-
Pandas.read_csv()函数及全部参数使用方法一文详解+实例代码
目录
前言
Pandas常用作数据分析工具库以及利用其自带的DataFrame数据类型做一些灵活的数据转换、计算、运算等复杂操作,但都是建立在我们获取数据源的数据之后。因此作为读取数据源信息的接口函数必然拥有其强大且方便的能力,在读取不同类源或是不同类数据时都有其对应的read函数可进行先一步处理,这会减少我们相当大的一部分数据处理操作。每一个read()函数,作为一名数据分析师我个人认为都应该掌握且熟悉它对应的参数,相对应的read()函数博主已有三篇文章详细解读了read_json、read_excel和read_sql:
Pandas获取SQL数据库read_sql()函数及参数一文详解+实例代码
Pandas处理JSON文件read_json()一文详解+代码展示
Pandas中read_excel函数参数使用详解+实例代码
纵观整个数据源路径来看,最常用的数据存储对象:SQL、JSON、EXCEL以及这次要详解的CSV都遍及全了。 如果能够懂得该函数参数的使用可以减少大量后续处理DataFrame数据结构的代码,仅需要设置几个read_csv参数就可实现,因此本篇文章初衷为详细介绍并运用此函数来达到彻底掌握的目的。希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新,希望大家喜欢。
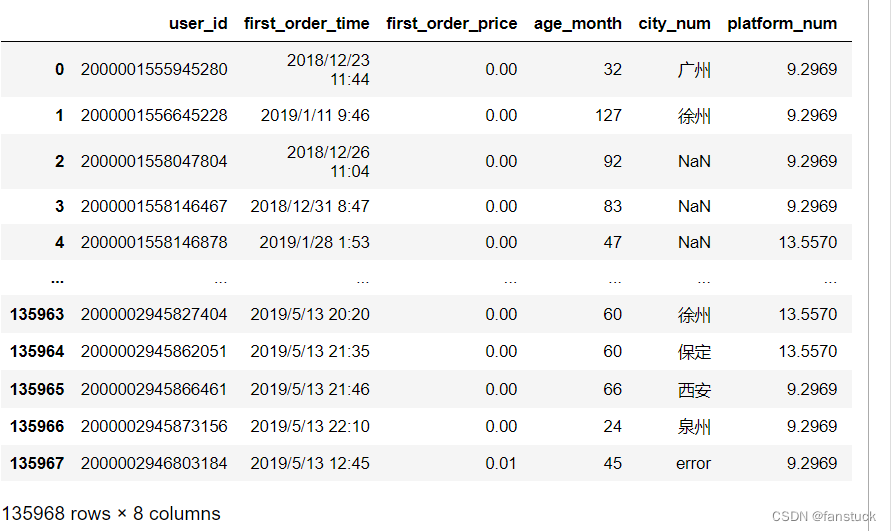
这里拿脱敏后的user_info.csv文件作为展示:

一、基础语法与功能
read_csv基础语法格式为:
- pandas.read_csv(filepath_or_buffer,
- sep=NoDefault.no_default,
- delimiter=None,
- header='infer',
- names=NoDefault.no_default,
- index_col=None,
- usecols=None,
- squeeze=None,
- prefix=NoDefault.no_default,
- mangle_dupe_cols=True,
- dtype=None,
- engine=None,
- converters=None,
- true_values=None,
- false_values=None,
- skipinitialspace=False,
- skiprows=None,
- skipfooter=0,
- nrows=None,
- na_values=None,
- keep_default_na=True,
- na_filter=True,
- verbose=False,
- skip_blank_lines=True,
- parse_dates=None,
- infer_datetime_format=False,
- keep_date_col=False,
- date_parser=None,
- dayfirst=False,
- cache_dates=True,
- iterator=False,
- chunksize=None,
- compression='infer',
- thousands=None,
- decimal='.',
- lineterminator=None,
- quotechar='"',
- quoting=0,
- doublequote=True,
- escapechar=None,
- comment=None,
- encoding=None,
- encoding_errors='strict',
- dialect=None,
- error_bad_lines=None,
- warn_bad_lines=None,
- on_bad_lines=None,
- delim_whitespace=False,
- low_memory=True,
- memory_map=False,
- float_precision=None,
- storage_options=None)
可以看到参数是相当多的,比起read_excel、read_json和read_sql加起来还要多。说明了使用csv文件存储数据的频率是其他记录数据文件的几倍之高,因此关于csv文件的处理参数也会有如此之多。这是好事,等到我们将csv文件转换为了DataFrame数据再处理时,就需要写很多代码去处理,提供了这么多参数可以大大加快我们处理文件的效率。
read_csv的基本功能就是将csv文件转化为DataFrame或者是TextParser,还支持可选地将文件迭代或分解为块。
- import numpy as np
- import pandas as pd
- df_csv=pd.read_csv('user_info.csv')
二、参数说明和代码演示
以下为官方文档,文字实在是太多了推荐直接点目录看:
首先我们将逐个了解每个参数的功能和作用,在了解参数意义后再进行实例使用。
1.filepath_or_buffer
接受类型:{str, path object or file-like object}字符串(一般为文件名且在当前运行程序的目录下才能读取到)、文件路径(一般推荐为绝对路径)、或者为其他可引用的数据类型。如url,http这种类型。
此参数为指定读入文件的路径。可以接受任何有效的字符串路径。字符串可以是URL。有效的URL包括http、ftp、s3、gs和文件。对于文件URL,本地文件可以是:file://localhost/path/to/table.csv.
