-
Kubernetes带你从头到尾捋一遍
k8s技术实践
为什么要学习 Kubernetes?
虽然 Docker 已经很强大了,但是在实际使用上还是有诸多不便,比如集群管理、资源调度、文件管理等等。
kubernetes 介绍
Kubernetes 解决的核心问题
- 服务发现和负载均衡
- Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果到容器的流量很大,Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
- 存储编排
- Kubernetes 允许您自动挂载您选择的存储系统,例如本地存储、公共云提供商等。
- 自动部署和回滚
- 您可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态更改为所需状态。例如,您可以自动化 Kubernetes 来为您的部署创建新容器,删除现有容器并将它们的所有资源用于新容器。
- 自动二进制打包
- Kubernetes 允许您指定每个容器所需 CPU 和内存(RAM)。当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。
- 自我修复
- Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。
- 密钥与配置管理
- Kubernetes 允许您存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。您可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
Kubernetes 的出现不仅主宰了容器编排的市场,更改变了过去的运维方式,不仅将开发与运维之间边界变得更加模糊,而且让 DevOps 这一角色变得更加清晰,每一个软件工程师都可以通过 Kubernetes 来定义服务之间的拓扑关系、线上的节点个数、资源使用量并且能够快速实现水平扩容、蓝绿部署等在过去复杂的运维操作。
Kubernetes 知识图谱

Kubernetes 软件架构
架构说明
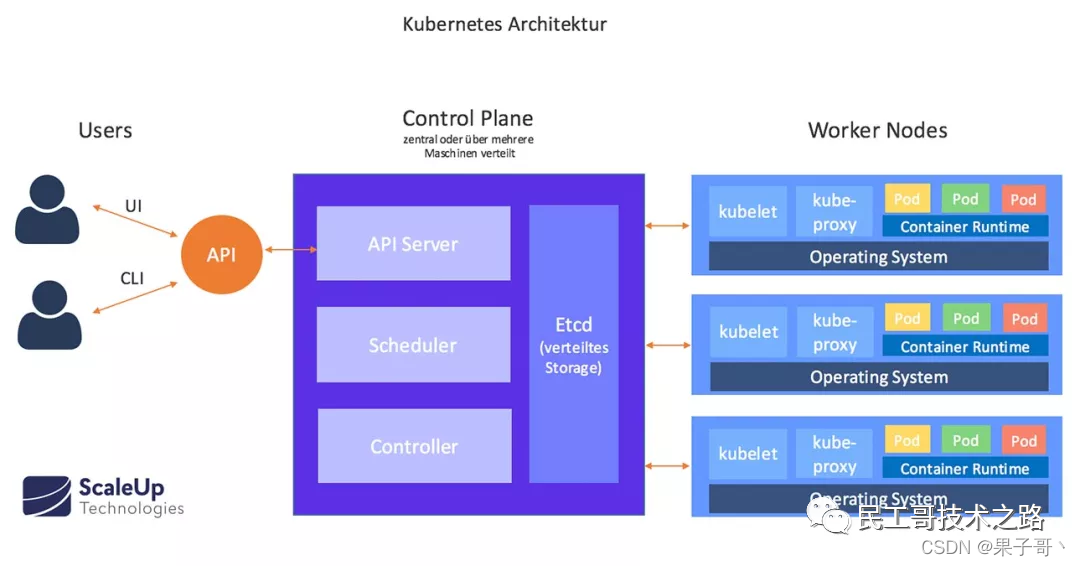
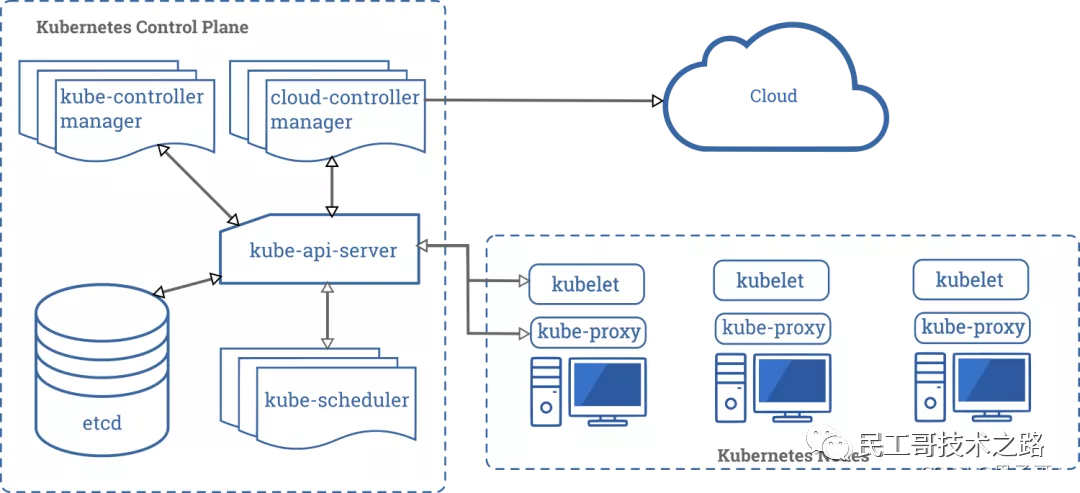
Kubernetes 遵循非常传统的客户端/服务端的架构模式,客户端可以通过 RESTful 接口或者直接使用 kubectl 与 Kubernetes 集群进行通信,这两者在实际上并没有太多的区别,后者也只是对 Kubernetes 提供的 RESTful API 进行封装并提供出来。每一个 Kubernetes 集群都是由一组 Master 节点和一系列的 Worker 节点组成,其中 Master 节点主要负责存储集群的状态并为 Kubernetes 对象分配和调度资源。
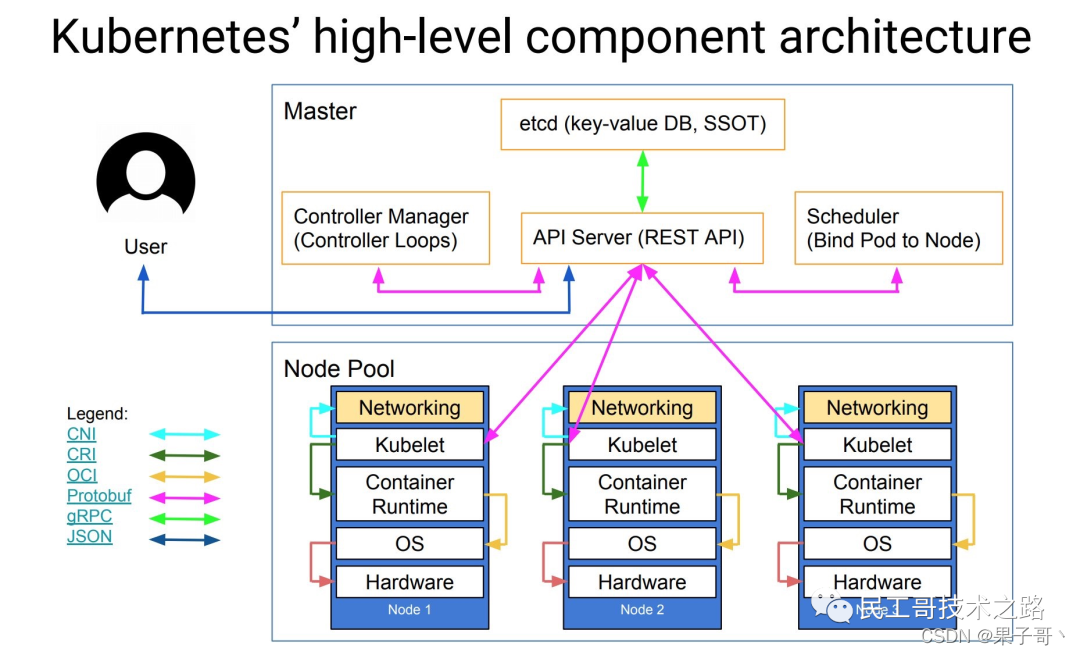
主节点服务 - Master 架构
作为管理集群状态的 Master 节点,它主要负责接收客户端的请求,安排容器的执行并且运行控制循环,将集群的状态向目标状态进行迁移。Master 节点内部由下面三个组件构成:- API Server: 负责处理来自用户的请求,其主要作用就是对外提供 RESTful 的接口,包括用于查看集群状态的读请求以及改变集群状态的写请求,也是唯一一个与 etcd 集群通信的组件。
- etcd: 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
- Scheduler: 主节点上的组件,该组件监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行。调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
- controller-manager: 在主节点上运行控制器的组件,从逻辑上讲,每个控制器都是一个单独的进程,但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。这些控制器包括:节点控制器(负责在节点出现故障时进行通知和响应)、副本控制器(负责为系统中的每个副本控制器对象维护正确数量的 Pod)、端点控制器(填充端点 Endpoints 对象,即加入 Service 与 Pod))、服务帐户和令牌控制器(为新的命名空间创建默认帐户和 API 访问令牌)。
