-
Huffman编码的Python与Matlab实现(附讲解)及编码效率与信源概率分布之间的关系
Author:qyan.li
Date:2022.5.30
Topic:借助于
Matlab和Python实现Huffman编码并对代码性能及编码效率进行分析Reference:
https://blog.csdn.net/qq_42098718/article/details/102809485https://blog.csdn.net/weixin_46258766/article/details/117607050一、写在前面:
~~~~~~~~ 最近,《信息论与编码》的课程设计需要我们自行实现
Huffman编码,并分析一下Huffman编码效率和信源概率分布之间的关系。所以,还是按照老样子写篇博文记录一下。Huffman编码的python或Matlab实现在CSDN上参考的资源很多,本篇博文编码实现的代码也是借用他人的,参考链接查看说明中的Reference,后续编码效率分析的代码自行实现,仅供大家参考,如有不当,也欢迎大家评论区批评指正,积极交流。二、Matlab自带Huffman函数调用:
~~~~~~~~ 老样子,还是直接先上代码,方便大家参考调用:
%% Matlab自带Huffman函数测试 clc clear %% 信源符号总共三个(可以理解为三进制) symbols = 1:3; p = [0.45 0.35 0.2]; %% 生成待编码的符号序列 sig = randsrc(100,1,[symbols;p]); tic dict = huffmandict(symbols,p); % Huffman编码生成 comp = huffmanenco(sig,dict); % 序列进行huffman编码 toc dsig = huffmandeco(comp,dict); if(~isequal(sig,dsig)) print('Error!'); else L = sum(cellfun('length',dict(:,2))'.*p); l = length(comp)/100; H = -sum(p.*log2(p)); eta = H/L; fprintf('Source Entrop:%1.2f,\nAverage Huffman code length:%1.2f,\nCoding efficiency:%3.1f.\n',... H,L,eta*100); end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
小
Tips:-
sig = randsrc(100,1,[symbols;p])用于产生含有100个symbol的符号序列,其中符号概率分布(信源概率分布)为矩阵p参考文献:https://blog.csdn.net/u011108244/article/details/52782361
-
tic和toc在Matlab中用于记录代码的运行时间,且自动输入显示在console中
三、Huffman编码效率规律分析:
~~~~~~~~ 为分析
Huffman编码效率和信源概率分布之间的关系,我们在此处随机生成1000组包含10个symbols的信源概率分布,分别计算编码效率,并存入txt文件进行保存,同时绘图进行可视化展示:
~~~~~~~~ 从上述编码效率图像中,我们几乎获取不到任何有用的信息,但是可以看见,所有Huffman编码的编码效率都在96.5以上,其中还有部分组的编码效率已经超过99.5。 ~~~~~~~~ 但是为判断
Huffman编码效率与信源概率分布的关系,仅仅靠上面的图像是没有任何作用的。因此,我们需要提取出其中两个比较重要的点:编码效率最大和最小值点,进行信源概率的分析。最大编码效率:Max_efficiency = 99.7827 最小编码效率:Min_efficiency = 96.5620 ~~~~~~~~ 下面两幅图展示的是编码效率最高和最低的两种情况下,信源概率分布的情况:

~~~~~~~~ 但是,观察上面两幅图,好像也并没有办法得出任何建设性的结论,既然从结果总结不出任何的结论,那就转换方向,猜测信源概率分布和
Huffman编码效率之间的关系,而后验证是否正确即可。 ~~~~~~~~ 顺着这种思路,我们产生第一个猜想:信源的概率分布越均匀,Huffman编码效率越高,于是,借助于代码进行验证,既然猜想信源概率分布的均匀性与效率有关,那就干脆取一种极端的情况,信源等概率分布:
%% 信源等概率分布 symbols = 1:10; p = ones(1,10)/10;- 1
- 2
- 3
此处,运行上述代码,输出的结果为:
历时 0.126426 秒。 Source Entrop:3.32, Average Huffman code length:3.40, Coding efficiency:97.7.- 1
- 2
- 3
- 4
~~~~~~~~ 结果比较明显,信源等概率分布的编码效率
