-
从python图像动漫化的设计和应用快速入门vue+python+深度学习+接口+部署
今天,ofter将分享一个独家出品的应用:图像动漫化系统。原本ofter只是单纯写一个图像处理的工具,但是当我写完这个应用系统时,发现这是一个绝佳的学习案例:简单、干净又完整。此系统将前端、后端、深度学习、图像处理完美地结合到了一起,这里先列出我们可以学习到的内容:
- 前端Vue
- 接口(前端js+后端Python)
- 后端Flask Python
- 深度学习(tensorflow框架、opencv-python库)
- 部署(本地、云服务器部署)
通过这个实战案例,我们完全可以入门vue、python、深度学习、接口、部署,绝对值得收藏、学习和使用。
完整资料下载地址见文末。
1、前端Vue
1.1 前端结构
- #src
- ├── api/ #前端接口
- ├── assets/ #静态图片路径
- ├── components/ #组件
- ├── anime.vue/ #图片动漫化页面
- ├── sort.vue/ #动态排序页面
- ├── layouts/ #页面布局组件
- ├── router/ #路由
- ├── utils/ #前端接口request
- ├── App.vue #App主页面
- ├── main.js #主定义
1.2 前端页面
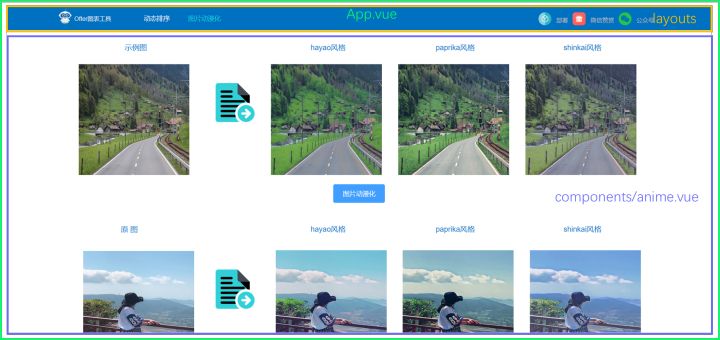
1.3 前端功能
别看页面简单,前端主要包含了3个功能点:1)上传图片:获取图片链接;2)压缩图片;3)动漫化:通过接口传送图片给后端,并返回动漫化的结果。
1.3.1 上传图片
element-ui是比较简单和经典的UI组件库,我们可以看下如何实现。

- <el-dialog
- class="temp_dialog"
- title="上传图片"
- :visible.sync="uploadVisible"
- >
- <el-form
- ref="ruleForm"
- :model="form"
- label-width="100px"
- :hide-required-asterisk="true"
- >
- <el-upload
- class="temp_upload"
- ref="fileUpload"
- drag
- action="/api/images/"
- :on-change="importPic"
- :on-exceed="onFileExceed"
- :on-remove="onFileRemove"
- :auto-upload="false"
- :limit="1"
- :file-list="fileList"
- multiple
- >
- <i class="el-icon-upload"/>
- <div class="el-upload__text">
- 将文件拖到此处,或<em>点击上传</em>
- </div>
- <div slot="tip" class="el-upload__tip" style="color: red">*注:只能上传1张图片,1分钟内可转换成功,5分钟未转换超时失败!</div>
- </el-upload>
- </el-form>
- <div
- slot="footer"
- class="dialog-footer"
- >
- <el-button
- type="primary"
- @click="uploadImages()"
- >
- {{ '确认' }}
- </el-button>
- <el-button @click="uploadVisible = false">
- {{ '取消' }}
- </el-button>
- </div>
- </el-dialog>
这里我们看下上传图片最核心的代码importPic():
- //:on-change="importPic"
- methods: {
- importPic (file, fileList) {
- const imgUrl = []
- let dtUrl = []
- let typeDis = true
- let that = this
- fileList.forEach(function (value, index) {
- const types = value.name.split('.')[1]
- const fileType = ['jpg', 'JPG', 'png', 'PNG', 'jpeg', 'JPEG'].some(
- item => item === types
- )
- if (fileType === false) {
- typeDis = false
- } else {
- // imgUrl[index] = URL.createObjectURL(value.raw) // 赋值图片的url,用于图片回显功能
- let reader = new FileReader()
- reader.readAsDataURL(value.raw)
- reader.onload = (e) => {
- let result = e.target.result
- let img = new Image()
- img.src = result.toString()
- console.log('*******原图片大小*******')
- console.log(result.length / 1024)
- // const temp = reader.result
- that.compress(img).then((value) => {
- dtUrl[index] = value
- })
- }
- }
- })
- if (typeDis === false) {
- this.$message.error('格式错误!请重新选择!')