工作节点 - Node 架构
Worker 节点实现就相对比较简单了,它主要由 kubelet 和 kube-proxy 两部分组成。- kubelet: 是工作节点执行操作的 agent,负责具体的容器生命周期管理,根据从数据库中获取的信息来管理容器,并上报 pod 运行状态等。
- kube-proxy: 是一个简单的网络访问代理,同时也是一个 Load Balancer。它负责将访问到某个服务的请求具体分配给工作节点上同一类标签的 Pod。kube-proxy 实质就是通过操作防火墙规则(iptables或者ipvs)来实现 Pod 的映射。
- Container Runtime: 容器运行环境是负责运行容器的软件,Kubernetes 支持多个容器运行环境: Docker、 containerd、cri-o、 rktlet 以及任何实现 Kubernetes CRI(容器运行环境接口)。
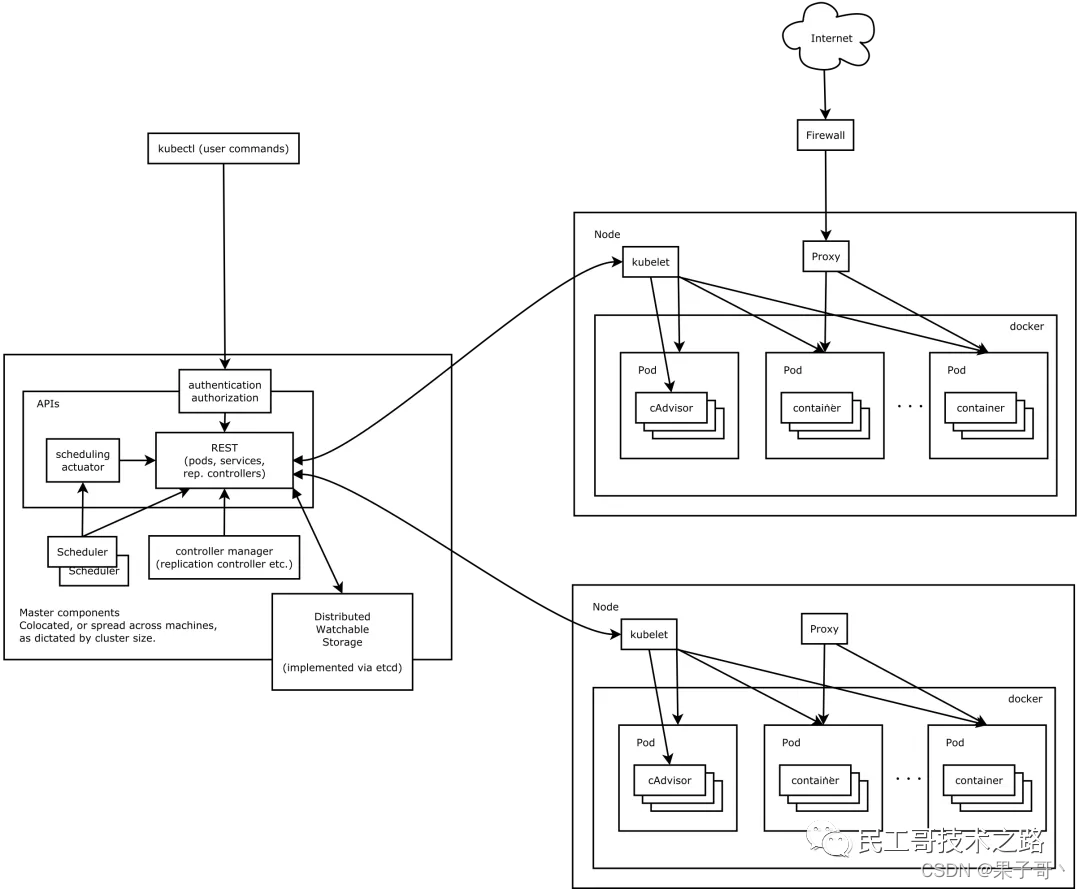
主要由以下几个核心组件组成:- apiserver
所有服务访问的唯一入口,提供认证、授权、访问控制、API 注册和发现等机制 - controller manager
负责维护集群的状态,比如副本期望数量、故障检测、自动扩展、滚动更新等 - scheduler
负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上 - etcd
键值对数据库,保存了整个集群的状态 - kubelet
负责维护容器的生命周期,同时也负责 Volume 和网络的管理 - kube-proxy
负责为 Service 提供 cluster 内部的服务发现和负载均衡 - Container runtime
负责镜像管理以及 Pod 和容器的真正运行
除了核心组件,还有一些推荐的插件:
- CoreDNS
可以为集群中的 SVC 创建一个域名 IP 的对应关系解析的 DNS 服务 - Dashboard
给 K8s 集群提供了一个 B/S 架构的访问入口 - Ingress Controller
官方只能够实现四层的网络代理,而 Ingress 可以实现七层的代理 - Prometheus
给 K8s 集群提供资源监控的能力 - Federation
提供一个可以跨集群中心多 K8s 的统一管理功能,提供跨可用区的集群
❤Kubernetes安装
安装v1.16.0版本,竟然成功了。记录在此,避免后来者踩坑。
本章节,安装大步骤如下:
安装docker-ce 18.09.9(所有机器)
设置k8s环境前置条件(所有机器)
安装k8s v1.16.0 master管理节点
安装k8s v1.16.0 node工作节点
安装flannel(master)
详细安装步骤参考:CentOS 搭建 K8S,一次性成功,收藏了!集群安装教程请参考:全网最新、最详细基于V1.20版本,无坑部署最小化 K8S 集群教程
Kubernetes Pod实现原理
Pod 就是最小并且最简单的 Kubernetes 对象
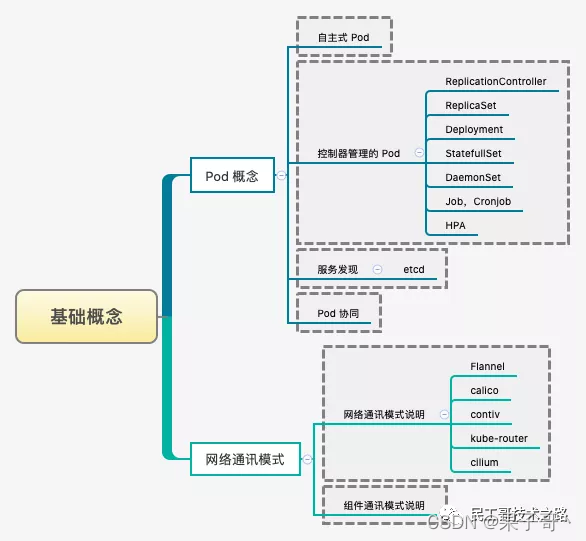
Pod、Service、Volume 和 Namespace 是 Kubernetes 集群中四大基本对象,它们能够表示系统中部署的应用、工作负载、网络和磁盘资源,共同定义了集群的状态。Kubernetes 中很多其他的资源其实只对这些基本的对象进行了组合。- Pod -> 集群中的基本单元
- Service -> 解决如何访问 Pod 里面服务的问题
- Volume -> 集群中的存储卷
- Namespace -> 命名空间为集群提供虚拟的隔离作用
详细介绍请参考:Kubernetes 之 Pod 实现原理
Kubernetes 之 Pod 实现原理