97.7明显比最大的编码效率99.7827要小很多,从此处即可以证明Huffman编码的效率与信源概率分布的均匀性基本没有什么关系,这一个方面其实从最大最小的分析那里即可以较为明显的看出。 ~~~~~~~~ 为进一步说明上述猜想不符合实际情况,代码中又计算方差指标用于衡量信源概率分布的均匀程度,并绘制信源方差和编码效率的曲线图。由此,也可以说明上述猜想与实际情况不相符合,如下图:
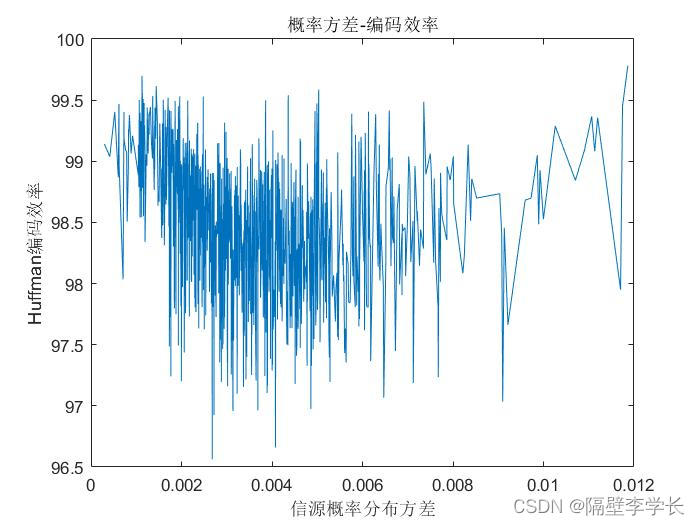
~~~~~~~~ 上述猜想错误,我们只得以进行其他假设,知乎上某位答主指出结论:信源概率分布越接近于2的负幂次项分布,Huffman编码的效率就越高,链接:https://www.zhihu.com/question/21146443/answer/35487161
~~~~~~~~
OK,现在结论已经知道,但是怎么验证呢?或者如何设置一个量度来判断信源概率分布与2的负幂次概率分布之间的贴近程度呢!最终的解决办法,借助于每一个信源符号概率与离他最近的2的负幂次的差的绝对值和来进行表征。衡量指标的计算方法:
- 初始化2的负幂次概率矩阵:
[1 0.5 0.25 0.125 0.0625 0.03125 0.015625] - 计算信源概率分布中每一个概率和离他最近的负幂次概率之间的绝对值差
- 计算出的所有绝对值差求和,获得信源概率分布的衡量指标
~~~~~~~~ 指标计算完成后,绘制上述指标和对应Huffman编码效率之间的关系图,如下图:

~~~~~~~~ 从上述中,可以看出:当衡量指标变小(说明此时的信源概率分布越接近2的负幂次分布)时,
Huffman编码的效率升高。这种情况说明上述的猜想是正确的,但是为什么并非严格的上升或下降的关系,猜测可能是指标设置的存在部分问题,但上述图像已经可以证明猜想的正确性。其实这种关系从Huffman编码的计算过程也是可以感受到的。 ~~~~~~~~ 现在,我们可以在回头看看,编码效率最高和最低时的信源概率分布情况:
Min_efficiency:0.114287527254987 0.0858841646595697 0.0964289876325734 0.0899019239264328 0.187208366203080 0.101651365197345 0.171970748146060 0.0782183655074910 0.0722370614230294 0.00221149004943209Min_efficiency:0.0165848708352351 0.00294453828055680 0.0679903091140727 0.0304985494733784 0.0111968267297072 0.242078234846760 0.111053329496081 0.253162202946172 0.00811368952010042 0.256377448757936 ~~~~~~~~ 会发现,
Max_efficiency的信源概率分布明显更贴近2的负幂次项,比如0.25附近,0.125附近,0.0625附近,0.03125附近,0.015625附近。这和我们的猜想也是一致的,同样也在是侧面印证猜想的正确性。参考代码:
%% 测试1000组随机生成的信源概率分布对应的编码效率的变化情况 clc clear %% 初始化编码效率矩阵 possibilityArray = zeros(1000,12); for j = 1:1000 %% 初始10个符号,随机生成1000组信源概率分布 symbols = 1:10; p = rand(1,10); possibility = sum(p); for i = 1:10 p(i) = p(i)/possibility; end sig = randsrc(100,1,[symbols;p]); tic dict = huffmandict(symbols,p); % Huffman编码生成 comp = huffmanenco(sig,dict); % 序列进行huffman编码 toc dsig = huffmandeco(comp,dict); if(~isequal(sig,dsig)) print('Error!'); else L = sum(cellfun('length',dict(:,2))'.*p); l = length(comp)/100; H = -sum(p.*log2(p)); eta = H/L; fprintf('Source Entrop:%1.2f,\nAverage Huffman code length:%1.2f,\nCoding efficiency:%3.1f.