-
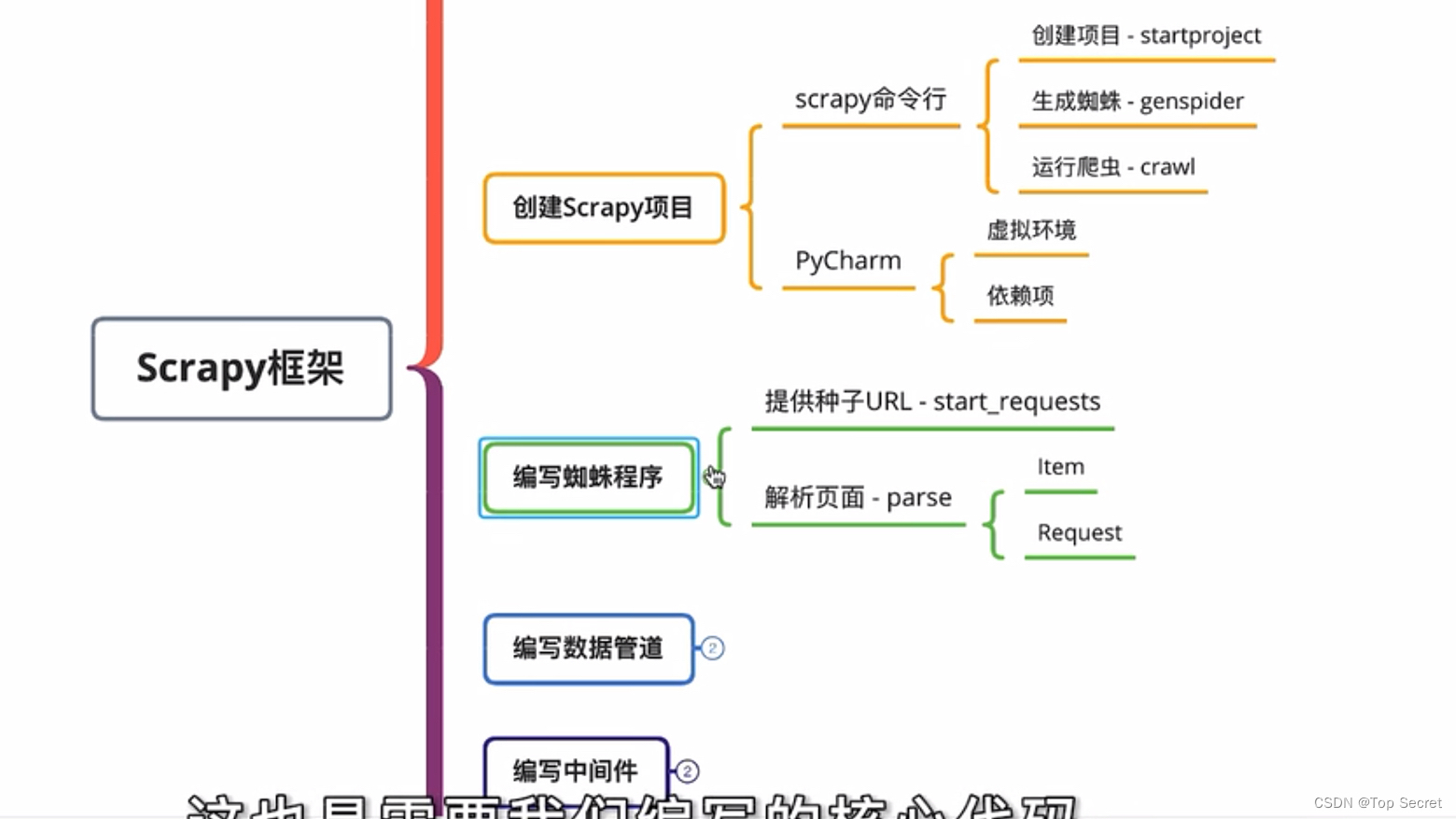
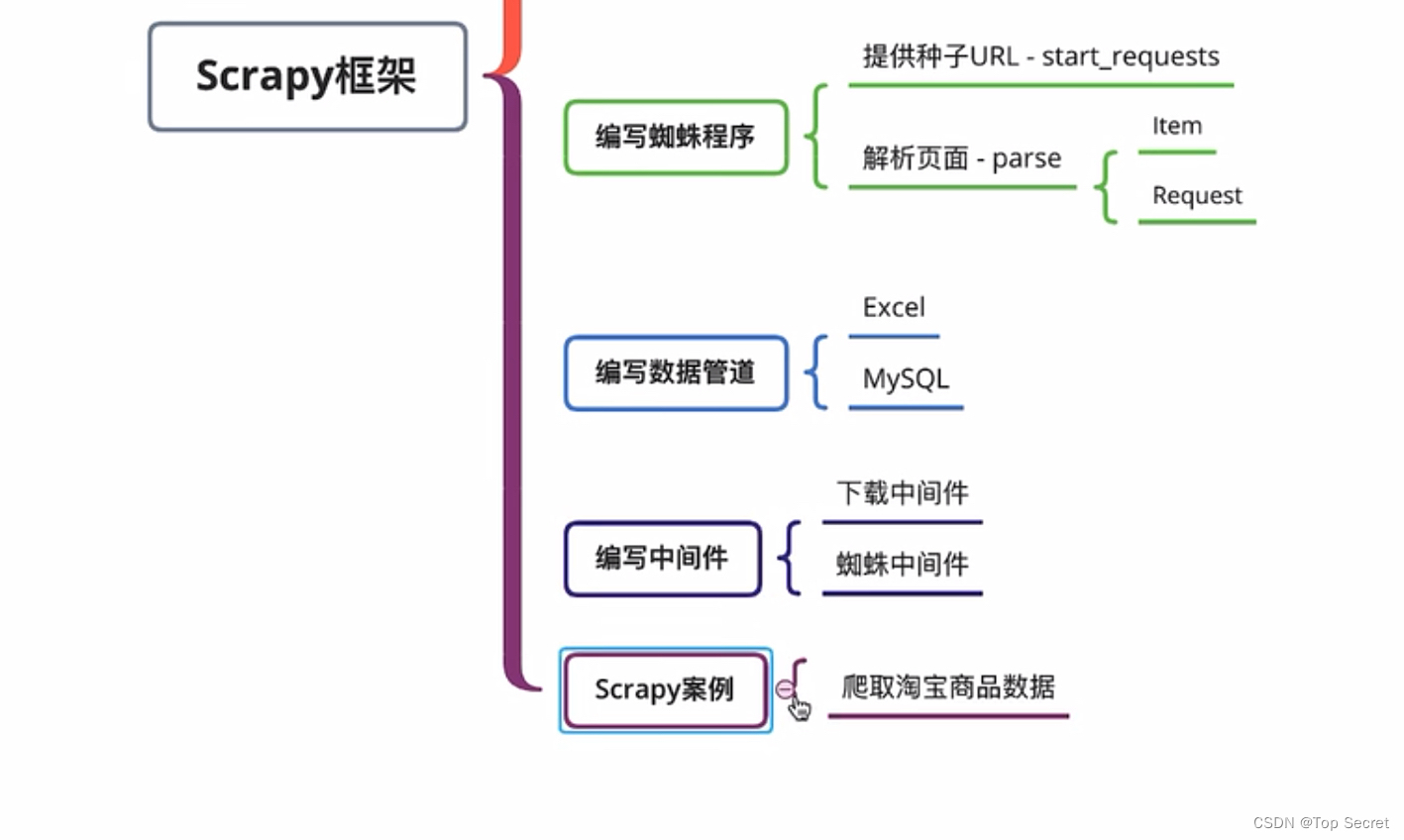
