-
Redis6笔记02 配置文件,发布和订阅,新数据类型,Jedis操作
Redis配置文件详解
Units单位
配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit
大小写不敏感

INCLUDES包含

网络相关配置
NETWORK下,默认情况如下,表示只能接受本机的访问请求

不写的情况下,无限制接受任何ip地址的访问,生产环境下肯定要写你应用服务器的地址;服务器是需要远程访问的,所以需要将其注释掉

如果开启protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应

将其修改为no

端口号

tcp-backlog
设置tcp的backlog,backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列+已完成三次握手队列
在高并发环境下你需要一个高backlog值来避免慢客户端连接问题
注意Linux内核会将这个值减少到/proc/sys/net/core/somaxconn的值(128),所以需要确认增大/proc/sys/net/core/somaxconn和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)两个值来达到想要的效果

timeout

连接后无操作的超时时间,超时后需要重新连接,0代表永不超时
tcp-keepalive

检测当前连接是否还在操作(活着)的时间间隔
General通用
daemonize
是否为后台进程,设置为yes,守护进程,后台启动

pidfile
存放pid文件的位置,每个实例会产生一个不同的pid文件

loglevle
日志级别

logfile
日志文件输出路径

databases
设定库的数量默认16,默认数据库0,可以使用select<did>命令在连接上指定数据库id

SECURITY安全
设置密码,默认是没有设置的

访问密码的查看,设置

在命令中设置密码,只是临时的。重启redis服务器,密码就还原了
永久设置,需要在配置文件中设置
LIMITS限制
maxclients
设置redis同时可以与多少个客户端进行连接
默认情况下为10000个客户端
如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出"max number of clients reached"以作回应

maxmemory
建议必须设置,否则,将内存占满,造成服务器宕机
设置redis可以使用的内存量,一旦到达内存使用上限,redis会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。
如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么redis则会针对哪些需要申请内存的指令返回错误信息,比如SET,LPUSH等。
但是对于无内存申请的指令,仍然会正常响应,比如GET等。如果你的redis是主redis(说明有从redis),那么设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。
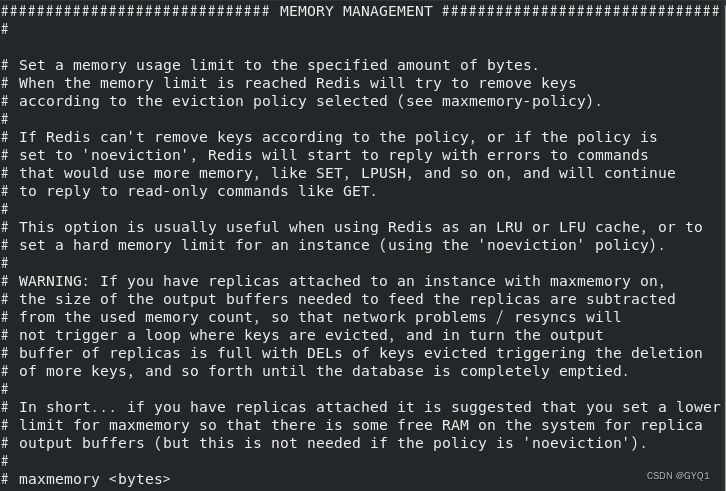
maxmemory-policy


maxmemory-samples
设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key并非选择LRU的那个
一般设置3-7的数字,数值越小样本越不精准,但性能消耗小。
发布和订阅
什么是发布和订阅
Redis发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis客户端可以订阅任意数量的频道。

发布订阅命令行实现
打开一个客户端订阅channel1

打开另一个客户端给channel1发布消息hello

返回1是订阅者数量
打开第一个客户端可以看到发送的消息

Redis6新数据类型
Bitmaps
现代计算机用二进制(位)作为信息的基础单位,1个字符等于8位,例如“abc”字符串是由3个字节组成,但实际在计算机存储时将其用二进制表示,“abc“分别对应的ASCII码分别是97,98,99,对应的二进制分别是01100001,01100010和01100011如下图

