-
python-线程池的使用
1.场景和需求:
有一个接口,里面做了获取数据和更新的操作,非常耗时,一条数据需要花费1秒钟
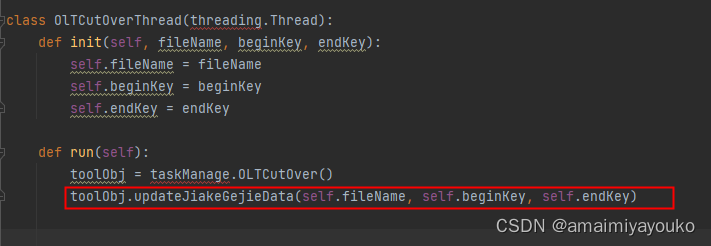
检查updateJiakeGejieData这个接口,里面有一段for循环操作,需要一条一条读取数据并更新
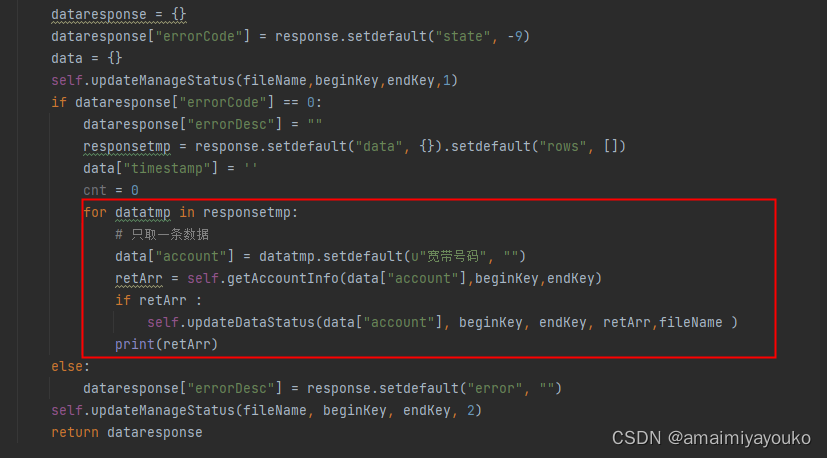
再检查getAccountInfo这个接口,发现里面请求了4条url,耗时操作就发生在这里2.解决办法
现网的代码是python2.7的,用线程池来解决此问题
下面展示一些代码片。for datatmp in responsetmp: # 只取一条数据 data["account"] = datatmp.setdefault(u"宽带号码", "") retArr = self.getAccountInfo(data["account"],beginKey,endKey) if retArr : self.updateDataStatus(data["account"], beginKey, endKey, retArr,fileName ) print(retArr)- 1
- 2
- 3
- 4
- 5
- 6
- 7
把这个代码块,放到线程池里
3.线程池代码
导包// An highlighted block import multiprocessing- 1
- 2
查询运行的服务器核数:
cpu_count = multiprocessing.cpu_count()- 1
启动线程池
pool = multiprocessing.Pool(processes=cpu_count)- 1
调用apply_async方法
cpu_count = multiprocessing.cpu_count() pool = multiprocessing.Pool(processes=cpu_count) time1 = time.time() result = [] for datatmp in responsetmp: result.append(pool.apply_async(run, args=(datatmp, data))) pool.close() pool.join()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
说明:apply_async里的几个参数,第一个run是我想用线程池运行的函数名,
args里面放入run方法里面想要用的参数,最后不要忘记close()和join()
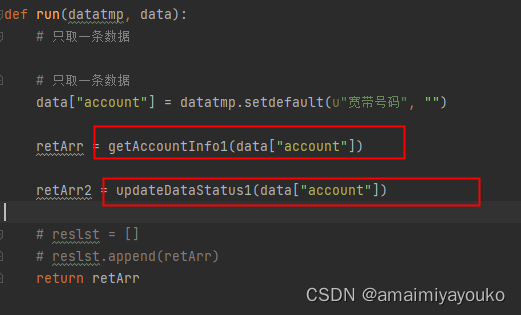
然后run方法里,是对之前getAccountInfo接口和updateDataStatus接口的调用,直接封装到了run里,这里如果打印result列表,会发现里面都是一条条的ApplyResul对象
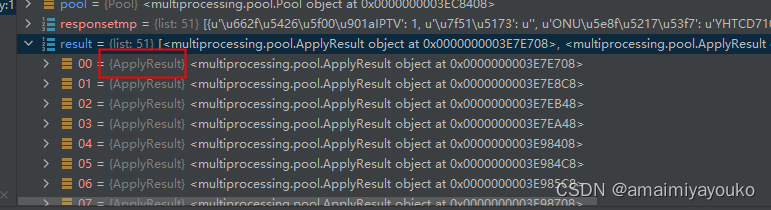
如果不用关心过程,那么线程池的介绍到此就结束了,因为我们没有改动原来的代码,只是在原来的代码块外面加了个线程池,实测也确实提高了运行速度,之前查找更新114条数据花费了110多秒,现在只需要20多秒就能完成4.其他需求
但是有时候想要获取线程池里的结果怎么办呢,因为我们上面的代码的updateDataStatus的接口,是一条条的更新的,现在想获取完了,存到列表里,最后一起更新,这种就需要对线程池里的对象做回调操作了.
