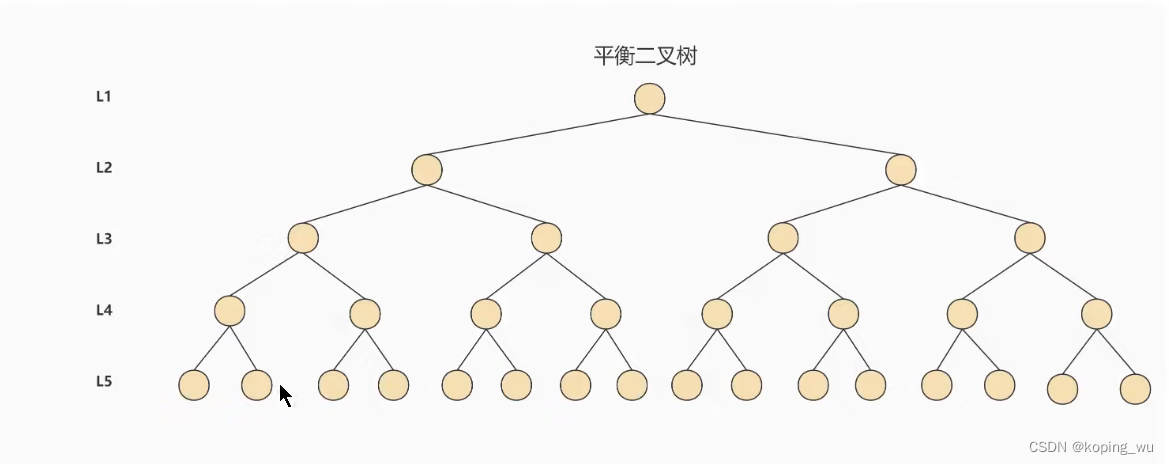
为了尽可能的降低磁盘I/O的次数,也就是降低树的高度,因此可以将二叉树改为M叉树(M>2),这样树的高度就可以变得更低一点了。
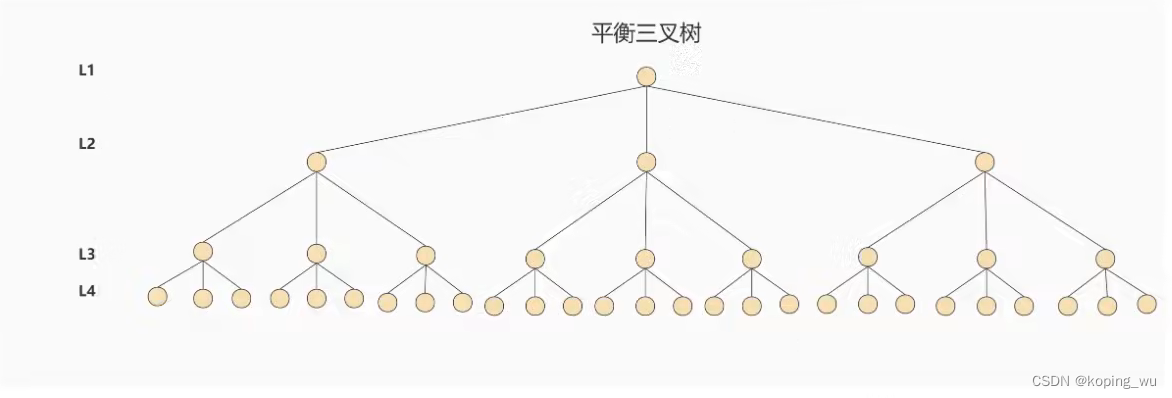
1.4 B树
当上面提到的M叉树的M值更大的时候,就可以理解为是一颗B树了。
注意区分下B树和B+树的区别。
B树的目录项记录里面是直接包含了用户记录数据的,而B+树只有叶子节点才包含用户记录数据的。
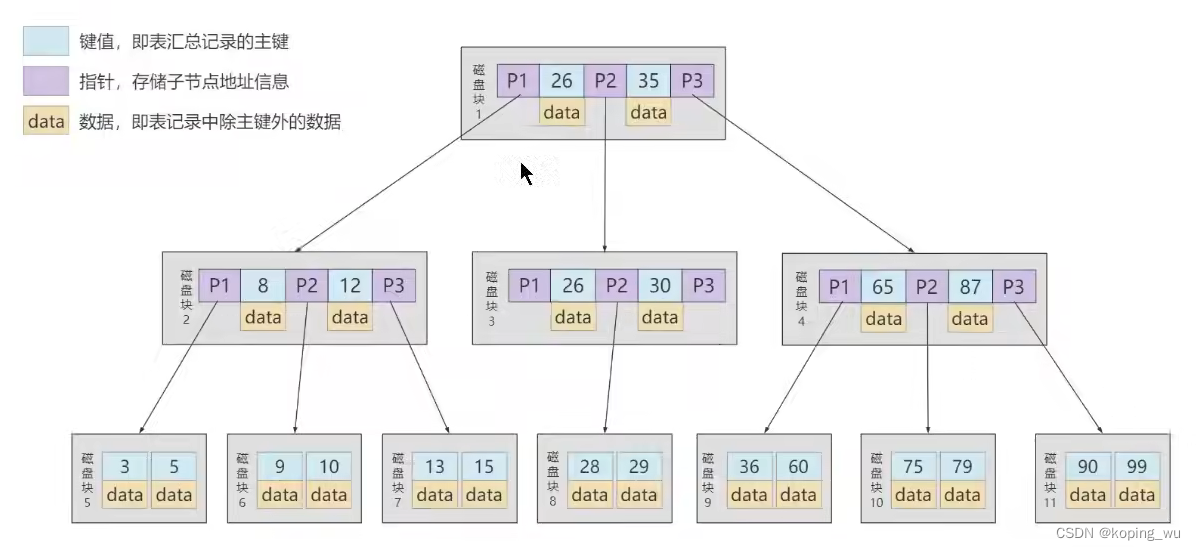
那为什么使用B+树,不适用B树呢?
- B+树查询效率更稳定。B+树每次只有访问到叶子节点才能找到对应数据,而B树中,非叶子节点也会存储数据,这样就会造成查询效率不稳定的情况。
- B+树查询效率更高。因为B树中还保存了用户记录的数据,所以每一个数据页能保存的数量要少于B+树的目录项记录的数量,所以B+树的高度会更低一点,因此所需要的磁盘I/O会更少一点。
- 在查询范围上,B+树的效率会更高。因为所有关键字都出现在B+树的叶子节点,数据是递增的,因为可以通过二分查找快速找到。而B树本质上还是二叉搜索的搜索逻辑,因此需要通过中序遍历才能完成查询范围的查找,效率要低很多。
-
相关阅读:
路线中桩测量计算程序浅析
Cadence orcad 原理图导出带书签目录的办法
IDEA配置Tomcat,先报500错误,刷新后报404.
ES6 Reflect
kubernetes 之 minikube折腾记
LabVIEW程序代码更新缓慢
食堂报餐订餐系统小程序_吃饭用餐人数统计缴费软件开发及介绍
Hive_Hive统计指令analyze table和 describe table
Go如何优雅的记录操作日志
MySQL SQL语句与事务执行及日志分析
- 原文地址:https://blog.csdn.net/xueping_wu/article/details/125459873