-
为什么 eBPF 如此受欢迎?

eBPF 是一个基于寄存器的虚拟机,最初是为过滤网络数据包而设计的,由于最初的论文[1]是在伯克利实验室(Lawrence Berkeley National Laboratory)写的,所以被称为扩展的伯克利数据包过滤器(Extended Berkeley Packet Filter),也就是 eBPF。本文将会用通俗易懂地语言给大家解释 eBPF 为什么这么受欢迎。
eBPF 介绍
通俗地讲,eBPF 是当有事件触发时,在操作系统的内核中运行的自定义程序,你可以把 eBPF 程序看成事件驱动的函数(比如 AWS lamda,👉OpenFunction)。eBPF 程序可以访问内核函数的子集以及内存,当 eBPF 程序被加载到内核中时,会有一个验证器来确保它是安全运行的,如果无法确认,就会被拒绝运行。也就是说,即使是垃圾 eBPF 代码也不会让内核崩溃。
在容器世界里,eBPF 正变得越来越流行,目前最流行的产品是 Cilium[2] 和 Pixie[3]。其中 Cilium 是基于 eBPF 的 CNI 插件,同时还提供了无需 Sidecar 的 Service Mesh[4]。
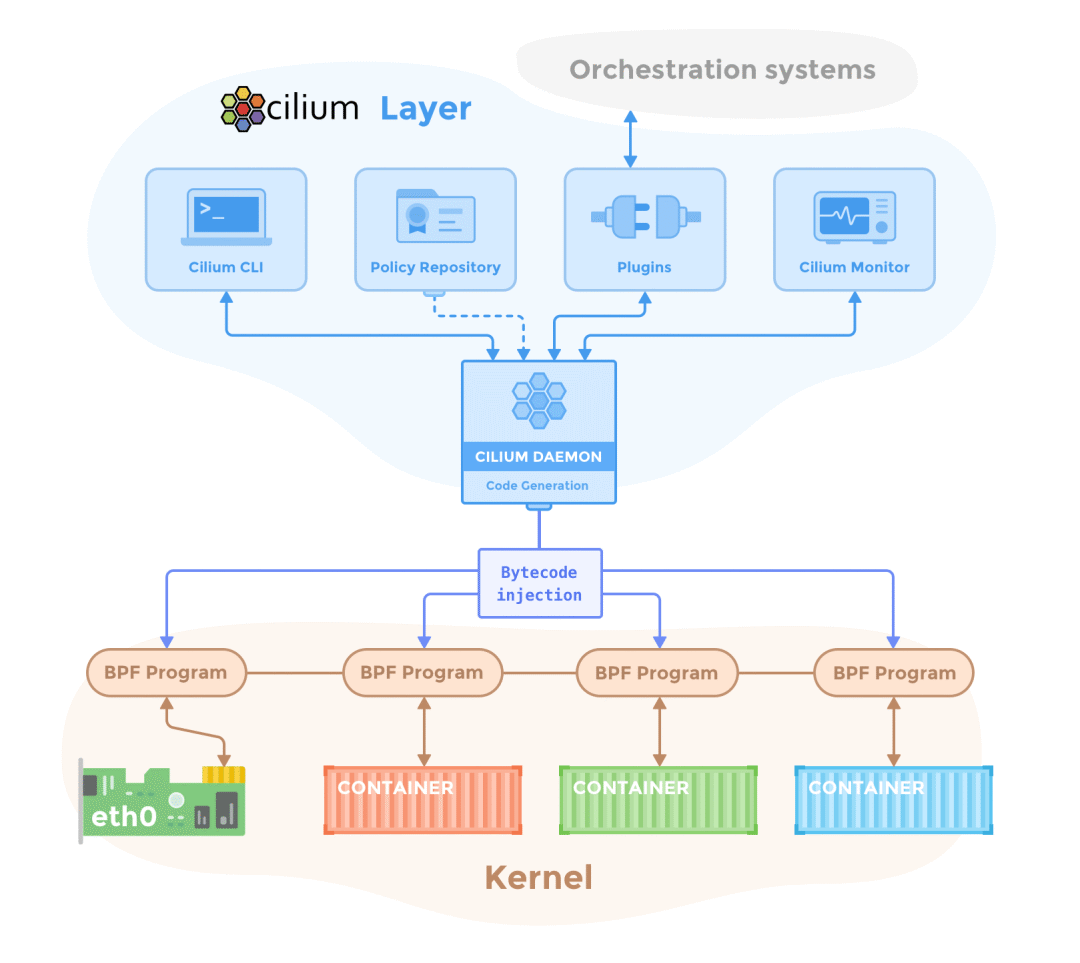
而 Pixie 则专注于使用 eBPF 来实现可观测性。
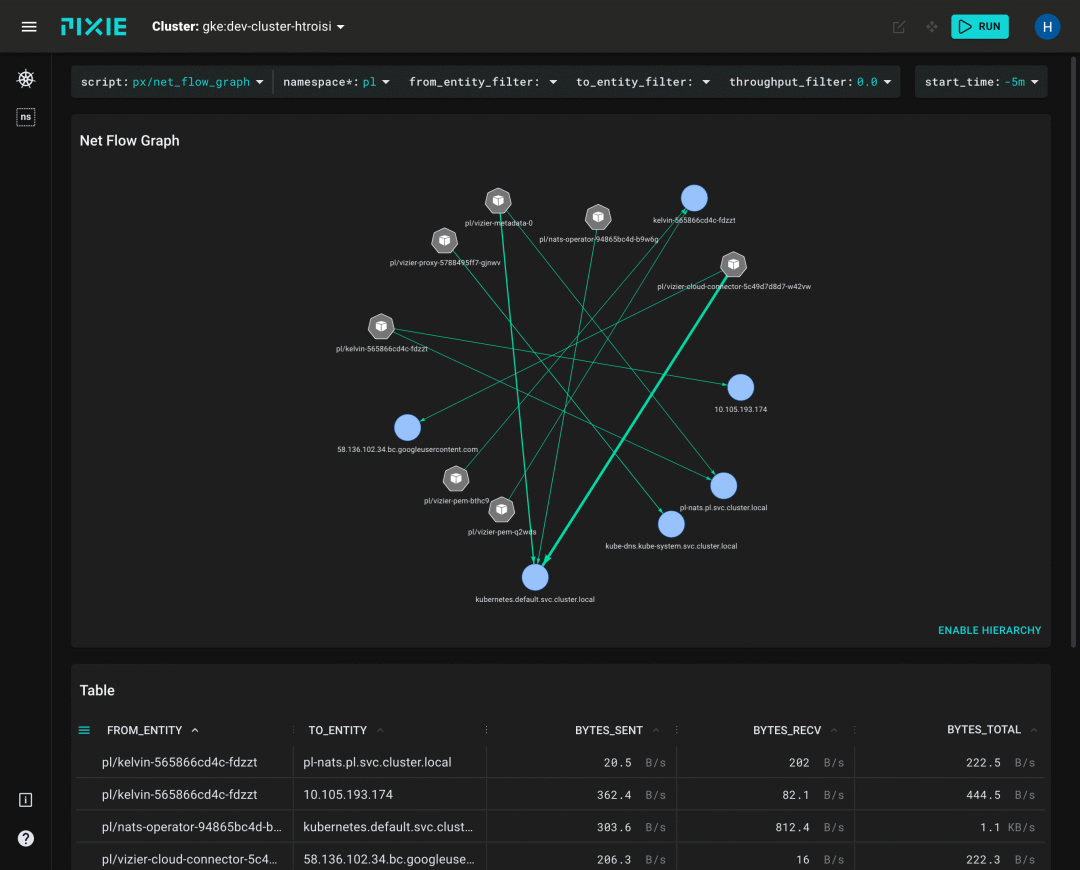
更多 eBPF 使用场景:
-
调试与追踪:追踪任意系统调用,内核函数,以及用户空间的任意进程。代表工具:bpftrace[5]。
-
网络:监测、过滤、控制流量。用户空间的程序可以在任意 Socket 上面附加一个过滤器,用来监测经过它的流量,并对其进行各种操作,比如允许通过、拒绝通过、重定向等等。
-
安全监控与隔离:eBPF 程序可以监测并报告内核中发生的系统调用,也可以阻止应用在内核中执行某些系统调用(例如删除文件)。
尽管 Linux 早已支持上述的这些功能,但 eBPF 可以帮助我们更高效地执行这些任务,消耗的 CPU 和内存资源更少。
eBPF 为什么这么高效?
