-
Redis 集群
一、集群概念
业务发展过程中遇到的峰值瓶颈:
- redis提供的服务OPS可以达到10万/秒,当前业务OPS已经达到20万/秒
- 内存单机容量达到256G,当前业务需求内存容量1T
这个时候可以使用集群的方式可以快速解决上述问题
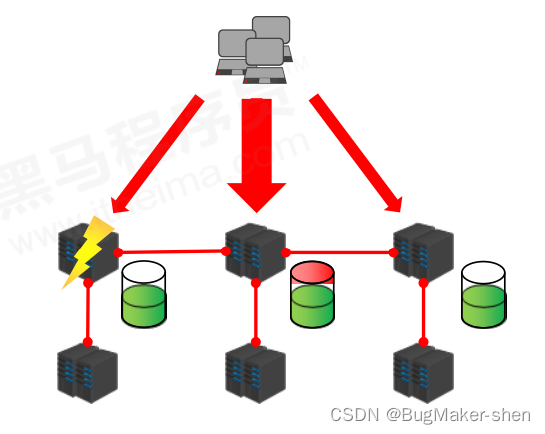
集群架构: 集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果
集群的作用:
- 分散单台服务器的访问压力,实现负载均衡
- 分散单台服务器的存储压力,实现可扩展性
- 降低单台服务器宕机带来的业务灾难的可能性,实现高可用性
二、集群数据存储设计
- 通过hash算法设计,计算出key应该保存的位置
- 将所有的存储空间切割成16384份,每台主机保存一部分,每份代表的一个存储空间(槽),不是一个key的保存空间,这个存储空间可以保存很多key
- 将key按照计算出的结果放到对应的存储空间

假定我们现在增加一台机器,这些存储的数据以及空间应该如何分配呢?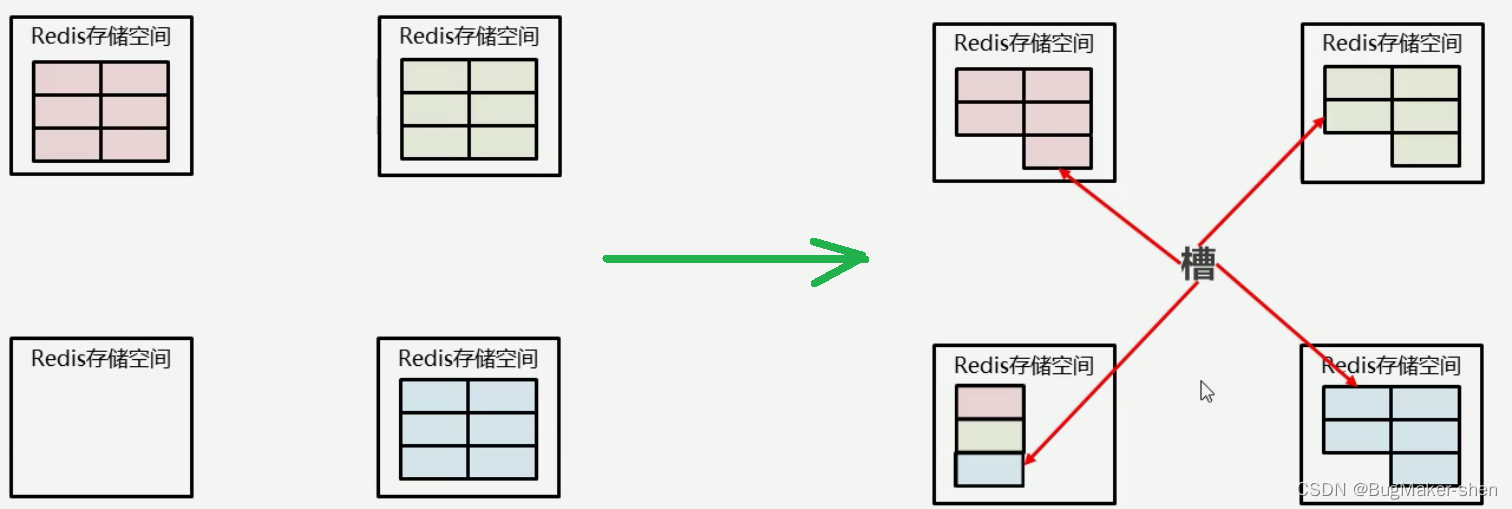