https://mp.weixin.qq.com/s?__biz=MzI0MDQ4MTM5NQ==&mid=2247511562&idx=2&sn=cc8aa9ddbf373a41af579186cd889574&chksm=e918cb16de6f42003fe7d8fdc623c246daf2beff249166e225e6fb5c045c88bd82d24f7673d7&cur_album_id=1790241575034290179&scene=21#wechat_redirect
Harbor仓库
Kuternetes 企业级 Docker 私有仓库 Harbor 工具。
Harbor 的每个组件都是以 Docker 容器的形式构建的,使用 Docker Compose 来对它进行部署。用于部署 Harbor 的 Docker Compose 模板位于 /Deployer/docker-compose.yml 中,其由 5 个容器组成,这几个容器通过 Docker link 的形式连接在一起,在容器之间通过容器名字互相访问。对终端用户而言,只需要暴露 Proxy(即Nginx) 的服务端口即可。
- Proxy
- 由Nginx服务器构成的反向代理
- Registry
- 由Docker官方的开源官方的开源Registry镜像构成的容器实例
- UI
- 即架构中的core services服务,构成此容器的代码是Harbor项目的主体
- MySQL
- 由官方MySQL镜像构成的数据库容器
- Log
- 运行着rsyslogd的容器,通过log-driver的形式收集其他容器的日志
详细介绍与搭建步骤请参考:企业级环境中基于 Harbor 搭建
企业级环境中基于 Harbor 搭建
https://mp.weixin.qq.com/s?__biz=MzI0MDQ4MTM5NQ==&mid=2247512177&idx=2&sn=e14e94410df53c74e99aac958a9b5658&chksm=e918d56dde6f5c7bc9ff13c39f6c8add6398babe3cdeb188bf38fd7be6a3ca527f53e11d3472&scene=21&cur_album_id=1790241575034290179#wechat_redirect
❤K8s服务发现
Kubernetes 中为了实现服务实例间的负载均衡和不同服务间的服务发现,创造了 Service 对象,同时又为从集群外部访问集群创建了 Ingress 对象。
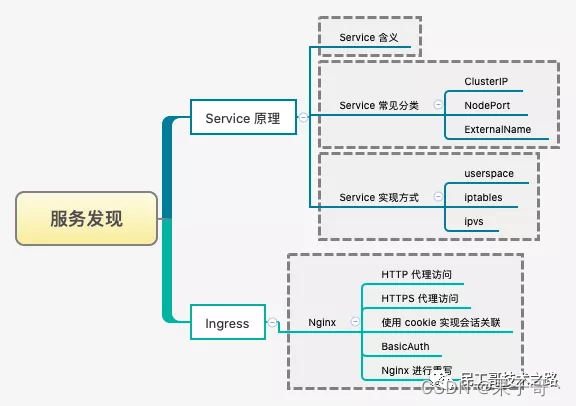
可参考:Kubernetes 之服务发现Kubernetes 中为了实现服务实例间的负载均衡和不同服务间的服务发现,创造了 Service 对象,同时又为从集群外部访问集群创建了 Ingress 对象。
Service服务
Service 在 K8S 中有以下四种类型

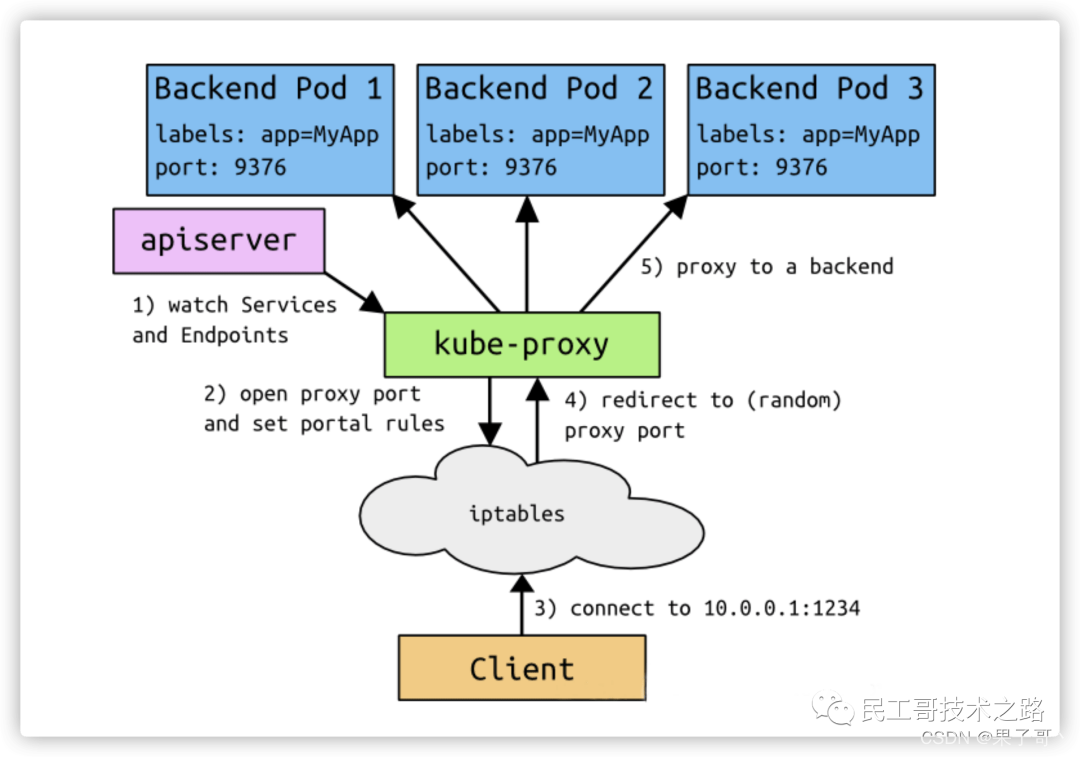
VIP(虚拟 IP 地址)和 Service 代理
- 在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟IP)的形式,而不是 ExternalName 的形式。
- 在 Kubernetes v1.0 版本,代理完全在 userspace。在 Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。从 Kubernetes v1.2 起,默认就是,iptables 代理。在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理。
- 在 Kubernetes 1.14 版本开始默认使用 ipvs 代理。在 Kubernetes v1.0 版本,Service 是 “4 层”(TCP/UDP over IP)概念。在 Kubernetes v1.1 版本,新增了 Ingress API(beta版),用来表示 “7 层”(HTTP)服务。
注意,ipvs 模式假定在运行 kube-proxy 之前的节点上都已经安装了 IPVS 内核模块。当 kube-proxy 以 ipvs 代理模式启动时,kube-proxy 将验证节点上是否安装了 IPVS 模块。如果未安装的话,则 kube-proxy 将回退到 iptables 的代理模式。
为什么不适用 Round-robin DNS 的形式进行负载均衡呢?
