-
大数据1星笔试题_220621


下面哪个程序负责hdfs数据存储?


13,block size 是不可以修改的

14,如果NameNode意外终止,SecondaryNameNode会接替它使集群继续工作


15,hadoop支持数据的随机读写?
随机写
hdfs的文件操作: 只支持一次写入,多次读取,不支持行级别的CRUD,但是从hadoop 2.X开始,支持追加操作


NameNode负责管理metadata,client端每次读写请求,他都会从磁盘中读取或者会写入metadata信息并反馈client端??
NameNode 不需要从磁盘读取 metadata,所有数据都在内存中,硬盘上的只是序列化的结果,只有每次 namenode 启动的时候才会读取。
NameNode本地磁盘保存了Block的位置信息??




slave节点要存储数据,所以它的磁盘越大越好?


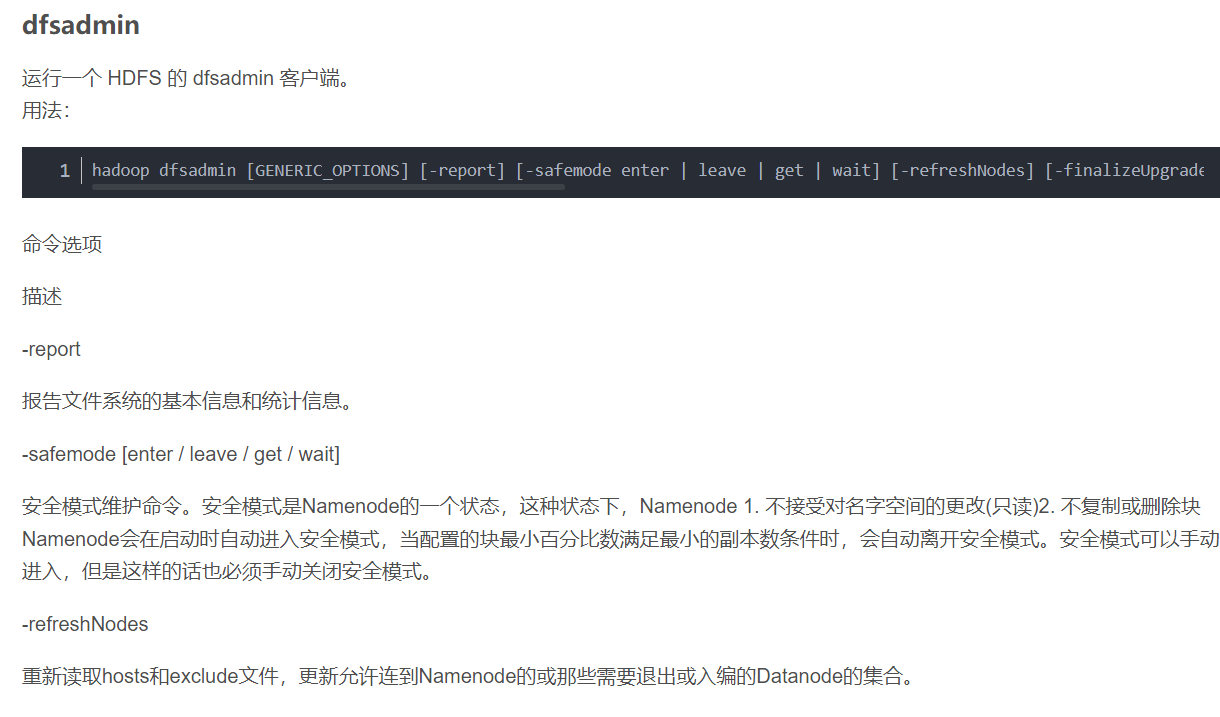
hadoop dfsadmin -report 命令用于监测hdfs损坏块?

因为hdfs有多个副本,所以Namenode是不存在单点问题的?


hadoop环境变量中的hadoop_heapsize用于设置所有hadoop守护线程的内容。他的默认是200GB?


hdfs在hadoop生态系统的作用有哪些?
1,HDFS的物理结构设计为主/从模式。物理集群由一个NameNode(负责管理文件系统命名空间,并控制客户端对文件的访问)以及许多数据节点DataNode组成。数据节点通常是每个物理节点一个,用于管理它们所运行节点的存储。在内部,文件被分成一个或多个块,这些块存储在一组DataNode中。
NameNode执行与文件系统命名空间相关的操作,例如打开,关闭和重命名文件和目录。它还负责存储集群元数据,并记录数据块到DataNode的映射。
DataNode负责处理来自文件系统客户端的读写请求,还会执行块的创建,删除操作,注意:单个的NameNode是专门为简化系统体系设计,仅负责命名空间等控制性操作,且用户数据不会流向NameNode。
2,
文件系统命名空间
HDFS支持传统的分级文件模式。用户或应用程序可以创建目录并将文件存储在这些目录中。
文件系统名称空间层次结构与大多数其他现有文件系统类似;可以创建和删除文件,将文件从一个目录移动到另一个目录或重命名文件。
HDFS支持配额(允许管理员为使用的名称数和用于单个目录的空间量设置配额)和文件权限控制
HDFS不支持硬链接或软链接(但是,HDFS并不排除实现这些功能)
NameNode维护文件系统的命名空间,对文件系统名称空间或其属性的任何更改都由NameNode记录,应用程序可以指定HDFS应该维护的文件副本的数量。文件的副本数称为该文件的复制因子,此信息由NameNode存储。
3,
数据复制
HDFS旨在大型集群中的计算机之间可靠地存储非常大的文件,它将每个文件存储为一系列块(即Block),该设计是为了容错,块大小和复制因子是每个文件可配置的。文件中除最后一个块外的所有块都具有相同的大小,而在添加了对可变长度块的支持后,用户可以在不填充最后一个块的情况下开始新的块,而不用配置的块大小。
应用程序可以指定文件的副本数。复制因子可以在文件创建时指定,以后可以更改。
HDFS中的文件只能写入一次(追加和截断除外),并且在任何时候都只能具有一个写入器,NameNode做出有关块复制的所有决定。它定期从群集中的每个DataNode接收心跳信号和Blockreport。收到心跳信号表示DataNode正常运行。Blockreport包含DataNode上所有块的列表。

hive能否直接读取hdfs,HBASE中的数据,如果能,请提供读取的示例方法?
第一步:创建文件夹写结构化数据。然后上传到hdfs
第二步:根据结构化数据在HIVE中创建对应的表
create table tb_log(
id int,
name string,
age int ,
gender string
)
//指定数据以什么分割
row format delimited fields terminated by ‘,’
//指定存在hdfs中数据的位置
location ‘hdfs://linux01:8020/data/log/’;
//在hive中用SQL语言操作数据求各性别平均年龄
select
gender,
avg(age) as avg_age
from
tb_log
group by gender;24的HBASE读取部分未完成??
未完成:::::::(部分未学??)
暂时看到,判断题1题,
-
相关阅读:
OSS专栏------文件上传(一)
全国职业技能大赛云计算--高职组赛题卷⑤(容器云)
用GPT干的18件事,能够真正提高学习生产力,建议收藏
ElasticSearch在Windows上的下载与安装
产品经理的工作职责是什么?
synchronized 与 spring事务 @Transactional 的介绍使用
基于jsp+ssm的新生入学报道系统-计算机毕业设计
Python Argparse 库讲解特别好的
HMM与LTP词性标注之命名实体识别与HMM
解决Nginx unknown directive “stream”问题
- 原文地址:https://blog.csdn.net/m0_48941160/article/details/125399635