-
MySQL高级SQL语句
目录
3.1、查询学生信息(先按兴趣id升序排列,相同分数的,id按降序排列)
3.2、 查询学生信息(先按兴趣id升序排列,相同分数的,id按升序排列 )
前言:对数据库的查询,除了最基本的增删改查语句之外,有时候需要对查询的结果进行处理,比如对数据的升序、降序等。有时候需要对查询的结果集进行处理。例如只取10条数据、对查询结果进行排序或分组等等。
一、按关键字排序
使用select语句可以将需要的数据从 mysql 数据库中查询出来,如果对查询的结果进行排序操作,可以使用 order by 语句完成排序,并且最终将排序后的结果返回给客户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段。
- ASC是按照升序进行排序的,是默认的排序方式,即 ASC可以省略。
- SELECT语句中如果没有指定具体的排序方式,则默认按ASc方式进行排序。
- DESC是按降序方式进行排列。
- 当然ORDER BY前面也可以使用WHERE子句对查询结果进一步过滤。
语法格式:
- select 字段1,字段2... from 表名 order by 字段1,字段2... asc #查询结果以升序方式显示,asc可以省略
- select 字段1,字段2... from 表名 order by 字段1,字段2,... desc #查询结果以降序方式显示
- ASC 是按照升序进行排名的,是默认的排序方式,即ASC可以省略
- DESC 是按照降序的方式进行排序的
- order by 也可以通过 where 子句对查询结果进行进一步的过滤
- 可进行多字段的排序
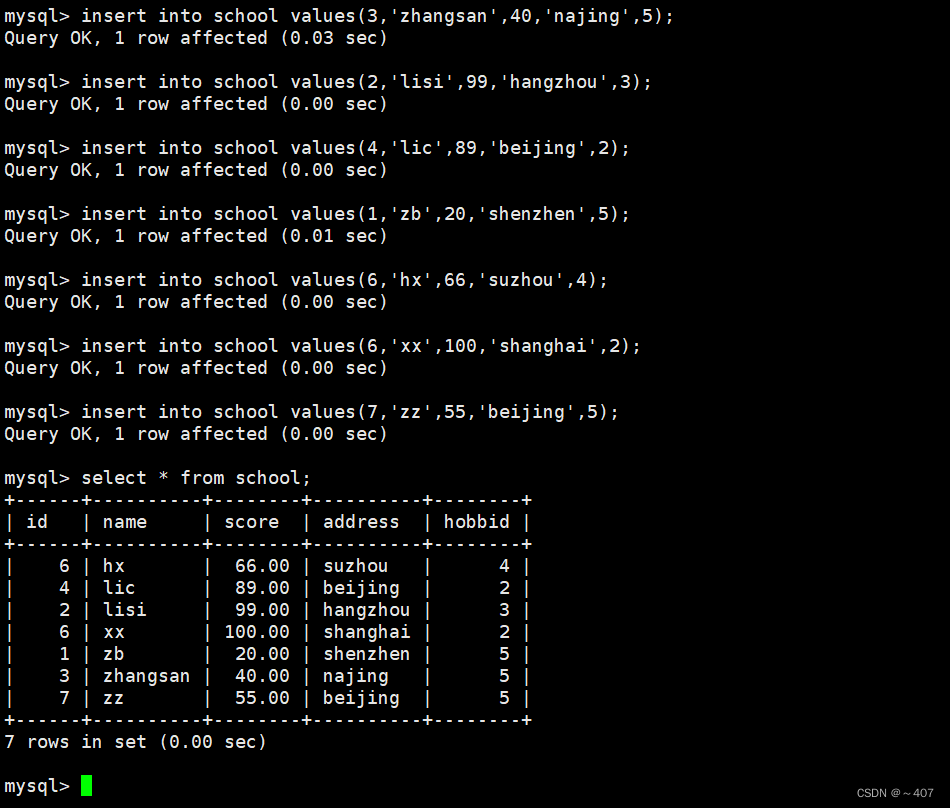
1、创建一个模板表
- create table school (id int,name varchar(10) primary key not null,
- score decimal(5,2),address varchar(20),hobbid int(5));
2、单字段排序
2.1、按分数排序
默认不指定是升序排列
select * from school order by score; (asc默认省略)
2.2、按分数降序排序
select name,score from school order by score desc;
2.3、结合where进行条件过滤
筛选地址是北京的学生按分数升序排列
select name,score,address from school where address='beijing' order by score;
3、多字段排序
ORDER BY 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,ORDER BY 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定,但order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义。
3.1、查询学生信息(先按兴趣id升序排列,相同分数的,id按降序排列)
select id,name,hobbid from school order by hobbid,id desc;
3.2、 查询学生信息(先按兴趣id升序排列,相同分数的,id按升序排列 )
