-
Kafka ETL 之后,我们将如何定义新一代实时数据集成解决方案?

上一个十年,以 Hadoop 为代表的大数据技术发展如火如荼,各种数据平台、数据湖、数据中台等产品和解决方案层出不穷,这些方案最常用的场景包括统一汇聚企业数据,并对这些离线数据进行分析洞察,来达到辅助决策或者辅助营销的目的,像传统的 BI 报表、数据大屏、标签画像等等。
但企业中除了这样分析型业务(OLAP),还同时存在对数据实时性要求更高的交互型业务场景(OLTP 或 Operational Applications),例如电商行业常见的统一商品或订单查询、金融行业的实时风控、服务行业的客户 CDP 等,这些场景对企业来说往往都是关键任务类型。
除了 OLTP 场景,很多新一代的运营型分析(Operational Analytics)也在逐渐成为主流数据应用,运营分析的特点是同样需要来自业务系统的最新的实时数据,以帮助客户做一些较为及时的业务响应。
针对这些交互式 APP 或者运营分析的场景,传统的大数据平台由于其对实时数据支持度有限,无法予以有效支撑。今天我们就来探讨关于实时数据的问题:
-
什么是实时数据?
-
如何获取实时数据,目前有哪些解决方案?分别是怎样解决问题的?有什么利弊?
-
一个理想的实时数据架构应该具有哪些特征?
-
如何利用新一代实时架构,对传统解决方案进行升级或替换?
一、什么是实时数据
一般来说,实时数据指的是对数据的传输、处理或最后交付发生在数据刚产生的短暂瞬间,如实时同步、实时消息处理等。用来衡量实时的指标是数据从产生端到消费端的传输时延。另外一种实时数据,则指的是对查询或者计算的响应是否足够快速,更多针对于数据库的内建分析或者查询引擎。这种实时数据技术的衡量指标是响应时间。如果传输时延或者响应时间能够控制在亚秒或者数秒内,我们可以称这些技术是”实时数据”技术。从用户的角度看,他们能够感受到的是一个“交互”式的体验,例如我执行一次查询,或者调取一个最新统计数字,结果通常在 1-3 秒之内返回,就是一种较为理想的实时体验。
如果我们把实时数据技术放到一个数据架构的完整版图里面,可能更容易来理解实时数据到底意味着什么。A16Z 的 Matt Bornstein 在 Emerging Architectures for Modern Data Infrastructure 这篇文章里,很好地归纳了新一代数据基础架构的主要组成部分。他把数据基础架构全生命周期分成了几个阶段: Ingestion, Storage, Query & Processing, Transformation, Analysis & Output。