- 熟悉 DNS 的话,都知道 DNS 会在客户端进行缓存。当后端服务发生变动的话,我们是无法得到最新的地址的,从而无法达到负载均衡的作用了。
代理模式
使用 iptables代理模式
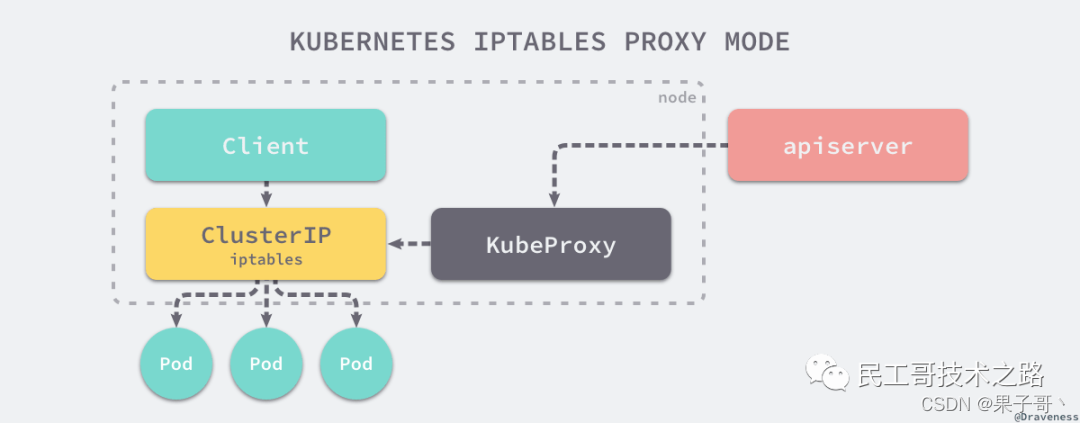
使用 ipvs 代理模式
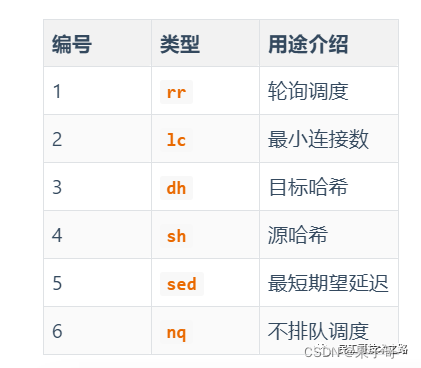
这种模式,kube-proxy 会监视 Kubernetes Service 对象和 Endpoints,调用 netlink 接口以相应地创建 ipvs 规则并定期与 Kubernetes Service 对象和 Endpoints 对象同步 ipvs 规则,以确保 ipvs 状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod。与 iptables 类似,ipvs 于 netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 ipvs 可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs 为负载均衡算法提供了更多选项,例如:
# 启动服务 $ kubectl create -f myapp-deploy.yaml $ kubectl create -f myapp-service.yaml # 查看SVC服务 $ ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 10.96.0.1:443 rr -> 192.168.66.10:6443 Masq 1 0 0 # 查看对应的IPVS防火墙规则 $ kubectl get svc -n default NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 125d- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
ClusterIP
ClusterIP 主要在每个 node 节点使用 ipvs/iptables,将发向 ClusterIP 对应端口的数据,转发到 kube-proxy 中。然后 kube-proxy 自己内部实现有负载均衡的方法,并可以查询到这个 Service 下对应 pod 的地址和端口,进而把数据转发给对应的 pod 的地址和端口。
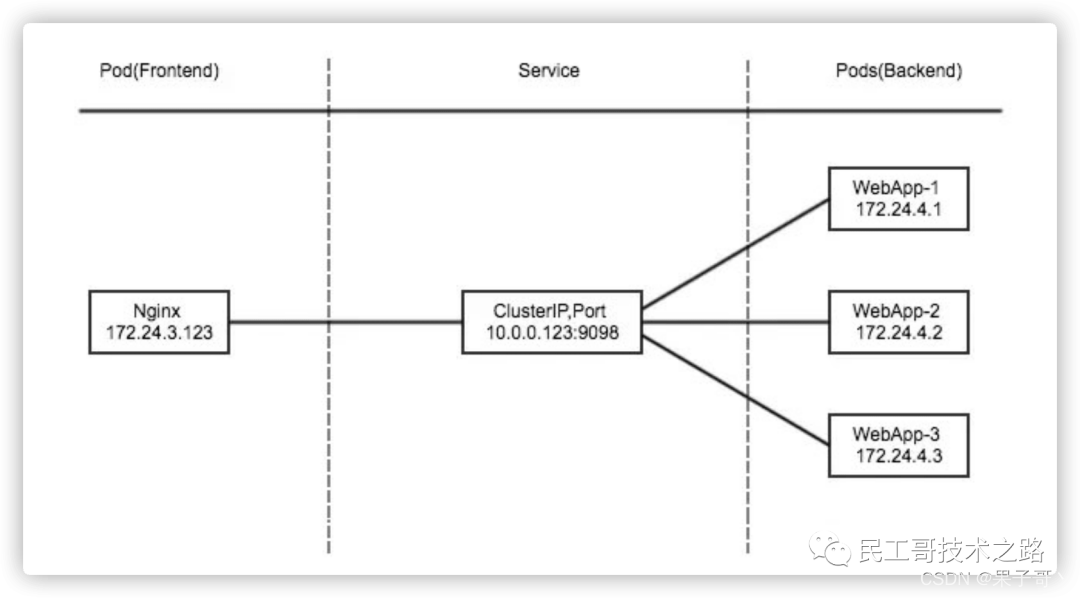
为了实现图上的功能,主要需要以下几个组件的协同工作:- apiserver 用户通过 kubectl命令向 apiserver 发送创建 service 的命令,apiserver 接收到请求后将数据存储到 etcd 中。
- kube-proxy 在 kubernetes 的每个节点中都有一个叫做 kube-porxy 的进程,这个进程负责感知 service 和 pod 的变化,并将变化的信息写入本地的 ipvs/iptables 规则中。
- ipvs/iptables 使用 NAT 等技术将 VirtualIP 的流量转至 endpoint 中。
对应配置文件,如下所示:
myapp-deploy.yaml# myapp-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: myapp-deploy namespace: default spec: replicas: 3 selector: matchLabels: app: myapp release: stabel template: metadata: labels: app: myapp release: stabel env: test spec: containers: - name: myapp image: escape/nginx:v2 imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
-
正确的Deployment书写方式,是要让spec.selector.matchLabels值和spec.template.metadata.lables值完全匹配,这样才不会报错。
-
在定义pod模板时,必须定义spec.template.metadata.lables,因为spec.selector.matchLabels是必须字段,而它又必须和spec.template.metadata.lables的键值一致
myapp-service.yaml
apiVersion: apps/v1 kind: Service metadata: name: myapp namespace: default spec: type: ClusterIP selector: app: myapp release: stabel ports: - name: http port: 80 targetPort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
启动服务之后,可以查到对应的防火墙规则和默认的 SVC 服务。
# 启动服务 $ kubectl create -f myapp-deploy.yaml $ kubectl create -f myapp-service.yaml # 查看SVC服务 $ kubectl get svc -n default NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 125d myapp ClusterIP 10.99.10.103 <none> 80/TCP 12s # 查看POD服务 $ kubectl get pod -n default NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myapp-deploy-5cxxc8c94-4fb9g 1/1 Running 0 18s 10.244.1.66 k8s-node01 <none> <none> myapp-deploy-ddxx88794-r5qgw 1/1 Running 0 18s 10.244.1.68 k8s-node01 <none> <none> myapp-deploy-68xxfd677-5q4s2 1/1 Running 0 18s 10.244.1.69 k8s-node01 <none> <none> # 查看对应的IPVS防火墙规则 $ ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 10.99.10.103:80 rr -> 10.244.1.66:80 Masq 1 0 0 -> 10.244.1.68:80 Masq 1 0 0 -> 10.244.1.69:80 Masq 1 0 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
Headless:
有时不需要或不想要负载均衡,以及单独的 Service IP。遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP) 的值为 “None” 来创建 Headless Service。这类 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由。
Headless Services 应用场景- 第一种:自主选择权,有时候 client 想自己来决定使用哪个Real Server,可以通过查询DNS来获取 Real Server 的信息。
- 第二种:Headless Service 的对应的每一个 Endpoints,即每一个Pod,都会有对应的DNS域名,这样Pod之间就可以互相访问。
# myapp-svc-headless.yaml apiVersion: v1 kind: Service metadata: name: myapp-headless namespace: default spec: selector: app: myapp clusterIP: "None" ports: - port: 80 targetPort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
启动服务之后,可以查到对应的防火墙规则和默认的 SVC 服务。
# 启动服务 $ kubectl create -f myapp-svc-headless.yaml # 查看SVC服务 $ kubectl get svc -n default NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 125d myapp-headless ClusterIP none <none> 80/TCP 19m # 查找K8S上面的DNS服务对应IP地址(任意一个即可) $ kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES coredns-12xxcxc5a-4129z 1/1 Running 3 23h 10.244.0.7 k8s-master01 <none> <none> # 查找对应无头服务的SVC解析的A记录 $ dig -t A myapp-headless.default.svc.cluster.local. @10.244.0.7 ;; ANSWER SECTION: myapp-headless.default.svc.cluster.local. 30 IN A 10.244.1.66 myapp-headless.default.svc.cluster.local. 30 IN A 10.244.1.68 myapp-headless.default.svc.cluster.local. 30 IN A 10.244.1.69- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
NodePort
nodePort 的原理在于在 node 上开了一个端口,将向该端口的流量导入到 kube-proxy,然后由 kube-proxy 进一步到给对应的 pod。
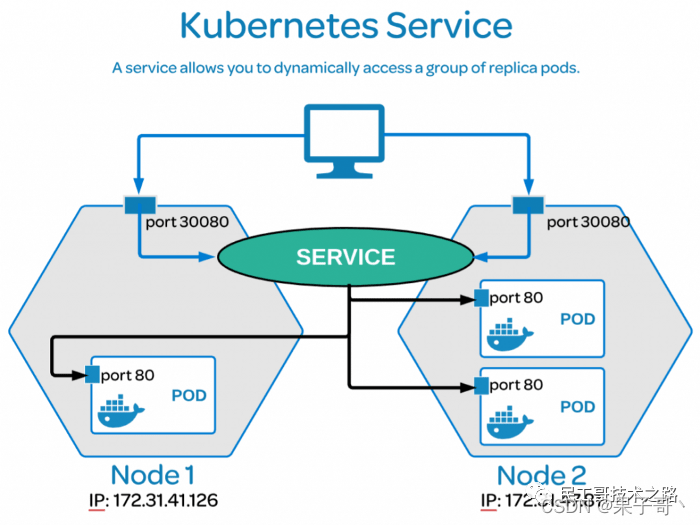
对应配置文件,如下所示:
# myapp-svc-nodeport.yaml apiVersion: v1 kind: Service metadata: name: myapp namespace: default spec: type: NodePort selector: app: myapp release: stabel ports: - name: http port: 80 targetPort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
service的spec.selector.app与deployment的pod名字保持一致
启动服务之后,可以查到对应的防火墙规则和默认的 SVC 服务。# 启动服务 $ kubectl create -f myapp-svc-nodeport.yaml # 查看SVC服务 $ kubectl get svc -n default NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 125d myapp NodePort 10.99.10.103 <none> 80:30715/TCP 1m myapp-headless ClusterIP none <none> 80/TCP 19m # 通过Node的服务器地址访问 $ curl -I http://192.168.66.21:30715 # 查询流程(在Node02上面查询的结果) $ ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.66.21:30715 rr -> 10.244.1.66:80 Masq 1 0 0 -> 10.244.1.68:80 Masq 1 0 0 -> 10.244.1.69:80 Masq 1 0 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
LoadBalancer
loadBalancer 和 nodePort 其实是同一种方式。区别在于 loadBalancer 比 nodePort 多了一步,就是可以调用 cloud provider 去创建 LB 来向节点导流。
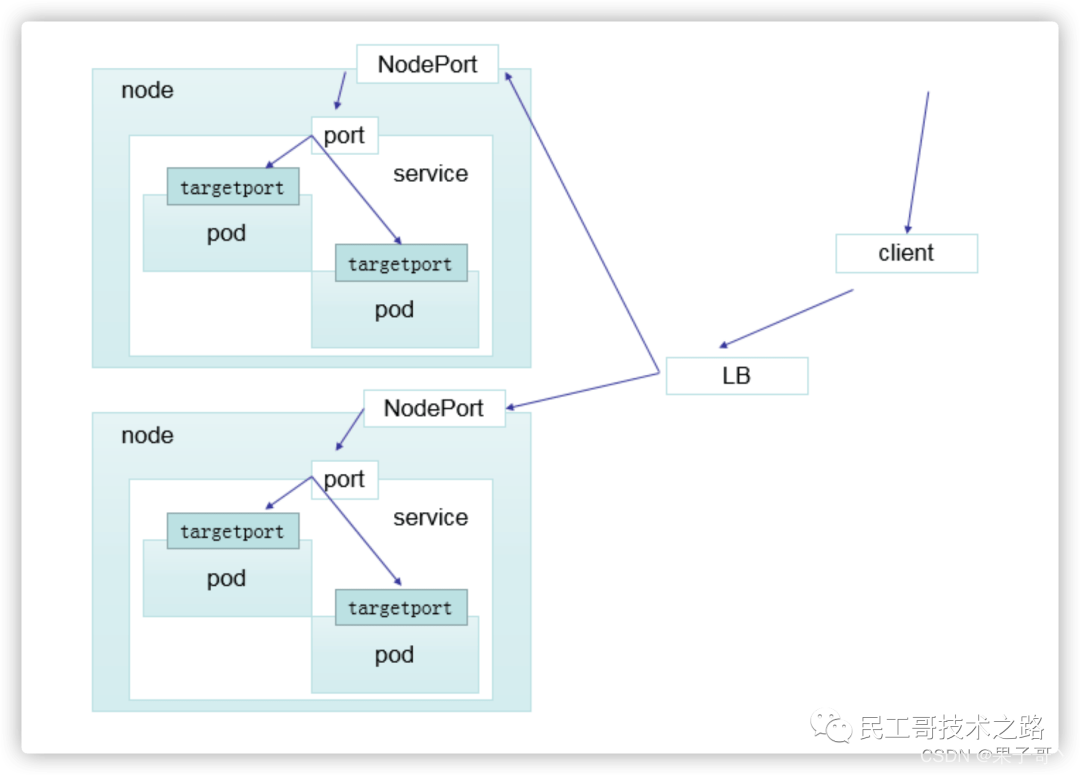
ExternalName
这种类型的 Service 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容,例如:hub.escapelife.site。ExternalName Service是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。当查询主机 my-service.defalut.svc.cluster.local 时,集群的 DNS 服务将返回一个值 hub.escapelife.site 的 CNAME 记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。
对应配置文件,如下所示:
# myapp-svc-externalname.yaml # SVC_NAME.NAMESPACE.svc.cluster.local kind: Service apiVersion: v1 metadata: name: my-service-1 namespace: default spec: type: ExternalName externalName: hub.escapelife.site- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
启动服务之后,可以查到对应的防火墙规则和默认的 SVC 服务。
# 查看SVC服务 $ kubectl get svc -n default NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 125d my-service-1 ExternalName <none> hub.escapelife.site <none> 3m myapp NodePort 10.99.10.103 <none> 80:30715/TCP 24m myapp-headless ClusterIP none <none> 80/TCP 45m # 查找对应无头服务的SVC解析的A记录 $ dig -t A my-service-1.default.svc.cluster.local. @10.244.0.7 ;; ANSWER SECTION: my-service-1.default.svc.cluster.local. 30 IN CNAME hub.escapelife.site- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Ingress服务
https://kubernetes.github.io/ingress-nginx/deploy/
https://github.com/kubernetes/ingress-nginx/blob/main/docs/deploy/index.md
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.2/deploy/static/provider/cloud/deploy.yamlK8s数据存储
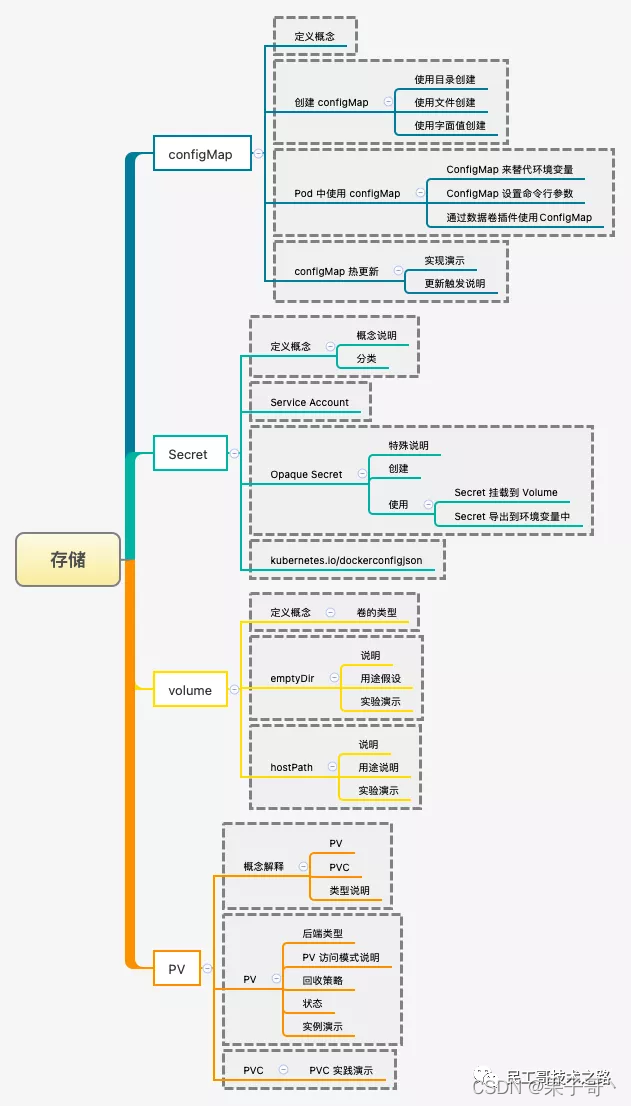
ConfigMap
ConfigMap API 给我们提供了向容器中注入配置信息的机制,ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者 JSON 二进制大对象
ConfigMap的创建
- 使用目录创建
--from-file指定在目录下的所有文件都会用在ConfigMap里面创建一个键值对,键的名字就是文件名,值就是文件的内容。
$ ls docs/user-guide/config-map/kubectl/ game.properties ui.properties # game.properties $ cat docs/user-guide/config-map/kubectl/game.properties enemies=aliens lives= 3 enemies.cheat=true enemies.cheat.level=noGoodRotten secret.code.passphrase=UUDDLRLRBABAS secret.code.allowed=true secret.code.lives= 30 # ui.properties $ cat docs/user-guide/config-map/kubectl/ui.properties color.good=purple color.bad=yellow allow.textmode=true how.nice.to.look=fairlyNice # 创建名称为game-config的ConfigMap配置 $ kubectl create configmap game-config \ --from-file=docs/user-guide/config-map/kubectl # 查看存储的ConfigMap列表 $ kubectl get configmap NAME DATA AGE game-config 2 22s # 查看对应内容 $ kubectl describe configmap game-config $ kubectl get configmap game-config -o yaml- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 使用文件创建
只要指定为一个文件就可以从单个文件中创建 ConfigMap。--from-file这个参数可以使用多次,你可以使用两次分别指定上个实例中的那两个配置文件,效果就跟指定整个目录是一样的。
# 创建名称为game-config-2的ConfigMap配置 $ kubectl create configmap game-config-2 \ --from-file=docs/user-guide/config-map/kubectl/game.properties # 查看存储的ConfigMap列表 $ kubectl get configmap NAME DATA AGE game-config 2 34s game-config-2 1 2s # 查看对应内容 $ kubectl describe configmap game-config-2 $ kubectl get configmap game-config-2 -o yaml- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 使用字面值创建
使用文字值创建,利用--from-literal参数传递配置信息,该参数可以使用多次,格式如下。
# 创建名称为special-config的ConfigMap配置 $ kubectl create configmap special-config \ --from-literal=special.how=very \ --from-literal=special.type=charm # 查看对应内容 $ kubectl get configmaps special-config -o yaml- 1
- 2
- 3
- 4
- 5
- 6
- 7
ConfigMap 的使用
- 使用 ConfigMap 来替代环境变量