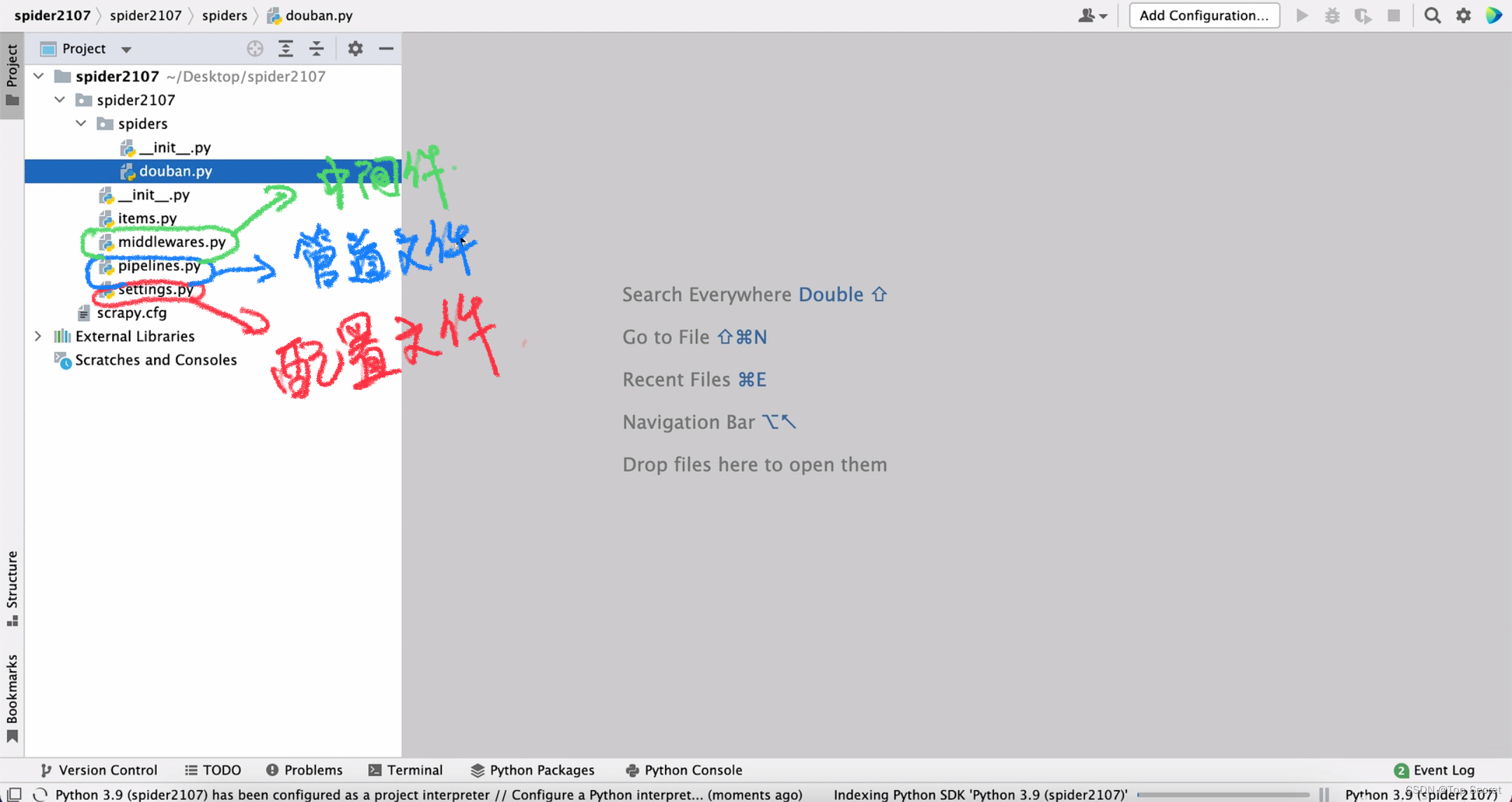
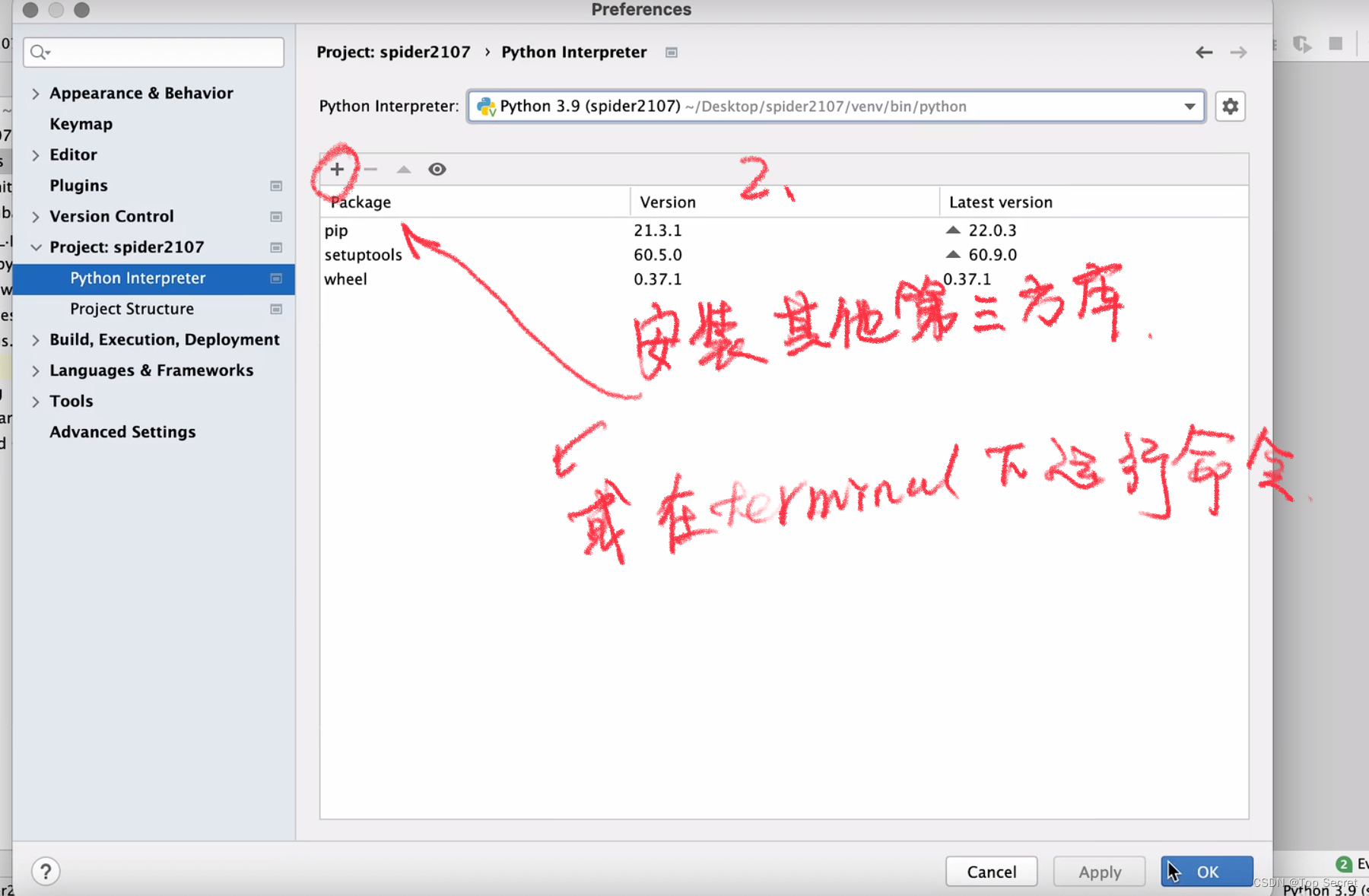
