-
【强化学习】policy gradient的一些tips
Tip 1: Add a baseline
θ ← θ + η ∇ R ˉ θ ∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( R ( τ n ) − b ) ∇ l o g p θ ( a t n ∣ s t n ) \theta \leftarrow \theta+\eta\nabla\bar{R}_{\theta}\\ \nabla\bar{R}_{\theta} \approx \frac{1}{N}\sum ^{N}_{n=1}\sum^{T_n}_{t=1}(R(\tau^n)-b)\nabla logp_\theta (a^n_t|s_t^n) θ←θ+η∇Rˉθ∇Rˉθ≈N1n=1∑Nt=1∑Tn(R(τn)−b)∇logpθ(atn∣stn)
Why?
很多场景中奖励都是正的,在采样的时候不是所有的动作都能被采样到。采样到的动作,概率会上升,那么没有被采样到的动作概率就会下降。但未被采样的动作不一定是不好的动作,只是因为没有被采样到。
因此我们希望奖励不要永远都是正的。
How?
奖励减掉一项b,叫做baseline,即可让 ( R ( τ n ) − b ) (R(\tau^n)-b) (R(τn)−b)有正有负。若此项为正,概率上升,此项为负,概率下降。
∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( R ( τ n ) − b ) ∇ l o g p θ ( a t n ∣ s t n ) b ≈ E [ R ( τ ) ] \nabla\bar{R}_{\theta} \approx \frac{1}{N}\sum ^{N}_{n=1}\sum^{T_n}_{t=1}(R(\tau^n)-b)\nabla logp_\theta (a^n_t|s_t^n) \\ b\approx E[R(\tau)] ∇Rˉθ≈N1n=1∑Nt=1∑Tn(R(τn)−b)∇logpθ(atn∣stn)b≈E[R(τ)]
b取轨迹奖励的期望,在训练的时候,不断记录 R ( τ ) R(\tau) R(τ)并计算平均值。这是其中一种做法,当然也有其他做法。Tip 2: Assign Suitable Credit
Why?
∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( R ( τ n ) − b ) ∇ l o g p θ ( a t n ∣ s t n ) \nabla\bar{R}_{\theta} \approx \frac{1}{N}\sum ^{N}_{n=1}\sum^{T_n}_{t=1}(R(\tau^n)-b)\nabla logp_\theta (a^n_t|s_t^n) ∇Rˉθ≈N1n=1∑Nt=1∑Tn(R(τn)−b)∇logpθ(atn∣stn)
在式子中,一个episode的所有state-action对都使用同样的奖励项,这显然是不公平的。有些动作是好的,有些是不好的。即使整场游戏结果是好的,但并不代表每一个动作都是对的。若整场游戏结果是坏的,也不代表所有的动作都是错的。因此我们希望不同动作有不同的权重。
How?
一个做法是,计算某个state-action的奖励的时候,不把所有的奖励加起来,只计算这个动作执行之后所获得的奖励。

再进一步,我们可以把未来的奖励做一个discount。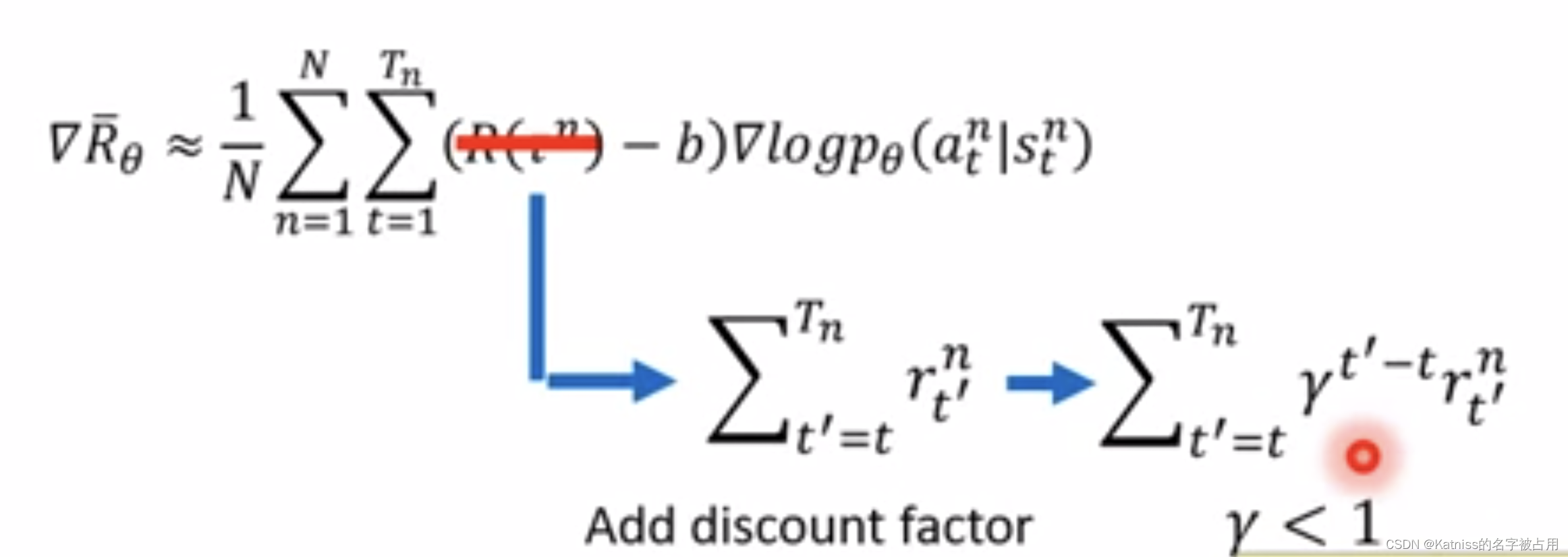
Conclusion
优势函数Advantage Fuction衡量在状态 s t s_t st采取动作 a t a_t at相较于其他动作有多好。它通常是network(critic)估计出来的。

-
相关阅读:
由于找不到vcruntime140_1.dll怎么修复,详细修复步骤分享
python使用pandas中的read_csv函数读取csv数据为dataframe、筛选dataframe中的一个数据列的前几行数据
责任链模式
kubernetes工作负载之控制器
Linux tar 压缩 解压
【开源库推荐】go-linq 强大的语言集成查询库如,ORM一般丝滑处理内存数据
mac电脑识别不出来u盘?mac识别不了u盘怎么办
MapReduce实现平均分计算
echarts图表toolbox工具箱配置
Google Data Fusion构建数据ETL任务
- 原文地址:https://blog.csdn.net/qq_42251120/article/details/125459943