-
MINet-测试算法性能-计算复杂度(GMac)、模型大小(M)、计算速度(FPS)
计算复杂度为 48.76GMac
参数数量为34.73M (这是我利用MINet网络架构设计的自己的网络的测试结果)计算图片读入和写出的时间
若batch=1,在ECSSD数据集上的测试结果为39FPS
不计算图片读入和写出的时间若batch=1,在ECSSD数据集上的测试结果为74FPS
首先梳理算法结构
1 主文件main.py
里面有solver = Solver(exp_name, arg_config, path_config)
这个文件来自于 # from utils.solver import Solver
2 utils里面的solver.py文件
里面有
if hasattr(network_lib, self.arg_dict["model"]):
self.net = getattr(network_lib, self.arg_dict["model"])().to(self.dev)
这个文件来自于
network_lib的由来 => import network as network_lib
model的由来 main.py => "model": "MINet_VGG16",
3 添加计算复杂度的语句get_model_complexity_info()
这些不重要,重要的是
self.net就是可以用于测试计算复杂度(GMac)、模型大小(M)的文件
写成如下格式即可: 注意调整(3,320,320),也就是输入图片的通道数、H、W
注意调整(3,320,320),也就是输入图片的通道数、H、W- with torch.cuda.device(0): # todo 1
- # net = self.net # Network(self.cfg)
- macs, params = get_model_complexity_info(self.net, (3, 320, 320), as_strings=True,
- print_per_layer_stat=True,
- verbose=True)
- print('{:<30} {:<8}'.format('Computational complexity: ', macs))
- print('{:<30} {:<8}'.format('Number of parameters: ', params))
4 此时get_model_complexity_info一定不要忘了import对应的库文件
如下即可
- # 计算模型Flops
- from ptflops import get_model_complexity_info
5 运行程序就可以得到得到对应参数 Efficiency

计算复杂度为 48.76GMac
参数数量为34.73M (这是我利用MINet网络架构设计的自己的网络的测试结果)在ECSSD数据集上的测试结果为16FPS
下面来计算速度 FPS
1 注释掉评测部分,这会导致测试速度慢
由于MINet的测试代码main.py->solver.py里面的def test(self):里面是测试的同时进行评测
因此需要注释掉
A原文件
B注释掉文件
2 测试PFS需要做5件事(其中ABC需要放在for循环外面DE放在里面)
=>A import time
=>B idx = 0
=>C time_spent = []
=>D start_time = time.time()
=>E time_spent.append(time.time() - start_time)
if idx % 100 == 0:
time_spent = []
if idx % 99 == 0:
print('time/FPS', np.mean(time_spent), 1 * 1 // np.mean(time_spent))
idx = idx + 1这个E步骤的计算逻辑是每循环99次统计一下平均时间,每循环100次做一次清空。
值得注意的是我们在测试的时候把batch设置为4(因为训练时候就是4),此时没循环一次是4张图片,直接用计算FPS结果x4即可.若,把batch设置为1,此时没循环一次是一张图片,直接用计算FPS结果即可.