eBPF 程序比传统程序“跑得”更快,因为它的代码是直接在内核空间中执行的。
设想这样一个场景,假设一个程序想要统计其从 Linux 系统上发送出去的字节数,需要经过哪些步骤?
首先,网络活动发生时,内核会生成原始数据,这些原始数据包含了大量的信息,而且大部分信息都与“字节数”这个信息无关。所以,无论生成的原始数据是个啥,只要你想统计发送出去的字节数,就必须反复过滤,并对其进行数学计算。这个过程每分钟要重复数百次(甚至更多)。
传统的监控程序都运行在用户空间,内核生成的所有原始数据都必须从内核空间复制到用户空间,这种数据复制和过滤的操作会对 CPU 造成极大的负担。这就是为什么 ptrace 很“慢”,而 bpftrace[6] 很”快“。
eBPF 无需将数据从内核空间复制到用户空间,你可以直接在内核空间运行监控程序来聚合可观测性数据,并将其发送到用户空间。eBPF 也可以直接在内核空间过滤数据以及创建 Histogram,这比在用户空间和内核空间之间交换大量数据要快得多。
eBPF 映射(eBPF Map)
eBPF 还有一个黑科技,它会使用 eBPF 映射(eBPF Map)来允许用户空间和内核空间之间进行双向数据交换。在 Linux 中,映射(Map)是一种通用的存储类型,用于在用户空间和内核空间之间共享数据,它们是驻留在内核中的键值存储。
对于可观测性这种应用场景,eBPF 程序会直接在内核空间进行计算,并将结果写入用户空间应用程序可以读取/写入的 eBPF 映射中。

现在你应该理解为什么 eBPF 这么高效了吧?主要还是 eBPF 提供了一种直接在内核空间运行自定义程序,并且避免了在内核空间和用户空间之间复制无关数据的方法。
参考资料
-
What Is eBPF?[7]
引用链接
[1]论文: https://www.tcpdump.org/papers/bpf-usenix93.pdf
[2] Cilium: https://github.com/cilium/cilium
[3] Pixie: https://github.com/pixie-io/pixie
[4] 无需 Sidecar 的 Service Mesh: https://cilium.io/blog/2021/12/01/cilium-service-mesh-beta
[5] bpftrace: https://github.com/iovisor/bpftrace
[6] bpftrace: https://github.com/iovisor/bpftrace
[7] What Is eBPF?: https://www.oreilly.com/library/view/what-is-ebpf/9781492097266/
-
-
相关阅读:
微服务架构推动精益数字化管理体系建设,构建大数据分析平台
DPDK系列之三十六报文转发
Joe 主题 Halo 移植版搭建部署教程
c++练习题(4)
C++:哈希
YOLOv7优化:渐近特征金字塔网络(AFPN)| 助力小目标检测
深度学习环境搭建入门环境搭建(pytorch版本)
kickstarter/indiegogo海外众筹六大核心
杭电多校十 - Wavy Tree (贪心)
一篇打通线程 等待 && 中断
- 原文地址:https://blog.csdn.net/alex_yangchuansheng/article/details/125437387