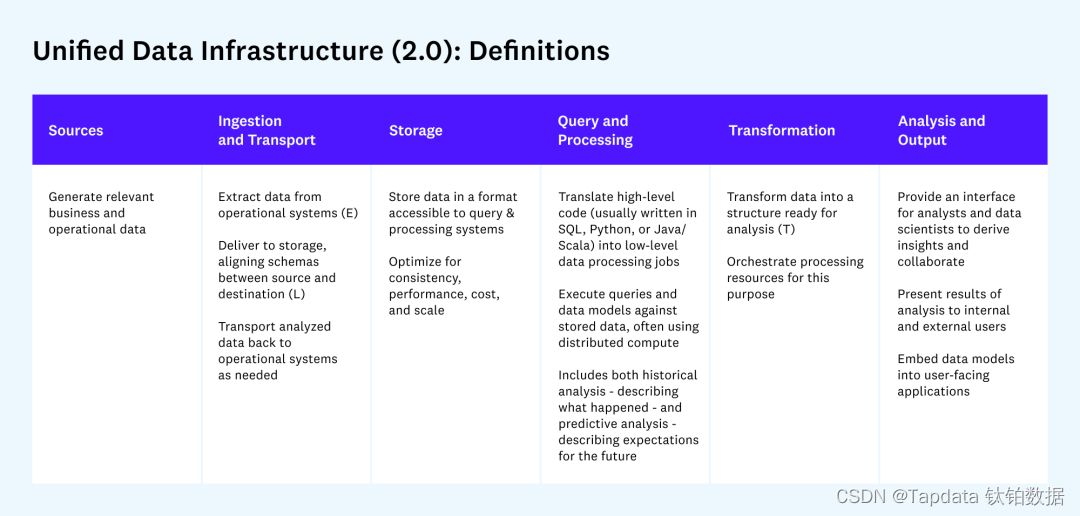
以这个框架作为参考,我们可以做一个离线数据技术和实时数据技术的对比:
如图所示,实时数据包含了实时采集同步、实时计算、实时存储、实时查询和服务等范畴。在实际工作中,这些技术支撑的场景案例分别如下:
实时采集同步/实时集成
以数字化防疫场景为例,疫情防控特殊阶段,“核酸码”、“健康码”已成日常出行的必需品,特别是在核酸检测频率较高的时期,因检测结果显示不及时而影响日常工作生活的情况比比皆是。而应对这一问题的核心环节,就是核酸检测数据的实时、精准采集。
实时计算
以数据可视化大屏的应用场景为例,作为传统制造业实现数字化转型的常见辅助工具,实时产能大屏可以为实现自动化生产提供数据依据;实时监控运行情况,及时预警;帮助企业分析产品周期,实现精准洞察,辅助业务开拓。而实现这些目标的基础就是实时数据——通过对全部系统数据的实时采集、实时计算,让数据分析展示更高效。
实时分析
以金融行业的反欺诈平台为例,随着用户体量不断增大,客户历史行为数据也在持续累积,为了在数据分析处理的同时不对交易行为产生影响,新时代的风控工作面临着更多实时性挑战,传统数仓架构逐渐无法满足相应需求。因此,需要联合多渠道表现,对客户行为数据进行实时分析与反馈,快速区分欺诈交易与正常交易,助力快速决策。
实时查询、服务
银行个贷、互金小额贷、保险等在线金融业务需要对客户进行实时风险管控。通过实时数据服务,可以将来自于金融系统和外部系统(信用、司法、公安等)的个人数据进行统一汇聚,在申请流程中实时查询客户的风险信息并提供给算法引擎做决策。
二、实时数据技术之源:实时数据集成
无论是哪一种实时数据处理技术,都离不开一个事实:我们需要有实时的数据来源。Doris 作为一个实时数仓,只有获取到第一时间的新鲜数据,才能得出即时有效的洞察;Flink 的实时流计算,需要 Kafka 为其供数;而 Kafka 作为消息队列,需要用户自己负责将源头数据推到 Kafka 的 Topic。可以说,一切的实时数据技术,都离不开源头——实时数据的获取和集成。
实时数据的集成,常见的技术方案有以下几种:
-
定制 API 集成或者使用低代码API
-
ETL 工具
-
ESB 或者MQ
-
Kafka
我们分别来看看这几种解决方案的 Pros & Cons。
API 、ETL 和 ESB
API 集成是一个不需要第三方工具的解决方案。通常可以由研发团队按照数据共享的诉求,定制开发相应的 API 接口,测试上线来支持下游业务。
这种方式的 Pros:
-
无需购买商业方案,就地制宜
-
可以高度定制
