-
Redis脑裂现象
Redis脑裂现象
什么是Redis的脑裂现象
当Redis主从集群环境出现两个主节点为客户端提供服务,这时客户端请求命令可能会发生数据丢失的情况。
脑裂出现的场景
场景一
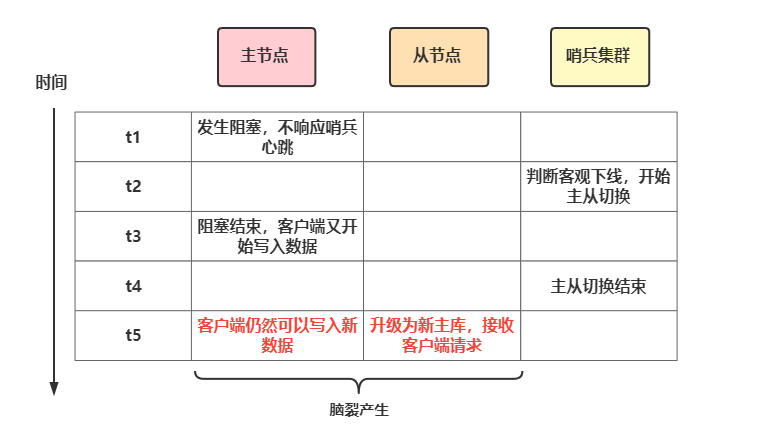
主从哨兵集群中如果当发生主从集群切换时,那么一定是超过预设quorum数量的哨兵和主库连接超时了,这时哨兵集群才会将主库判断为客观下线,然后哨兵开始选举新的主节点,进行故障转移,转移完毕后客户端和新的主节点通信恢复正常请求。
如果在哨兵进行选举,故障转移的过程中原主节点恢复和客户端的通信,那么证明原主节点没有真正的故障,这时客户端依旧可以向原主节点正常通信,这就是脑裂产生的第一个场景,示意图如下
假故障:
1、同服务器其它进程占用大量CPU资源,导致主节点短时间无法响应心跳,CPU资源空闲后恢复正常。
2、主库自身阻塞,如处理bigkey或者发生内存swap时,短时间无法响应心跳,阻塞解决后心跳恢复正常。
真故障:
1、服务器宕机。
2、实例进程挂了。
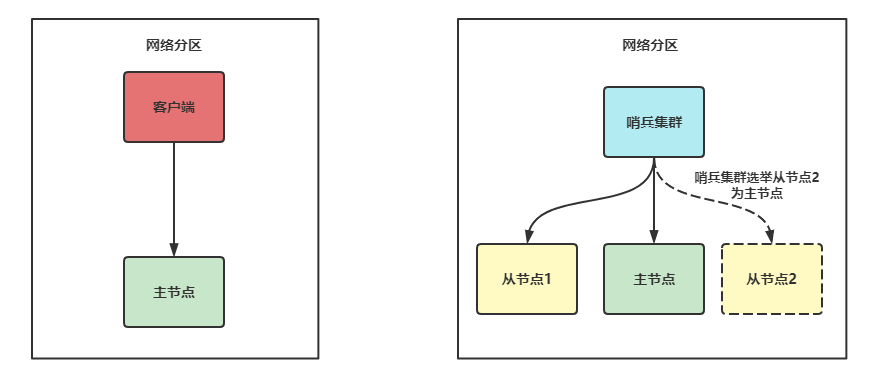
场景二
网络分区,主节点和客户端,哨兵和从库分割为了两个网络,主库和客户端处在一个网络中,从库和哨兵在另外一个网络中,此时哨兵也会发起主从切换,出现两个主节点的情况。
脑裂带来的影响
脑裂出现后带来最严重的后果就是数据丢失,为什么会出现数据丢失的问题呢,主要原因是新主库确定后会向所有的实例发送slave of命令,让所有实例重新进行全量同步,而全量同步首先就会将实例上的数据先清空,所以在主从同步期间在原主库执行的命令将会被清空(上面场景二是同样的道理,在网络分区恢复后原主节点将被降级为从节点,并且执行全量同步导致数据丢失),所以这就是数据丢失的具体原因。

如何应对脑裂
脑裂的主要原因其实就是哨兵集群认为主节点已经出现故障了,重新选举其它从节点作为主节点,而原主节点其实是假故障,从而导致短暂的出现两个主节点,那么在主从切换期间客户端一旦给原主节点发送命令,就会造成数据丢失。
所以应对脑裂的解决办法应该是去限制原主库接收请求,Redis提供了两个配置项。
-
min-slaves-to-write:与主节点通信的从节点数量必须大于等于该值主节点,否则主节点拒绝写入。
-
min-slaves-max-lag:主节点与从节点通信的ACK消息延迟必须小于该值,否则主节点拒绝写入。
这两个配置项必须同时满足,不然主节点拒绝写入。
在假故障期间满足min-slaves-to-write和min-slaves-max-lag的要求,那么主节点就会被禁止写入,脑裂造成的数据丢失情况自然也就解决了。
脑裂可以完全解决吗
通过上面的学习我们知道了脑裂出现的场景,带来的问题,以及解决办法,那么脑裂问题可以完全被解决吗?我们直接看下面的场景
为了防止脑裂我们将min-slaves-to-write设置为1,min-slaves-max-lag设置为12s,down-after-milliseconds哨兵判断主节点客观下线的限制为10s,主节点因为某些原因卡住了15s,导致哨兵集群判断主节点为主观下线,主从切换,因为没有一个从节点与主节点之间的数据复制在12s内,这样就规避脑裂的情况。
但是我们再看另外一个场景
我们同样将min-slaves-to-write设置为1,min-slaves-max-lag 设置为 15s,down-after-milliseconds哨兵判断主节点客观下线的限制为10s,哨兵主从切换需要 5s。主节点因为某些原因卡住了 12s,这时还会发生脑裂吗?
主节点卡住12s这时哨兵集群判断主节点下线,同时哨兵集群做主从切换需要5s,这就意味着主从切换过程中,主节点恢复运行,而min-slaves-max-lag设置为15s那么主节点还是可写,也就是说在12s~15s这期间如果有客户端写入原主节点,那么这段时间的数据会丢失。
总结
Redis脑裂可以采用min-slaves-to-write和min-slaves-max-lag合理配置尽量规避,但无法彻底解决,Redis脑裂最本质的问题是主从集群内部没有共识算法来维护多个节点的强一致性,它不像Zookeeper那样,每次写入必须大多数节点成功后才算成功,当脑裂发生时,Zookeeper节点被孤立,此时无法写入大多数节点,写请求会直接失败,因此Zookeeper才能保证集群的强一致性。
-
-
相关阅读:
9.15c++基础
【Prometheus】基于Altertmanager发送告警到多个接收方、监控各种服务、pushgateway
选择排序算法的速度测试 [数据结构][Java]
【PyCharm Community Edition】:PCAN-USB上位机开发
软件测试不是所有人都适合的
Android Camera性能分析 - 第26讲 DequeueBuffer Latency
【flask+python】利用魔术方法,更优雅的封装model类
JAVA-Map接口概述、常用方法、排序、Hashtable面试题
分享使用百度EasyDL实现安全帽智能识别
聊聊Spring中最常用的11个扩展点
- 原文地址:https://blog.csdn.net/zzf1233/article/details/125288605