- this.form.data = []
- this.$refs['fileUpload'].clearFiles()
- this.fileList = []
- this.dataUrl = []
- } else {
- this.fileList = fileList
- this.imageUrl = imgUrl
- this.dataUrl = dtUrl
- }
- }
1.3.1.1 遍历图片
虽然我们限制只能上传1张图片(为了防止上传太多图片而导致等待时间过长),但是我们的方法是按照上传多张图片来写的。
fileList.forEach(function (value, index) {}1.3.1.2 检验文件格式
我们必须提前筛选格式,避免后端做无谓的操作
- const types = value.name.split('.')[1]
- const fileType = ['jpg', 'JPG', 'png', 'PNG', 'jpeg', 'JPEG'].some(
- item => item === types
- )
- if (fileType === false) {
- typeDis = false
- } else {}
1.3.1.3 获取图片链接
最关键的我们需要获取通过el-upload上传的图片链接,然后传递给后端。这里我们将多张图片链接组合成一个数组dtUrl[]进行接口传递,当然我们也可以组成json格式。
- let reader = new FileReader()
- reader.readAsDataURL(value.raw)
- reader.onload = (e) => {
- let result = e.target.result
- let img = new Image()
- img.src = result.toString()
- console.log('*******原图片大小*******')
- console.log(result.length / 1024)
- // const temp = reader.result
- that.compress(img).then((value) => {
- dtUrl[index] = value
- })
- }
获取图片链接主要有两种方式:a)blob链接;b)base64链接。我们这里采用的是b方式,而that.compress(img)即获取压缩后图片的方法。
1.3.2 压缩图片
压缩图片也是重要的一环,一般图片动不动就几mb,这需要耗费后端更长的时间和资源。对于用户来说,也需要等待更长的时间,等待是丢失用户的杀手。

压缩图片方法compress():
- compress (img) {
- const canvas = document.createElement('canvas')
- const ctx = canvas.getContext('2d')
- let that = this
- return new Promise(function (resolve, reject) {
- img.onload = setTimeout(() => {
- // 图片原始尺寸
- let originWidth = img.width
- let originHeight = img.height
- // 最大尺寸限制,可通过设置宽高来实现图片压缩程度
- let maxWidth = 1200
- let maxHeight = 1200
- // 目标尺寸
- let targetWidth = originWidth
- let targetHeight = originHeight
- // 图片尺寸超过限制
- if (originWidth > maxWidth || originHeight > maxHeight) {
- if (originWidth / originHeight > maxWidth / maxHeight) {
- // 更宽,按照宽度限定尺寸
- targetWidth = maxWidth
- targetHeight = Math.round(maxWidth * (originHeight / originWidth))
- } else {
- targetHeight = maxHeight
- targetWidth = Math.round(maxHeight * (originWidth / originHeight))
- }
- }
- // canvas对图片进行缩放
- canvas.width = targetWidth
- canvas.height = targetHeight
- // 清除画布
- ctx.clearRect(0, 0, targetWidth, targetHeight)
- // 图片压缩
- ctx.drawImage(img, 0, 0, targetWidth, targetHeight)
- // 进行最小压缩
- that.result = canvas.toDataURL('image/jpeg', 0.7)
- resolve(that.result)
- console.log('*******压缩后的图片大小*******')
- console.log(that.result.length / 1024)
- }, 1000)
- })
- }
1.3.2.1 promise方法
网上有很多类似的方法,但是你会发现经常获取不到图片,因为异步的原因,我们最好使用promise方法,通过resolve来保存图片数据。
- return new Promise(function (resolve, reject) {
- ...
- that.result = canvas.toDataURL('image/jpeg', 0.7)
- resolve(that.result)
- ...
- }
然后,我们可以回顾importPic()中获取resolve保存的压缩图片的方法。
- that.compress(img).then((value) => {
- dtUrl[index] = value
- })
这里提醒一句,数据需要提前定义。
- data () {
- return {
- result: ''
- }
- },
1.3.3 动漫化
当我们获取到压缩后的图片,我们就开始动漫化了。
- uploadImages () {
- this.uploadVisible = false
- this.loading = true
- this.$message.warning('图像越大可能需要的时间越长,ofter正在努力动漫化...')
