-
使用Navicat对比多环境数据库数据差异和结构差异,以及自动DML和DDL脚本
说明
今天在开发项目中在使用navicat同步工具时无意中看到数据同步和结构同步有点好奇,于是就简单使用了下,使用过后感觉很适合目前的需求;
【1】不同环境数据库表的差异对比,以及自动生成差异DDL语句
【2】不同环境的数据记录的差异,以及自动生成DML语句
【数据传输】相信开发人员很熟悉经常使用,而对于【数据同步】【结构同步】之前是没有接触的,其中数据同步主要对比两个数据间对应表的数据差异,结构同步主要对比两个数据库间数据表的差异以及生成SQL脚本。结构同步
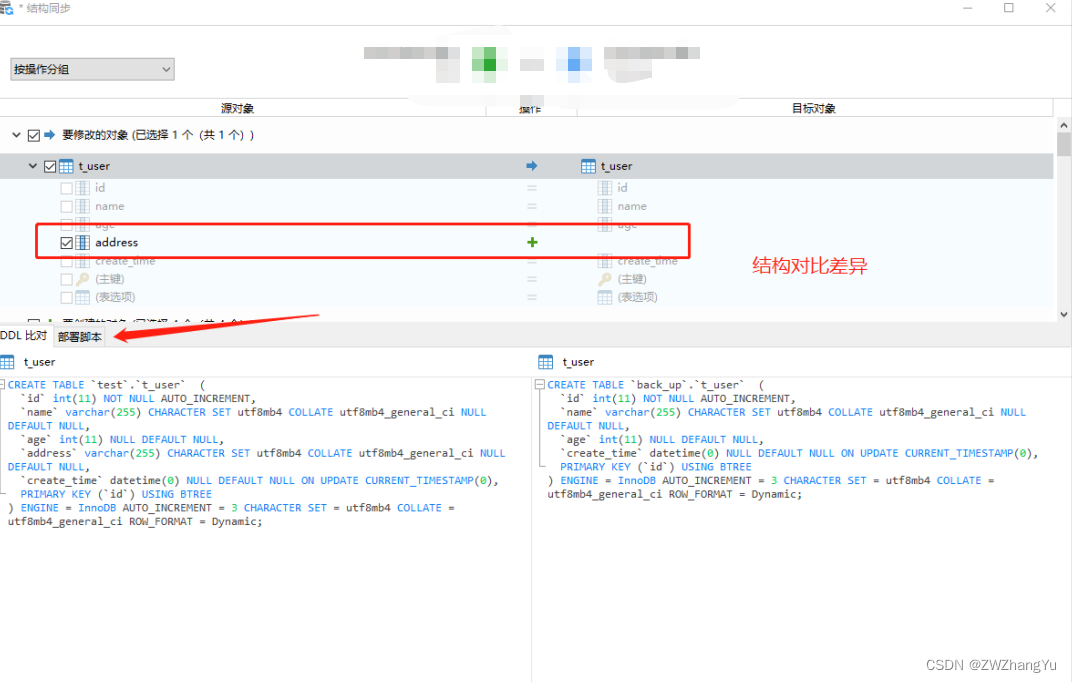
准备两个数据库,然后分别在两个数据库创建一个相同表名的数据表,其中上边的表比下面边的多一个address字段。
CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(255) DEFAULT NULL, `create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, `create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;- 1
- 2
- 3
- 4
- 5
- 6
- 7
选择【工具】【结构对比】,选择t_user表结果如下,通过下面的展示可以很直观的看到差异
点击【部署脚本】可以看到工具帮我们生成的差异SQL,非常的方便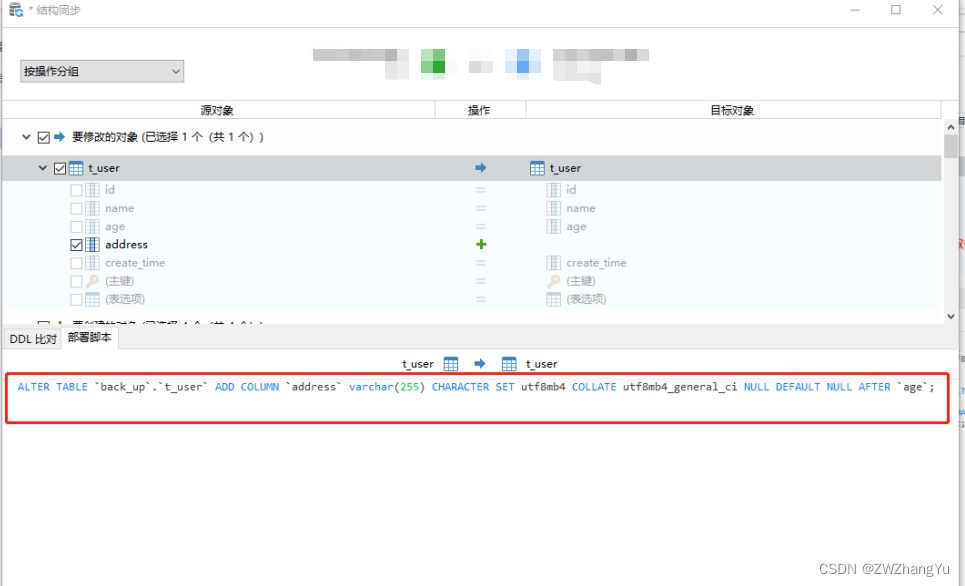
数据同步
基于上面的表结构,执行上面生成的DDL语句使两边的数据表保持一致,然后添加如下的测试数据
【源库】 INSERT INTO `t_user`(`id`, `name`, `age`, `address`, `create_time`) VALUES (1, '张三', 25, '安徽合肥', '2022-06-22 15:29:16'); INSERT INTO `t_user`(`id`, `name`, `age`, `address`, `create_time`) VALUES (2, '李四', 25, '合肥', '2022-06-22 15:29:54'); INSERT