如果要传入路径对象,pandas接受任何路径。
对于类文件对象,我们使用read()方法引用对象,例如文件句柄(例如通过内置的open函数)或StringIO。df_csv=pd.read_csv('user_info.csv')df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv')df_csv=pd.read_csv('C:\\Users\\10799\\test-python\\user_info.csv')2.sep
接受类型{str, default ‘,’}
csv文件一般默认是用','来分隔每个字符串的,而sep就是指定分隔的符号是什么类型。
如果sep为None,则C引擎无法自动检测分隔符,但Python解析引擎可以,这意味着Python的内置嗅探器工具csv将使用后者并自动检测分隔符。此外,长度超过1个字符且与“\s+”不同的分隔符将被解释为正则表达式,并将强制使用Python解析引擎。请注意regex分隔符容易忽略引用的数据。regex正则表达式示例:“\r\t”。
- df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',sep=',')
- df_csv

对于sep字符可以参照转义字符:
转义字符 描述 \(在行尾时) 续行符 \\ 反斜杠符号 \‘ 单引号 \” 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 换行 \v 纵向制表符 \t 横向制表符 \r 回车 \f 换页 \oyy 八进制数yy代表的字符,例如:\o12代表换行 \xyy 十进制数yy代表的字符,例如:\x0a代表换行 \other 其它的字符以普通格式输出 df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',sep='/t')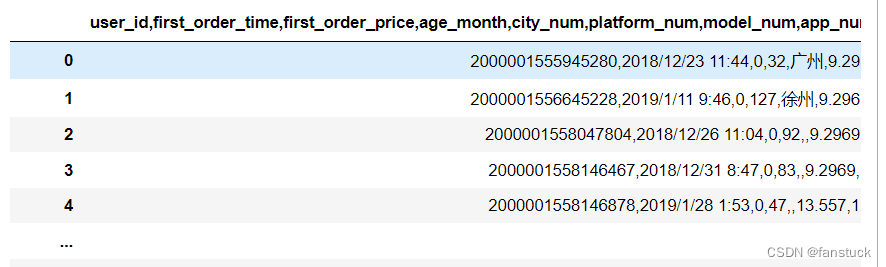
这样不再重复实验,有兴趣的大家可以自行尝试。
3.delimiter
接受类型:{str, default
None}sep的别名,可以设置为想要名字,没有什么很大的意义。
- df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',delimiter=',')
- df_csv

4.header
接受类型:{int, list of int, None, default ‘infer’}整数、整数列表、None。默认为infer
指定要用作列名的行号,以及数据的开头。默认行为是推断列名:如果未传递任何名称,则行为与header=0相同,并且从文件的第一行推断列名,如果显式传递列名,则行为与header=None相同。显式传递header=0,以便能够替换现有名称。标题可以是整数列表,指定列上多索引的行位置,例如[0,1,3]。将跳过未指定的中间行(例如,跳过本例中的2)。请注意,如果skip_blank_lines=True,此参数将忽略注释行和空行,因此header=0表示数据的第一行,而不是文件的第一行。
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',header=1)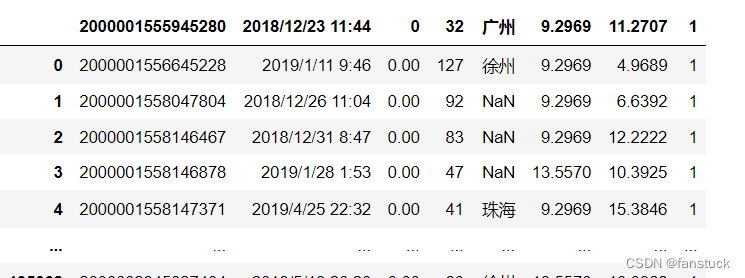
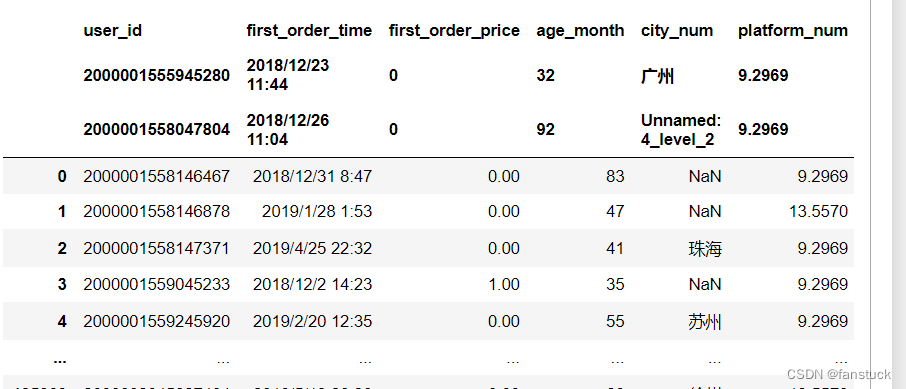
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',header=[0,1,3])这样的话。第二例就会消失:
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',header=None)