apiVersion: v1 kind: ConfigMap metadata: name: special-config namespace: default data: special.how: very special.type: charm yaml apiVersion: v1 kind: ConfigMap metadata: name: env-config namespace: default data: log_level: INFO yaml apiVersion: v1 kind: Pod metadata: name: myapp-test-pod spec: restartPolicy: Never containers: - name: test-container image: hub.escape.com/library/myapp:v1 command: ["/bin/sh", "-c", "env"] env: - name: SPECIAL_LEVEL_KEY valueFrom: configMapKeyRef: name: special-config key: special.how - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-config key: special.type envFrom: - configMapRef: name: env-config- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 用 ConfigMap 设置命令行参数
apiVersion: v1 kind: ConfigMap metadata: name: special-config namespace: default data: special.how: very special.type: charm yaml apiVersion: v1 kind: Pod metadata: name: myapp-test-pod spec: restartPolicy: Never containers: - name: test-container image: hub.escape.com/library/myapp:v1 command: ["/bin/sh", "-c", "echo $(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)"] env: - name: SPECIAL_LEVEL_KEY valueFrom: configMapKeyRef: name: special-config key: special.how - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-config key: special.type- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 通过数据卷插件使用 ConfigMap
在数据卷里面使用这个 ConfigMap,有不同的选项。最基本的就是将文件填入数据卷,在这个文件中,键就是文件名,键值就是文件内容。
apiVersion: v1 kind: ConfigMap metadata: name: special-config namespace: default data: special.how: very special.type: charm yaml apiVersion: v1 kind: Pod metadata: name: myapp-test-pod spec: restartPolicy: Never containers: - name: test-container image: hub.escape.com/library/myapp:v1 command: ["/bin/sh", "-c", "cat /etc/config/special.how"] volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: special-config- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
ConfigMap 热更新
正常情况下,我们可以通过如下配置,在启动的 Pod 容器里面获取到 ConfigMap 中配置的信息。apiVersion: v1 kind: ConfigMap metadata: name: log-config namespace: default data: log_level: INFO --- apiVersion: extensions/v1beta kind: Deployment metadata: name: my-nginx spec: replicas: 1 template: metadata: labels: run: my-nginx spec: containers: - name: my-nginx image: hub.escape.com/library/myapp:v1 ports: - containerPort: 80 volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: log-config- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
# 查找对应信息 $ kubectl exec \ `kubectl get pods -l run=my-nginx -o=name | cut -d "/" -f2` \ cat /etc/config/log_level INFO- 1
- 2
- 3
- 4
- 5
修改 ConfigMap 配置,修改 log_level 的值为 DEBUG 等待大概 10 秒钟时间,再次查看环境变量的值。
# 修改ConfigMap配置 $ kubectl edit configmap log-config # 查找对应信息 $ kubectl exec \ `kubectl get pods -l run=my-nginx -o=name|cut -d "/" -f2` \ cat /etc/config/log_level DEBUG- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
ConfigMap 更新后滚动更新 Pod,更新 ConfigMap 目前并不会触发相关 Pod 的滚动更新,可以通过修改 pod annotations 的方式强制触发滚动更新。这个例子里我们在 .spec.template.metadata.annotations 中添加 version/config,每次通过修改 version/config 来触发滚动更新。
$ kubectl patch deployment my-nginx \ --patch '{"spec": {"template": {"metadata": {"annotations": \ {"version/config": "20190411" }}}}}'- 1
- 2
- 3
更新 ConfigMap 后:
- 使用该 ConfigMap 挂载的 Env 不会同步更新
- 使用该 ConfigMap 挂载的 Volume 中的数据需要一段时间(实测大概 10 秒)才能同步更新
Secret
Secret 解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者 Pod Spec 中。Secret 可以以 Volume 或者环境变量的方式使用。Secret 有三种类型,分别是:
- Service Account
用来访问 Kubernetes API,由 Kubernetes 自动创建,并且会自动挂载到 Pod 的特点目录中。 - Opaque
base64 编码格式的 Secret,用来存储密码、密钥等,相当来说不安全。 - kubernetes.io/dockerconfigjson
用来存储私有 docker registry 的认证信息。
Service Account
Service Account 是用来访问 Kubernetes API 接口的,由 Kubernetes 自动创建和管理的,并且会自动挂载到 Pod 的 /run/secrets/kubernetes.io/serviceaccount 目录中。$ kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE kube-proxy-md1u2 1/1 Running 0 13d $ kubectl exec kube-proxy-md1u2 -- \ ls /run/secrets/kubernetes.io/serviceaccount ca.crt namespace token- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Opaque
- 创建说明
Opaque 类型的数据是一个 map 类型,要求 value 是 base64 编码格式。
$ echo -n "admin" | base YWRtaW4= $ echo -n "1f2d1e2e67df" | base MWYyZDFlMmU2N2Rm- 1
- 2
- 3
- 4
- 5
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque data: password: MWYyZDFlMmU2N2Rm username: YWRtaW4=- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用方式 —— 将 Secret 挂载到 Volume 中
apiVersion: v1 kind: Pod metadata: labels: name: seret-test spec: containers: - name: db image: hub.escape.com/library/myapp:v1 volumeMounts: - name: secrets mountPath: "readOnly: true" volumes: - name: secrets secret: secretName: mysecret- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
使用方式 —— 将 Secret 导出到环境变量中
apiVersion: extensions/v1beta kind: Deployment metadata: name: pod-deployment spec: replicas: 2 template: metadata: labels: app: pod-deployment spec: containers: - name: pod-1 image: hub.escape.com/library/myapp:v1 ports: - containerPort: 80 env: - name: TEST_USER valueFrom: secretKeyRef: name: mysecret key: username - name: TEST_PASSWORD valueFrom: secretKeyRef: name: mysecret key: password volumes: - name: config-volume configMap: name: mysecret- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