INTO `t_user`(`id`, `name`, `age`, `address`, `create_time`) VALUES (3, '王五', 25, '合肥', '2022-06-22 15:29:54'); 【目标库】 INSERT INTO `t_user`(`id`, `name`, `age`, `address`, `create_time`) VALUES (1, '张三', 25, '安徽合肥', '2022-06-22 15:29:16'); INSERT INTO `t_user`(`id`, `name`, `age`, `address`, `create_time`) VALUES (3, '王五', 26, '上海', '2022-06-22 15:29:54');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
点击【工具】【数据同步】,选择源库和目标库,下图就是本次对比的结果。
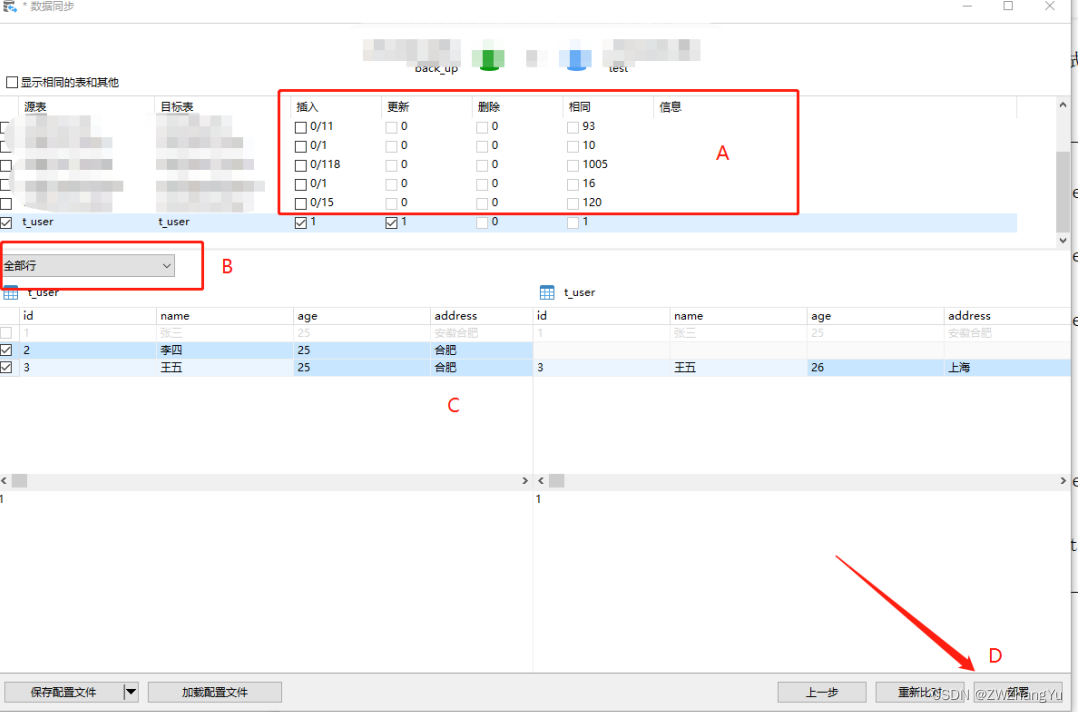
【A】区域展示了经过对比存在不同数据的表的记录,展示了不同的记录数和相同的数量等等。【B】区域这里可以选择仅展示不同的数据,相同的数据,全部的数据等等,展示的结果在C区域,会以不同的颜色标识。
【C】展示了实际的对比结果,通过上图可以看到两库之间ID为1的数据记录相同,左表多一个ID为2的记录,两表ID为3的记录数据有差异
【D】部署,点击部署会生成差异的SQL,如上例所示,从源库到目标库,会新增一个ID为2的记录,并更新ID为3的记录
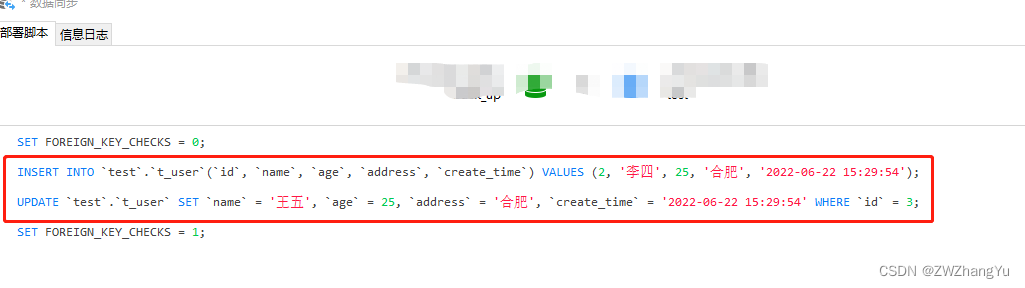
生成的DML如下:SET FOREIGN_KEY_CHECKS = 0; INSERT INTO `test`.`t_user`(`id`, `name`, `age`, `address`, `create_time`) VALUES (2, '李四', 25, '合肥', '2022-06-22 15:29:54'); UPDATE `test`.`t_user` SET `name` = '王五', `age` = 25, `address` = '合肥', `create_time` = '2022-06-22 15:29:54' WHERE `id` = 3; SET FOREIGN_KEY_CHECKS = 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中:SET FOREIGN_KEY_CHECKS作用:在执行sql脚本时,为了不让外键受影响导致出错。