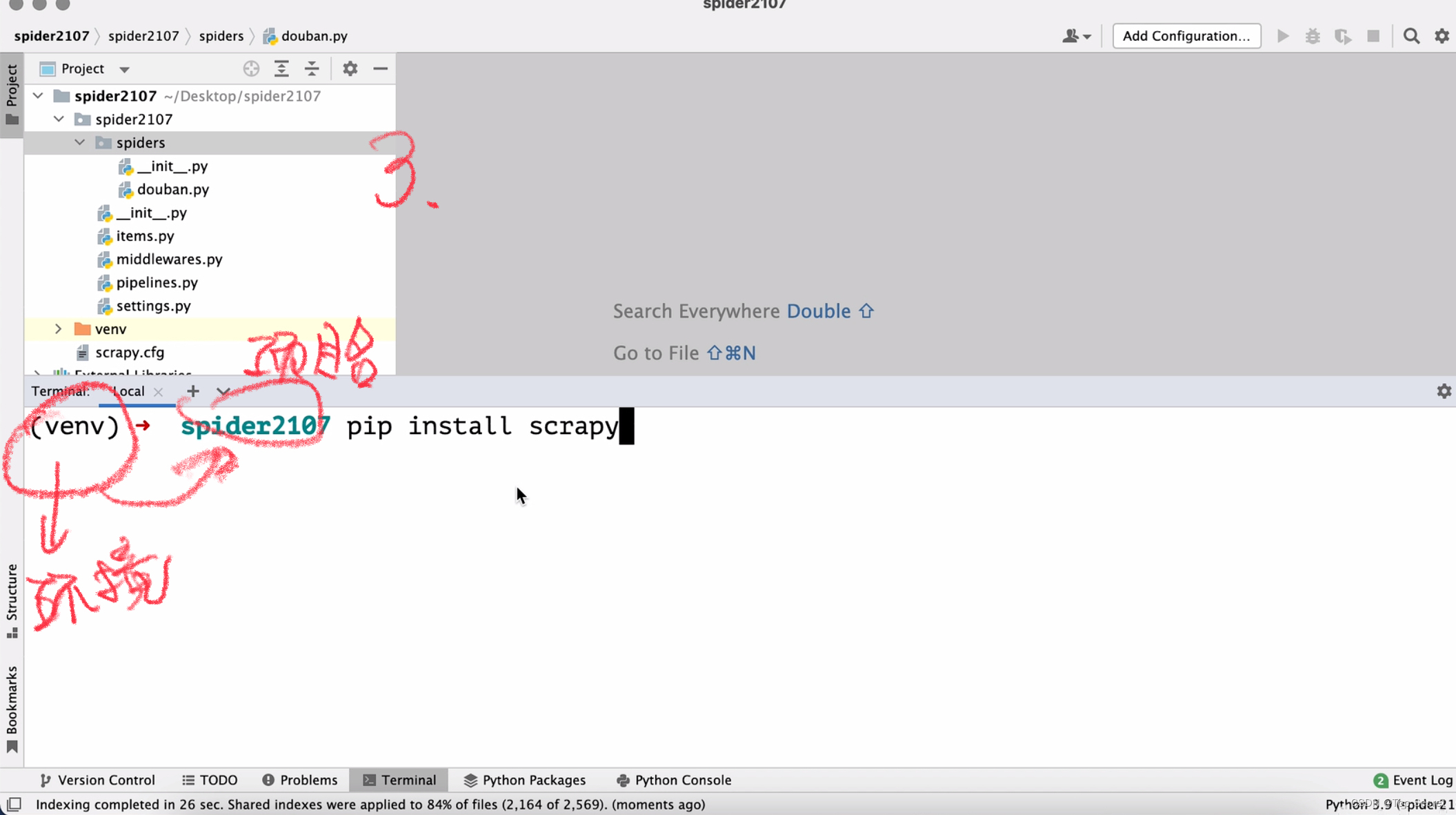
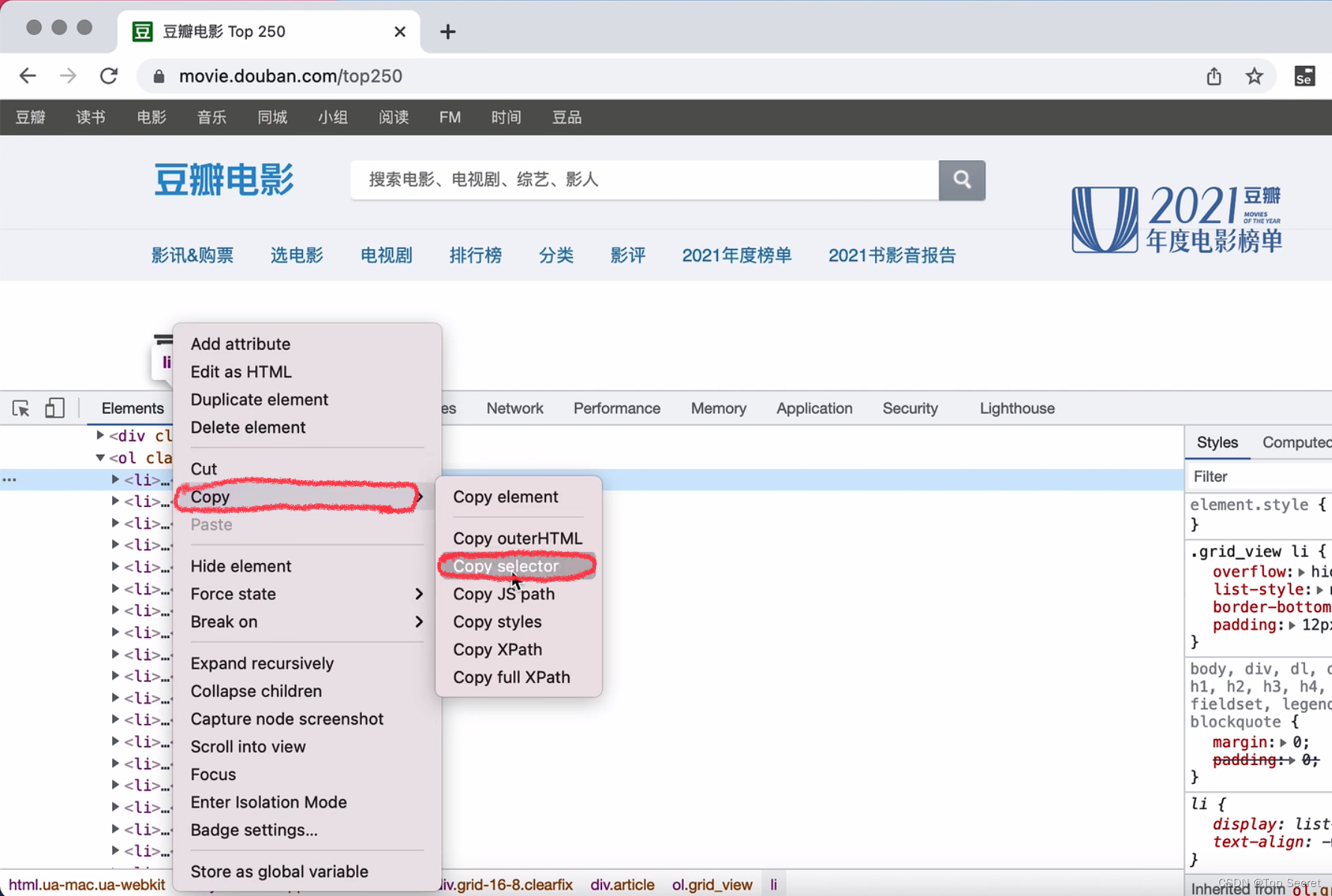