\n',... H,L,eta*100); end possibilityArray(j,1) = j; %% 存入编码序列的index possibilityArray(j,2:11) = p; %% 存入每组的信源概率分布 possibilityArray(j,12) = eta*100; %% 存入每组Huffman编码的编码效率 end %% 将随机生成的1000组数据存入txt文件 writematrix(possibilityArray,'./possibilityFile.txt') %% ---------------------------------------------------- %% %% 读取1000组Huffman编码效率 possibilityArray = readmatrix('./possibilityFile.txt'); %% 绘制编码效率变化曲线图 plot(possibilityArray(:,1),possibilityArray(:,12)) xlabel('编码序号') ylabel('编码效率') title('1000组随机生成概率的Huffman编码效率') %% ---------------------------------------------------- %% %% 编码效率的分析(最大和最小的编码效率) M_data = readmatrix('./possibilityFile.txt'); subplot(2,1,1) [Max_efficiency,Max_index] = max(M_data(:,12)); plot(1:10,M_data(Max_index,2:11)); xlabel('信源符号索引') ylabel('信源概率') title('最大编码效率信源分布情况') subplot(2,1,2) [Min_efficiency,Min_index] = min(M_data(:,12)); plot(1:10,M_data(Min_index,2:11)); xlabel('信源符号索引') ylabel('信源概率') title('最小编码效率信源分布情况') %% ---------------------------------------------------- %% % 信源等概率分布时,编码效率为97.70(高于最小的编码效率96.5620) %% 特殊情况的编码效率分析(信源等概率分布) symbols = 1:10; p = ones(1,10)/10; %% Matlab生成伪随机数:生成100*1的矩阵,矩阵中的符号在symbols中任选,p为对应符号生成的概率 %% 参考文献:https://blog.csdn.net/u011108244/article/details/52782361 sig = randsrc(1000,1,[symbols;p]); % Matlab中tic和toc结合记录代码执行时间 tic dict = huffmandict(symbols,p); % Huffman编码生成 comp = huffmanenco(sig,dict); % 序列进行huffman编码 toc dsig = huffmandeco(comp,dict); if(~isequal(sig,dsig)) print('Error!'); else L = sum(cellfun('length',dict(:,2))'.*p); l = length(comp)/100; H = -sum(p.*log2(p)); eta = H/L; fprintf('Source Entrop:%1.2f,\nAverage Huffman code length:%1.2f,\nCoding efficiency:%3.1f.\n',... H,L,eta*100); end %% ---------------------------------------------------- %% figure %% 信源概率分布(方差和均值计算) M_data = readmatrix('./possibilityFile.txt'); possibilityData = M_data(:,2:11)'; varArray = var(possibilityData); % 方差计算 AverageArray = ones(1,1000)/10; % 均值计算 M_data(:,13) = varArray'; M_data(:,14) = AverageArray'; [varArraySort,index] = sort(varArray); EffiArray = M_data(:,12); plot(varArraySort,EffiArray(index)); xlabel('信源概率分布方差') ylabel('Huffman编码效率') title('概率方差-编码效率') %% ---------------------------------------------------- %% %% Huffman编码效率猜想验证(越接近于2的幂次的信源概率分布,Huffman编码的效率就会越高) M_data = readmatrix('./possibilityFile.txt'); %% 设置端点值(1 