-
prometheus告警流程及相关时间参数说明
说明
用prometheus做监控,从告警事件发生到我们收到告警信息中间经历了很多流程,了解其中的流程及相关的时间配置,就能更及时、高效的获取告警信息。
以下记录下prometheus告警生命周期/流程、相关配置参数和告警案例说明。
prometheus告警生命周期/流程
- prometheus定时采集指标数据
- prometheus定时计算是否指标触发规则
- 触发规则的指标告警状态转为pending,当持续时间超过for指定的时间后,转换为firing,并将告警发送到alertmanager
- alertmanager收到告警后,等待一段分组时间,到时间后发送告警;如果该分组又持续收到了告警,会等待一个分组告警间隔时间后,再次为该分组发送告警
- 如果该告警一直存在,alertmanager会按照重发间隔来重复发送告警
下面这张图是整个prometheus的流程全景图,能清晰的了解prometheus的告警运转流程。
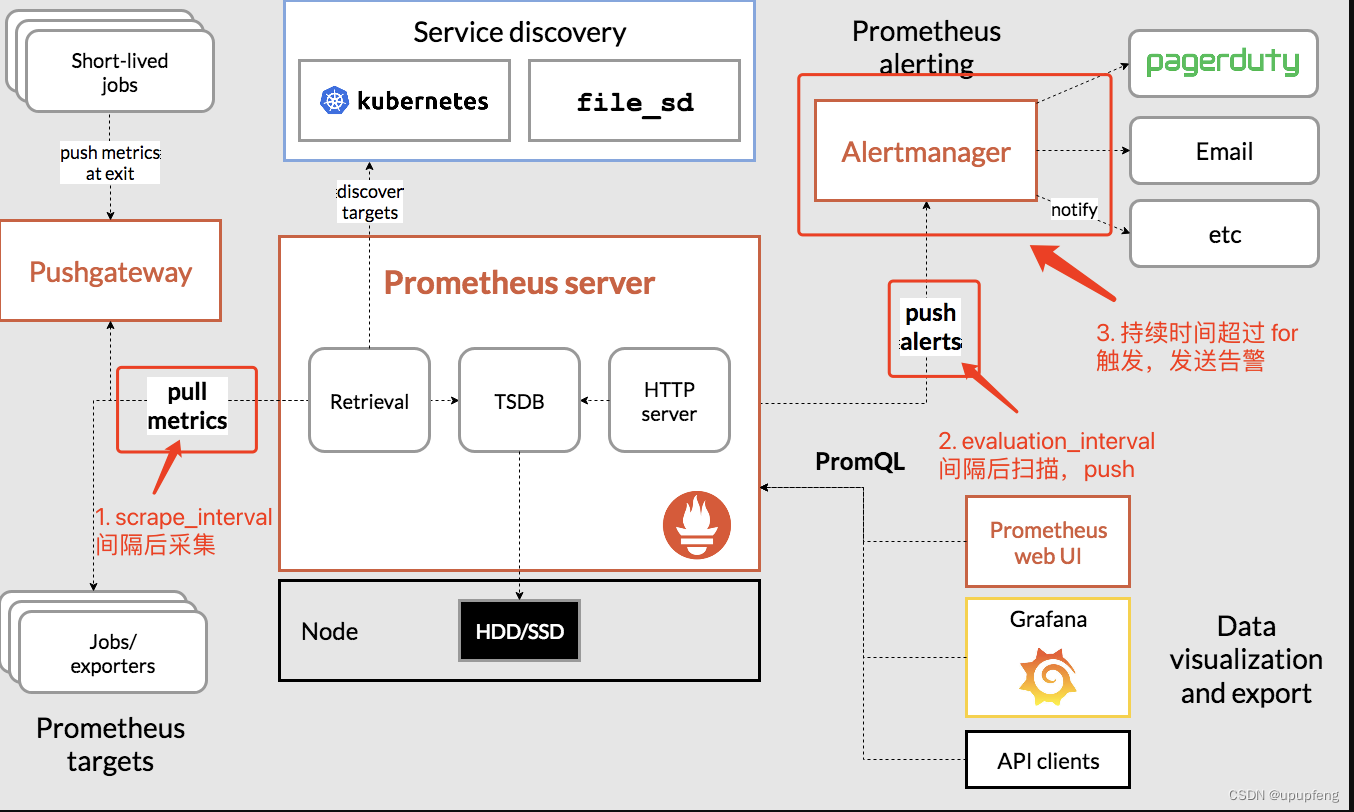
时间相关参数
参数名称 说明 默认值 参数所属 scrape_interval 指标数据采集间隔 1分钟 prometheus.yml evaluation_interval 规则的计算间隔 1分钟 prometheus.yml for: 时间 异常持续多长时间发送告警 0 规则配置 group_wait 分组等待时间。同一分组内收到第一个告警等待多久开始发送,目的是为了同组消息同时发送 30秒 alertmanager.yml group_interval 上下两组发送告警的间隔时间。第一次告警发出后等待group_interval时间,开始为该组触发新告警 5分钟 alertmanager.yml repeat_interval 重发间隔。告警已经发送,且无新增告警,再次发送告警需要的间隔时间 4小时 alertmanager.yml 案例
监控Kafka节点是否down掉。
配置
指标名:kakfa_up_status 1存活 0挂掉了 # prometheus.yml配置 global: scrape_interval: 20s evaluation_interval: 30s # 规则配置 - alert: kakfa_down expr: kakfa_up_status == 0 for: 1m annotations: summary: "Kafka挂掉了" # alertmanager配置 route: group_by: [alertname] group_wait: 60s group_interval: 5m repeat_interval: 10m- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
事件流程
10:00:05 Kafka挂掉了 10:00:20 拉取指标kakfa_up_status=0 10:00:30 计算规则,发现Kafka挂掉了,将kakfa_down设置为pending 10:00:30~10:01:30 持续拉取指标、计算规则 10:01:30 kafka_down持续时间达到了1分钟,设置为firing,发送到alertmanager 10:01:30 alertmanager收到后,等待分组等待时间 10:02:30 分组等待时间完成,发出告警 10:12:30 告警还没有解决,重复发出告警- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
参考
prometheus 告警机制 -(为什么告警发的不及时) https://blog.csdn.net/luo4105/article/details/123700003
多久可以收到prometheus的告警? https://www.jianshu.com/p/b3b4e68409e0
prometheus告警group_wait&repeat_interval https://blog.csdn.net/tryyourbest0928/article/details/115337984
-
相关阅读:
python os.path.abspath()与os.path.realpath()区别
【工具】Ubuntu开机黑屏、NVIDIA显卡驱动问题
微软出品自动化神器【Playwright+Java】系列(四)之 浏览器操作
总结《你不知道的JavaScript》三卷小记
【Mybatis编程:批量插入相册(动态SQL)】
SSM+网上书城系统 毕业设计-附源码180919
激励合作伙伴的8个想法
Java解析MDB(上)-纯JDBC解析非空间数据
动态图算法:EvolveGCN——融合GNN和RNN的离散型动态图神经网络
Java 修饰符 private、default、protected、public 的应用实例 (属性)
- 原文地址:https://blog.csdn.net/ifenggege/article/details/125456836