5.names
接受类型:{array-like, optional}
指定要使用的列名列表。如果文件包含标题行,则应显式传递header=0以覆盖列名。此列表中不允许重复。
- df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',
- header=0,names=['id','time','name1','name2','name3','name4','name5','name6'])
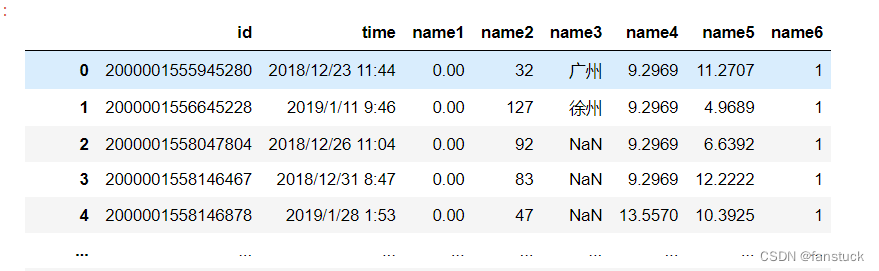
6.index_col
接受类型:{int, str, sequence of int / str, or False, optional}默认为None。
指定要用作DataFrame行标签的列,以字符串名称或列索引的形式给出。如果给定int/str序列,则使用多索引。
注意:index_col=False可用于强制pandas不使用第一列作为索引,例如,当您有一个格式错误的文件,每行末尾都有分隔符时。df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',index_col='user_id')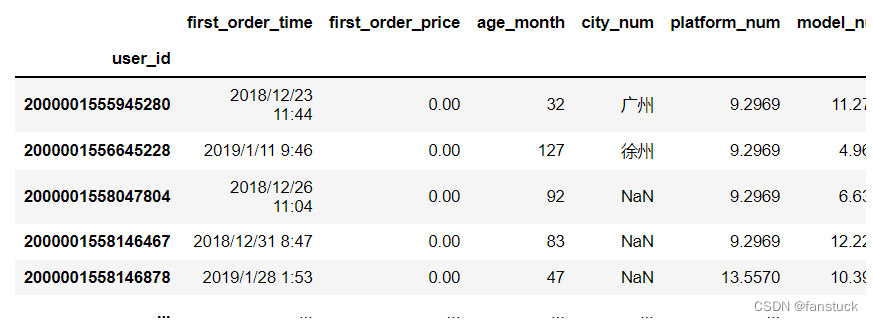
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',index_col=0)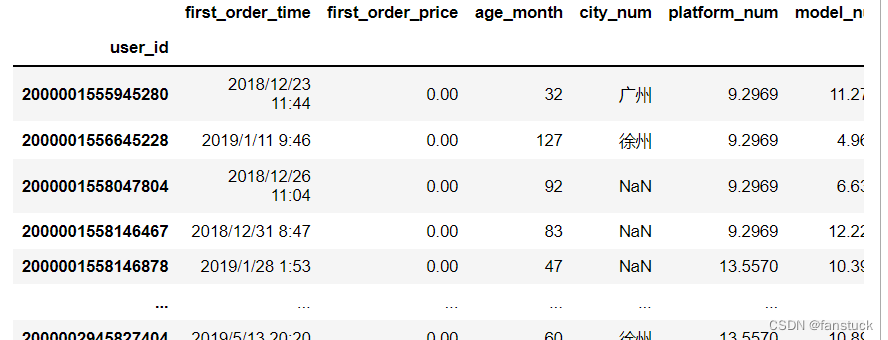
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',index_col=[1,'user_id'])
当index_col为False时,将不指定索引列。
7.usecols
接受类型:{list-like or callable, optional}
返回列的子集。如果为列表形式,则所有元素必须是位置元素(即文档列中的整数索引)或与用户在名称中提供的列名或从文档标题行推断的列名相对应的字符串。如果给定了names参数,则不考虑文档标题行。例如,像usecols参数这样的有效列表应该是[0、1、2]或['foo',bar',baz']。
指定的列表顺序是不给予考虑的,与原csv文件的列原始顺序一样,因此usecols=[0,1]与[1,0]相同。如果可调用,将根据列名计算可调用函数,返回可调用函数计算为True的名称。有效的可调用参数的一个示例是['AAA','BBB','DDD'中的lambda x:x.upper()。使用此参数可以加快解析时间并降低内存使用率。
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',usecols=['age_month'])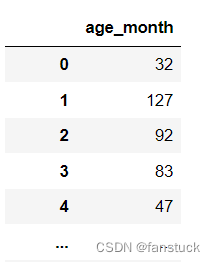
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',usecols=[0,2])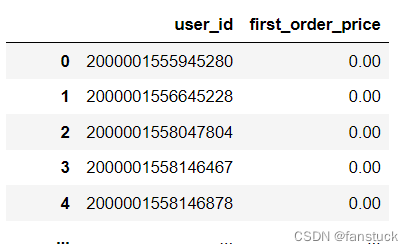
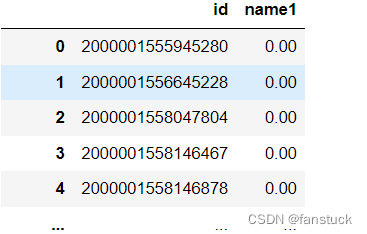
- df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',
- header=0,
- names=['id','time','name1','name2','name3','name4','name5','name6'],
- usecols=['id','name1'])
- df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',
