-
视觉Transformer中的位置编码方式
绝对位置编码
基本形式:x = x + p
可学习的绝对位置编码(ViT)
ViT中提出的位置编码方式简单粗暴,设置一组可学习的编码tokens,并在patch embeding后逐元素相加,在训练阶段一起训练。这种方式的不足是序列化长度固定了,在遇到较大分辨率图像时可以对学习好的positional embedding进行插值然后对模型进行fine-tune。

条件位置编码(CPVT)
本文针对上述问题,提出了一种利用卷积核自适应地根据输入图片的tokens长度生成positional embedding的方法。同时文章也研究了位置编码放置的位置和不同layer之间是否共享位置编码对模型性能的影响。

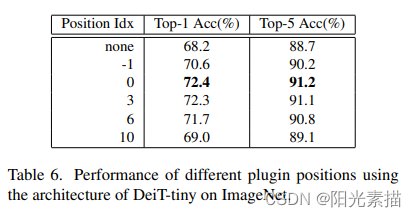


其他方法
如,从BETR-3中借鉴过来的正余弦位置编码方式。
相对位置编码
基本形式:

Shaw’s RPE
在一定距离范围内,设置可学习的位置嵌入对

RPE in Transformer-XL.
u和v是两个可学习的向量,s是正弦先验偏置项,用于引入先验位置信息。
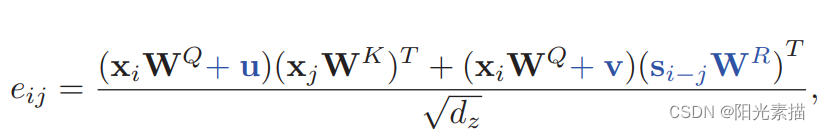
Huang’s RPE
query和key共享编码向量,同时考虑了query和key的交互以及正弦先验位置信息。

image Relative Positional Embedding paper report
本文深入研究了相对位置编码中的上下文关系、编码的方向性、编码共享、截断函数的影响,还比较了绝对编码与相对编码混合使用的效果。
首先,作者使用了统一的形式来表示偏置编码和上下文编码。

然后,作者设计了欧氏距离、量化、十字交叉和乘积四种形式的r,分别对应了无、有相对方向的考虑。

例如,对于上图这种十字交叉的r形式,分别计算了相对位置在x和y上的距离,并通过分段函数进行索引映射,从而找到可学习的位置嵌入向量p,并加和得到最终的r。 -
相关阅读:
单级高频谐振小放
opencv入门建议
对称二叉树(C++)
10.0 SpringMVC源码分析之MVC 模型由来
计算机设计大赛 疲劳驾驶检测系统 python
Android开发——Fragment
6.3 - 常见协议及对应的端口号
Spring数据库数据源JDBC连接池连接MySQL的超时问题
R语言探索 BRFSS 数据和预测
springboot的web开发
- 原文地址:https://blog.csdn.net/qq_38681990/article/details/125430963