Cons 也比较明显:
-
需求变多时,开发成本会比较高,API 的管理也会出新的问题
-
对源库性能有不小的影响,这是核心业务系统一般不能容忍的
-
API 方式不太适合有全量或者大量数据交付的场景
ETL 是通过抽取的方式将需要的数据复制到下游的系统内。取决于需求量,可以通过自己写一些定期运行的脚本,或者使用一些成熟的 ETL 工具来实现。
Pros:
-
对源库性能影响较小,可以安排在业务低峰如半夜执行
-
实现相对简单,也可以有很多的开源或者商业工具
Cons:
-
定期执行,无法支撑对数据时效性要求比较高的场景
-
ETL 无法复用,每个新起业务都需要不少数量的 ETL 链路,导致数量激增,管理困难
ESB 作为一个企业数据总线,通过一系列的接口标准,将独立的软件系统以一个中央总线方式连接在一起。每个系统如果需要将数据或者消息传递给另外一个系统,可以通过 ESB 进行中转。ESB 的架构优势体现在:
-
移除了多个系统之间进行两两交互的重复工作
-
降低了系统之间的对接成本,都只需要和标准的 ESB 中间件交互就够了
-
数据实时可达
但是 ESB 已经被证明是“明日黄花”,它主要的锅在于:
-
接口定义异常繁琐
-
性能较低,无法支撑新一代大量的实时数据处理诉求
-
和系统耦合比较高,更新一个上游系统可能会影响到下游系统
-
成本较高,只有商业化方案
今天的主流:Kafka ETL
十年前,随着大数据技术的发展,一个叫做 Kafka 的消息中间件开始流行起来,并快速在实时数据集成领域占据架构主导地位。作为最主流的消息事件平台代表,Apache Kafka 最初只是一个分布式的日志存储。后来逐渐增加了 Kafka Connect 和 Kafka Streams 功能。基于这些能力,我们可以用 Kafka 来搭建一个实时 ETL 链路,满足企业内业务系统之间数据实时集成的需求。
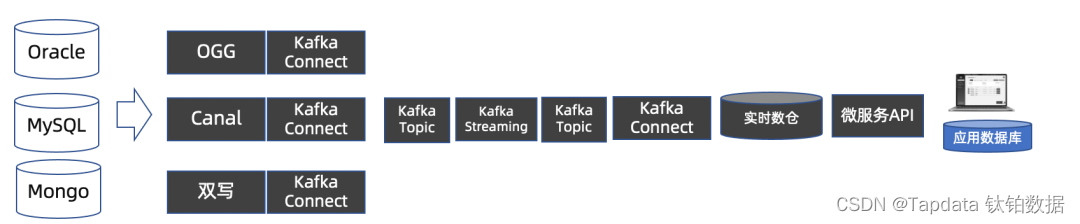
但是这种基于 Kafka 来做实时 ETL 的架构,不足点非常明显:
-
需要自己对接、实现数据采集的能力,很多时候意味着应用双写(代码侵入!)或额外的开源组件
-
需要 Java 代码开发,超出一般数据工程师的能力范围
-
节点多、链路长、数据容易中断、排查不容易
DaaS:以服务化的方式来解决数据集成的问题
总结下来,已有的技术方案在一定程度上满足需求的前提下,都有一些明确的痛点:
-
API 开发太繁琐,对源端性能侵入影响高
-
ETL 实时性不够,无法有效复用,造成意大利面的摊子
-
ESB 有中央化的优势,太贵性能太弱,已经 out
-
