-
【Java面试】HashMap是如何解决hash冲突的?
Hi,大家好,我是Mic。
今天我们来分享一道工作一年左右的面试题。
最近很多粉丝在面试的时候都遇到了这个问题
问题是:“HashMap是如何解决Hash冲突的”?
很多人觉得这个问题很简单,但是我认为高手的回答会更好一点。
下面看看普通人和高手对这个问题的回答。
需要高手面试文档(附赠阿里内部十万字面试文档)或者有不懂的技术面试题想咨询的小伙伴可以后台私信【Mic】或者评论区留言。
普通人:
HashMap解决hash冲突的方式 我记得是用那个链表的方式用单向链表就说如果承认hash冲突的话,它会把那个存在冲突这样一个键值对啊会保存到那个链表的尾部。
高手:
好的,这个问题我需要从几个方面来回答。
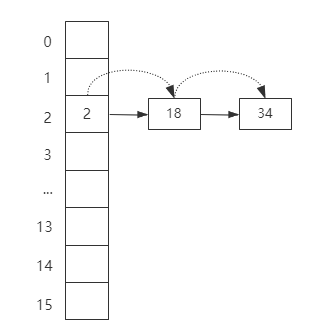
首先,HashMap底层采用了数组的结构来存储数据元素,数组的默认长度是16,当我们通过put方法添加数据的时候,HashMap根据Key的hash值进行取模运算。
最终保存到数组的指定位置。
但是这种设计会存在hash冲突问题,也就是两个不同hash值的key,最终取模后会落到同一个数组下标。
所以HashMap引入了链式寻址法来解决hash冲突问题, 对于存在冲突的key,HashMap把这些key组成一个单向链表。
然后采用尾插法把这个key保存到链表的尾部。
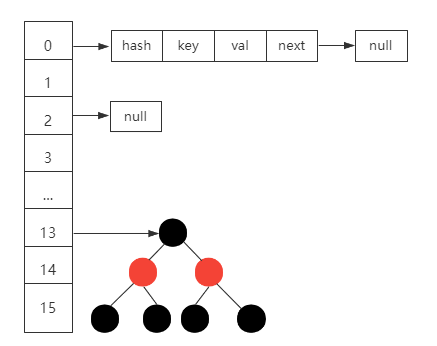
另外,为了避免链表过长的问题,当链表长度大于8并且数组长度大于等于64的时候,
HashMap会把链表转化为红黑树。
从而减少链表数据查询的时间复杂度问题,提升查询性能。
最后,我再补充一下,解决hash冲突问题的方法有很多,比如
-
再hash法,就是如果某个hash函数产生了冲突,再用另外一个hash进行计算,比如布隆过滤器就采用了这种方法。
-
开放寻址法,就是直接从冲突的数组位置往下寻找一个空的数组下标进行数据存储,这个在ThreadLocal里面有使用到。
-
建立公共溢出区,也就是把存在冲突的key统一放在一个公共溢出区里面。
以上就是我对这个问题的理解。
总结
hash冲突这个问题,在业务开发的过程中比较少遇到。
但是从解决方法中,可以学到很多的技术设计思想
不管是为了面试还是为了长期的职业发展,我认为这个技术点都是有必要深度理解的基础知识。
喜欢我的作品的朋友,记得点赞收藏加关注
需要高手面试文档(附赠大厂内部十万字面试文档)或者有不懂的技术面试题想咨询的小伙伴可以扫描下方二维码
↓↓↓↓↓↓↓↓↓↓↓↓↓↓
-
-
相关阅读:
lintcode 1410 · 矩阵注水【BFS 中等 vip】
算法与数据结构-图
ant-design的Select组件采用自定义后缀图标(suffixIcon属性)时,点击该自定义图标没有反应,不会展示下拉菜单的问题
C#中实现按位域操作
Unity 动画知识点
uniapp 微信小程序 uni-file-picker上传图片报错 chooseAndUploadFile
【MyBatis】mybatis工具类迭代
JavaScript 2.0
移动端适配
通过pip,查看tensorflow和tensorflow-probaility版本
- 原文地址:https://blog.csdn.net/q331464542/article/details/125430674