- let dtUrl = {}
- this.dataUrl.forEach(function (value, index) {
- dtUrl[index] = value
- })
- return getImages(dtUrl).then(
- res => {
- const {code, data} = res
- if (code !== 200) {
- this.$message.error('无法从后端获取数据')
- this.fileList = []
- this.dataUrl = []
- this.loading = false
- } else {
- this.fileList = []
- this.imgList1 = data.Hayao
- this.imgList2 = data.Paprika
- this.imgList3 = data.Shinkai
- this.loading = false
- }
- }
- ).catch(() => {
- })
- },
通过getImages()方法,我们就进入到了api接口部分,即将连接后端。
return getImages(dtUrl).then()1.4 前端接口
api:
- import request from '../utils/request'
- export function getImages (data) {
- return request({
- url: '/connect/anime',
- method: 'post',
- data: data
- })
- }
request.js:
- import axios from 'axios'
- import { Message } from 'element-ui'
- const service = axios.create({
- baseURL: 'http://127.0.0.1:5000/', //连接后端的url
- timeout: 300000 // request timeout
- })
- service.interceptors.response.use(
- response => {
- const res = response.data
- return res
- },
- error => {
- console.log('err' + error) // for debug
- Message({
- message: '动漫化出现问题,请稍后刷新再试!',
- type: 'error',
- duration: 300 * 1000
- })
- return Promise.reject(error)
- }
- )
- export default service
是的,这就是所有的前端接口代码,够简单吧!
2、后端Flask-Python
2.1 后端结构
- ├── checkpoint/ #生成器权重
- ├── dist/ #前端打包文件
- ├── net/ #网络生成器
- ├── discriminator/ #图片鉴别器
- ├── generator/ #图片生成器
- ├── response/ #返回前端接口代码
- ├── results/ #图片生成结果保存路径
- ├── tools2/ #工具函数
- ├── adjust_brightness.py/ #调整图片亮度
- ├── base64_code.py/ #base64图像格式转换
- ...
- ├── app.py #运行程序
- ├── README.md #使用说明
- ├── requirements.txt #安装库文件
- ├── test.py #动漫化代码
- ├── start.sh #启动程序脚本
- ├── stop.sh #停止程序脚本
2.2 后端接口
为了与前端接口对接,flask轻量级后端框架是个不错的选择。代码也很简单,前端通过axios传递了3个参数:
- url: '/connect/anime',
- method: 'post',
- data: data
那么在flask-python文件中,app.py:
- @app.route('/connect/anime', methods=['POST'])
- def upload_images():
- data = request.get_data()
- data = json.loads(data.decode("UTF-8"))
- if data is None or data == '':
- return response_fail(403, '未接收到任何图片')
- images = []
- for i in range(len(data)):
- images.append(data[str(i)])
- Hayao = 'checkpoint/generator_Hayao_weight'
- Paprika = 'checkpoint/generator_Paprika_weight'
- Shinkai = 'checkpoint/generator_Shinkai_weight'
- save_add = 'imgs/'
- brightness = False
- result_Hayao = test_anime(Hayao, save_add, images, brightness)
- result_Paprika = test_anime(Paprika, save_add, images, brightness)
- result_Shinkai = test_anime(Shinkai, save_add, images, brightness)
- result_arr = {
- 'Hayao': result_Hayao,
- 'Paprika': result_Paprika,
- 'Shinkai': result_Shinkai
- }
- return response_success('success', result_arr)
其中获取Post的数据有3种方式:a)params;b)form.data;c)data。我们这里用了方式c:
data = request.get_data()2.3 执行动漫化
我们稍微介绍下AnimeGanV2的网络架构和实现。如果您并未了解过神经网络,建议可以阅读下ofter用最简单的方式写的关于卷积神经网络的文章:
[5机器学习]计算机视觉的世界-卷积神经网络(CNNs) - 知乎
2.3.1 卷积神经网络

因为辨别器网络只是为了识别图片是不是Cartoon图片,所以该网络架构很简单,我们主要看下生成器网络的实现,我们把网络架构分割成几个部分。

- with tf.compat.v1.variable_scope('A'):
