-
caffeine与guava cache
1.Caffeine 对比 Guava cache

Caffeine在读写上都明显优于Guava cache,主要是因为2个原因, 淘汰策略 W-TinyLRU 和 Ringbuffer队列.
package Demo; import com.github.benmanes.caffeine.cache.*; import org.jetbrains.annotations.NotNull; import java.util.Map; import java.util.concurrent.CompletableFuture; import java.util.concurrent.Executor; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit; /** * @author fangpengx.zhou * @Date 2021/5/28 15:59 */ public class CaffeineDemo { private LoadingCache<String, String> caffeine = Caffeine.newBuilder() //自定义时间计时器 .expireAfter(new Expiry<String, String>() { @Override public long expireAfterCreate(String key, String value, long currentTime) { return 0; } @Override public long expireAfterUpdate(String key, String value, long currentTime, long currentDuration) { return 0; } @Override public long expireAfterRead(String key, String value, long currentTime, long currentDuration) { return 0; } }) //上次写入后开始计时 .expireAfterWrite(10, TimeUnit.SECONDS) //上次访问后开始计时(读写) .expireAfterAccess(10, TimeUnit.SECONDS) //写入后就会刷新新值(expireAfterWrite 同步, refreshAfterWriter 异步(返回旧值)) .refreshAfterWrite(10, TimeUnit.SECONDS) //最大大小 .maximumSize(2) //key 弱引用 -> 内存溢出前回收 .weakKeys() //value 弱引用 -> 内存溢出前回收 .weakValues() //软引用 -> 下次GC时回收 .softValues() .build(new CacheLoader<String, String>() { //同步填充 @Override public String load(@NotNull String key) throws Exception { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return "load" + key; } //批量填充 @NotNull @Override public Map<String, String> loadAll(@NotNull Iterable<? extends String> keys) throws Exception { return null; } //重新加载 @Override public String reload(@NotNull String key, @NotNull String oldValue) throws Exception { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return "reload" + key; } }); private AsyncLoadingCache<String, String> asyncCaffeine = Caffeine.newBuilder() .executor(Executors.newSingleThreadExecutor()) .buildAsync(new AsyncCacheLoader<String, String>() { @NotNull @Override public CompletableFuture<String> asyncLoad(@NotNull String key, @NotNull Executor executor) { return CompletableFuture.supplyAsync(() -> { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return "asyncLoad" + key; }); } @NotNull @Override public CompletableFuture<String> asyncReload(@NotNull String key, @NotNull String oldValue, @NotNull Executor executor) { return CompletableFuture.supplyAsync(() -> { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return "asyncReload" + key; }); } }); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
2.W-TinyLRU
2.1主流的淘汰策略
FIFO 先进先出, 队列的形式,淘汰最先进入的缓冲数据,命中率较低
LFU 最近最少未使用, 数据放入队尾,直接淘汰队首的数据即可,但是如果一个热点数据在短时间内没有访问就会导致被淘汰.
LRU 最近最少频率, 对数据进行了访问频率的计算,通过每个数据的频率进行淘汰,这样也避免了LFU的问题.但是LRU也有局限性的,不能随着时间的变化而变化,如果一个热点数据突然不热点了,那这个数据在一段时间内都不能被淘汰出去.
淘汰策略的命中率 FIFO<LFU<LRU,但是对于的成本也是FIFO<LFU<LRU.
2.2淘汰策略问题
LRU需要记录每一个数据的访问频率,就算数据没有在缓存中也需要记录,这就是一个很大开销
LRU不能随着时间做出改变的
2.3解决方案
2.3.1 Count-Min Sketch:针对开销较大布隆过滤器:
布隆过滤器通常用于大量数据的匹配(黑名单,白名单),缓存穿透等.用更小的空间实现匹配功能,但是不可避免的会有误差,并且对于删除值不友好.
布隆过滤器通过计算n个hash,并在对应的点进行描黑操作. 查询时也计算对应hash并判断点是否全未黑.
count-min sketch:
count-min sketchs是Bloom Filter(布隆过滤器)的一个变种,key通过n个hash计算定位在对应的位置,取值时在多个位置中取值最低的值.
count-min sketchs使用long型数组,一个long占64位,而存储频率最高为15,转换为二进制为1111.数组一位可以放16种算法,但是sketchs只放了4种hash算法,并分成了4份.这样数据存储128字节就可以存储128*4个数据.
频率最高只能存15,值较小.所以sketch在有值到达了15时会将所有值除2,除2后,继续增加