- usecols=['age_month','first_order_time'])
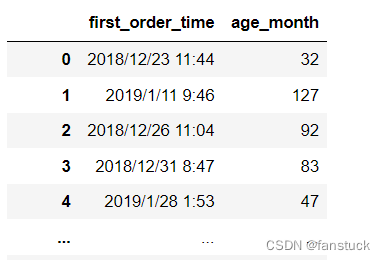
可见给定的列表但生成的DataFrame的顺序是不会根据给的列表顺序改变的。
8.squeeze
接受类型:{bool, default False}
如果解析的数据只包含一列,则返回一个序列。
df_csv=pd.read_csv('user_info.csv',usecols=['age_month'],squeeze=True)
9.prefix
接受类型:{str, optional}
无标题时添加到列号的前缀,例如“X”表示X0,X1。
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',header=None,prefix='name')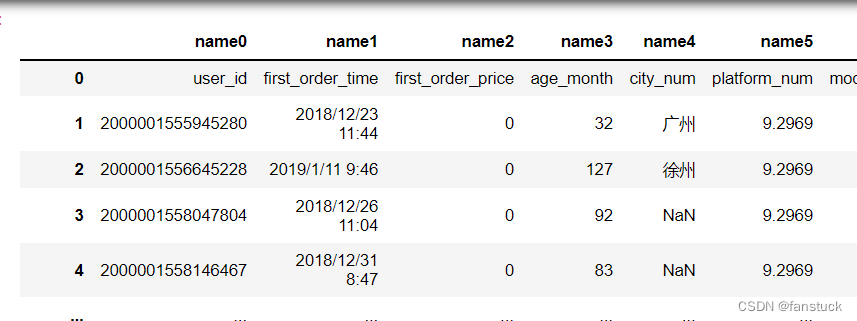
10.mangle_dupe_cols
接受类型:{bool, default True}
重复列将指定为“X”、“X.1”、“X.N”,而不是“X”…“X”。如果列中有重复的名称,传入False将导致数据被覆盖。
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',header=0,names=['id','time','name1','name2','name3','name4','name5','name6'],mangle_dupe_cols=False)ValueError: Setting mangle_dupe_cols=False is not supported yet
设置为False时现在还不支持。
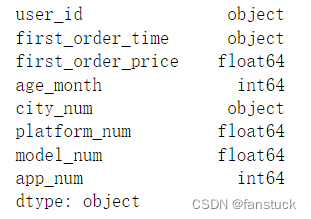
11.dtype
接受类型:{Type name or dict of column -> type, optional}
指定数据或列的数据类型。例如:{‘a’: np.float64, ‘b’: np.int32, ‘c’: ‘Int64’} 。
将str或object与适当的na_values设置一起使用,以保留而不是解释数据类型。如果指定了转换器,则将应用INSTEAD而不是数据类型转换。
- df_csv=pd.read_csv('user_info.csv')
- df_csv.dtypes

- df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',dtype={'user_id':'str'})
- df_csv.dtypes
12.engine
接受类型:{‘c’, ‘python’, ‘pyarrow’}
指定要使用的解析器引擎。C和pyarrow引擎的速度更快,而python引擎目前的功能更加完整。多线程目前仅由pyarrow引擎支持。
- time_start=time.time()
- df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',engine='python')
- time_end=time.time()
- print('time cost',time_end-time_start,'s')
time cost 1.0299623012542725 s
- time_start=time.time()
- df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',engine='c')
- time_end=time.time()
- print('time cost',time_end-time_start,'s')
time cost 0.20297026634216309 s
13.converters
