-
PSO算法(优化与探索四*DDPG与GAN)
前言
今天怎么说干的事情不多,一方面是因为看了一篇论文,关于RLPSO的是今年6月3日出来的新的文章《Reinforcement learning based parameters adaption method for particleswarm optimization》
里面提到了不少关于PSO的优化,然后提出了一种基于强化学习的PSO,通过预训练一个神经网络,输入当前的粒子状态,得到一组参数 w,c1,c2。然后做出调整,因为粒子群,包括遗传,EDA 等等对参数的设置是比较敏感,所以你懂的,用深度学习去搞。所以我就想了,能不能在原来的基础上,我也那么干?然后发现我欠考虑了,写到一半发现方向错了。
一开始,我是打算使用QLearning直接做,因为论文提到的DDPG也是QLearn在线学习嘛。
然后是打算设计动作的,让w,c1,c2 往一定的步长运动,运动方向由QLearn决定,但是这里有涉及到步长的设置,等等,所以发现不如直接得到参数w c1 c2那样一来还不如用DDPG,而且一开始我是使用Qlearning不用神经网络来做的,但是后面发现,智能算法的迭代次数过多就直接炸了,还是要用神经网络也就是DQN,后面也是代码写到一般发现不行,还是要改为DDPG。但是仔细看看了论文,以及DDPG以后,我陷入了沉思,于是仔细对比策略,发现GAN好像更容易建模去优化PSO。
版权
郑重提示:本文版权归本人所有,任何人不得抄袭,搬运,使用需征得本人同意!2022.6.23
日期:2022.6.22 DAY 4
DDPG 神经网络
DDPG 是一种强化学习神经网络,是基于DQN优化后的神经网络,DQN 是在QLearn的基础上使用神经网络代替Q表的动作价值优先策略的机器学习方法(深度学习)。换一句话说就是把Q表变成了一个神经网络,然后用这个神经网络去代替Q表,主要是避免大数据下,存储Q表困难。
DQN神经网络
现在我们使用的DQN一般是改进型,也就是具备记忆库的神经网络,这样做的目的是为了保持样本独立性,这个具体原理比较复杂,我就不展开了。
算法描述如下:

流程如下:
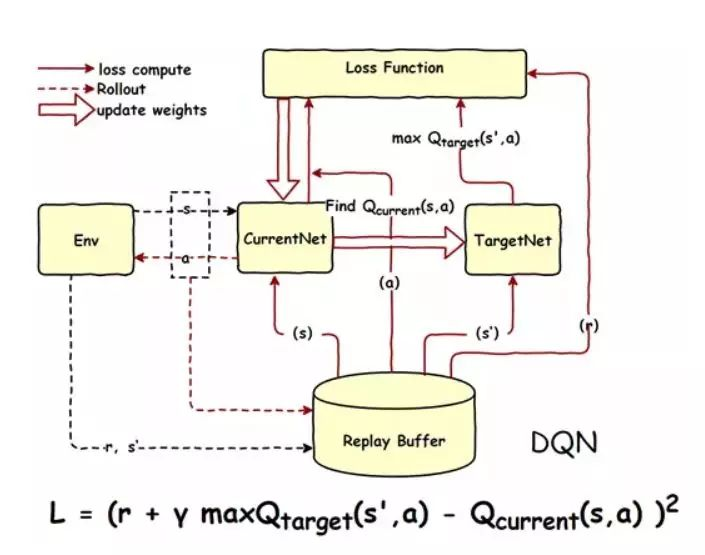
DQN的问题
从前面也知道,包括我以前写的有关于DQN 神经网络的博文,你会发现,这个玩意和传统的Qlearn没太大区别只是很巧妙地使用了神经网络,最终还是要得到一个关于每一个动作的打分,然后去按照那个得分去选择分高的动作,换一句话说是,这个神经网络还是只能得到对应动作的价值,例如 上下左右,然后选价值最大的,如 上 这个动作。
但是在我实际的PSO问题当中,我想要的是一组解,也就是你直接告诉我w c1 c2 取哪些值?
所以现在直接使用DQN 就很难了,显然这玩意貌似只能选择出一个动作,而我的w c1 c2 不可能是一个动作,如果把他看作是一个动作的话,那么你将有 无穷个动作选择,假定有范围,那就是可数无穷个动作。
DDGP
为了解决那个问题,于是有了DDGP,也就是我想要直接得到一组动作,你直接告诉我 w c1 c2取得哪些值?
怎么做,没错,再来一个神经网络。
具体怎么做,如下图:

Actor 网络直接生成一个动作,然后 原来在DQN的那个网络在这里是Critic 网络 去评价,这个评价其实就是在DQN里面的那个网络,输入一个S,和 A 得到一个价值,现在这个价值变成了评分。

损失函数就是这样:

GAN神经网络
现在我们再来对比一下GAN神经网络。
首先Actor 还是Actor
评委还是评委,这两个网络都是要训练的网络。

异同
这个判断器,就好比那个Cirtic,区别是啥?强化学习有个环境,这个DQN里面,或者DDPG里面那个评分怎么来的,还不是按照环境来给的,你把DDPG里面的Critic换成Q表一样跑,只是内存要炸,而且效果可能还要好,一方面精准记录,一方面只有一个网络。
而我们的GAN 是现有一个专家,这个专家不就也相当于环境嘛?此外损失函数不同。


使用GAN 建模
使用GAN和使用DDPG最大的问题在于如何对GAN进行建模,使用强化学习建模是非常简单的,因为直接根据适应值就可以了,但是在GAN来说,建模的问题在于如何确立判断器?这里我们其实可以从解本身出发,DDPG,强化学习是从适应值也就是F(x) 出发,这个适应值可以直接作为价值,而GAN,我们从解本身出发,还记得广义PSO嘛,我们知道了最好的解是怎么样的,那么我直接那啥,通过判断差异,不就可以实现打分了吗。
总结
这些就是今天的内容,和昨天比,有点垃了…
-
相关阅读:
更改主机名的方法(永久)
C#经典十大排序算法(完结)
JAVA中一段有趣的代码-关于类、多态、变量的执行分析
C++智能指针简介
【LeetCode每日一题】——90.子集 II
electron-vite:轻松保护你的 Electron 源代码
【机器学习300问】102、什么是混淆矩阵?
203. 数据库操作
SH-CST 2022丨SpeechHome 语音技术研讨会
数据结构Python版(四)——队列
- 原文地址:https://blog.csdn.net/FUTEROX/article/details/125434777