可以使用 线程池对象.get() ,获取线程池里return的结果。cpu_count = multiprocessing.cpu_count() pool = multiprocessing.Pool(processes=cpu_count) time1 = time.time() result = [] for datatmp in responsetmp: result.append(pool.apply_async(run, args=(datatmp, data))) pool.close() pool.join() time2 = time.time() l = len(result) i = 0 for datatmp in responsetmp: data["account"] = datatmp.setdefault(u"宽带号码", "") if i < l: # 获取线程池里的每条线程的参数 a = result[i].get() print a retArr2 = updateDataStatus1(data["account"]) i += 1 print("time consume {}".format(time2 - time1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
更新和获取的接口做了简化,实际上很复杂,就不展示了
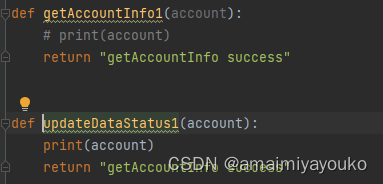
5.总结
线程池用法本身不难,就是传参的地方要小心,
对线程池对象的回调,使用get()就好6.遇到的坑:
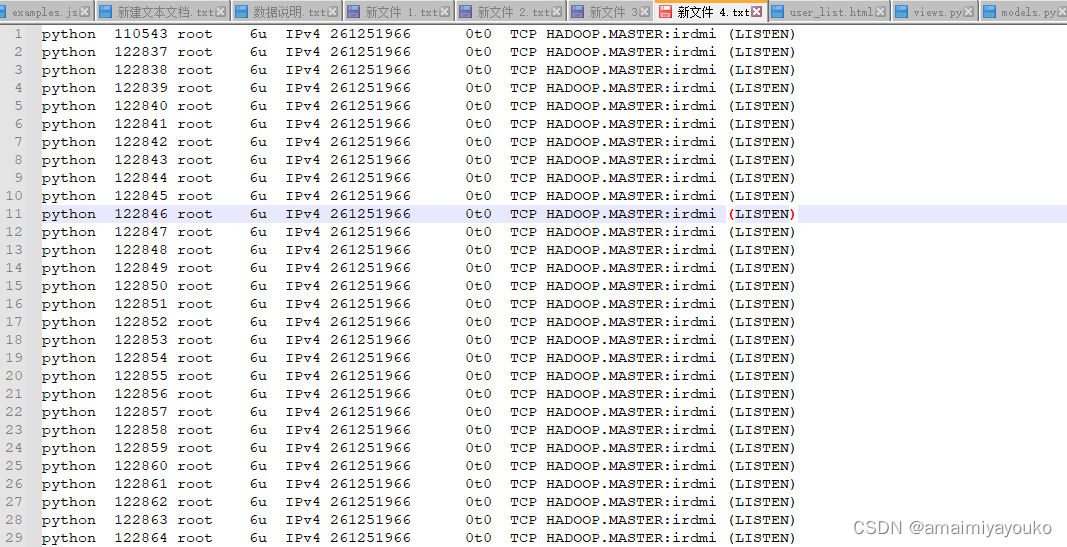
用django启动工程后,如果中间报错,按ctrl+c后,可能会产生一大堆python的进程出来,差不多好几百个端口被占用了,猜测是上面开的那个线程池的原因,我遇到过两次了,不知道咋解决,只能先写了个shell脚本,把占用的端口号复制出来,然后kill -9 端口号
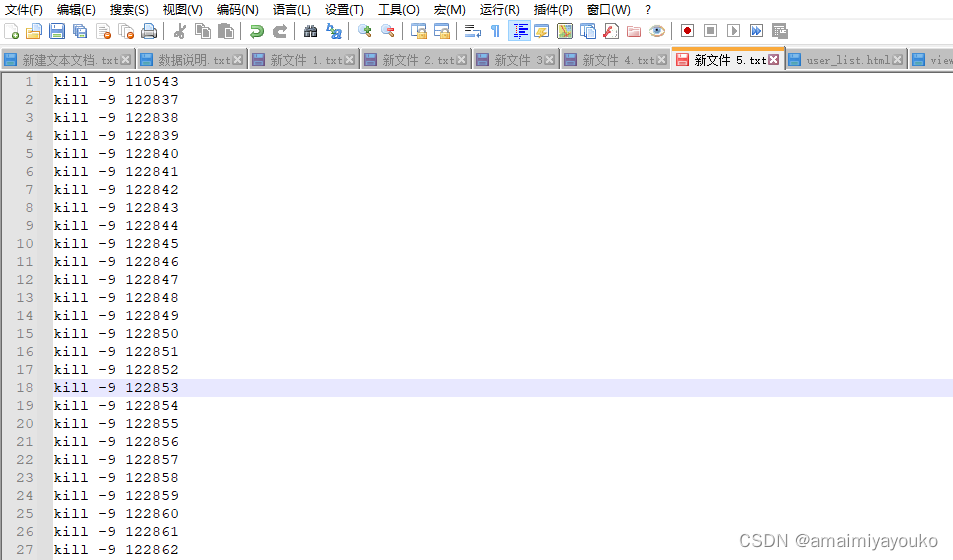
最后再运行shell脚本杀死这些占用大批量端口号被占用:
写个shell一起杀掉
-
相关阅读:
坑爹的jack-server
相机拍照不清晰怎么回事?不清晰地照片还能修复高清吗?
Java --- Spring6对IoC的实现
c语言运算符优先级问题
四十一、django框架简介
uniapp小程序定位;解决调试可以,发布不行的问题
Qt_C++读取RFID卡号支持Windows统信麒麟国产Linux系统
linux 应急响应工具整理列表
基于Python仓库管理系统的设计与实现django框架
无纸化时代,企业复杂庞大的表格信息如何快速提取?光学控件LEADTOOLS轻松搞定
- 原文地址:https://blog.csdn.net/amamiyayouko/article/details/125411431