一台机器分一些槽出来给新的机器,所谓的增加机器和删除机器,改变槽所存储的机器即可
三、集群内部通讯设计
- 各个数据库相互通信,保存各个库中槽的编号
- 一次命中,直接返回
- 一次未命中,告知具体位置,最多两次才命中

此时有一台客户端查找key,首先会通过hash算法计算出key对应的槽编号,然后在哈希环上找到对应的机器,检查这台机器上是否有对应的槽(由于可能进行了机器的增加、删除,机器上的槽会被添加到不同机器上)如果这台机器有key对应的槽,直接查找返回;如果没有,则查找每台机器槽编号和机器的记录,然后再到对应机器取即可
四、搭建集群
Cluster配置
设置加入cluster,成为其中的节点
cluster-enabled yes|no- 1
cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-config-file <filename>- 1
节点服务响应超时时间,用于判定该节点是否下线或切换为slave
cluster-node-timeout <milliseconds>- 1
master连接的slave最小数量
cluster-migration-barrier <count>- 1
配置3 masters—3 slaves
编写redis-6379.conf
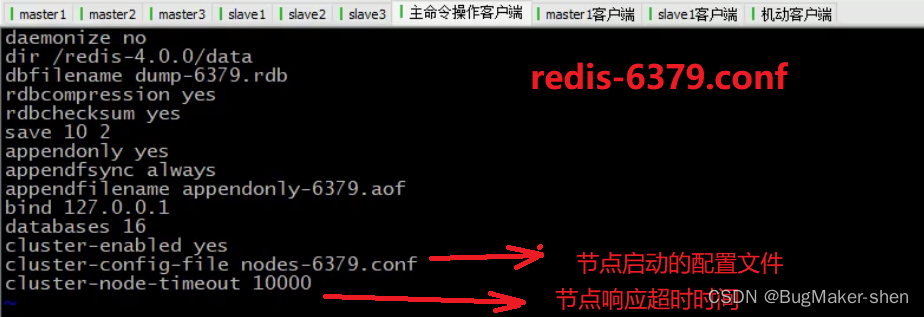
由redis-6379.conf得到redis-6380.conf、redis-6381.conf、redis-6382.conf、redis-6383.conf、redis-6384.conf,分别作为3个master和3个slave的启动配置文件
启动所有的master和slave

这还是一个一个的节点,我们需要把他们连在一起,在src目录下有一个redis-trib.rb的可执行程序(这个文件执行需要安装ruby)
# 这里的n表示1个master对应n个slave # 后面的ip:port表示master和slave的信息,master和slave的数量需要和前面的n对应 # 假设n=1,写了6组ip:port,则表示前3个为master,后3个为slave,实现1主1从 # 假设n=2,写了9组ip:port,则表示前3个为master,后6个为slave,实现1主2从 ./redis-trib.rb create --replicas n ip1:port1 ip2:port2 ....- 1
- 2
- 3
- 4
- 5