- inputs = Conv2DNormLReLU(inputs, 32, 7)
- inputs = Conv2DNormLReLU(inputs, 64, strides=2)
- inputs = Conv2DNormLReLU(inputs, 64)
- with tf.compat.v1.variable_scope('B'):
- inputs = Conv2DNormLReLU(inputs, 128, strides=2)
- inputs = Conv2DNormLReLU(inputs, 128)
- with tf.compat.v1.variable_scope('C'):
- inputs = Conv2DNormLReLU(inputs, 128)
- inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r1')
- inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r2')
- inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r3')
- inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r4')
- inputs = Conv2DNormLReLU(inputs, 128)
- with tf.compat.v1.variable_scope('D'):
- inputs = Unsample(inputs, 128)
- inputs = Conv2DNormLReLU(inputs, 128)
- with tf.compat.v1.variable_scope('E'):
- inputs = Unsample(inputs, 64)
- inputs = Conv2DNormLReLU(inputs, 64)
- inputs = Conv2DNormLReLU(inputs, 32, 7)
- with tf.compat.v1.variable_scope('out_layer'):
- out = Conv2D(inputs, filters =3, kernel_size=1, strides=1)
- self.fake = tf.tanh(out)
代码实现与网络架构一一对上了,当然tensorflow中没有那么便利的方法,而我们只需对每个方法再往下写。
2.3.2 卷积层
Conv2DNormLReLU方法:
- def Conv2DNormLReLU(inputs, filters, kernel_size=3, strides=1, padding='VALID', Use_bias = None):
- x = Conv2D(inputs, filters, kernel_size, strides,padding=padding, Use_bias = Use_bias)
- x = layer_norm(x,scope=None)
- return lrelu(x)
- def Conv2D(inputs, filters, kernel_size=3, strides=1, padding='VALID', Use_bias = None):
- if kernel_size == 3 and strides == 1:
- inputs = tf.pad(inputs, [[0, 0], [1, 1], [1, 1], [0, 0]], mode="REFLECT")
- if kernel_size == 7 and strides == 1:
- inputs = tf.pad(inputs, [[0, 0], [3, 3], [3, 3], [0, 0]], mode="REFLECT")
- if strides == 2:
- inputs = tf.pad(inputs, [[0, 0], [0, 1], [0, 1], [0, 0]], mode="REFLECT")
- return tf_layers.conv2d(
- inputs,
- num_outputs=filters,
- kernel_size=kernel_size,
- stride=strides,
- weights_initializer=tf_layers.variance_scaling_initializer(),
- biases_initializer= Use_bias,
- normalizer_fn=None,
- activation_fn=None,
- padding=padding)
- def layer_norm(x, scope='layer_norm') :
- return tf_layers.layer_norm(x, center=True, scale=True, scope=scope)
- def lrelu(x, alpha=0.2):
- return tf.nn.leaky_relu(x, alpha)
Unsample方法:
- def Unsample(inputs, filters, kernel_size=3):
- new_H, new_W = 2 * tf.shape(inputs)[1], 2 * tf.shape(inputs)[2]
- inputs = tf.compat.v1.image.resize_images(inputs, [new_H, new_W])
- return Conv2DNormLReLU(filters=filters, kernel_size=kernel_size, inputs=inputs)
为了避免丢失图像的信息,我们尽量避免使用池化操作。
3、深度学习-Gan网络对抗(模型训练)
对于图像风格迁移来说,最重要的一环是Gan网络对抗。此节与我们的实际应用无关,是用于模型训练的,既然我们今天的应用主题是图像动漫化,那也稍微提一下。以生成器的损失为例:
- # gan
- c_loss, s_loss = con_sty_loss(self.vgg, self.real, self.anime_gray, self.generated)
- tv_loss = self.tv_weight * total_variation_loss(self.generated)
- t_loss = self.con_weight * c_loss + self.sty_weight * s_loss + color_loss(self.real,self.generated) * self.color_weight + tv_loss
- g_loss = self.g_adv_weight * generator_loss(self.gan_type, generated_logit)