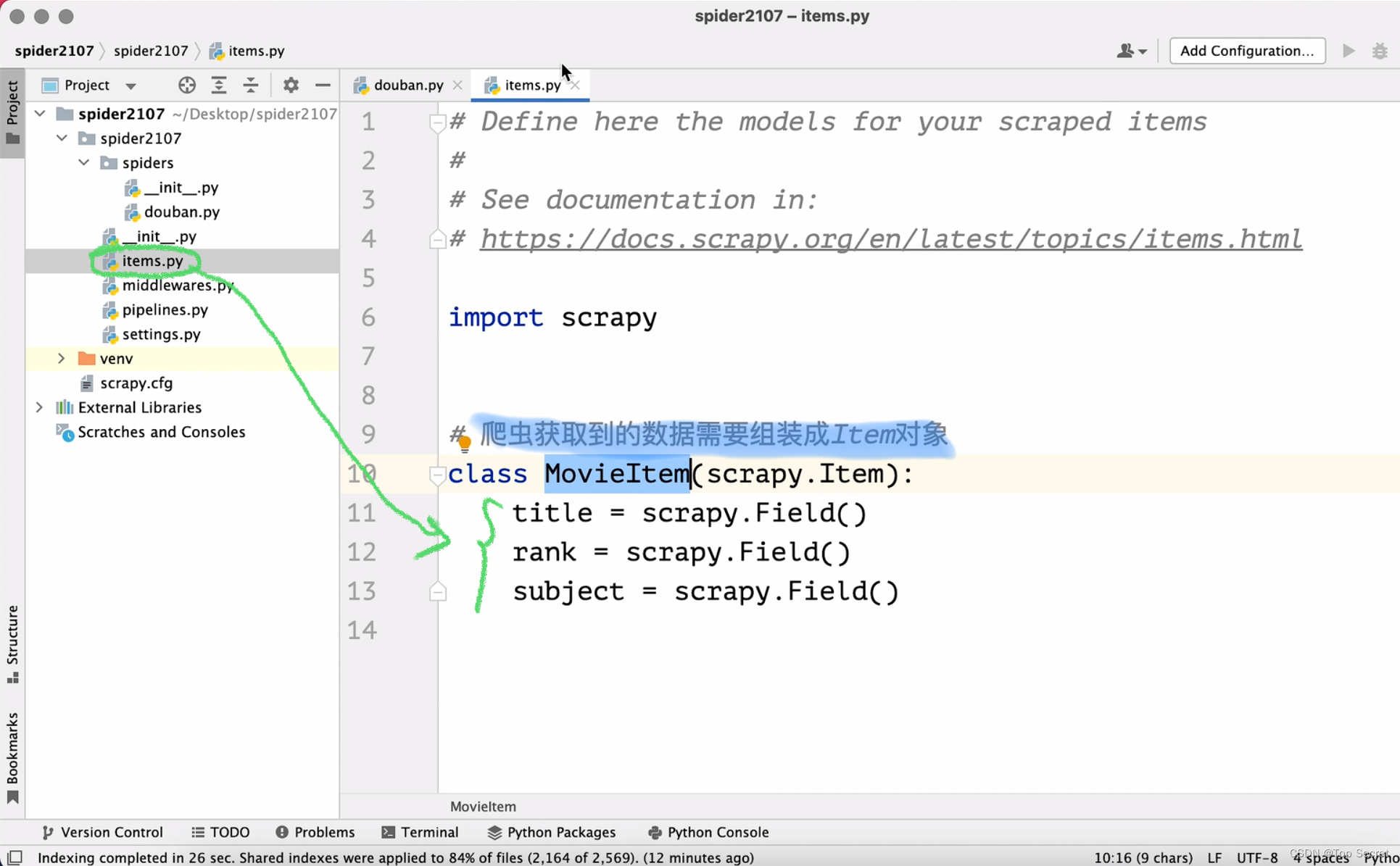
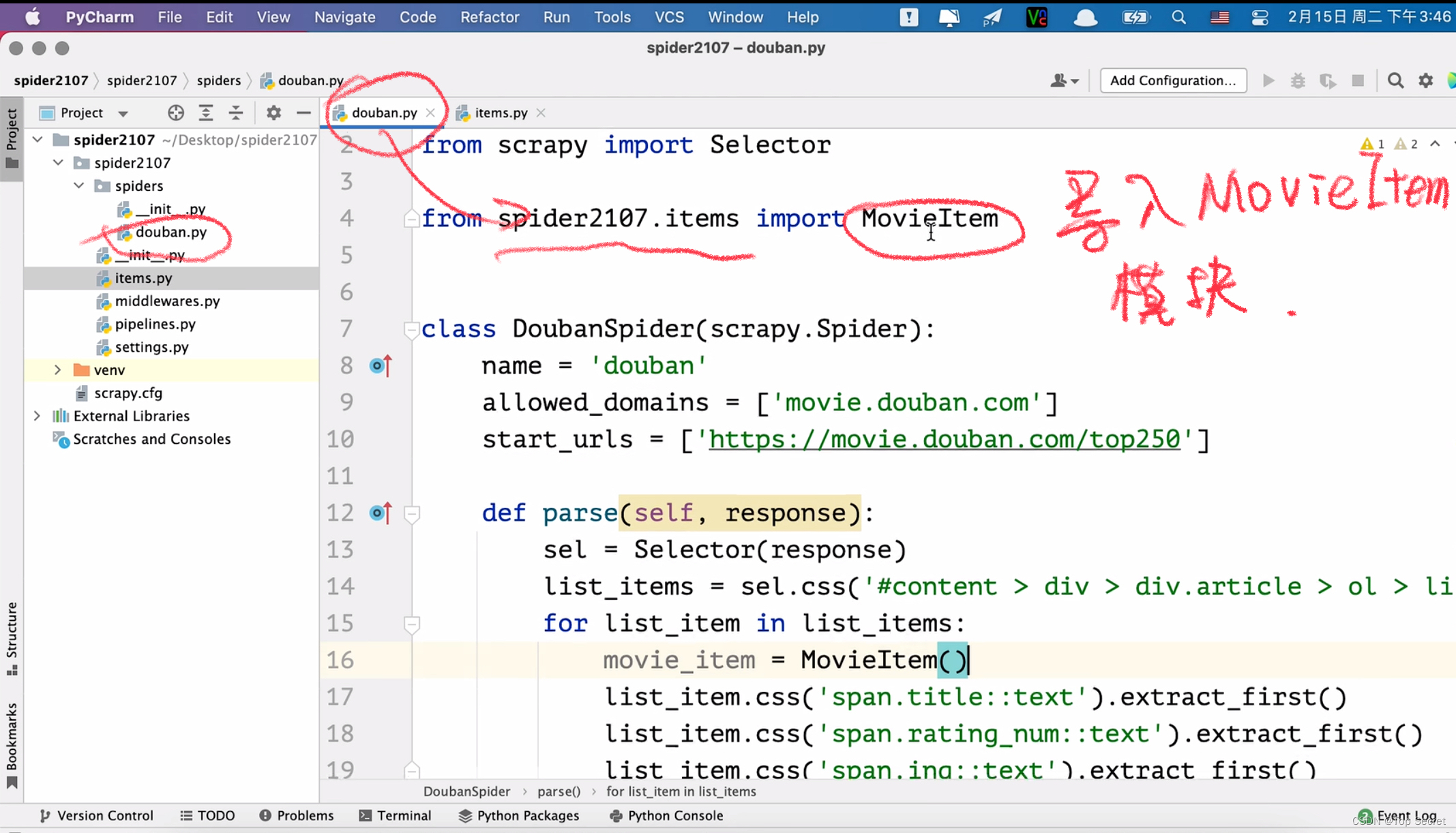
爬虫基础——Scrapy(B站学习笔记)
-
相关阅读:
计算机网络第四章——网络层(中)
vite+vue3+ts中watch和watchEffct的使用
智能化时代与智慧化时代
OpenCV-Python小应用(四):红绿灯检测
风控建模十二:数据淘金——如何从APP数据中挖掘出有效变量
【Vue实用功能】彻底搞懂Vue中的Mixin混入
JavaWeb-服务器&Tomcat
数据科学技术与应用——第2章 多维数据结构与运算
数说故事全新官网2.0正式上线,全新视觉焕新升级
[数据结构]数据结构简介和顺序表
- 原文地址:https://blog.csdn.net/m0_55196097/article/details/125421430