2.3.2 LRU+LFU结合: 保证时间变化
Eden队列:在caffeine中规定只能为缓存容量的1%,如果size=100,那这个队列的有效大小就等于1。这个队列中记录的是新到的数据,防止突发流量由于之前没有访问频率,而导致被淘汰,eden区,最舒服最安逸的区域,在这里很难被其他数据淘汰。
Probation队列:叫做缓刑队列,在这个队列就代表你的数据相对比较冷,马上就要被淘汰了。这个有效大小为size减去eden减去protected。
Protected队列:在这个队列中,可以稍微放心一下了,你暂时不会被淘汰,但是别急,如果Probation队列没有数据了或者Protected数据满了,你也将会被面临淘汰的尴尬局面。当然想要变成这个队列,需要把Probation访问一次之后,就会提升为Protected队列。这个有效大小为(size减去eden) * 80% 如果size =100,就会是79。

所有的新数据都会进入Eden。
Eden满了,淘汰进入Probation。
如果在Probation中访问了其中某个数据,则这个数据升级为Protected。
如果Protected满了又会继续降级为Probation。
队列已满的情况下,会在probation队首选出一个元素(LRU)作为受害者,受害者不会直接淘汰会于攻击者进行pk,攻击者选择队尾的元素.然后在从攻击者和受害者中淘汰一个.通过我们的Count-Min Sketch中的记录的频率数据有以下几个判断:
如果攻击者大于受害者,那么受害者就直接被淘汰。
如果攻击者<=5,那么直接淘汰攻击者。这个逻辑在他的注释中有解释: 他认为设置一个预热的门槛会让整体命中率更高。
其他情况,随机淘汰。
3.读写效率
读写效率的提升主要原因是, Guava cache在读写操作中会夹杂着其他操作,例如put操作的时候会有过期时间动作.而caffeine在处理其他操作的时候是异步的进行,把任务提交到一个异步的队列中(Ringbuffer).缓存都是读多写少的场景,所以caffeine在写中多个线程使用同一个ringbuffer,而读是在每个线程都分配一个ringbuffer.
3.1RingBuffer
Ringbuffer是一个无锁的环形数组队列主流的队列主要为以下几个特征
有界,无界,
加锁,无锁,
链表,数组,堆
在性能上 无锁 > 有锁 , 数组 > 链表. 有界队列必须为有锁… 堆一般使用在带优先级的队列中.Ringbuffer是一个环形的无界队列(long最大值),无锁的实现(CAS),使用数组的方式实现.
消除伪共享, 数组数据结构, 数组是内存连续的能最大的利用cpu的一级二级三级缓存.因为cpu每次加载缓存是以缓存行的方式加载数据,如果数据连续的话一次读取缓存就可以获取多个有效数据, (空间换时间) 并且 可以预先分配好内存,避免垃圾回收