小结
【1】本次只是简单的测试了数据同步和结构同步的功能,对于这两个功能也是工作中无意接触到的,在了解过后确实感觉对于以后的项目开发中有一定的帮助。
【2】对于其中数据结构同步,在进行版本测试提测时或者大版本升级的时候,如果没有留存升级脚本,可以通过该工具一键快速生成相关的DDL语句。如果准备了升级脚本,也还是可以通过这个工具进行一次源库和目标库的对比,这样可以保证升级时不会有缺失的,做一个保障。【3】其中数据同步功能可以适用于一些基础表、配置表、字典表等等,如果开发中有人变更了某些数据但是未及时提交,就会导致各环境不一致。此外,对于数据结构的变更一般能够比较及时的提交,但是对于临时修改一些配置数据,基础数据等很可能有遗漏的情况,那么通过这个工具就可以对比差异,并自动生成差异SQL。
【4】在接触到该功能后,我也找了一些类似的产品,比如Liquibase、dbForge Data Compare、以及一些开源的平台。总体的功能差不多,Navicat这里提供的使用起来很方便功能也很强大,最重要的没有其他成本,作为目前项目团队所使用的数据库连接工具,可以直接连接各个环境数据库无需额外配置,而且稳定好用。
-
相关阅读:
CSS画一条虚线,并且灵活设置虚线的宽度和虚线之间的间隔和虚线的颜色
盘点CSV文件在Excel中打开后乱码问题的三种处理方法
【Vue】数据表格增删改查与表单验证
nginx的安装(一)
APT攻击与零日漏洞
B站:李宏毅2020机器学习笔记 5 —— 分类器Classification
WPF 制作 Windows 屏保
Linux组的介绍:1.文件/目录 所有者相关命令+2.组的创建+3.权限的基本介绍
华为OD机试真题-计算误码率-2023年OD统一考试(B卷)
UG\NX二次开发 获取装配部件的相关信息UF_ASSEM_ask_component_data
- 原文地址:https://blog.csdn.net/Octopus21/article/details/125433610