写6组ip:port,执行指令,生成3组1主1从
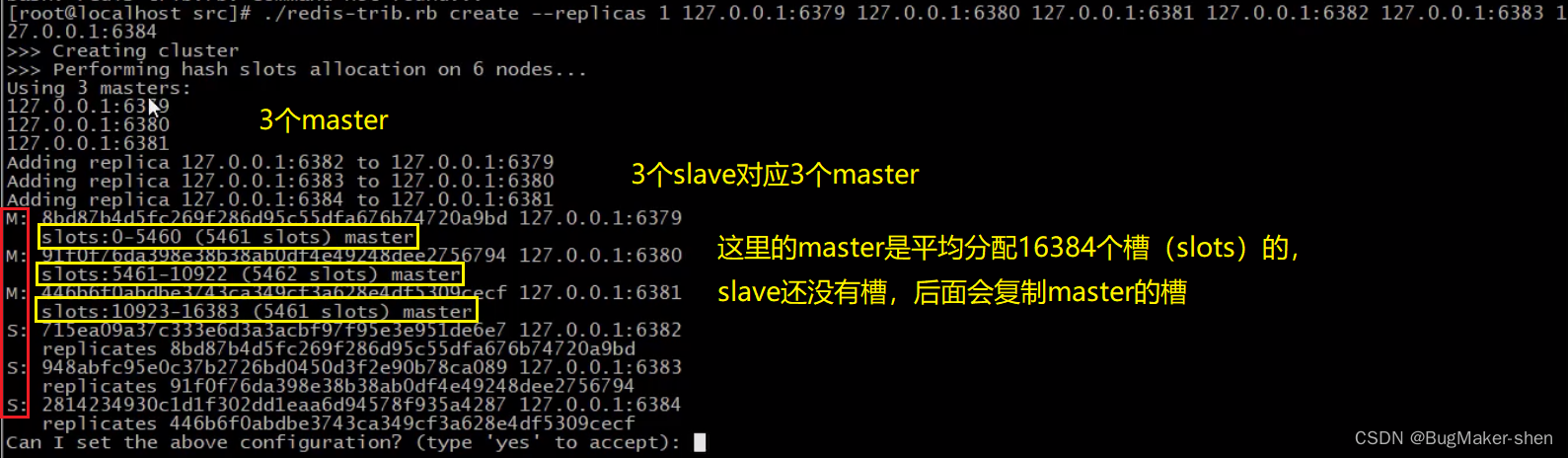
生成多组主从结构前,我们先看一下data目录(在redis-端口.conf中配置)下生成的节点的配置文件nodes-端口.conf
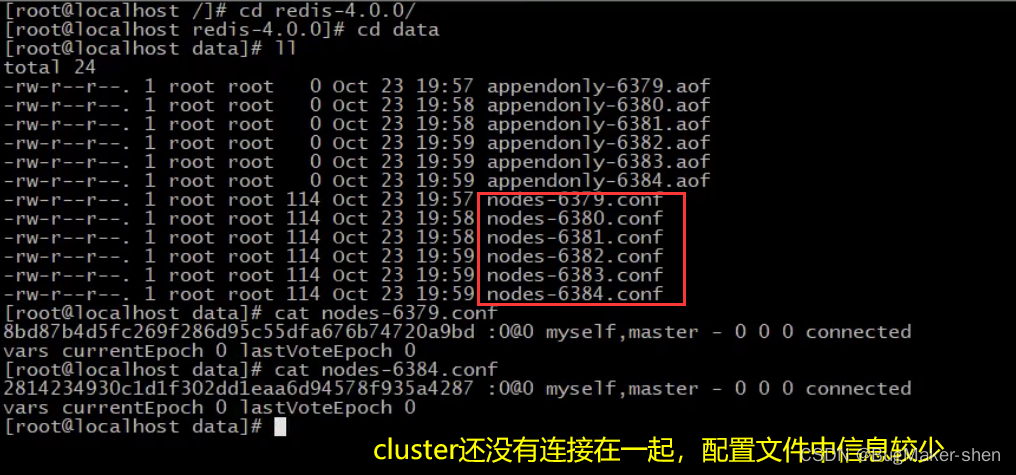
我们输入yes,生成3组1主1从

cluster连接在一起后,集群就配置好了,此时nodes-端口.conf就发生了改变。我们看一下master 6379对应的节点配置文件

我们看一下6379master终端的提示信息

五、集群使用实践
1. 使用集群存放数据

我们连接上6379端口的redis服务器后,想要在6379服务器上放数据,可通过CRC算法和模16384计算出itheima这个数据应该放在5798号槽,而这个槽在6380机器上,不允许我们放在6379机器上我们使用
-c参数登录服务器,这个参数是专门操作集群的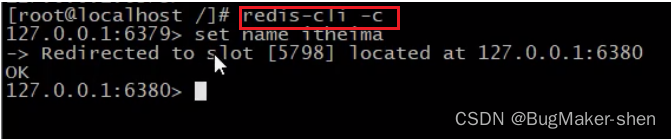
我们依然连接6379服务器,放数据的时候,给出提示信息,虽然我们在6379上放数据,但通过CRC算法和模16384计算出