Volume
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。其次,在 Pod 中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的 Volume 抽象就很好的解决了这些问题。
Kubernetes 中的卷有明确的寿命 —— 与封装它的 Pod 相同。所以,卷的生命比 Pod 中的所有容器都长,当这个容器重启时数据仍然得以保存。当然,当 Pod 不再存在时,卷也将不复存在。也许更重要的是,Kubernetes 支持多种类型的卷,Pod 可以同时使用任意数量的卷。
Kubernetes 支持以下类型的卷
nfs、emptyDir、local awsElasticBlockStore、azureDisk、azureFile cephfs、csi、downwardAPI、fc、flocker、scaleIO gcePersistentDisk、gitRepo、glusterfs、hostPath、iscsi persistentVolumeClaim、projected、portworxVolume quobyte、rbd、secret、storageos、vsphereVolume- 1
- 2
- 3
- 4
- 5
- 6
PersistentVolume(PV)
是由管理员设置的存储,它是群集的一部分,用于描述一个具体的 Volume 属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。就像节点是集群中的资源一样,PV 也是集群中的资源。PV 是 Volume 之类的卷插件,但具有独立于使用 PV 的 Pod 的生命周期。此 API 对象包含存储实现的细节,即 NFS、iSCSI 或特定于云供应商的存储系统。PersistentVolumeClaim(PVC)
是用户存储的请求,用于描述 Pod 想要使用的持久化属性,比如存储大小、读写权限等。它与 Pod 相似。Pod 消耗节点资源,PVC 消耗 PV 资源。Pod 可以请求特定级别的资源(CPU 和内存)。声明可以请求特定的大小和访问模式(例如,可以以读/写一次或只读多次模式挂载)。StorageClass(SC)
充当 PV 的模板,自动为 PVC 创建 PV。

动态PV

PV访问模式
ReadWriteOnce- 该卷可以被单个节点以读/写模式挂载
- 在命令行中访问模式缩写为:RWO
ReadOnlyMany - 该卷可以被多个节点以只读模式挂载
- 在命令行中访问模式缩写为:ROX
ReadWriteMany - 该卷可以被多个节点以读/写模式挂载
- 在命令行中访问模式缩写为:RWX
回收策略
Retain(保留)—— 手动回收
Recycle(回收)—— 基本擦除
Delete(删除)—— 关联的存储资产将被删除状态
卷可以处于以下的某种状态(命令行会显示绑定到 PV 的 PVC 的名称):
Available(可用)—— 块空闲资源还没有被任何声明绑定
Bound(已绑定)—— 卷已经被声明绑定
Released(已释放)—— 声明被删除但是资源还未被集群重新声明
Failed(失败)—— 该卷的自动回收失败emptyDir
hostPath 为静态存储机制 - 同一 Pod 内的不同容器之间共享工作过程EmptyDir 是一个空目录,他的生命周期和所属的 Pod 是完全一致的,它用处是把同一 Pod 内的不同容器之间共享工作过程产生的文件。当 Pod 被分配给节点时,首先创建 emptyDir 卷,并且只要该 Pod 在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。
Pod 中的容器可以读取和写入 emptyDir 卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除 Pod 时,emptyDir 中的数据将被永久删除。emptyDir 的用法有:
- 暂存空间,例如用于基于磁盘的合并排序
- 用作长时间计算崩溃恢复时的检查点
- Web 服务器容器提供数据时,保存内容管理器容器提取的文件
apiVersion: v1 kind: Pod metadata: name: pod-demo namespace: default labels: app: myapp tier: frontend annotations: youmen.com/created-by: "youmen admin" spec: containers: - name: myapp image: ikubernetes/myapp:v1 imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 volumeMounts: - name: html mountPath: /usr/share/nginx/html/ - name: busybox image: busybox:latest imagePullPolicy: IfNotPresent volumeMounts: - name: html mountPath: /data/ command: ["/bin/sh", "-c"] args: - "while true; do echo $(date) >> /data/index.html; sleep 3; done" volumes: - name: html emptyDir: {}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
hostPath
hostPath 为静态存储机制 - 主机目录挂载hostPath 卷将主机节点的文件系统中的文件或目录挂载到集群中,hostPath 的用途如下所示:
- 运行需要访问 Docker 内部的容器
- 使用 /var/lib/docker 的 hostPath
- 在容器中运行 cAdvisor 监控服务
- 使用 /dev/cgroups 的 hostPath
- 允许 pod 指定给定的 hostPath
- 是否应该在 pod 运行之前存在,是否应该创建,以及它应该以什么形式存在
除了所需的 path 属性之外,用户还可以为 hostPath 卷指定 type。使用这种卷类型是请注意,因为:
- 由于每个节点上的文件都不同,具有相同配置(例如从 podTemplate 创建的)的 pod 在不同节点上的行为可能会有所不同。
- 当 Kubernetes 按照计划添加资源感知调度时,将无法考虑 hostPath 使用的资源。
- 在底层主机上创建的文件或目录只能由 root 写入。您需要在特权容器中以 root 身份运行进程,或修改主机上的文件权限以便写入 hostPath 卷。

apiVersion: v1 kind: Pod metadata: name: test-pd spec: containers: - name: test-container image: k8s.gcr.io/test-webserver volumeMounts: - mountPath: /test-pd name: test-volume volumes: - name: test-volume hostPath: path: /data type: Directory- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
nfs
使用 nfs-client-provisioner 插件来动态创建 pvnfs-client-provisioner 是一个 Kubernetes 的简易 NFS 的外部 provisioner,本身不提供 NFS,需要现有的 NFS 服务器提供存储。
- 动态 PV 又叫做动态供给,就是在创建 PVC 以后,自动创建出 PV
- PV 以
namespace-${pvcName}-${pvName}的命名格式提供(在 NFS 服务器上) - PV 回收的时候以
archieved-${pvcName}-${pvName}的命名格式(在 NFS 服务器上)
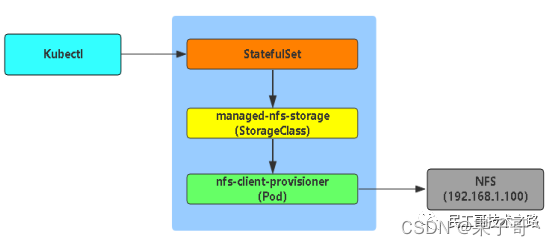
在 kubernetes 中要实现动态创建 pv 必须先要创建 StorageClass,每一个 StorageClass 对应了一个 provisioner。在 kubernetes 中内置了很多 provisioner 类型可供选择,但是很难受的是没有内置的 nfs 的 provisioner。对普通用户而言,部署 nfs 是实现后端存储最简单直接的方法。虽然 k8s 并不提供,但其允许提供外部的 provisioner,而对应迫切需要使用 nfs 的用户,可以使用 nfs-client-provisioner 这个插件完成。
创建完成之后再来创建 StorageClass
- provisioner 就是刚才 deployment 中的 PROVISIONER_NAME
- 还有一个比较关键的参数是 archiveOnDelete,如果你想在删除了 pvc 之后还保留数据的话需要把这个参数改为 true,不然你删除了 pvc 同时 pv 也会删除,然后数据也会丢失。
# nfs-class.yaml # kubectl apply -f nfs-class.yaml # kubectl get storageclass apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: managed-nfs-storage provisioner: fuseim.pri/ifs parameters: archiveOnDelete: "false"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
K8s集群调度
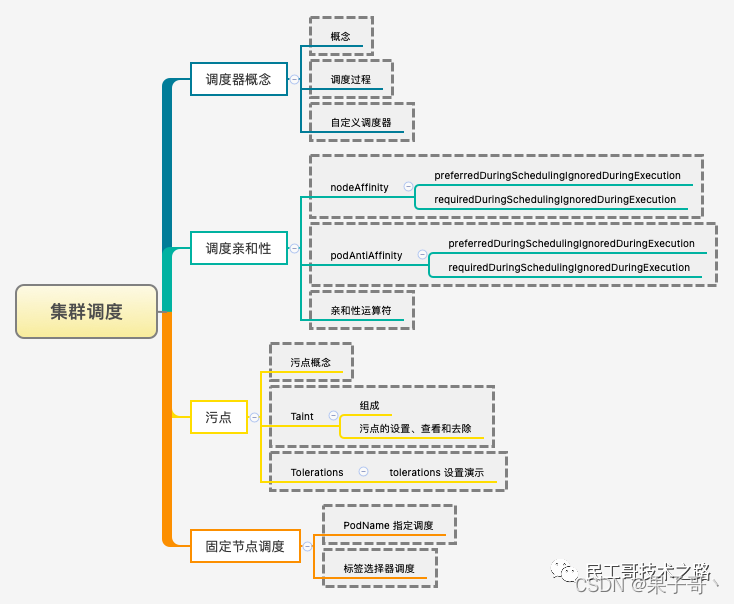