Kafka 架构复杂,开发成本不低,关键数据排错很困难
DaaS(Data as a Service,数据即服务)是一种新型的数据架构,通过将企业的核心数据进行物理或者逻辑的汇总,然后通过一个标准化的方式为下游提供数据的支撑,如下图所示:
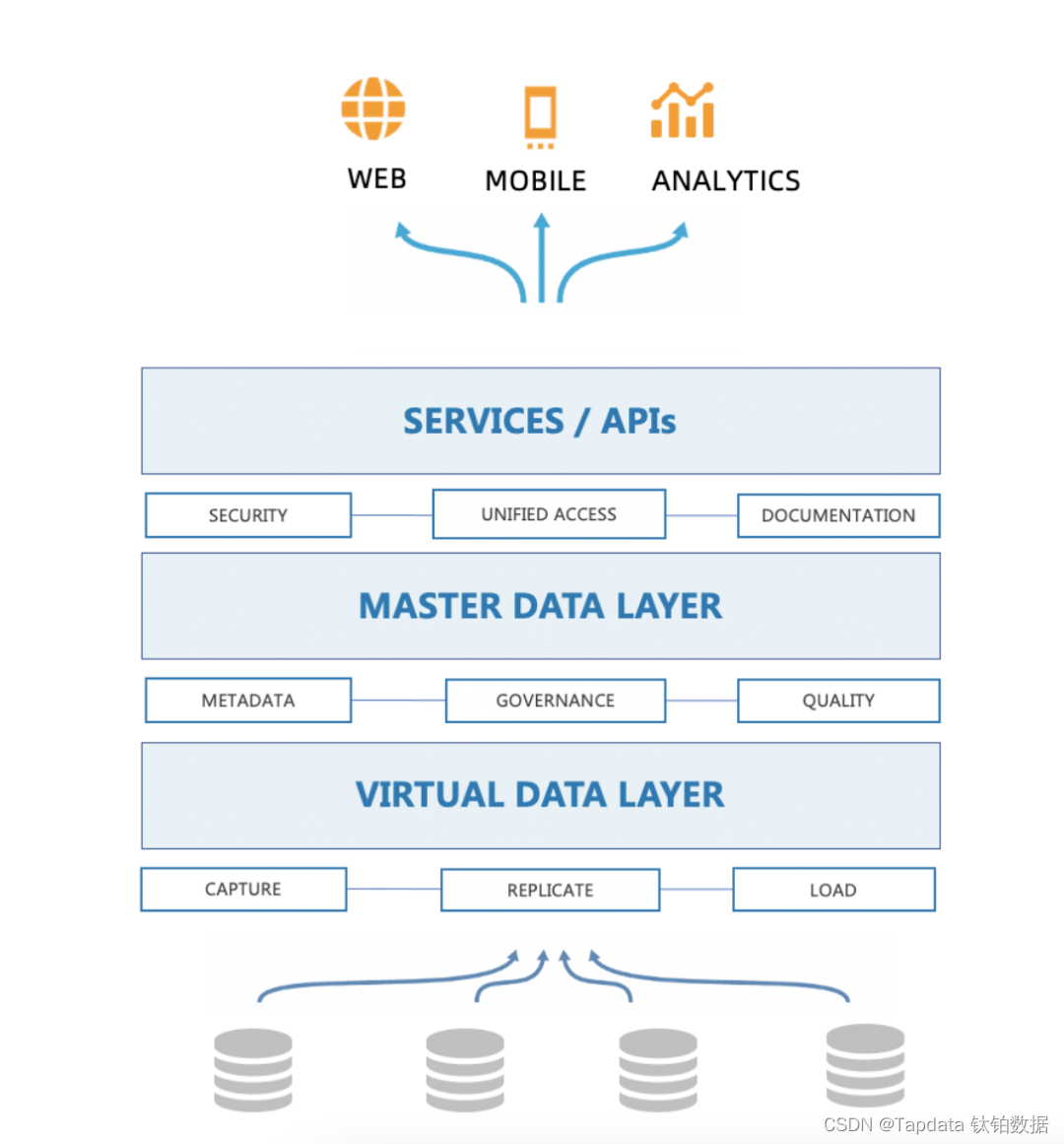
这种架构的优势是:
-
数据中央化,可以在一个地方为多个业务提供数据,充分提高数据复用能力
-
接口标准化
-
数据采集只需要一次性完成,结合元数据管理技术,为企业构建一个全面的数据目录,可以快速发现需要的数据
-
解耦:数据的入库和数据服务分开,不会产生耦合
但是传统的 DaaS 解决方案,如数据中台这样的实现,有一个很大的局限就是数据的入库是通过批量采集方式,导致数据不够新鲜实时,直接影响了传统 DaaS 的业务价值。
三、新一代 DaaS 方案:自带实时 ETL 的数据服务平台
展望新的十年,基于完全自主研发的新一代实时数据平台「Tapdata Live Data Platform」应运而生,作为一个实现 DaaS 架构的新型数据平台,Tapdata LDP 的核心突破点是自己实现了完整的基于 CDC 的异构数据实时集成+计算建模的能力,通过源源不断对数十种源数据库实时采集并输送到 DaaS 存储的方式,确保数据在 DaaS 里始终得到实时更新,实现了一个 Incremental DaaS,增量数据服务平台的理念。通过这种对 DaaS 的实时增强,Tapdata 将承载着将企业 ETL 数量从 N 降为 1 的使命,凭借“全链路实时”的核心技术优势,加速连接并统一数据孤岛,打造一站式的实时数据服务底座,为企业的数据驱动业务“Warehouse Native ”提供全面、完整、准确的新鲜数据支撑。
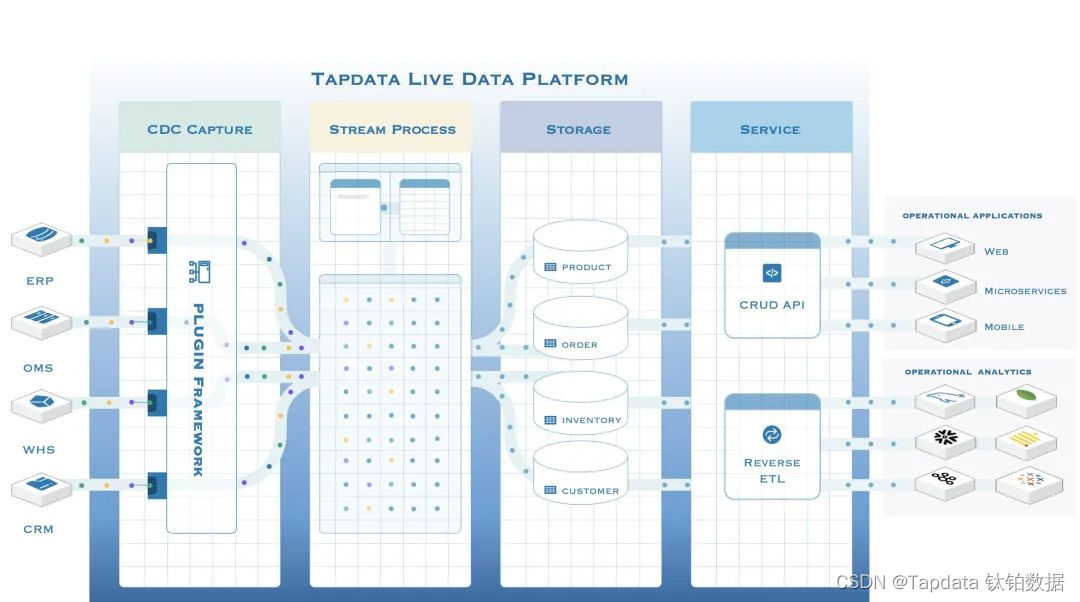
一图读懂 Tapdata LDP 的工作模式
功能特性
-
首个同时支持 TP 和 AP 业务场景的实时数据平台
-
两大核心技术能力:实时数据集成(ETL) 和 实时数据服务(DaaS)
-
首创以 DaaS 方式解决实时数据集成问题,数倍降低 ETL 链路数量
-
40+ 数据源的实时复制能力,立即打通企业数据孤岛
-
多流合并、复杂宽表构建等实时流计算能力
-
面向程序员:首创 Fluent ETL,用代码而不是 SQL 来处理数据
-
面向数据工程师:全程可视化,拖拉拽完成开发建模
-
开放+开源,使用PDK自助扩展更多对接和处理能力,在免费获得实时能力同时回馈社区
实时应用场景
-
