-
【C++必知必会】异常处理机制,你了解多少?
大家好,我是翼同学! 
1️⃣前言
今天的笔记内容是:C++异常处理
2️⃣异常简介
✨什么是C++异常?
事实上,程序发生错误的类型一般可以分为三种:
- 语法错误
在编译和链接阶段就能发现的错误,也就是说,只有语法正确的代码才能生成可执行程序。
- 逻辑错误
也就是说,我们编写的代码无法解决问题,无法达到目标。因此只能通过调试来解决逻辑错误。
- 运行错误
即程序在运行期间发生的错误,比如数组下标越界,访问了不存在的下标数据;除0溢出;内存不足;文件操作时读取的文件不存在等
因此,为了解决运行时发生的错误,C++提出了异常机制。
当C++程序运行时,可能会发生一些错误导致程序无法继续正常运行下去。而C++异常为处理这些情况而提供了一种功能强大且灵活的工具,也就是一种转移程序控制权的方式。总结的说,抛出异常就是报告一个运行时的错误信息
✨异常与错误的区别
- 异常
Exception都是运行时的; - 编译时产生的不是异常,而是错误
Error; - 最开始大家都将程序设计导致的错误
Error认定文不属于异常Exception; - 但是一般都将
Error作为异常的一种; - 所以异常一般分两类,
Error与Except
✨C++异常处理的优势
早期在C语言中,通常是我们人为的对返回结果加一些标志来进行判定,比如发生错误返回什么标志,正常情况下我们又是返回什么标记。也就是说我们可以通过使用整型的返回值标识错误或者使用
error宏来记录错误。但C++的异常处理机制会比C语言的异常处理更有优势。具体如下:
- 在C语言中使用函数返回值或
error宏来处理异常错误时,调用者可能会忘记检查,导致错误没有被处理,造成程序终止或者出现错误结果;而在C++中,如果程序出现异常且没有被捕获,那么程序就会终止。 - C++异常包含着语义信息,通过类型就能体现出来;
- 整型返回值缺乏上下文信息,而异常作为一个类,可以有自己的成员,这些成员就可以传递足够多信息。
- 异常处理可以在调用跳级。比如说在有多个函数的调用栈中出现了某个错误,使用整型返回值则要求在每一级函数中都要进行处理。而使用异常处理的栈展开机制则只需要在一处进行错误处理即可。
3️⃣异常处理简介
🌱关键字
C++的异常处理有三个关键字:
- throw:抛出异常(通过
throw关键字来抛出异常) - try:激活异常(在
try语句块中编写可能发生异常的代码) - catch:捕获异常(用
catch关键字来捕获异常并处理)
举个简单的例子:
#include <iostream> using namespace std; int func(int a, int b) { if( b == 0 ){ throw 1; } return a / b; } int main() { int a = 8; int b = 4; int c = 0; // 在try语句块中编写可能发现异常的代码 try { int result1 = func(a, b); // 无异常 cout<< a << "/" << b << "=" << result1 << endl; int result2 = func(a, c); // 有异常(c的值为0) cout<< a << "/" << c << "=" << result2 << endl; } // 捕获异常并做出处理 catch(int) { cout<<"出现异常!除数不能为0"; } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
运行结果如下:

🌳小结
- 如果有异常发生,可以用
throw操作,创建一个异常对象并抛出; - 将可能发生异常的代码放在
try语句块中; - 如果
try语句在执行时没有引起异常,则catch代码块就不会执行; - 如果
try语句块中发生异常,则catch子句则会根据出现的先后顺序逐一检查; - 匹配到的
catch语句(即捕获了相应异常)则会处理异常(或者也可以继续抛出异常); - 如果没有匹配的
catch语句块,程序就会终止; - C++的异常处理机制使得异常的发生和异常的处理不必拘泥于一个函数中,这样底层的函数可以着重解决相应的问题而不必过多考虑异常的处理;
- 让调用者可以在适当的位置设置对不同类型异常的处理。
4️⃣关键字详解
前面讲到,C++异常处理的流程为:
抛出(throw)--> 检测(try) --> 捕获(catch)注意:异常必须显式地抛出,才能被检测和捕获到。下面重点看看各个关键字的细节。
📗throw
✔️用法
throw exceptionData;- 1