接受类型:{dict, optional}
用于转换某些列中的值的函数的功能。键可以是整数或列标签。
df_csv=pd.read_csv(r'C:\Users\10799\test-python\user_info.csv',converters={'city_num':lambda x:x})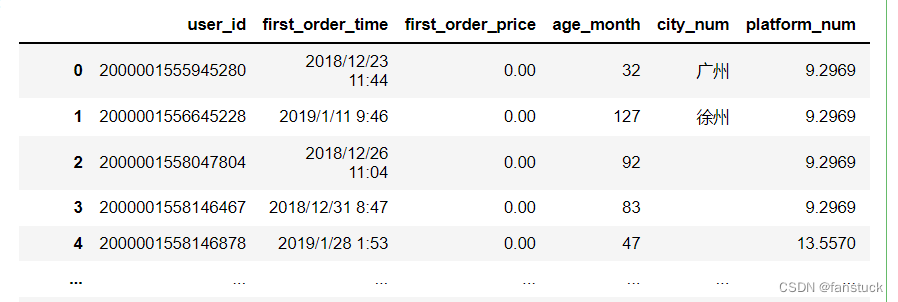
14.true_values
接受类型:{list, optional}
指定列表要视为真,当读出的csv太多时该参数会有BUG,读不出来:
df_csv=pd.read_csv('user_info.csv',true_values=['广州'])这个广州没变,我也试了试很多值也没用,估计内部参数逻辑不适用大含量的csv数据。

跑个简单的就行:
- from io import StringIO
- data = ('a,b,c\n1,Yes,2\n3,No,4')
- pd.read_csv(StringIO(data),
- true_values=['Yes'], false_values=['No'])

不推荐大家使用该参数来调TRUE,自己写个lambda函数或者replace是一样的,这个作用于全局会出问题。只有当某一列的数据全部出现在true_values + false_values里面,才会被替换。
15.false_values
接受类型:{list, optional}
指定列表要视为假。和上个参数一样,属于无用参数,坑人、跳过。只有当某一列的数据全部出现在true_values + false_values里面,才会被替换。
16.skipinitialspace
接受类型:{bool, default False}
跳过分隔符后的空格。
df_csv=pd.read_csv('user_info.csv',skipinitialspace=True)没啥区别:

17. skiprows
接受类型:{list-like,int或callable,可选}
指定文件开头要跳过的行号(0初始索引)或要跳过的行数(int)。
如果可调用,将根据行索引计算可调用函数,如果应跳过该行,则返回True,否则返回False。有效的可调用参数的一个示例是[0,2]中的lambda x:x。df_csv=pd.read_csv('user_info.csv',skiprows=[0,1,2,3])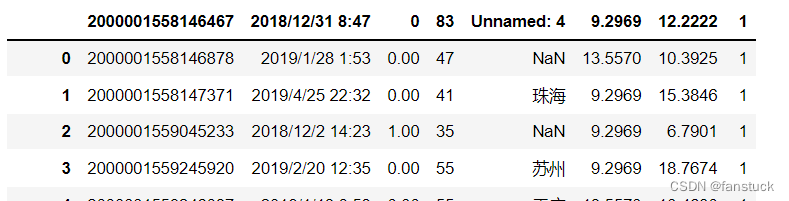
例如选择行为偶数的行:
df_csv=pd.read_csv('user_info.csv',skiprows=lambda x :x%2==0) 18.skipfooter
18.skipfooter接受类型:{int, default 0}
指定 要跳过的文件底部的行数(engine='c'不支持)。
df_csv=pd.read_csv('user_info.csv',skipfooter=1)跳过底部指定数目的行:

19.nrows
接受类型:{int, optional}
指定要读取的文件行数。用于读取大型文件。
df_csv=pd.read_csv('user_info.csv',nrows=50)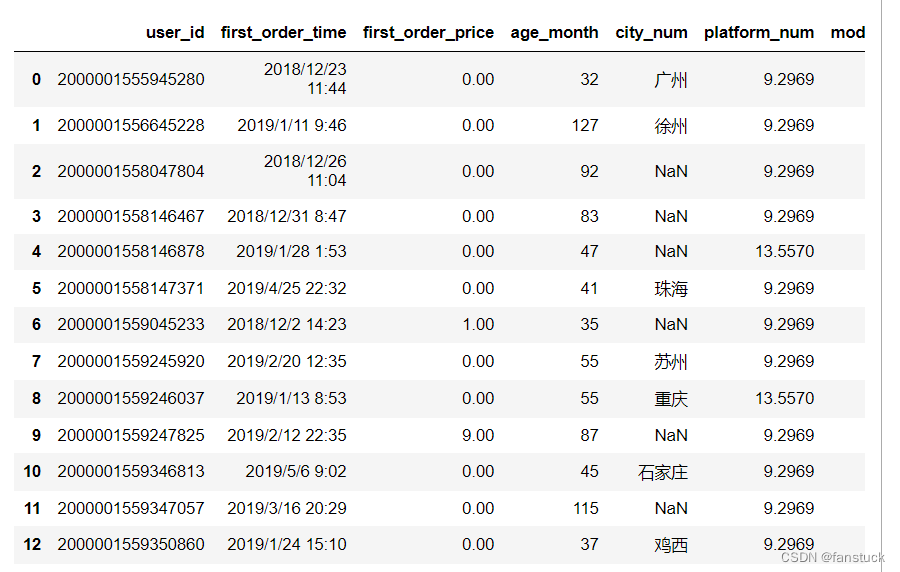
20.na_values
接受类型:{scalar, str, list-like, or dict, optional}
要识别为NA/NaN的其他字符串。如果dict通过,则指定每列NA值。默认情况下,以下值被解释为 NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘<NA>’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’.