0.5 0.25 0.125 0.0625 0.03125 0.015625) tempArray = zeros(1,8); %% 存储每个符号到端点值的距离 dataArray = [1 0.5 0.25 0.125 0.0625 0.03125 0.015625 0.0078125]; %% 2的负幂次端点值的矩阵 disArray = zeros(1000,1); %% 接近2的负幂次概率分布的程度 for i = 1:1000 Alldistance = 0; for j = 2:11 for m = 1:length(dataArray) tempArray(1,m) = abs(M_data(i,j)-dataArray(1,m)); end MinDistance = min(tempArray(1,:)); Alldistance = Alldistance + MinDistance; end disArray(i,1) = Alldistance; end %% 将对应关系存入txt文件 Degree_efficiency(:,1) = disArray; Degree_efficiency(:,2) = M_data(:,12); writematrix(Degree_efficiency,'./relationship.txt') %% 绘制对应的关系图 [DegreeSort,index] = sort(Degree_efficiency(:,1)); efficiency = Degree_efficiency(:,2); plot(DegreeSort,efficiency(index)) title('衡量指标和Huffman编码效率关系图') xlabel('衡量指标') ylabel('Huffman编码效率')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
小
Tips:- 上述代码执行时,以分割线为间隔分段执行
Matlab代码
四、Huffman编码的python和Matlab实现
~~~~~~~~ 这部分就来到编码环节,由于代码并非我自己编写,所以此处仅做代码的搬运工并对代码中个人认为理解有困难的地方做些许讲解:
-
Huffman编码的python实现:参考链接:
https://blog.csdn.net/qq_42098718/article/details/102809485老样子,还是先上代码,方便大家参考借鉴:
# -*-coding = utf-8-*- # Author:qyan.li # Date:2022/5/16 15:20 # Topic:huffman编码的python实现 # Reference:https://blog.csdn.net/qq_42098718/article/details/102809485 import copy import numpy as np # 结点类Node class class Node(): # 带参构造函数 def __init__(self,value,weight): self.value = value self.weight = weight self.parent = None self.lchild = None self.rchild = None # 判断当前结点是否为左子节点 def isLChild(self): return self.parent.lchild == self # 编码数据构建 def initCodeData(labels,dataSet): ''' :param labels:待编码的符号,如['a','b',....] :param dataSet: 待编码符号权重 :return: 编码数据列表list ''' if(len(dataSet) != len(labels)): raise Exception('数据和标签不匹配') # 待编码数据存放的列表 nodes = [] for i in range(len(labels)): nodes.append(Node(labels[i],dataSet[i])) return nodes # 创建Huffman树 def createHuffmanTree(nodes): ''' :param nodes: 待编码数据传入 :return:根节点,便于后续获取Huffman树 ''' NodeTree = nodes.copy() while len(NodeTree) > 1: # NodeTree升序排列 NodeTree.sort(key = lambda node:node.weight) # 获取树最小权重的两个结点 lNode = NodeTree.pop(0) rNode = NodeTree.pop(0) # 构造新节点,value = None,weight = l.weight + r.weight NewNode = Node(None,lNode.weight + rNode.weight) # 新节点左右结点赋值 NewNode.lchild = lNode NewNode.rchild = rNode lNode.parent = NewNode rNode.parent = NewNode # 新节点放入树中重新参与 NodeTree.append(NewNode) # 根节点父节点为None NodeTree[0].parent = None return NodeTree[0] # 获取HuffmanCode def getHuffmanCode(nodes): # 构建词典存放Huffman编码 codes = {} # 遍历HuffmanTree获得每个结点的编码值 for node in nodes: code = '' value = node.value while node.parent != None: # 判断不是父节点 if node.isLChild(): code = '0' + code else: code = '1' + code node = node.parent # 结点值存入字典 codes[value] = code return codes # Huffman编码常见参数计算(编码效率等等) def codeEfficiency(labels,weights,codes): ''' :param labels:信源符号 :param weights: 信源符号概率 :param codes: 编码字典 :return: entropy-信源熵,AverageCodeLength-平均码长,efficiencyCode-编码效率 ''' entropy = 0 AverageCodeLength = 0 efficiencyCode = 0 weightSum = sum(weights) # 计算平均码长 for i in range(len(labels)): AverageCodeLength += len(codes[labels[i]]) * (weights[i]/weightSum) # 计算信源熵 for i in range(len(labels)): possibility = weights[i]/weightSum entropy += -possibility*np.log2(possibility) # 计算编码效率 efficiencyCode = entropy/AverageCodeLength return entropy,AverageCodeLength,efficiencyCode if __name__ == '__main__': labels = ['a','b','c','d','e'] weights = [55,9,52,411,56] nodes = initCodeData(labels,weights) createHuffmanTree(nodes) codes = getHuffmanCode(nodes) print(codes) entropy,AverageCodeLength,efficiencyCode = codeEfficiency(labels,weights,codes) print(entropy) print(AverageCodeLength) print(efficiencyCode)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
小
Tips:Huffman编码的过程本质上为从底端点构造二叉树的过程,二叉树根据概率的大小进行合并与赋值相应的编码。Huffman编码的获取本质上为从根节点依据路径寻找底结点的过程,并在这个过程中将每个结点的编码记录下来形成最终的Huffman编码
~~~~~~~~ 另外,二叉树构建和遍历的代码此处不会细讲,了解过数据结构与算法对上述代码应该会比较熟悉,谈一点个人认为代码中最重要的部分:
copy函数的应用 ~~~~~~~~ 仔细观察代码中的
createHuffmanTree和getHuffmanCode两个函数,其实都是对nodes进行操作,区别在于create函数操作nodes本身,而get函数操作nodes的copy对象。 ~~~~~~~~ 在搞清楚作者为什么这么写前,可以先了解一下这两个函数需要产生什么作用?首先,
initCodeData函数用于构建一个存放node的list,值得注意,其中node全部为初始化,彼此之间没有任何联系,而create函数的作用就是创建Huffman二叉树,函数返回根节点,方便后续进行Huffman树的调用,调用完create函数后各个node之间通过树联系起来了,但是,注意此处假设我们没有nodes.copy函数,此时的nodes中就只剩下一个概率为1根节点啦。 ~~~~~~~~ 这时,我们就需要调用