itheima这个数据应该放在5798号槽,故重定向到了6380机器我们通过
-c参数登录6382这台slave服务器取数据

提示信息告诉我们,重定向到6380机器上的5798号槽取出来的。只要是我们登录集群中的任意一台机器,都能在6380机器上的5798号槽取出来,如果我们登录6380机器就不会有重定向信息,而是直接取出数据2. slave掉线对集群的影响
集群最大的优势并不是能在多台机器存放数据,而是集群能够很好的解决宕机带来的业务灾难
我们先停掉6382 slave1

我们看一下slave1对应的master1,master1发现slave1 10s内无响应,则将其标记为已下线
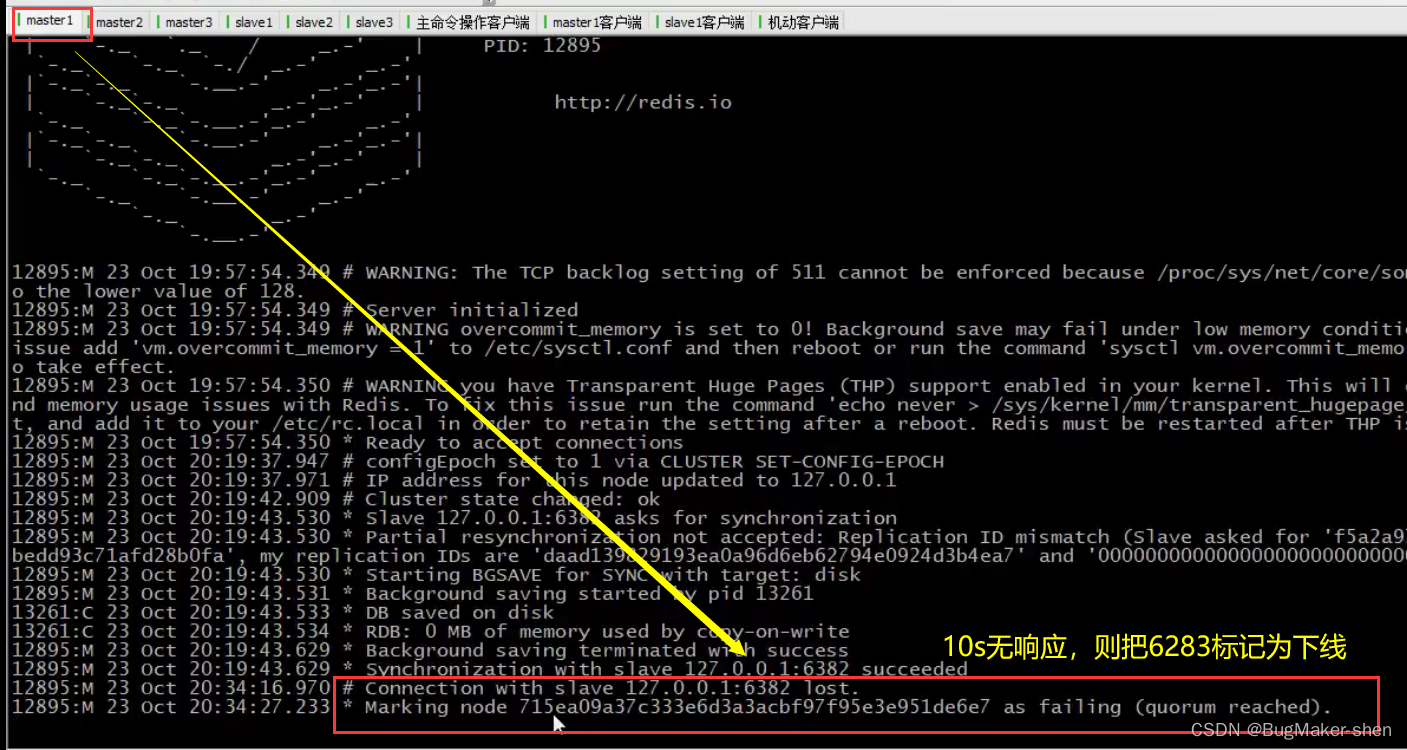
而此时集群中的其他master和slave都会收到master1的通知,slave1已下线
这时我们让slave1重新上线
上线后和master1重新同步即可,master1再通知其他的master和slave有关slave1的上线信息,其他的机器就清除slave1的下线标记
总结: slave下线后,与其对应的master会将其标记为下线状态,同时通知集群中其他机器该slave下线;待其上线后,再与其进行数据同步,然后通知集群中其他的机器该slave的上线信息