合理使用操作位能够有效地提高内存使用率和开发效率。
Redis提供了Bitmaps这个”数据类型”可以实现对位操作
Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作。
Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。

常用命令
setbit key offset value:设置Bitmaps中某个偏移量的值(0或1),偏移量从0开始
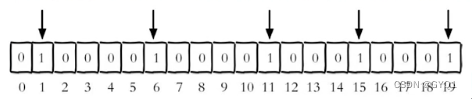
实例:每个独立用户是否访问过网站存放在Bitmaps中,将访问的用户记做1,没有访问的用户记做0,用偏移量作为用户id。
设置键的第offset个位的值(从0算起),假设现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问,那么当前Bitmaps初始化结果如图

很多应用的用户id以一个指定数字(如:10000)开头,直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费,通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时,假如偏移量非常大,那么整个初始化过程执行就会比较慢,可能会造成Redis阻塞。
getbit key offset:获取Bitmaps中某个偏移量的值,不存在的偏移量对应的值为0

bitcount key start end统计字符串从start字节到end字节比特值为1的数量

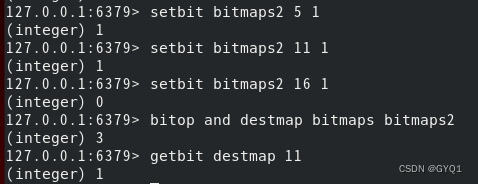
bitop and(or/not/xor) destkey key
bitop是一个符合操作,它可以做多个Bitmaps的and交集,or并集,not非,xor异或操作并将结果保存在destkey中
set和Bitmaps的对比
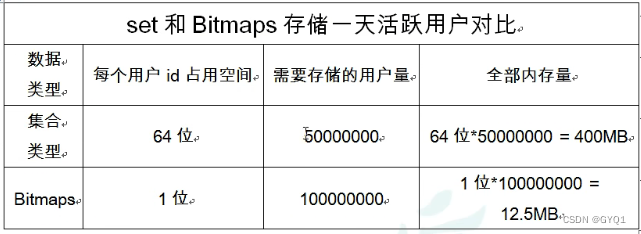
很明显,这种情况使用Bitmaps能节省很多的内存空间,尤其是随着时间的推移节省的内存还是非常可观的。

但是Bitmaps并不是万金油,加入该网站每天的独立访问用户很少,那么两者的对比如下表所示,很显然,这时候使用Bitmaps就不太合适了,因为基本上大部分位都是0。

HyperLogLog
在工作中,我们经常会遇到统计相关的功能需求,例如统计网站页面访问量,可以使用Redis的incr,incrby轻松实现。
但像UV(UniqueVistor,独立访客),独立IP数,搜索记录数等需要去重合计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
1、数据存储在Mysql表中,使用distinct count计算不重复个数
2、使用Redis提供的hash,set,bitmaps等数据结构来处理
以上方案结果精确,但是随着数据的不断增大,导致占用空间越来越大,对于非常大的数据集是不切实际的
能否能够降低一定的精度来平衡存储空间?Redis推出了HyperLogLog
Redis HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是,在输入元素的数量或体积非常非常大时,计算基数所需的空间总是固定的,并且是很小的
在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64不同元素的基数。这和计算基数时,元素越多损耗内存就越多的集合形成了鲜明对比。
但是,因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集{1,3,5,7,5,7,8},那么这个数据集的基数集为{1,3,5,7,8},基数(不重复元素个数)为5。基数估计就是在误差可接受的范围内,快速计算基数。
命令
pfadd key element...:添加指定元素到HyperLogLog中
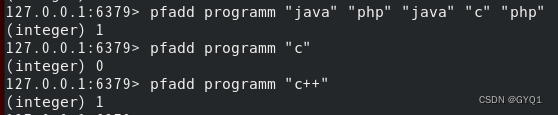
加入之后,基数发生变化返回1,否则返回0
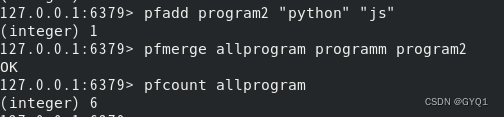
pfcount key....:计算HLL的近似基数,可以 计算多个HLL,用HLL存储每天的UV,计算一周的使用7天的合并即可