select id,name,hobbid from school order by hobbid,id;
二、区间判断及查询不重复记录
1、AND/OR ——且/或的使用
select id,name from school where id>2 and id<5;
select id,name from school where id>2 or id<5;
2、 嵌套/多条件
select id,name from school where id>2 or (id>3 and id<5);
select id,name,score from school where score <60 or (score>90 and score<100);
- 查看分数大于70 小于等于95的数据
- select id,name,score from school where score >70 and score <=90;

- 查看分数小于70 或者大于90的数据,按降序显示
- select id,name,score from school where score <70 or score >90 order by score desc;

3、distinct 查询不重复记录
- select distinct 字段 from 表名﹔
- distinct 必须放在最开头
- distinct 只能使用需要去重的字段进行操作
- distinct 去重多个字段时,含义是:几个字段同时重复时才能被过滤,会默认按左边第一个字段为依据。
3.1、查看hobbid有多少种
select distinct hobbid from school;
三、对结果进行分组
通过 SQL 查询出来的结果,还可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
select 字段,聚合函数 from 表名 (where 字段名(匹配) 数值) group by 字段名;1、对hobbid进行分组查询,并显示最大的id
select hobbid,max(id) from school group by hobbid;
2、按hobbid相同的分组,计算相同得的个数
select count(name),hobbid from school group by hobbid;
3、结合where语句
筛选分数大于等于80的分组,计算学生个数
select count(name),score from school where score >80 group by score;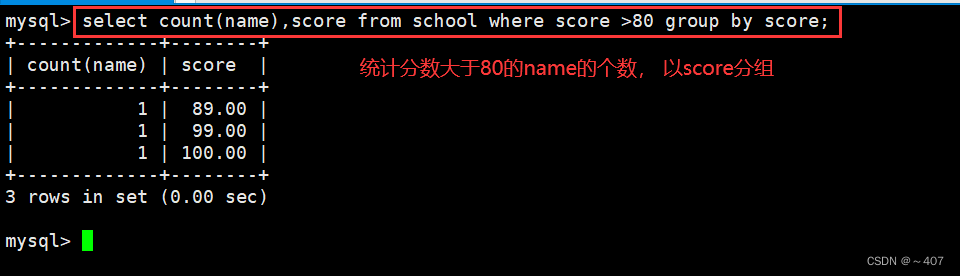
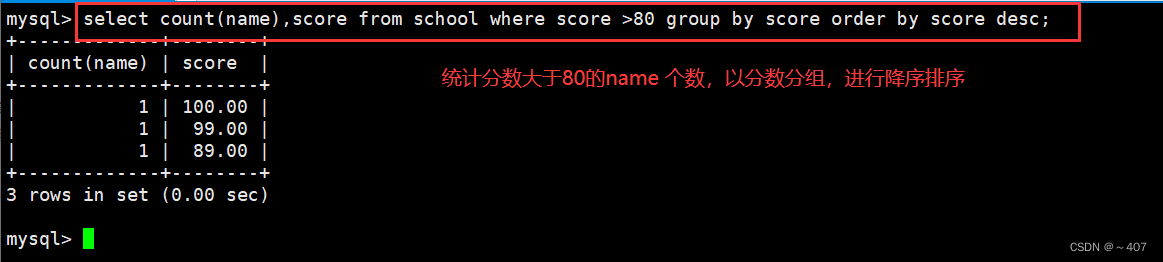
- count(name):计数 score 分数 :
- 结合order by把分数按降序排列
- select count(name),score from gaojie where score > 80 group by score oeder by score desc;
四、限制结果条目
limit 限制输出的结果记录
在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,这时候就需要用到 LIMIT 子句
- 语法格式:
- select 字段 from 表名 limit [offset,] number
- limit 的第一个参数是位置偏移量(可选参数),是设置 mysql 从哪一行开始
- 如果不设定第一个参数,将会从表中的第一条记录开始显示。
- 第一条偏移量是0,第二条为1
- offset 为索引下标
- number 为索引下标后的几位
1、查询所有信息显示前4行记录
select * from school limit 4;
2、从第4行开始,往后显示3行内容
select * from school limit 3,3;
3、按score降序查询前三的数据
select * from school order by score limit 3;
五、设置别名(alias -----as)
- 在 mysql 查询时,当表的名字比较长或者表内某些字段比较长时,
- 为了方便书写或者多次使用相同的表,可以给字段列或表设置别名,方便操作,增强可读性。
- 列的别名 select 字段 as 字段别名 表名
- 表的别名 select 别名.字段 from 表名 as 别名
- as 可以省略
- 使用场景:
- 1、对复杂的表进行查询的时候,别名可以缩短查询语句的长度
- 2、多表相连查询的时候(通俗易懂、减短sql语句)
1、查询表的记录数量,以别名显示
select count(*) as number from school;
2、利用as,将查询的数据导入到另外一个表内
创建xiangxiang表,将school表的查询记录全部插入xiangxiang表
create table xiangxiang as select * from school;
- 此处as起到的作用:
- 创建了一个新表, 并定义表结构,插入表数据(与school表相同)
- 但是”约束“没有被完全”复制“过来 #但是如果原表设置了主键,
- 那么附表的:default字段会默认设置一个0
相似:
克隆、复制表结构
也可以加入where 语句判断
在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突。
列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。

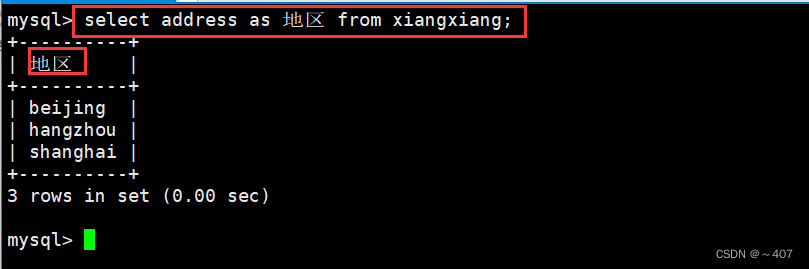
- select address as 地区 from xiangxiang;
- 利用as ,将xiangxiang表中的address设置别名地区,进去查询
未完待续。。。。。。
-
相关阅读:
23.4 Bootstrap 框架5
C. Monoblock(思维/计数)
ATF源码篇(五):docs文件夹-Components组件(4)
git问题: git@10.18.*.*: Permission denied (publickey,password)
一文解读功率放大器(功率放大器如何选型)
WebGL前景如何?
微信小程序通过npm引入tdesign包进行构建的时候报错
Python刘诗诗
微信小程序报错request:fail -2:net::ERR_FAILED(生成中间证书)
【软考-软件设计师精华知识点笔记】第十章 网络与信息安全
- 原文地址:https://blog.csdn.net/weixin_56270746/article/details/125416472