df_csv=pd.read_csv('user_info.csv',na_values='0')
df_csv=pd.read_csv('user_info.csv',na_values=['0','32'])
21.keep_default_na
接受类型:{bool, default True}
解析数据时是否包括默认的NaN值。根据是否传入na_values,行为如下:
- 如果keep_default_na为True,并且指定了na_value,则将na_value附加到用于解析的默认NaN值。
- 如果keep_default_na为True,并且未指定na_value,则仅使用默认的NaN值进行解析。
- 如果keep_default_na为False,并且指定了na_value,则仅使用指定的NaN值na_value进行解析。
- 如果keep_default_na为False,并且未指定na_value,则不会将任何字符串解析为NaN。
注意,如果na_filter作为False传入,keep_default_na和na_values参数将被忽略。
df_csv=pd.read_csv('user_info.csv',keep_default_na=False)
22. na_filter
接受类型:{bool, default True}
检测缺失的值标记(空字符串和na_values的值)。在没有任何NAs的数据中,传递na_filter=False可以提高读取大型文件的性能。
这个参数用于调优,由于存储数据很多都存在空值,所以默认为True合适。
23.verbose
接受类型:{bool, default False}
打印各种解析器的输出信息,可指示放置在非数字列中的NA值的数量。
df_csv=pd.read_csv('user_info.csv',verbose=True)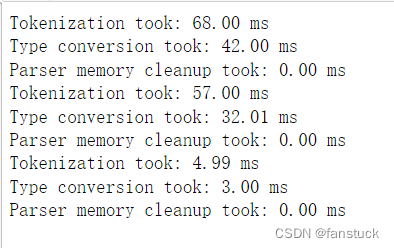
24.skip_blank_lines
接受类型:{bool, default True}
如果为True,则跳过空行,而不是解释为NaN值。否则则为NaN
df_csv=pd.read_csv('user_info.csv',skip_blank_lines=False)
25.parse_dates
接受类型:{bool or list of int or names or list of lists or dict, default False}
参数选择功能如下:
- bool:如果为True则分析索引。
- ist of int or names:例如:如果[1、2、3]则尝试将列1、2、3分别解析为单独的日期列。
- list of lists.例如:如果为[[1,3]]则组合第1列和第3列,并解析为单个日期列。
- dict,例如{'foo':[1,3]},则将列1,3解析为日期并调用结果“foo”。
如果一个列或索引不能表示为datetimes数组,例如由于不可分析的值或时区的混合,那么该列或索引将作为对象数据类型原封不动地返回。对于非标准的datetime解析,pd.read_csv之后的处理使用to_datetime。要解析混合时区的索引或列,请将date_parser指定为部分应用的pandas.to_datetime()使用utc=True。有关更多信息,请参阅使用混合时区解析CSV:https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html#io-csv-mixed-timezones。
注意:存在iso8601格式日期的快速路径。df_csv=pd.read_csv('user_info.csv',parse_dates=['first_order_time'])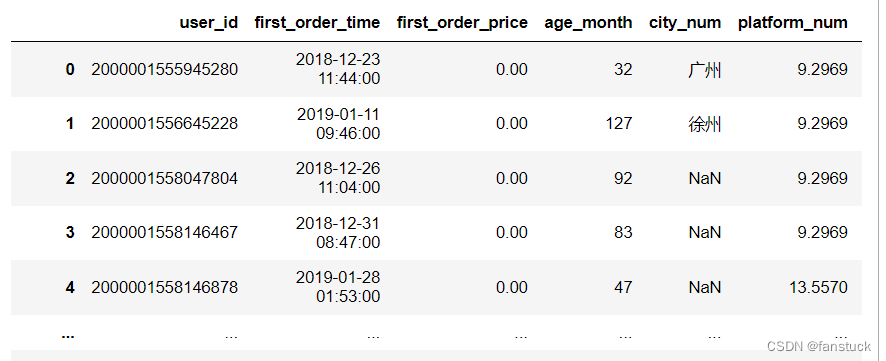
df_csv.dtypes
- df_csv=pd.read_csv('user_info.csv',parse_dates=[1])
- df_csv.dtypes

26.infer_datetime_format
接受类型:{bool, default False}
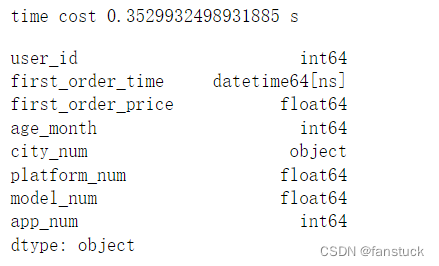
如果启用了True和parse_dates,pandas将尝试推断列中datetime字符串的格式,如果可以推断,则切换到更快的解析方法。在某些情况下,这可以将解析速度提高5-10倍。
- time_start=time.time()
- df_csv=pd.read_csv('user_info.csv',parse_dates=[1])
- time_end=time.time()
- print('time cost',time_end-time_start,'s')
- df_csv.dtypes
- time_start=time.time()
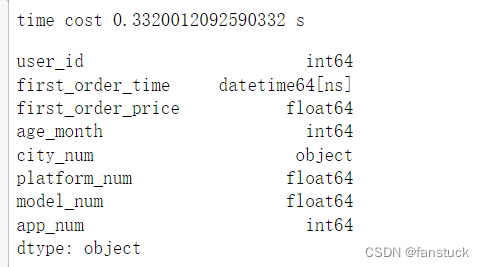
- df_csv=pd.read_csv('user_info.csv',parse_dates=[1],infer_datetime_format='%Y/%m/%d %H:%M')
- time_end=time.time()
- print('time cost',time_end-time_start,'s')
- df_csv
27.keep_date_col
接受类型:{bool, default False}
如果True和parse_dates指定组合多个列,则保留原始列。
因为如果多个列是指定不同时间单位的时间时,合并之后是不会有原来的列的,指定keep_date_col为True时,它们就会保留下来。
- from io import StringIO
- data = ('year,month,day\n2022,6,21\n2022,6,22\n2022,6,23')
- pd.read_csv(StringIO(data),parse_dates=[[0,1,2]]
- )
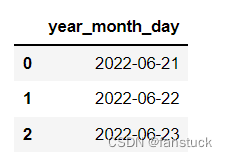