exceptionData就是异常数据,可以是任意的数据类型(int、double、char*等),由我们自己决定。因此,
throw的作用就是在函数体中抛出异常。✔️扩展
- 另外的,
throw还可以用作异常规范(或者叫异常列表、异常指示符) - 即
throw可以在函数头和函数体之间声明,指出当前函数能够抛出的异常类型,这就是异常规范。
1)例1
int func1 (char x) throw (int);- 1
- 函数
func1并且只能抛出int类型的异常; - 如果抛出其他类型的异常,
try将无法捕获,程序只能终结。
2)例2
int func2 (char y) throw (int, double);- 1
- 函数
func2可以抛出多种异常,用逗号隔开
3)例3
int func3 (char z) throw ();- 1
- 函数
func3不会抛出任何异常,throw( )中什么也不用写; - 即使抛出了,try 也检测不到。
需要注意的是,异常规范的初衷是为了让程序员看到函数的定义或声明后,能够立马就知道该函数会抛出什么类型的异常,这样程序员就可以使用
try-catch来捕获了。如果没有异常规范,程序员必须阅读函数源码才能知道函数会抛出什么异常。但由于异常规范的初衷较难实现,后来的 C++11 也将其抛弃了,因此我们不建议使用异常规范。📙try-catch
✔️用法
try和catch关键字是一起使用的。用法相当于让try语句块去检测代码运行时有没有异常,一旦有异常抛出就会被catch所捕获。换句话说,如果 try 语句块没有检测到异常(没有异常抛出),那么就不会执行 catch 中的语句。
语法如下:
1)例1
try { // 将可能发生异常的代码放置在try语句块中 } catch(异常类型 变量名) { // 捕获相应异常并处理 }- 1
- 2
- 3
- 4
- 5
- 6
2)例2
try { // 将可能发生异常的代码放置在try语句块中 } catch(...) { // 加省略号表示可以处理try抛出的任何类型的异常 }- 1
- 2
- 3
- 4
- 5
- 6
3)例3
//可以有多级catch语句 try { // 将可能发生异常的代码放置在try语句块中 } catch(异常类型 变量名) { // 捕获相应异常并处理 } catch(异常类型 变量名) { // 捕获相应异常并处理 } catch(...) { // 加省略号表示可以处理try抛出的任何类型的异常 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
✔️小结
- 只有当异常被明确抛出时(明确地告诉程序发生了什么错误),try语句才能检测到。也就是说,如果发生错误,异常又没有抛出,则
try语句是检测不到的。 - 在
try语句块中,一旦异常被抛出,则会立刻被try检测到,并且程序执行发生跳转,从异常抛出点跳转到catch处,将异常交给catch语句块处理。也就是说,位于异常抛出点之后的语句不会再执行。 - 执行完
catch块的代码后,程序会继续执行catch块后面的代码,即恢复正常的执行流程。
5️⃣异常发生的位置
无论在当前try块中直接抛出异常,还是在try中调用的某个函数发生了异常,都可以被try检测到。
💡try中直接抛出异常
#include <iostream> using namespace std; int main() { try { throw 1; //抛出异常 cout<<"程序运行中..."<<endl; } catch(int num) { cout << num << endl; } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
运行结果为:
1- 1
💡try中调用的函数抛出异常
#include <iostream> using namespace std; void func() { throw 1; // 抛出异常 } int main() { try { func(); cout<<"程序运行中..."<<endl; } catch(int num) { cout << num << endl; } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
运行结果为:
1- 1
6️⃣栈解旋
🔋理解
异常被抛出后,从进入try块起到异常被抛掷前,这期间在栈上构造的所有对象都会被自动析构。析构的顺序和构造的顺序相反。这一过程被称为栈的解旋。
通俗来讲就是在try块中,当发生了异常并被抛出时,异常抛出前创建的对象都会被自动析构,不然的话创建的对象会一直存在,占用着内存。