/** * 考虑一般缓存行大小是64字节,一个 long 类型占8字节 */ static long[][] arr; @org.junit.Test public void test3() { //填充arr数组 arr = new long[1024 * 1024][]; for (int i = 0; i < 1024 * 1024; i++) { arr[i] = new long[8]; for (int j = 0; j < 8; j++) { arr[i][j] = 0L; } } long sum = 0L; long marked = System.currentTimeMillis(); //先遍历1024 for (int i = 0; i < 1024 * 1024; i += 1) { //遍历连续的数组 for (int j = 0; j < 8; j++) { sum = arr[i][j]; } } System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms"); marked = System.currentTimeMillis(); for (int i = 0; i < 8; i += 1) { for (int j = 0; j < 1024 * 1024; j++) { sum = arr[j][i]; } } System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms"); } Loop times:15ms Loop times:72ms- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
数组大小为2^n,使用位运算,最高效的利用cpu
无锁设计,每次读写会提前在对应的数组中申请位置,申请成功在进行读写.
相较与链表 不使用尾指针(取多个消费者中最小的值), 不删除数据
多线程读写:
在多线程的情况下,每个线程获取不同的一段数组空间进行操作。这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去即可。读:
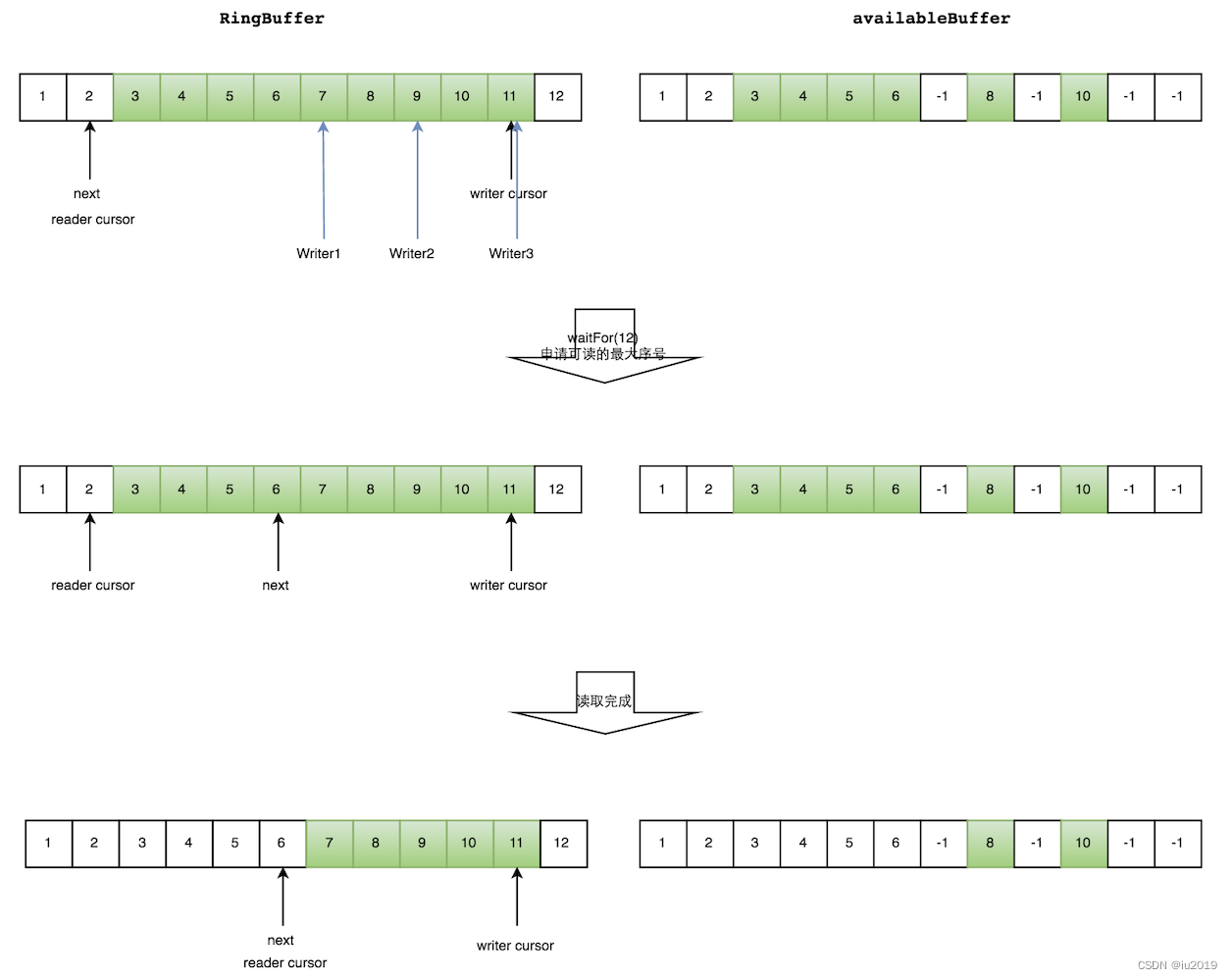
写:
Writer1被分配了下标3到下表5的空间,Writer2被分配了下标6到下标9的空间

Ringbuffer重叠问题:


-
相关阅读:
spark中使用flatmap报错:TypeError: ‘int‘ object is not subscriptable
典型卷积神经网络算法(AlexNet、VGG、GoogLeNet、ResNet)
Redis学习
【无标题】
无涯教程-JavaScript - DDB函数
408王道计算机组成原理强化——存储系统大题
第六章第一节:图的基本概念和存储及基本操作
portswigger JWT attacks
简单易用的操作界面,让你轻松制作电子期刊
【D3.js】1.19-给 D3 元素添加悬停效果
- 原文地址:https://blog.csdn.net/weixin_44464373/article/details/125430333