- from io import StringIO
- data = ('year,month,day\n2022,6,21\n2022,6,22\n2022,6,23')
- pd.read_csv(StringIO(data),parse_dates=[[0,1,2]],keep_date_col=True
- )
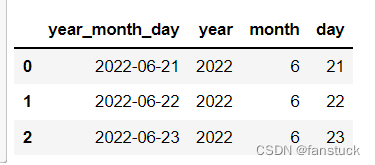
28.date_parser
接受类型:{function, optional}
指定函数,用于将字符串列序列转换为datetime实例数组。默认使用
dateutil.parser.parser来进行转换。Pandas将尝试以三种不同的方式调用date_parser,如果发生异常,则会前进到下一种方式:1)传递一个或多个数组(由parse_dates定义)作为参数;2) 将parse_dates定义的列中的字符串值串联(按行)到一个数组中,并传递该数组;和3)使用一个或多个字符串(对应于parse_dates定义的列)作为参数,为每一行调用一次parse_dates。一般来说会用在以及read_csv转换为DataFrame之后,处理datetime之后写函数,但是有了这个参数前期写完自定义函数之后就可以直接处理带时间的参数的值了。
- from io import StringIO
- from datetime import datetime
- def dele_date(dateframe):
- for x in dateframe:
- x=pd.to_datetime(x,format='%Y/%m/%d %H:%M')
- x.strftime('%m/%d/%Y')
- return x
- df_csv=pd.read_csv('user_info.csv',parse_dates=['first_order_time'],date_parser=dele_date)
- df_csv
29. dayfirst
接受类型:{bool, default False}
日/月格式日期,国际和欧洲格式。
- df_csv=pd.read_csv('user_info.csv',parse_dates=['first_order_time'],dayfirst=True)
- df_csv

没啥作用,该是什么形式还是什么形式,除非是DD/MM格式才有用,用处不大。
30.cache_dates
接受类型:{bool, default True}
如果为True,请使用唯一的已转换日期缓存来应用日期时间转换。在分析重复的日期字符串时,尤其是带有时区偏移的日期字符串时,可能会产生显著的加速。
优化参数,提速。
31.iterator
接受类型:{bool, default False}
返回TextFileReader对象以进行迭代或获取块get_chunk().
- df_csv=pd.read_csv('user_info.csv',iterator=True)
- print(df_csv)
<pandas.io.parsers.readers.TextFileReader object at 0x000002624BBA5848>
32.chunksize
接受类型:{int, optional}
返回用于迭代的TextFileReader对象。有关
iterator和chunksize的更多信息,请参阅IO工具文档。功能性函数,指定转化为TextFileReader的块数。
33.compression
接受类型:{str or dict, default ‘infer’}
用于实时解压缩磁盘数据。如果“infer”和“%s”类似于路径,则从以下扩展检测压缩:'。gz','。bz2’,”。zip“,”。xz’,或’。zst’(否则无压缩)。如果使用“zip”,zip文件必须只包含一个要读入的数据文件。设置为“None”表示无解压缩。也可以是一个dict,其中键“method”设置为{'zip',gzip',bz2',zstd}之一,其他键值对被转发到zipfile。ZipFile,gzip。gzip文件,bz2。BZ2文件或zstandard。ZstdDecompressor。例如,可以使用自定义压缩字典为Zstandard解压缩传递以下内容:compression={'method':'zstd','dict_data':my_compression_dict}。
- df_csv=pd.read_csv('user_info.csv',compression=None)
- df_csv

34.thousands
接受类型:{str, optional}
千位分隔符。
35.decimal
接受类型:{str, default ‘.’}
要识别为小数点的字符(例如,对于欧洲数据使用“,”。)
一般为float的数据都为小数点,我感觉这个参数可能加密的时候有点用。
36.lineterminator
接受类型:{str (length 1), optional}
字符将文件拆分为行。仅对C解析器有效。设置为engine为C:
- df_csv=pd.read_csv('user_info.csv',engine='c',lineterminator='2')
- df_csv
37.quotechar
接受类型:{str (length 1), optional}
用于表示引用项的开始和结束的字符。带引号的项目可以包含分隔符,它将被忽略。
38.quoting
接受类型:{int or csv.QUOTE_* instance, default 0}
- df_csv=pd.read_csv('user_info.csv',quotechar = '"')
- df_csv
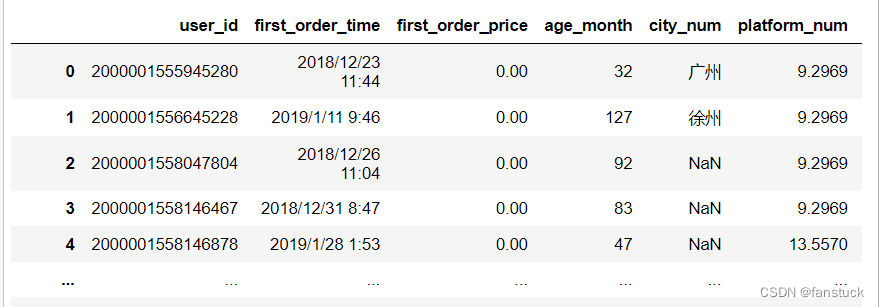
每个csv的控制字段引用行为。QUOTE_*常量。使用QUOTE\u MINIMAL(0)、QUOTE\u ALL(1)、QUOTE_NONNERIAL(2)或QUOTE_NONE(3)之一。
感觉到了后面的参数是临时加上去的,平常业务需求很难用得上。
39.doublequote
