-
Flink学习1:简介
flink目录:


1.传统的数据处理模式:
1.1中心数据库模式
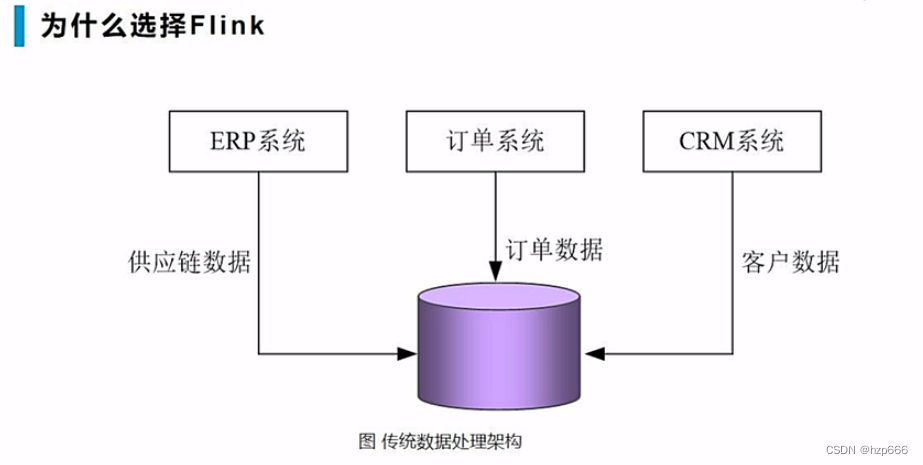

中心数据库负载很大,而且中心数据库一旦出现问题,所有业务系统都将崩溃
1.2 lamda数仓模式


但是lamda模式的数仓,一般采用关系型数据库,无法满足海量数据的存储

1.3 基于Hadoop的hdfs搭建的lamda数仓模式

一定程度上解决了,不同计算模式(实时和离线)的业务需求。

但是,这种流批模式,等于是实时和离线两套架构,导致 复杂度和运维成本高。

1.4 基于流处理的模式

流处理架构一般分为2部分,消息传输层(负责采集新数据 和 推送数据) 和 流处理层(负责数据的转换加工等)

流处理大致框架

flink没有中心数据库,而且流处理天然支持批处理(不再需要两套实时和离线架构)
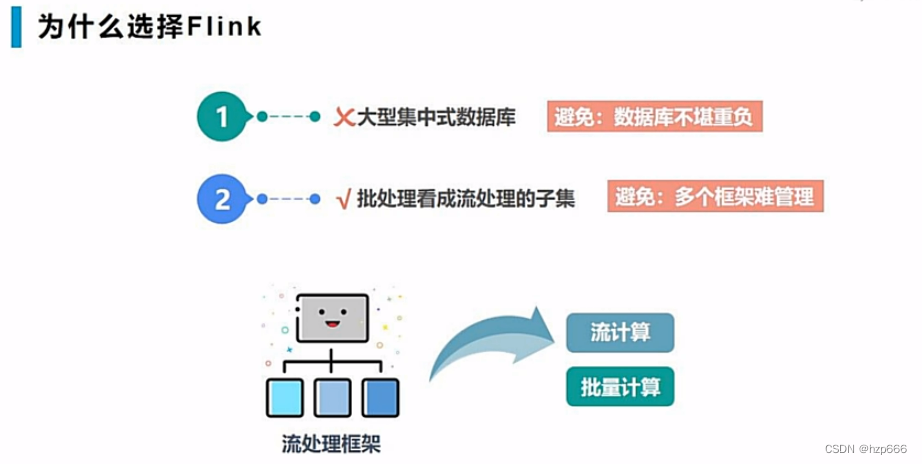
2.flink的介绍
2.1 flink的特点