实时数据管道:Tapdata 可以用来替换 CDC + Kafka + Flink,几分钟快速构建完整的数据采集+流转的管道,避开 CDC 数据采集易错、Kafka 阻塞、链路排查困难等大坑小坑。
-
实时 ETL:Tapdata 可以用来替换 Kettle / Informatica 或 Python 这样的 ETL 工具或脚本。基于 JS 或 Python 的 UDF 功能可以无限扩展处理能力;分布式部署能力可以提供更高的处理性能;基于拖拉拽的新一代数据开发更加简便。此外,还支持通过自定义算子快速扩展平台的数据处理及加工能力。
-
实时构建宽表:从大数据分析到数仓建设,再到 Dashboard,数据工程人员使用大量批处理任务来生成用于展现和分析的宽表或视图。这些宽表构建通常需要耗费大量资源,且数据更新不及时。但若利用 Tapdata 独特的增量宽表构建能力,即可以最小化的成本提供最新鲜的数据结果。
-
实时数据服务:数字化转型过程中企业需要构建大量新型业务,这些业务往往需要来自其他业务系统的数据。传统基于 ETL 的数据搬运方案局限性较大,如链路繁杂、无法复用、大量的数据链路对源端产生影响较大等。Tapdata 的实时数据服务可以通过对数据做最后一次 ETL,同步到基于 MongoDB 或 TiDB 的分布式数据平台,结合无代码 API,可以为众多下游业务直接在数据平台提供快速的数据 API 支撑。
想要了解更多新一代实时数据集成架构的技术细节,以及实时数据领域的前沿发展,推荐关注下周三 6 月 29 日 14:30 的 Tapdata Live Data Platform 产品发布暨开源说明会——纯粹的技术分享,干货式的理念交流,更有实时数据“输送者”和“使用者”等多方代表参与的圆桌论坛——敬请期待!点击报名

-
-
相关阅读:
有营养的算法笔记五
对话PostgreSQL作者Bruce:“转行”是为了更好地前行
利用SpringBoot框架轻松上手常用的设计模式
cv2.split函数与cv2.merge函数
全量知识系统问题及SmartChat给出的答复 之12 知识图表设计
高质量发展项目——冠心病药物治疗管理标准化培训在京顺利举办
Golang实现JAVA虚拟机-指令集和解释器
kubernetes 通过HostAliases属性配置域名解析
Flutter(一) package的使用、开发与发布
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(二)
- 原文地址:https://blog.csdn.net/weixin_58202160/article/details/125430890