接受类型:{bool, default
True}如果指定了quotechar且Quoteching不是QUOTE_NONE,请指示是否将字段内的两个连续quotechar元素解释为单个quotechar元素。
- df_csv=pd.read_csv('user_info.csv',quotechar='"', doublequote=True)
- df_csv
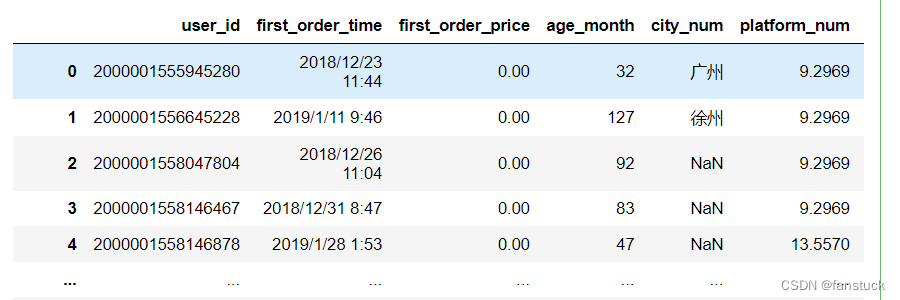
40.escapechar
接受类型:{str (length 1), optional}
用于转义其他字符的字符串。当quoting 为QUOTE_NONE时,指定一个字符使的不受分隔符限值。
41.comment
接受类型:{str, optional}
指示不应分析行的其余部分。如果在一行的开头找到,该行将被完全忽略。此参数必须是单个字符。与空行一样(只要skip_blank_lines=True),完全注释的行将被参数头忽略,而不是被skiprows忽略。例如,如果注释=“#”,分析标题为0的#empty\na、b、c\n1、2、3将导致“a、b、c”被视为标题。
- df_csv=pd.read_csv('user_info.csv',sep=',', comment='#', skiprows=1)
- df_csv

42.encoding
接受类型:{str, optional}
读/写时用于UTF的编码(例如“UTF-8”)。
43.encoding_errors
接受类型:{str, optional, default “strict”}
处理编码错误。
44.dialect
接受类型:{str or csv.Dialect, optional}
如果提供,此参数将覆盖以下参数的值(默认值或非默认值):delimiter、doublequote、escapechar、skipinitialspace、quotechar和quoting。如果需要重写值,将发出ParserWarning。请参见csv。如果没有指定特定的语言,如果sep大于一个字符则忽略。方言文档了解更多详细信息。
45. error_bad_lines
接受类型:{bool, optional, default
None}默认情况下,字段过多的行(例如,逗号过多的csv行)将引发异常,并且不会返回DataFrame。如果为False,则将从返回的数据帧中删除这些“错误行”。这是比较好用来处理错误的数据的:
46.warn_bad_lines
接受类型:{bool, optional, default
None}如果error_bad_lines为False,warn_bad_lines为True,则会输出每个“bad line”的警告。
47.on_bad_lines
接受类型:{{‘error’, ‘warn’, ‘skip’} or callable, default ‘error’}
指定遇到错误行(字段太多的行)时要执行的操作。允许的值为:
- “error”,遇到错误行时引发异常。
- “警告”,遇到错误行时发出警告并跳过该行。
- “跳过”,在遇到错误行时跳过错误行而不引发或警告。
- df_csv=pd.read_csv('http://localhost:8889/edit/test-python/user_info.csv',sep=',',on_bad_lines='skip')
- df_csv

48.delim_whitespace
接受类型:{bool, default False}
指定是否将空格(例如“.”或“”)用作sep。相当于设置sep=“\s+”。如果此选项设置为True,则不应为delimiter参数传入任何内容。
- df_csv=pd.read_csv('user_info.csv',delim_whitespace=True)
- df_csv
这里是时间里面有个空格导致全部分开。设置sep=“\s+”是一样的。
49.low_memory
接受类型:{bool, default True}
在内部以块的形式处理文件,从而在解析时减少内存使用,但可能是混合类型推断。要确保没有混合类型,请设置False,或使用dtype参数指定类型。请注意,整个文件都被读取到单个数据帧中,不管如何,请使用chunksize或iterator参数以块的形式返回数据。(仅对C解析器有效)。
50.memory_map
接受类型:{bool, default False}
如果为filepath_or_buffer提供了filepath,请将文件对象直接映射到内存,并从内存直接访问数据。使用此选项可以提高性能,因为不再存在任何I/O开销。
51.float_precision
接受类型:{str, optional}
指定C引擎应将哪个转换器用于浮点值。普通转换器的选项为无或“高”,原始低精度熊猫转换器的选项为“传统”,往返转换器的选项为“往返”。
52.storage_options
对特定存储连接有意义的额外选项,例如主机、端口、用户名、密码等。对于HTTP(S)URL,键值对作为标头选项转发给urllib。对于其他URL(例如,以“s3://”和“gcs://”)开头),将键值对转发给fsspec。有关更多详细信息,请参阅fsspec和urllib。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
-
相关阅读:
华大基因肿瘤检测助力早期癌症筛查,提高癌症患者生存率
基于JavaScript的Web端股票价格查看器——大道
SpringBoot
升级到 jQuery 3.6.1 遇见的几个坑以及应对方法
将十进制转化成其他进制‘支持2-16进制(C语言)昨天码完忘发了,呜呜呜
动视是否磨灭了暴雪的灵魂?
数据安全常用术语表 V0.1 附下载地址
数据结构之顺序表习题讲解
轻松理解 Transformers(1):Input部分
ts json的中boolean布尔值或者int数字都是字符串,转成对象对应类型
- 原文地址:https://blog.csdn.net/master_hunter/article/details/125412791