- self.Generator_loss = t_loss + g_loss
- G_vars = [var for var in t_vars if 'generator' in var.name]
- self.G_optim = tf.train.AdamOptimizer(self.g_lr , beta1=0.5, beta2=0.999).minimize(self.Generator_loss, var_list=G_vars)
这里我们在训练过程中,使用AdamOptimizer优化算法使我们的生成器网络损失最小化。
4、Opencv库的使用
opencv是一个比较常用的图像处理库。
4.1 读取和预处理图片数据
我们先看个本地图片的例子,我们知道计算机处理图片其实是对矩阵数组的处理,那么我们可以用cv2.imread获取图片的矩阵数组。
- import cv2
- image_path = 'D:/XXX.png'
- img = cv2.imread(image_path).astype(np.float32)
- print(img)
输出结果:
[[255,255,255],[],[],...]但本案例中ofter获取到的是base64图像,因此采用了另一种读取图像数据的函数:
- cap = cv2.VideoCapture(image_path)
- ret, frame = cap.read()
其中frame才是我们需要的图像数据,我们看下我们加载图像数据,进行预处理的方法:
- def load_test_data(image_path, size):
- # img = cv2.imread(image_path).astype(np.float32)
- cap = cv2.VideoCapture(image_path)
- ret, frame = cap.read()
- img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- img = preprocessing(img, size)
- img = np.expand_dims(img, axis=0)
- return img
- def preprocessing(img, size):
- h, w = img.shape[:2]
- if h <= size[0]:
- h = size[0]
- else:
- x = h % 32
- h = h - x
- if w < size[1]:
- w = size[1]
- else:
- y = w % 32
- w = w - y
- # the cv2 resize func : dsize format is (W ,H)
- img = cv2.resize(img, (w, h))
- return img/127.5 - 1.0
4.2 保存图片数据
对图像数据进行保存,我们使用cv2.imwrite()方法:
cv2.imwrite(path, cv2.cvtColor(images, cv2.COLOR_BGR2RGB))4.3 返回图片数据
当我们有了图片的路径,我们将其通过接口返回给前端。
返回base64图片链接的方法:
- #获取本地图片
- def return_img_stream(img_local_path):
- img_stream = ''
- with open(img_local_path, 'rb') as img_f:
- img_stream = img_f.read()
- img_stream = str("data:;base64," + str(base64.b64encode(img_stream).decode('utf-8')))
- return img_stream
return图片链接数组:
- result_arr=[]
- result_arr.append(return_img_stream('./'+image_name))
- return result_arr
5、运行和部署
5.1 本地后端运行(无需前端)
如果只需要本地测试,本案例提供了args的方法,在项目路径下,执行如下:
- python test.py --checkpoint_dir checkpoint/generator_Hayao_weight --test_dir dataset/pics --save_dir /imgs
- # --checkpoint_dir 拉取生成器权重,目前有hayao/paprika/shinkai。
- # --test_dir 需要动漫化图片的路径
- # --save_dir 动漫化结果图片保存的路径
即可将图片动漫化结果保存到指定路径。
5.2 本地部署运行(需要前端)
将电脑当作服务器使用,使用前需先下载Nginx。
5.2.1 启动flask后端程序
在项目路径下,执行如下命令:
- chmod u+x start.sh #授权脚本运行
- ./start.sh > result.log & #运行脚本
- #停止脚本:./stop.sh
5.2.2 Nginx配置和运行
配置Nginx
- #nginx.conf
- server
- {
- listen 80;
- server_name localhost;
- location / {
- index index.html index.htm;
- root XX/dist; #dist路径
- }
- # 接口
- location /api {
- proxy_pass http://127.0.0.1:5000/;
- }
- }
启动Nginx
service nginx start #重启: service nginx restart5.2.3 浏览器运行
在浏览器上输入localhost,即可运行。
5.3 云服务器部署
云服务器部署方式与本地类似,体验地址如下:
http://139.159.233.237/#/anime

6、完整资料下载
-
相关阅读:
educoder_python:6-1-对象第1关:TOM猫原型 类
【毕业设计】深度学习人脸性别年龄识别系统 - python
【SpringBoot】mockito+junit 单元测试
Lua 如何在Lua中调用C/C++函数
支付宝现金红包源码demo示例
虾皮二面:既然有 HTTP 协议,为什么还要有 RPC?
SpringBoot中“@SpringBootApplication“自动配置原理《第七课》
金色传说:SAP-ABAP- PM工单:IW32组件增强
【接口测试】常见HTTP面试题
【C#版本】微信公众号模板消息对接(二)(图文详解)
- 原文地址:https://blog.csdn.net/weixin_42341655/article/details/125436784