-
端到端语音识别笔记
一、端到端语音识别的输入与输出是什么
输入:目前端到端语音识别常用的输入特征为 fbank。fbank 特征的处理过程为对一段语音信号进行预加重、分帧、加窗、短时傅里叶变换(STFT)、mel 滤波、去均值等。一个 fbank 向量对应往往对应10ms的语音,而一段十秒的语音,即可得到大约1000个 fbank 的向量描述该语音。除了 fbank,MFCC 以及 raw waveform 在一些论文中也被当做输入特征,但主流的方法仍然采用 fbank。输出:端到端的输出可以是字母、子词(subword)、词等等。目前以子词当做输出比较流行,和 NLP 类似,一般用 sentence piece 等工具将文本进行切分。
二、端到端语音识别技术和混合系统的差异是什么
端到端语音识别技术将声学特征序列直接转换成字符或词语序列,其中的转换工作仅仅由一个神经网络模型完成。下图对比了端到端语音识别技术和传统语音识别技术识别流程之间的差异。
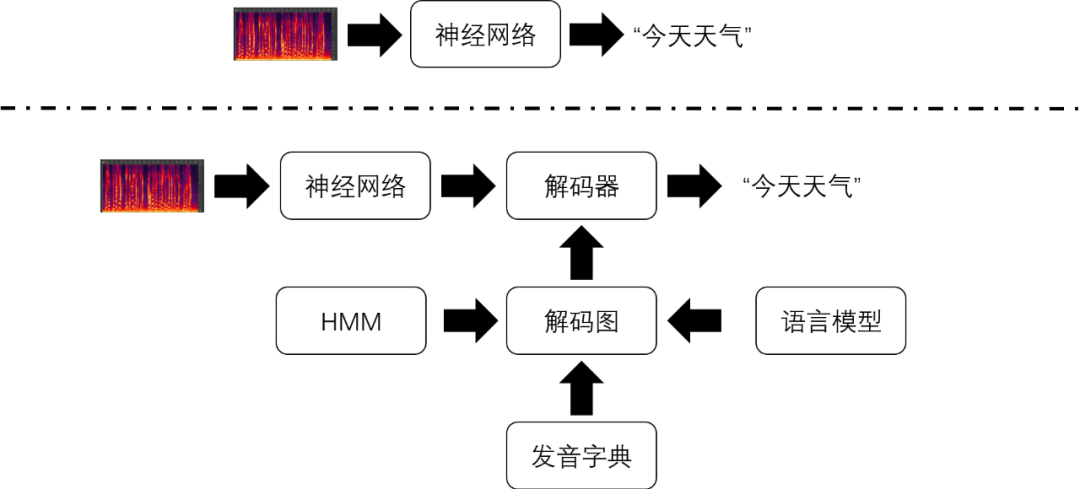
在传统的语音识别技术中,实现声学特征到文本的转换相对复杂很多。在传统的语音识别系统中也存在一个神经网络模型。虽然它的输入也是声学特征,但它的输出代表的是比字符或者词语更加细粒度的语音单位(比如,音素的状态)。解码器无法单独使用神经网络的输出进行解码,还需要结合由隐马尔科夫模型(HMM),发音词典和语言模型构成的解码图才能解码得到识别结果。其中,HMM实现对音素的建模;发音词典包含了所有词语的发音,每个发音由多个音素表示;语言模型则对词语之间连接的概率进行建模。
三、端到端语音识别技术相比混合系统的优势是哪些- 建模单元是基于字,更能适应不同的口音语调
- 能结合语音合成的原始文本作为上文
- 更容易在轻量级的设备端上部署
- 训练耗时更短,更有利于快速迭代
四、端到端语音识别工具,推荐使用wenet
如果追求实时率,可能还是kaldi更猛些五、语音识别流程
语音识别的主要任务在于从语音到文本 其处理流程主要分为三个部分:特征提取:将语音信号转化为特征向量,代表有mfcc和i-vector
声学模型:衡量语音特征和文本之间的距离,判断该语音听起来像什么
语言模型:结合先验知识对声学模型的识别结果进行评价,判断识别结果像不像人话
其中声学模型是研究的主体根据原理,声学模型可分为三个框架:HMM、CTC和LAS
六、HMM+GMM
HMM+GMM是传统语音识别的核心,至今仍有深远影响 在使用HMM+GMM进行声学模型的解码之前,要做三件事:将语音信号转化为特征帧序列
语音信号的会以10ms-20ms为间隔分割为若干帧,每一帧通过信号处理方法转化为特征向量- 训练HMM模型
人为对语音的状态建模,比如三音素模型,即以音素为单元进行建模,每个音素包含三个子状态 HMM模型描述了子状态间的转化概率,训练的过程就是通过数据确定这些概率的过程
- 训练GMM模型
GMM模型度量语音帧和HMM模型中状态间的距离
HMM+GMM模型的目的是求解P(x|o), 其中x是给定的语音信号,o是语音识别的结果 (传统的语音识别模型是一个生成式模型,声学模型负责求解P(x|o),语言模型负责求解P(o))求解过程也分为三个步骤:
将特征帧序列和HMM状态进行对齐
根据对齐方式,通过GMM模型计算发射概率
根据发射概率,通过HMM模型计算特定对齐状态a下的P(x|o,a)
对所有对齐方式的P(x|o,a)求和,就得到总的后验概率 选取P(x|o)最大的o,就得到了识别的结果

该框架主要分为3个模型:声学模型、发音模型和语言模型。其中,声学模型建模语音特征向量与音素概率之间的联系;发音模型以发音字典的形式存在,建模音素与单词之间的对应关系;语言模型对句子中单词与单词之间相互关联的概率进行建模.声学模型其实就是可以识别单个音素的模型(音素a的模型可以判定一小段语音是否是a);语言模型表示一个个词串(如何结合了词典,就可以成为一个个音素串)它们在语料库中出现的概率大小(比如,不合语法的词串(句子)概率接近0,很合乎语法的词串概率大);解码器就是基于Viterbi算法在HMM模型上搜索生成给定观测值序列(待识别语音的声学特征)概率最大的HMM状态序列,再由HMM状态序列获取对应的词序列,得到结果结果。如果你只做单个音素识别,(语音很短,内容只是音素),那么只用声学模型就可以做到,不用语言模型。做法就是在每个音素的声学模型上使用解码器做解码(简单的Viterbi算法即可)。但是,通常是要识别一个比较长的语音,这段语音中包含了很多词。这就需要把所有可能的词串,结合词典展开为音素串,再跟音素的声学模型结合,可以得到解码图(实际上可以看成很多很多HMM模型连接而成),然后在这个解码图上实施Viterbi算法,得到最佳序列,进而得到识别结果。
参考文献:
- https://www.msra.cn/zh-cn/news/features/e2e-asr-paper-list
- https://www.modb.pro/db/179668
- https://www.zhihu.com/question/274765693
-
相关阅读:
学会编程, 而不是学会Java
P1226 【模板】快速幂
计算机网络知识点(七)
Redis缓存更新策略、详解并发条件下数据库与缓存的一致性问题以及消息队列解决方案
DAY04 HTML&CSS
C#:计算机视觉与OpenCV 的目标
C#泛型
Java多线程设计模式之保护性暂挂模式
ASP.NET-Server.UrlEncode
1254. 统计封闭岛屿的数目
- 原文地址:https://blog.csdn.net/zh515858237/article/details/125410072