但是网络模型设置的是batch=4,这与这个训练架构有关,需要设置为1。 然后会生成一个BS1的文件里面的pth是空的,把右边BS4的模型放进BS1文件夹里面就可以以batch=1的方式运行测试程序了。
然后会生成一个BS1的文件里面的pth是空的,把右边BS4的模型放进BS1文件夹里面就可以以batch=1的方式运行测试程序了。
- # => A
- import time
- # => B
- idx = 0
- # => C
- time_spent = []
- for test_batch_id, test_data in tqdm_iter:
- # => D
- start_time = time.time()
- xxx
- xxx
- xxx
- xxx
- xxx
- xxx
- # => E
- time_spent.append(time.time() - start_time)
- if idx % 100 == 0:
- time_spent = []
- if idx % 99 == 0:
- print('time/FPS', np.mean(time_spent), 1 * 1 // np.mean(time_spent))
- idx = idx + 1
实际情况如下
A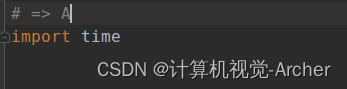
BCD
E
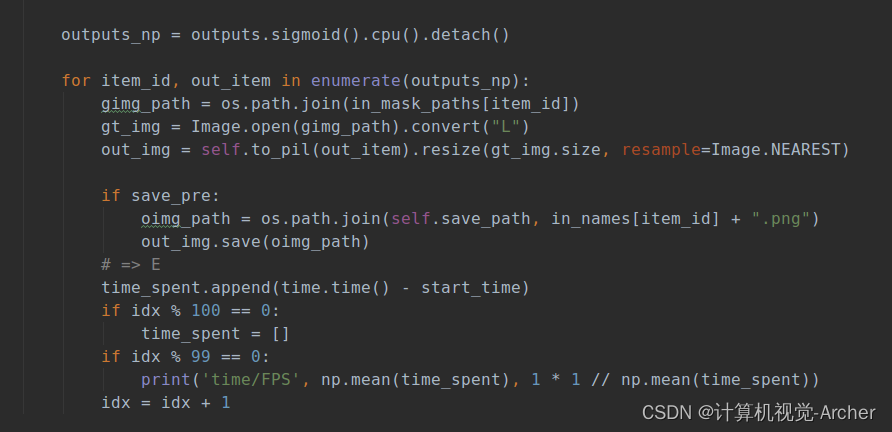
具体全部代码如下
- # => B
- idx = 0
- # => C
- time_spent = []
- for test_batch_id, test_data in tqdm_iter:
- # => D
- start_time = time.time()
- tqdm_iter.set_description(f"{self.exp_name}: te=>{test_batch_id + 1}")
- with torch.no_grad():
- in_imgs, in_mask_paths, in_names = test_data
- in_imgs = in_imgs.to(self.dev, non_blocking=True)
- outputs = self.net(in_imgs)
- outputs_np = outputs.sigmoid().cpu().detach()
- for item_id, out_item in enumerate(outputs_np):
- gimg_path = os.path.join(in_mask_paths[item_id])
- gt_img = Image.open(gimg_path).convert("L")
- out_img = self.to_pil(out_item).resize(gt_img.size, resample=Image.NEAREST)
- if save_pre:
- oimg_path = os.path.join(self.save_path, in_names[item_id] + ".png")
- out_img.save(oimg_path)
- # => E
- time_spent.append(time.time() - start_time)
- if idx % 100 == 0:
- time_spent = []
- if idx % 99 == 0:
- print('time/FPS', np.mean(time_spent), 1 * 1 // np.mean(time_spent))
- idx = idx + 1
- # 下面是为了计算Fmax\Favg\MAE设置因此可以注释掉
- # gt_img = np.asarray(gt_img)
- # out_img = np.array(out_img)
- # ps, rs, mae, meanf = cal_pr_mae_meanf(out_img, gt_img)
- # for pidx, pdata in enumerate(zip(ps, rs)):
- # p, r = pdata
- # pres[pidx].update(p)
- # recs[pidx].update(r)
- # maes.update(mae)
- # meanfs.update(meanf)
- # maxf = cal_maxf([pre.avg for pre in pres], [rec.avg for rec in recs])
- # results = {"MAXF": maxf, "MEANF": meanfs.avg, "MAE": maes.avg}
- results = {}
- return results
测试结果(计算读入和写出时间)
若batch=4
在ECSSD数据集上的测试结果为16X4FPS=64FPS(并行计算了这个测试不准确不采纳)
若batch=1
在ECSSD数据集上的测试结果为39FPS
测试结果(不计算读入和写出时间)
若batch=4 torch.Size([4, 3, 320, 320])
在ECSSD数据集上的测试结果为68X4FPS (并行计算了这个测试不准确不采纳)
若batch=1 torch.Size([1, 3, 320, 320])
在ECSSD数据集上的测试结果为74FPS
-
相关阅读:
k8s--基础--30.1--Tekton--介绍和按照
基于stm32单片机的智能恒温自动加氧换水鱼缸
JMeter详解
深入理解java泛型
客户案例:CACTER邮件网关护航首钢集团重保任务
面试题:说说Java并发运行中的一些安全问题
MySQL系列——MySQL8+keepalived双主热备高可用
微信小程序实现上拉加载更多
centos7基础操作
后端工程师的前端之路系列--小程序学习
- 原文地址:https://blog.csdn.net/zjc910997316/article/details/125452862