🔋示例
看个小例子就能理解了
#include <iostream> #include <string> using namespace std; class myClass{ public: myClass(string name) { m_name = name; cout<< m_name << "对象被创建了!" << endl; } ~myClass() { cout<< m_name << "对象被析构了!" << endl; } string m_name; }; void func1(){ myClass b("b"); myClass c("c"); throw -1; // 函数1抛出异常 } void func2() { myClass a("a"); func1(); // 调用函数1 } int main() { try { func2(); // 调用函数2 } catch(int) { cout << "这里是异常处理!" << endl; } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
运行结果为:

7️⃣异常变量的生命周期
先来看一段代码:
#include <iostream> #include <string> using namespace std; class myException{ public: myException() { cout<< "构造函数调用了!" << endl; } myException(const myException& e) { cout<< "拷贝构造函数调用了" << endl; } ~myException() { cout<< "析构函数调用了!" << endl; } }; void func1(){ throw myException(); // 抛出异常匿名对象 } void func2() { try{ func1(); } catch(myException myExcept){ cout << "异常捕获并处理!" << endl; } } int main() { func2(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
运行结果如下:
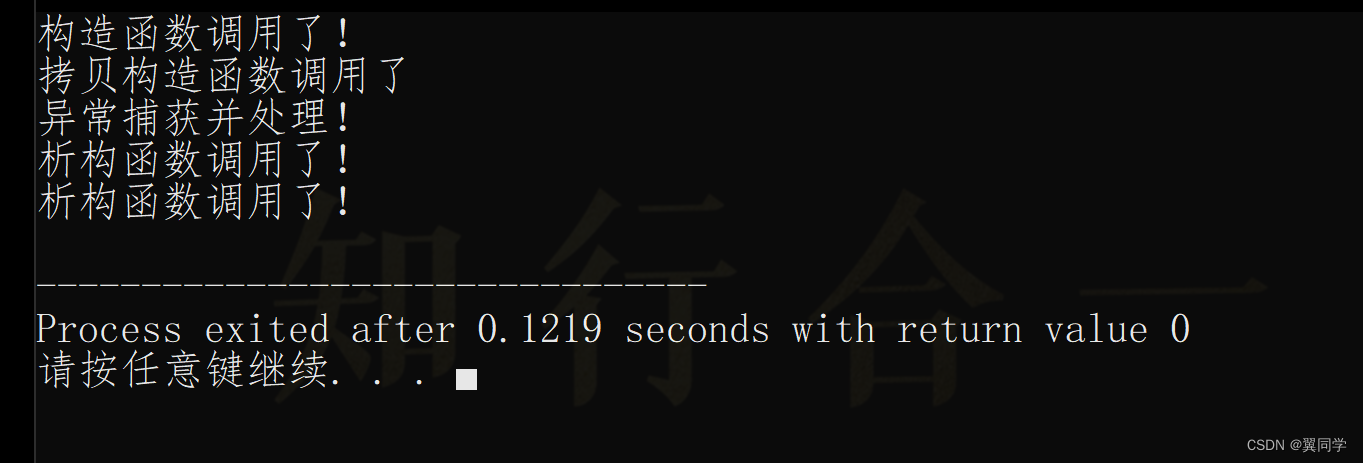
分析如下:
- 主函数中调用了函数
func2(),执行流程就跳到func2()的函数体中; func2()中有try-catch语句块,其中try语句调用了func1()函数,所以执行流程又跳到了func1()的函数体中;func1()中抛出了自定义的异常类对象myException(),此时构造函数调用了;- 异常抛出后,执行流程就跳到
func2()中的catch语句块中,异常被catch捕获了; - 此时调用了拷贝构造函数,将匿名对象
myException()拷贝给了myExcept; - 接着是异常的处理(在上述代码中是输出语句的执行)
- 最后是栈解旋,即析构函数的自动调用,且析构的顺序和构造的顺序相反。
如果,在上述代码中,将catch中的捕获语句改为引用类型,如下所示:
void func2() { try{ func1(); } catch(myException& myExcept){ cout << "异常捕获并处理!" << endl; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
则代码运行的结果如下:
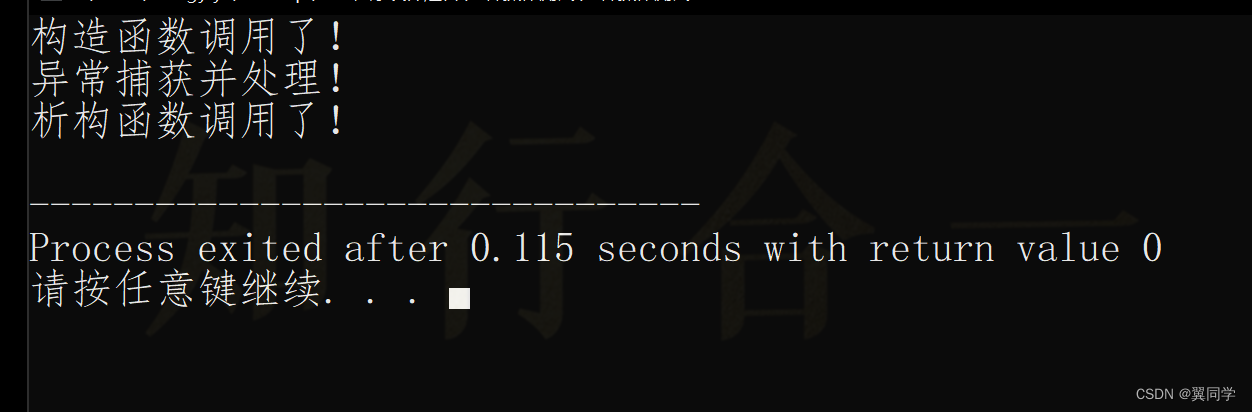
也就是说没有调用拷贝构造函数。直接将抛出的异常匿名对象赋值给引用对象,也就是起别名。此时抛出的异常对象的生命周期就发生了变化。即生命周期交给引用对象所托管(这种效率会较高些)。
9️⃣写在最后
好了,本篇笔记就到写这,欢迎大家到评论区一起讨论!
-
相关阅读:
Xshell连接Ubuntu详细过程
海屯心理平台搭建系统模式
你真的会使用Typora吗?
FBX文件结构解读【文本格式】
java108-StringBuilder连接字符串和删除操作
kafka原理与应用
2023年智慧政务一网通办云平台顶层设计与建设方案PPT
npm install卡在sill idealTree buildDeps没有反应,安装失灵
96 前缀树Trie
在虚拟机安装Hadoop
- 原文地址:https://blog.csdn.net/m0_62999278/article/details/125420279