3. master掉线对集群的影响
我们停掉master1
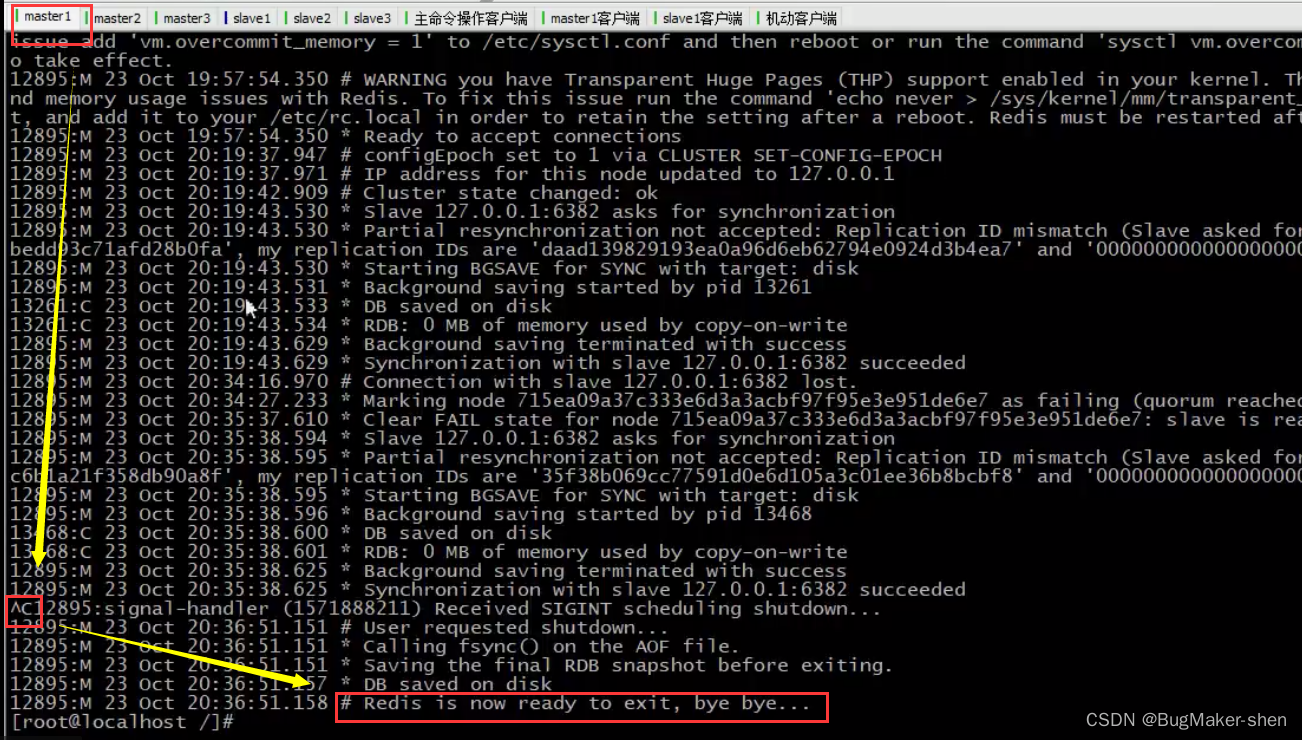
下面是与master1对应的slave1的操作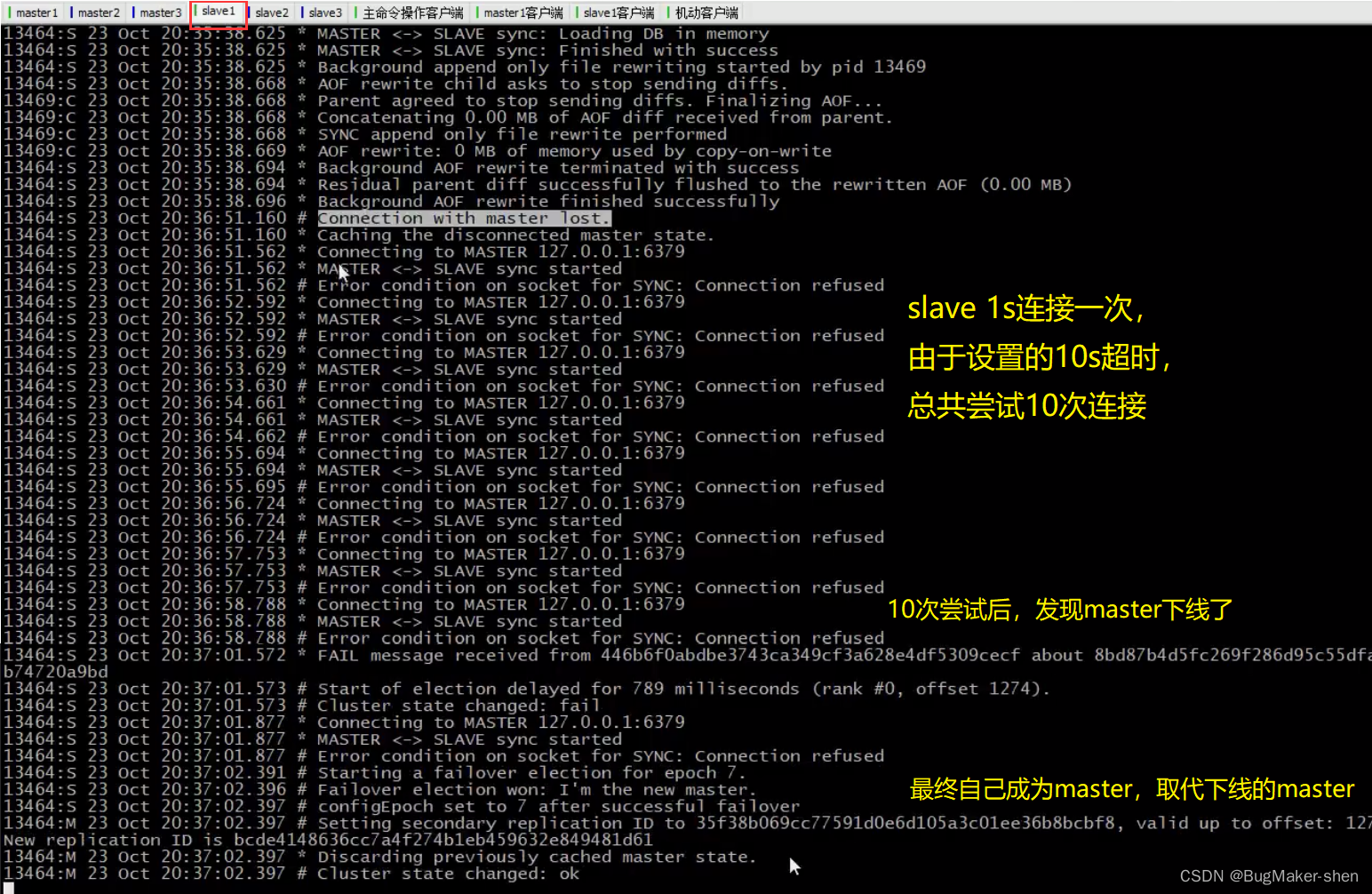
我们用cluster nodes查看一下节点信息,发现有4个master,其中6379被标记为fail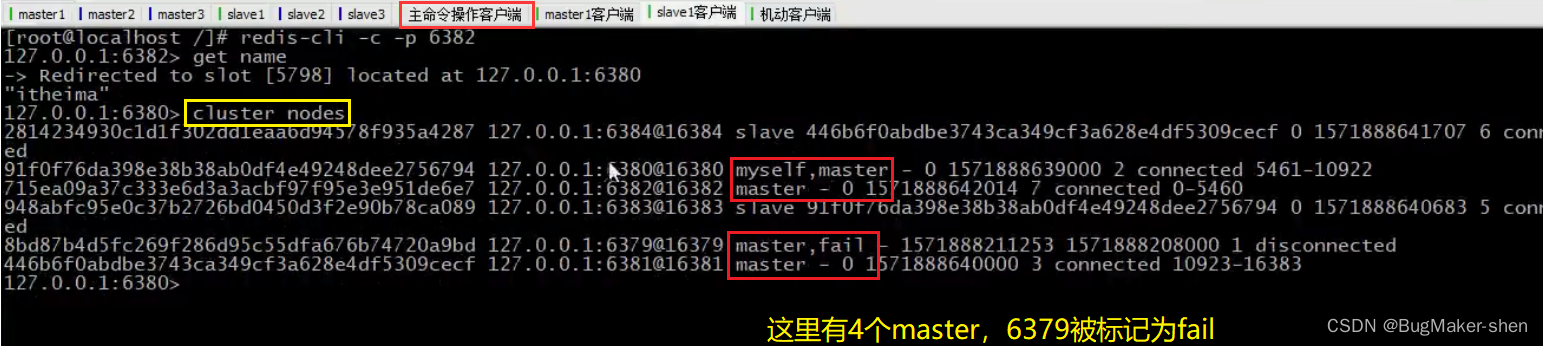
我们现在重新启动6379

6379请求和6382进行数据同步
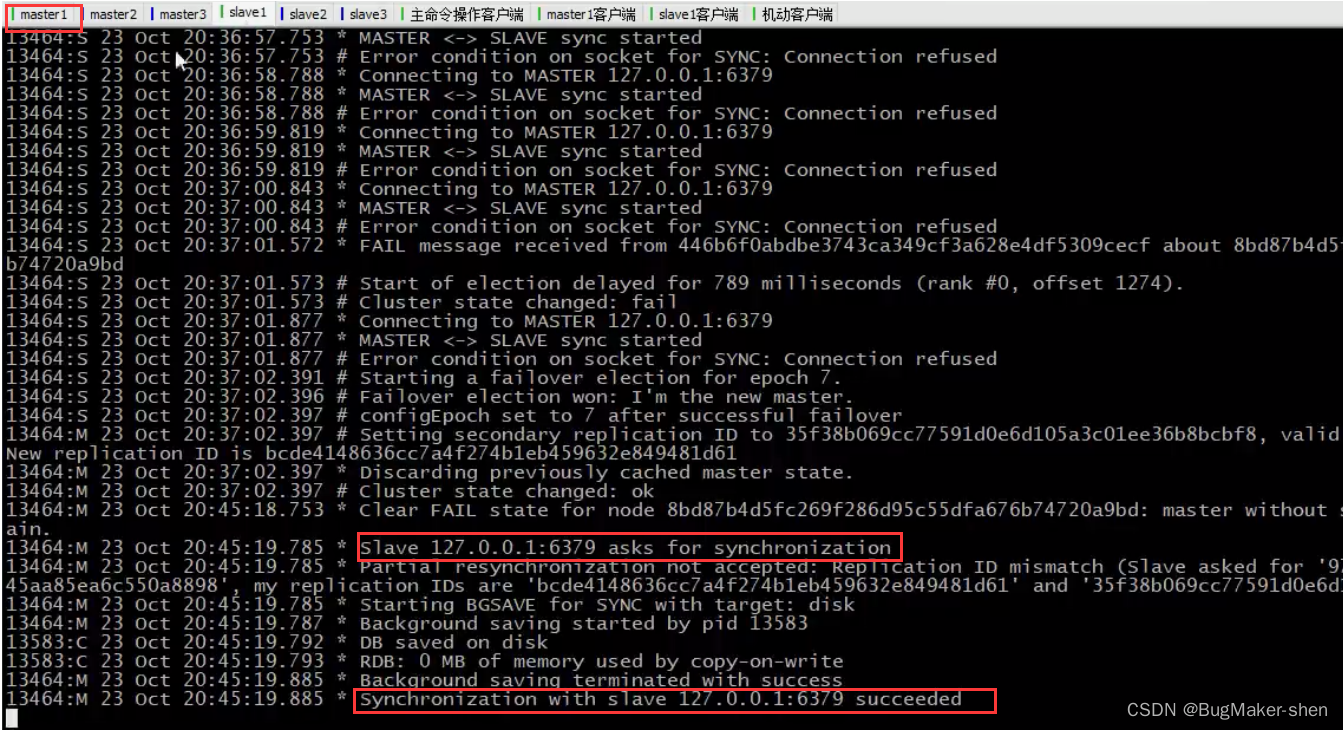
再用cluster nodes查看一下节点信息,6379的状态从master fail被修改为slave
总结: 当master1下线后,对应的slave1会尝试连接,超时后自己成为新的master,然后通知集群中其他的机器,master1下线以及自己成为master的消息,master1的状态被标记为master fail;6379重新上线时,会成为slave,并和自己的master进行数据同步Cluster节点操作命令
查看集群节点信息
cluster nodes- 1
进入一个从节点redis,切换其主节点
cluster replication <master-id>- 1
发现一个新节点,新增主节点
cluster meet ip:port- 1
忽略一个没有slot的节点
cluster forget- 1
手动故障转移
cluster failover- 1
-
相关阅读:
24.聚类算法的介绍
Python error:Compressed file ended before the end-of-stream marker was reached
防火墙 (五十四)
嵌入式系统中偶发性问题
Leetcode978. Longest Turbulent Subarray
Shell脚本使用jq解析json
Android Java JVM常见问答分析与总结
【算法|双指针系列No.3】leetcode202. 快乐数
MATLAB算法实战应用案例精讲-【优化算法】树木生长算法(TGA)(附MATLAB代码实现)
<OpenCV> Mat属性
- 原文地址:https://blog.csdn.net/qq_42500831/article/details/125413561