-
数据库查询优化:主从读写分离及常见问题
1.主从读写分离基本原理
大部分系统的访问模型是读多写少,读写请求量的差距可能达到几个数量级。
依据一些云厂商的 Benchmark 的结果,在 4 核 8G 的机器上运行 MySQL 5.7 时,大概可以支撑 500 的 TPS 和 10000 的 QPS。
当单机MySQL无法承受过高的QPS时,可以组建MySQL主从读写分离集群来将读请求分摊到多个从节点中,以实现水平拓展。1.1.主从复制过程
- 主库db的更新事件(update、insert、delete)被写到binlog
- 从库发起连接,连接到主库
- 此时主库创建一个binlog dump thread,把binlog的内容发送到从库
- 从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到中继日志(relay log)
- 还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
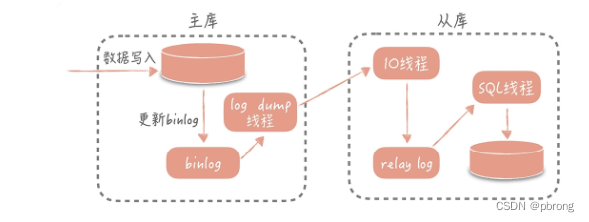
做了主从复制之后,我们就可以在写入时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响到读请求的执行。同时呢,在读流量比较大的情况下,我们可以部署多个从库共同承担读流量,这就是所说的“一主多从”部署方式。
1.2.是否可以无限拓展从节点
为了应对更高的数据库读取QPS,是否可以无限拓展从节点来抵抗大量并发呢?答案是不能。
因为随着从库数量增加,从库连接上来的 IO 线程比较多,主库也需要创建同样多的 log dump 线程来处理复制的请求,对于主库资源消耗比较高,同时受限于主库的网络带宽,所以在实际使用中,一般一个主库最多挂 3~5 个从库。2.主从读写分离模式-SDK及独立Proxy部署
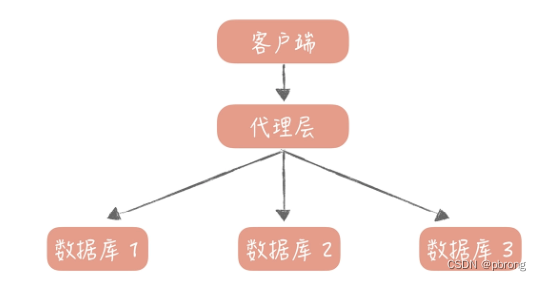
使用主从复制的技术将数据复制到了多个节点,也实现了数据库读写的分离,这时,对于数据库的使用方式发生了变化。以前只需要使用一个数据库地址就好了,现在需要使用一个主库地址和多个从库地址,并且需要区分写入操作和查询操作,复杂度会提升更多。为了降低实现的复杂度,业界涌现了很多数据库中间件来解决数据库的访问问题,这些中间件可以分为两类:SDK类及独立Proxy部署类。
2.1.SDK类
以淘宝的 TDDL( Taobao Distributed Data Layer)为及Sharding—JDBC为代表,以代码形式内嵌运行在应用程序内部。你可以把它看成是一种数据源的代理,它的配置管理着多个数据源,每个数据源对应一个数据库,可能是主库,可能是从库。
当有一个数据库请求时,中间件将 SQL 语句发给某一个指定的数据源来处理,然后将处理结果返回。SDK优点是简单易用,没有多余的部署成本,缺点是和编程语言高度绑定,比如TDDL和Sharding-JDBC都只能在Java中使用,版本升级也较为困难。2.2.Proxy类
另一类是单独部署的代理层方案,这一类方案代表比较多,如早期阿里巴巴开源的 Cobar,基于 Cobar 开发出来的 Mycat,360 开源的 Atlas,美团开源的基于 Atlas 开发的 DBProxy 等等。
这一类中间件部署在独立的服务器上,业务代码如同在使用单一数据库一样使用它,实际上它内部管理着很多的数据源,当有数据库请求时,它会对 SQL 语句做必要的改写,然后发往指定的数据源。
它一般使用标准的 MySQL 通信协议,所以可以很好地支持多语言。由于它是独立部署的,所以也比较方便进行维护升级,比较适合有一定运维能力的大中型团队使用。它的缺陷是所有的 SQL 语句都需要跨两次网络:从应用到代理层和从代理层到数据源,所以在性能上会有一些损耗。
3.主从读写分离会遇到的问题及解决办法
主从读写分离可以使得数据库扛住更多的读压力,但是问题也会随之而来:主从复制间是异步的,存在延迟现象:从库消费中转日志的速度比主库生产binlog的速度慢。
一般来说,可以尝试提升从库规格(CPU、内存)来降低这个延迟时间,但是主从延迟客观上来讲肯定会存在的,特别是写入量很大的时候,这个时候会遇到一个问题:
在数据写入主库后立刻从库读取数据,此时数据可能尚未复制,导致获取数据失败或者数据不一致。解决主从延迟读取不一致问题的方案主要思路:
- 第一种方案是数据冗余:在需要立刻读取写入数据的场景,不要传递数据ID查数据库,而是直接传递整个最新的数据。
- 第二种方案是使用缓存:写入主库的时候,把这份数据也写入Redis中,需要立刻查询时先查缓存获取这份最新的数据。
- 第三种方案是查主库:不允许出现不一致的数据时,可以直接路由到主库查询,但是这种做法会对主库造成很大压力,需要做好限流,避免把主库给打挂。
-
相关阅读:
gin框架再探
springboot vue街球社区网站java
HG/T 5367.5-2022 轨道交通车辆用防结冰涂料检测
Python是什么?要如何学习?
Linux cat命令详解
Android 13.0 屏蔽FallbackHome机制去掉android正在启动直接进入默认Launcher功能实现
STM32串口通信-简单版
sql多表查询,嵌套查询,函数查询
Python中处理HTTP异常和错误的策略
聊一聊数据库的行存与列存
- 原文地址:https://blog.csdn.net/pbrlovejava/article/details/125460063