get函数获得Huffman编码,会发现get函数传入的参数也是nodes,但明显不能是只有一个概率为1根节点的nodes,也不能是create函数之前init函数生成的nodes(因为这个nodes中node还没有建立关系)。所以,这就是copy函数的作用,它使得init生成的nodes中的所有元素得以保留,同时又使得其中的每一个node都具有Huffman树所建立的联系,这才是我们所需要的。终于写完啦,喘口气~~ ~~~~~~~~
copy函数的特性,给大家提供一个代码,供大家参考,对上文理解有帮助的# -*-coding = utf-8-*- # Author:qyan.li # Date:2022/5/16 18:27 # Topic:测试copy函数使用 # Reference:https://www.php.cn/python-tutorials-408710.html ''' 区别在于: 1. 直接赋值,相当于起别名,原始修改,所有都会进行修改 2. copy函数,原始修改时,父对象(最上级)不会修改,后续的延伸则会进行修改 ''' dict1 = {'user': 'runoob', 'num': [1, 2, 3]} dict2 = dict1 # 浅拷贝: 引用对象 dict3 = dict1.copy() # 浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用 # 修改 data 数据 dict1['user'] = 'root' dict1['num'].remove(1) # 输出结果 print(dict1) # {'user': 'root', 'num': [2, 3]} print(dict2) # {'user': 'root', 'num': [2, 3]} print(dict3) # {'user': 'runoob', 'num': [2, 3]}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
-
Huffman编码的Matlab实现:参考链接:
https://blog.csdn.net/weixin_46258766/article/details/117607050~~~~~~~~ 老样子,还是先上代码,方便大家参考借鉴:
%% Huffman编码Matlab实现CSDN参考 %% 实验四:哈夫曼编码仿真实现 clear all clc % 用户输入符号概率 p = input('请输入离散信源概率分布,例如[0.5,0.5]:\n'); N = length(p); tic % 将概率排序并获得单步码字排序 code = strings(N-1,N);% 初始化单步过程的码字 reflect = zeros(N-1,N);% 初始化位置对应向量 p_SD = p;% p_SD为每次得到的概率排序数组 for i=1:N-1 % i表示排序后第几个符号 M = length(p_SD); [p_SD,reflect(i,1:M)] = sort(p_SD,'descend')% 将概率从大到小进行排序 code(i,M) = '1';% 概率最小的是1 code(i,M-1) = '0';% 概率第二小的暂且定义为0 p_SD(M-1) = p_SD(M-1)+p_SD(M);% 将最后两个概率相加 p_SD(M)=[]; end % 根据位置对应向量和单步过程的码字计算对应码字 CODE = strings(1,N); % 初始化对应码字 % 确定待编码序列中每一位的编码 %% 索引值 for i=1:N column = i; for m=1:N-1 [row,column] = find(reflect(m,:)==column); % 实时更新索引值 CODE(1,i) = strcat(CODE(1,i),code(m,column)); % 将最小的两个概率映射成一个(将概率最小的两个符号在新一轮中索引值变为一致,每组的最后一个元素) if column==N+1-m column = column-1; end end end CODE = reverse(CODE); toc % 计算平均码长 for i=1:N L(i) = size(char(CODE(1,i)),2); end L_ave = sum(L.*p); H = sum(-p.*log2(p)); % 计算信源信息熵 yita = H/L_ave; % 计算编码效率 % 展示输出码字、平均码长和编码效率 disp(['信号符号 ',num2str(1:N)]); disp(['对应概率 ',num2str(p)]); disp(['对应码字 ',CODE]); disp(['平均码长',num2str(L_ave)]); disp(['编码效率',num2str(yita)]);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
小
Tips:Matlab实现Huffman编码的方式无法借助于树的构建,Matlab中并不存在类似于面向对象的编程思想。个人一直认为Matlab的编程风格更加数学化,所以Huffman编码的实现也是更多借助于数学矩阵思想。