pfmerge destkey sourcekey1 sourcekey2.....:将一个或多个HLL合并后的结果存储在另一个HLL
Geospatial
Redis3.2中增加了对GED类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的二维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
命令
geoadd key longgitude latitude member...:添加地理位置(精度,维度,名称)


geopos key member:获取指定地区的坐标值

geodist key member1 member2 [m|km|ft|mi]:获取两个位置之间的直线距离,默认米

mi:英里,ft:英尺
georadius key longitude latitude radius [m|km|ft|mi],已给定的经纬度为中心,找出某一半径内的元素

Jedis操作Redis6
连接Redis
创建maven工程
添加Jedis所需依赖
- <dependency>
- <groupId>redis.clients</groupId>
- <artifactId>jedis</artifactId>
- <version>3.2.0</version>
- </dependency>
Java连接Redis
需要先注释掉redis.conf中bind下的内容

关闭protected mode

查看Linux系统防火墙状态,按q退出
systemctl status firewalld
暂时关闭防火墙
systemctl stop firewalld测试

返回值为PONG则连接成功
测试相关操作
操作String类型

操作list
操作set
操作hash
操作zset

和命令行命令一一对应。
案例:验证码(六位随机验证码,两分钟过期,每个手机号每天三次)
- public class JedisDemo {
- public static void main(String[] args) {
- //用户提示
- System.out.println("请输入您的手机号码");
- Scanner sc = new Scanner(System.in);
- String tel = sc.next();
- //验证发送次数,将验证码放入Redis
- verifyCode(tel);
- //用户输入验证码
- System.out.println("请输入收到的验证码");
- String code = sc.next();
- //判断验证码是否正确
- getRedisCode(tel, code);
- }
- //生成验证码
- public static String generateCode() {
- Random random = new Random();
- String code = "";
- for (int i = 0; i < 6; i++) {
- int rand = random.nextInt(10);
- code += rand;
- }
- return code;
- }
- //每个手机每天只能发送三次验证码,将验证码放到Redis中
- public static void verifyCode(String tel) {
- //创建Jedis对象,Redis运行的服务器的ip地址,端口号
- Jedis jedis = new Jedis("192.168.199.129", 6379);
- //拼接key
- //手机发送次数key
- String countKey = "VerifyCode" + tel + ":count";
- //验证码key
- String codeKey = "VerifyCode" + tel + ":code";
- //每个手机每次只能发送三次
- String count = jedis.get(countKey);
- if (count == null) {
- //第一次发送
- jedis.setex(countKey, 24 * 60 * 60, "1");
- } else if (Integer.parseInt(count) <= 2) {
- //发送次数加1
- jedis.incr(countKey);
- } else if (Integer.parseInt(count) > 2) {
- //已经发送了三次
- System.out.println("发送超过三次了");
- jedis.close();
- return;
- }
- //发送验证码放到redis中去
- String code = generateCode();
- System.out.println(code);
- jedis.setex(codeKey, 120, code);
- jedis.close();
- }
- //验证码校验
- public static void getRedisCode(String tel, String code) {
- //连接Redis
- Jedis jedis = new Jedis("192.168.199.129", 6379);
- //验证码key
- String codeKey = "VerifyCode" + tel + ":code";
- String redisCode = jedis.get(codeKey);
- //判断
- if (code.equals(redisCode)) {
- System.out.println("验证成功");
- } else {
- System.out.println("验证失败");
- }
- }
- }
-
相关阅读:
Dubbo 框架搭建一个passport案例
Oracle/PLSQL: Sign Function
新知同享 | AI 开发广泛应用,高效构建
pair的用法
单商户商城系统功能拆解33—营销中心—包邮活动
构建dagu+replicadb镜像
金九银十Go面试题进阶知识点:select和channel
电机应用-步进电机
一次 Java log4j2 漏洞导致的生产问题
PMP项目管理中的各种图
- 原文地址:https://blog.csdn.net/qq_53157982/article/details/125389693