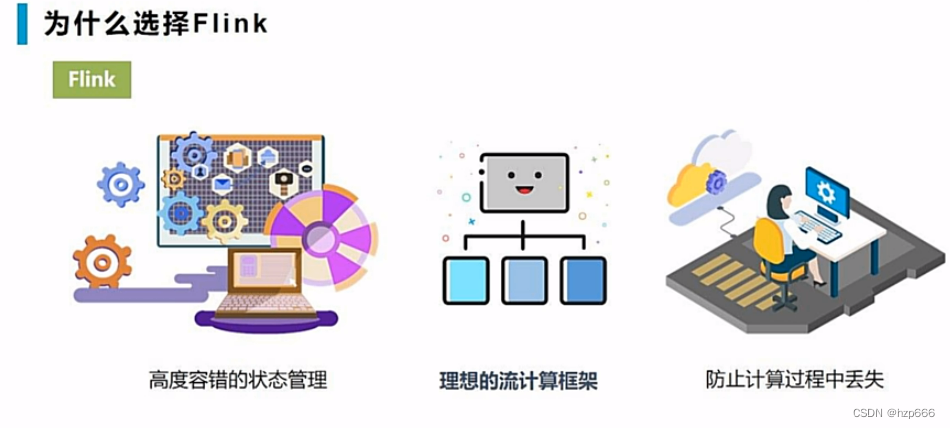

flink的优势:
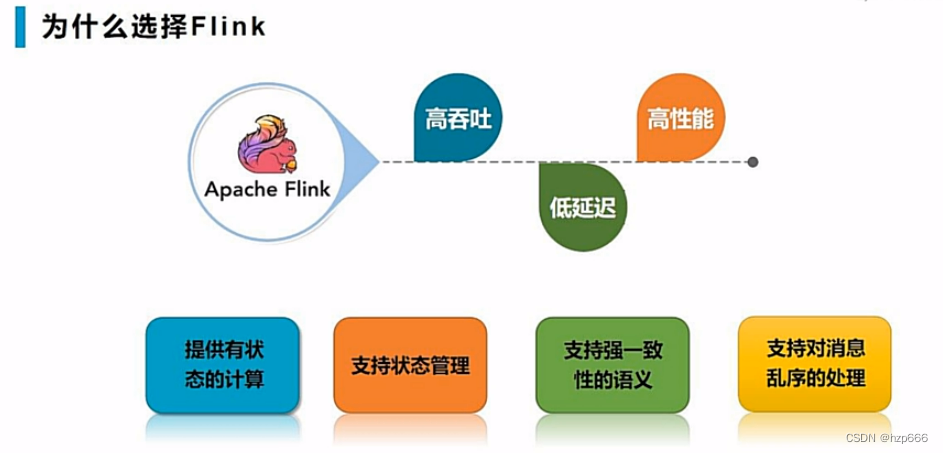
2.2 flink的优势:

2.2.1 流式窗口:
其中第3个高度灵活的流式窗口
因为在流式数据中是无穷无尽的,不能直接进行计算,所以flink提出了,窗口的概念:

窗口的概念
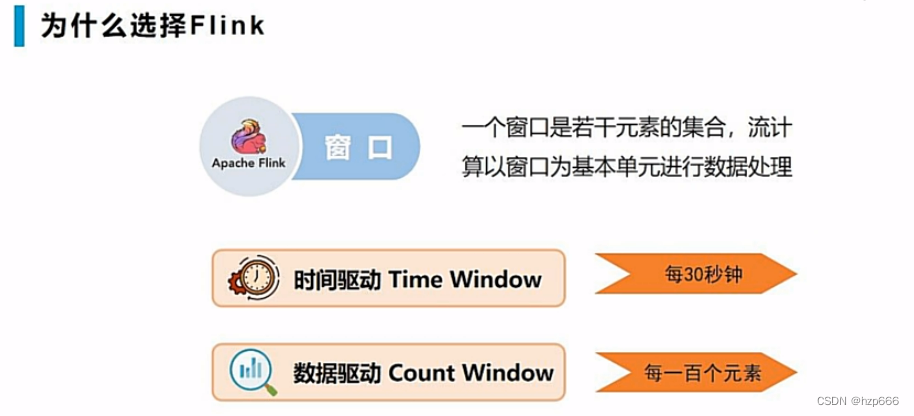
窗口的分类:

2.2.2 流式计算的状态:

有状态是指的每个事件的状态都会记录:

2.2.3 良好的容错性
如何保证分布式系统,各节点的一致性


flink 不断创建快照,来对照数据一致性

2.2.4 高性能的内存管理
因为java的内存管理会有一些问题,所以flink创建了自己的内存管理


flink是如何自己管理内存的
将所有的对象进行序列号和反序列化,在内存中存储

序列化存储内存,这样做的好处:

2.2.5 支持迭代和增量迭代
这里的迭代指的是:每次迭代计算的结果,给到下个迭代
增量迭代:下个迭代只需要,计算上个迭代的部分数据,或者 只需要更新上个迭代的部分数据集




-
相关阅读:
Sublime Text3 最简单的修改字体的方法
卫语句-前端应用
综合布线工程测试技术
三门问题-Swift测试
详细教程。2022年滁州市明光市、来安县等各地区高新技术企业申报
MySQL标准差和方差函数使用
力扣(LeetCode)304. 二维区域和检索 - 矩阵不可变(2022.11.01)
数据结构 ----- 归并排序
[附源码]java毕业设计壹家吃货店网站
C++函数模板学习笔记
- 原文地址:https://blog.csdn.net/hzp666/article/details/125423225