~~~~~~~~ 讲实话,个人很佩服这个博主编写的代码,很是简洁和巧妙,但这同时就以为着理解的难度会比较大。自己也只能仅凭个人的一点见解尝试着给大家解释一下,如有理解上的疏漏,欢迎批评指正:
~~~~~~~~ 本来想给大家粘贴张图片,但奈何
markdown对图片太不友好,所以还是文字描述吧!代码中最重要的两个部分:reflect和code矩阵 ~~~~~~~~ 假设信源概率分布为
[0.25 0.2 0.4 0.15] ~~~~~~~~ 则在此过程中,
reflect和code矩阵分别为:reflect矩阵: 3 1 2 4 1 3 2 0 2 1 0 0 code矩阵: "" "" "0" "1" "" "0" "1" "" "0" "1" "" ""- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
~~~~~~~~
reflect矩阵和code矩阵中的元素是一一对应的,所以找到目标元素在reflect矩阵中的位置,在code矩阵中对应位置取而后拼接即可完成,但难点在于如何在reflect矩阵中寻找目标元素。 ~~~~~~~~
reflect矩阵是(N-1,N)的,N-1代表此过程一共进行N-1次的Huffman编码,N则代表一共有N个元素,矩阵中的每一行代表排序后矩阵每一个位置上元素在排序前矩阵中的位置索引。容易得,每进行一次Huffman编码,信源概率最小的两个就会合并,信源中就会减少一个符号。而**reflect每一行最后两个元素分别代表当前概率最小的两个元素,且他们合并的元素在下一行矩阵中的值一定是最大的,等于矩阵长度(注意是值,而不是位置,因为生成的新矩阵还要进行排序)**,基于此,在反向获取Huffman编码时,仅需要借助此映射关系即可完成。 ~~~~~~~~ 结合实际
reflect矩阵再看一下: ~~~~~~~~
reflect矩阵中的第一行最后两个2和4分别对应概率0.2和0.15,他们合并后生成的0.35概率在reflect第二行中的索引一定为第二行矩阵的长度3,但经过排序后,位置出现在第2个位置上。下面的均以此类推,第二行3和2的元素合并后在第三行中的索引值为第三行的长度2,但排序后排在第一位。 ~~~~~~~~ 那么,如何反向回溯
Huffman编码呢?以概率0.2的元素为例,他在reflect第一行中为2所代表的元素,然后位置却是第三位,此时可以去code中寻找编码,然后,它和第四位数字会被编码形成新的元素,且新元素的索引值为reflect矩阵下一行的长度为3。因此,在第二行中寻找值为3的元素,在第二位,此时又可以去code中寻找,很不幸,他将再一次被编码,合并后对应第三行中值为2的元素(因为第三行长度为2),在位置一的地方,再去code中寻找对应的编码即可。 ~~~~~~~~ 但是,有一个问题是,被编码两个元素中概率较大(排在前面)的元素,在本行的位置和下一行中的索引不会变(注意是索引,不是位置),例如0.2这个元素,他在第一行中位于第三个位置上,第一次
Huffman编码后生成的新元素的索引就是3,而0.15这个元素的索引会上一行中的位置减1,第一行在第四位,新生成的元素在第二行中的索引为3,这也就解释为什么会出现:if column==N+1-m column = column-1;- 1
- 2
这行代码,为什么要减一,就是解决这个问题的。
~~~~~~~~ 实在不知道怎么写啦,有问题评论区见吧,或者直接寻找原大佬询问!!!
五、自行实现Huffman编码与Matlab官方代码效率比较:
~~~~~~~~ 课程设计剩下最后一个内容,比较自行实现的
Huffman编码效率和官方函数运行效率的大小:编码信源概率分布:[0.45 0.2 0.15 0.2](仅测试一组,含4个符号) 运行结果: 官方自带:历时 0.002 秒左右 python实现:历时0.001秒左右 matlab实现:历时 0.02 秒左右- 1
- 2
- 3
- 4
- 5
~~~~~~ 最终结果还是挺让我意外的,我原本以为
python的运行时间最长,没想到是最短的。自己编写的Huffman编码时下果不其然,比官方低将近10倍,未来的路途任重而道远。 -
相关阅读:
【计算机毕业设计】206校园顺路代送微信小程序
无线信道划分
机器学习参数|数学建模|自相关性
java运算操作符示例大全
艾美捷ProSci 激活素RIB / ACVR1B重组蛋白方案
Spring中bean的生命周期(最详细)
Nginx集群负载均衡配置完整流程
代理IP和Socks5代理:跨界电商与爬虫的智能引擎
玄子Share-MultipartFileUtil-文件上传工具类,单文件,多文件,指定大小,指定后缀
vue3: 2.如何利用 effectScope 自己实现一个青铜版pinia 一 getters篇
- 原文地址:https://blog.csdn.net/DALEONE/article/details/125076914