集群调度:
https://mp.weixin.qq.com/s?__biz=MzI0MDQ4MTM5NQ==&mid=2247512338&idx=2&sn=2618b76560d10da849b3cc6163b1968b&chksm=e918d40ede6f5d18813348bbbed70379788a23347f575014ffab08dd6afa160d99bf5dd1947b&scene=21&cur_album_id=1790241575034290179#wechat_redirectK8s常用命令
Kubernetes 工具使用参数
get #显示一个或多个资源 describe #显示资源详情 create #从文件或标准输入创建资源 update #从文件或标准输入更新资源 delete #通过文件名、标准输入、资源名或者 label 删除资源 log #输出 pod 中一个容器的日志 rolling-update #对指定的 RC 执行滚动升级 exec #在容器内部执行命令 port-forward #将本地端口转发到 Pod proxy #为 Kubernetes API server 启动代理服务器 run #在集群中使用指定镜像启动容器 expose #将 SVC 或 pod 暴露为新的 kubernetes service label #更新资源的 label config #修改 kubernetes 配置文件 cluster-info #显示集群信息 api-versions #以”组/版本”的格式输出服务端支持的 API 版本 version #输出服务端和客户端的版本信息 help #显示各个命令的帮助信息 ingress-nginx #管理 ingress 服务的插件(官方安装和使用方式)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
创建资源对象
# yaml kubectl create -f xxx-rc.yaml kubectl create -f xxx-service.yaml # json kubectl create -f ./pod.json cat pod.json | kubectl create -f - # yaml2json kubectl create -f docker-registry.yaml --edit -o json- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
滚动更新
# 滚动更新 pod frontend-v1 kubectl rolling-update frontend-v1 -f frontend-v2.json # 更新资源名称并更新镜像 kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2 # 更新 frontend pod 中的镜像 kubectl rolling-update frontend --image=image:v2 # 退出已存在的进行中的滚动更新 kubectl rolling-update frontend-v1 frontend-v2 --rollback # 强制替换; 删除后重新创建资源; 服务会中断 kubectl replace --force -f ./pod.json # 添加标签 kubectl label pods my-pod new-label=awesome # 添加注解 kubectl annotate pods my-pod icon-url=http://goo.gl/XXBTWq- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
修补资源
# 部分更新节点 kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}' # 更新容器镜像;spec.containers[*].name 是必须的,因为这是合并的关键字 kubectl patch pod valid-pod -p \ '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'- 1
- 2
- 3
- 4
- 5
- 6
Scale 资源
# Scale a replicaset named 'foo' to 3 kubectl scale --replicas=3 rs/foo # Scale a resource specified in "foo.yaml" to 3 kubectl scale --replicas=3 -f foo.yaml # If the deployment named mysql's current size is 2, scale mysql to 3 kubectl scale --current-replicas=2 --replicas=3 deployment/mysql # Scale multiple replication controllers kubectl scale --replicas=5 rc/foo rc/bar rc/baz- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
删除资源对象
基于 xxx.yaml 文件删除 Pod 对象# yaml文件名字按照你创建时的文件一致 kubectl delete -f xxx.yaml- 1
- 2
删除包括某个 label 的 pod 对象 kubectl delete pods -l name=<label-name> 删除包括某个 label 的 service 对象 kubectl delete services -l name=<label-name> 删除包括某个 label 的 pod 和 service 对象 kubectl delete pods,services -l name=<label-name> 删除所有 pod/services 对象 kubectl delete pods --all kubectl delete service --all kubectl delete deployment --all- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
直接查看日志
# 不实时刷新kubectl logs mypod kubectl logs mypod --namespace=test- 1
- 2
查看日志实时刷新
kubectl logs -f mypod -c ruby-container- 1
K8s常见问题总结
1、如何删除不一致状态下的 rc,deployment,service
在某些情况下,经常发现 kubectl 进程挂起现象,然后在 get 时候发现删了一半,而另外的删除不了2、删除Pod一直处于Terminating状态
可以通过下面命令强制删除kubectl delete pod NAME --grace-period=0 --force- 1
3、删除namespace一直处于Terminating状态
K8s面试题
一个目标:容器操作;两地三中心;四层服务发现;五种 Pod 共享资源;六个 CNI 常用插件;七层负载均衡;八种隔离维度;九个网络模型原则;十类 IP 地址;百级产品线;千级物理机;万级容器;相如无亿,k8s 有亿:亿级日服务人次。
组成:
- kubectl:客户端命令行工具,作为整个系统的操作入口。
- kube-apiserver:以 REST API 服务形式提供接口,作为整个系统的控制入口。
- kube-controller-manager:执行整个系统的后台任务,包括节点状态状况、Pod 个数、Pods 和Service 的关联等。
- kube-scheduler:负责节点资源管理,接收来自 kube-apiserver 创建 Pods 任务,并分配到某个节点。
- etcd:负责节点间的服务发现和配置共享。
- kube-proxy:运行在每个计算节点上,负责 Pod 网络代理。定时从 etcd 获取到 service 信息来做相应的策略。
- kubelet:运行在每个计算节点上,作为 agent,接收分配该节点的 Pods 任务及管理容器,周期性获取容器状态,反馈给 kube-apiserver。
- DNS:一个可选的 DNS 服务,用于为每个 Service 对象创建 DNS 记录,这样所有的 Pod 就可以通过 DNS 访问服务了。
五种 Pod 共享资源
一个 Pod 可以被一个容器化的环境看作应用层的“逻辑宿主机”;一个 Pod 中的多个容器应用通常是紧密耦合的,Pod 在 Node 上被创建、启动或者销毁;每个 Pod 里运行着一个特殊的被称之为 Volume 挂载卷同一个 Pod 里的容器之间仅需通过 localhost 就能互相通信。
一个 Pod 中的应用容器共享五种资源:
- PID 命名空间:Pod 中的不同应用程序可以看到其他应用程序的进程 ID。
- 网络命名空间:Pod 中的多个容器能够访问同一个IP和端口范围。
- IPC 命名空间:Pod 中的多个容器能够使用 SystemV IPC 或 POSIX 消息队列进行通信。
- UTS 命名空间:Pod 中的多个容器共享一个主机名。
- Volumes(共享存储卷):Pod 中的各个容器可以访问在 Pod 级别定义的 Volumes。
Pod 的生命周期通过 Replication Controller 来管理;通过模板进行定义,然后分配到一个 Node 上运行,在 Pod 所包含容器运行结束后,Pod 结束。
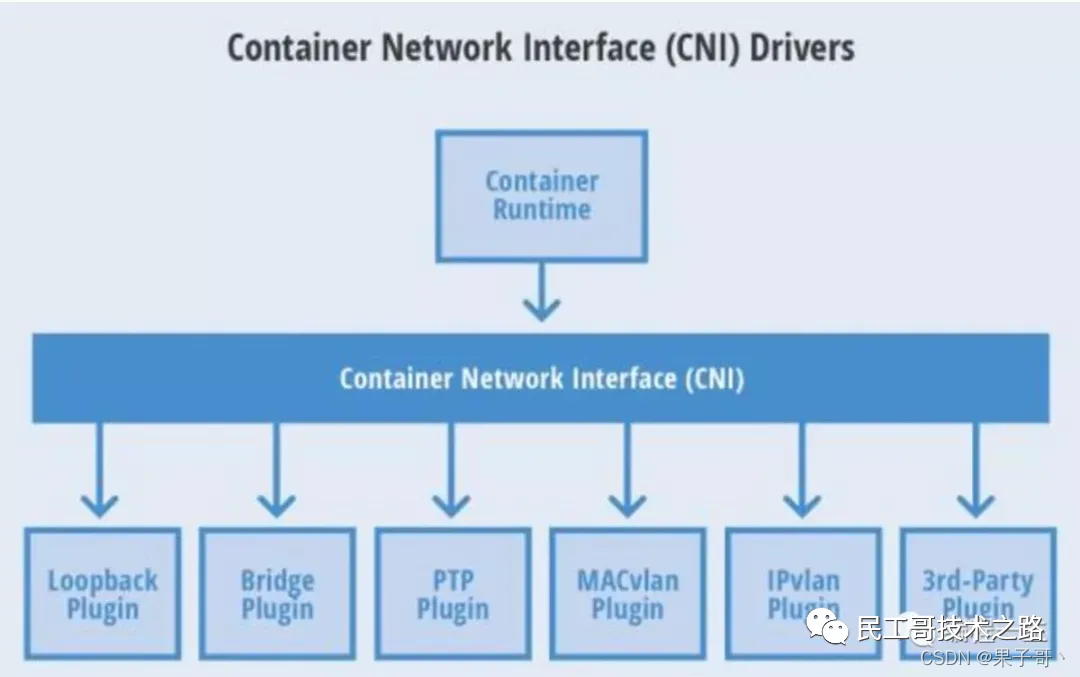
六个 CNI 常用插件
CNI(Container Network Interface)容器网络接口是 Linux容器网络配置的一组标准和库,用户需要根据这些标准和库来开发自己的容器网络插件。CNI只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架。所以 CNI 可以支持大量不同的网络模式,并且容易实现。
下面用一张图表示六个 CNI 常用插件:
- 服务发现和负载均衡
-
相关阅读:
虹科案例 | 订单自动分拣效率居然这么高?
以太网通讯与485通讯哪个好?
YASKAWA安川机器人DX100轴板维修故障细节分享
BP神经网络需要训练的参数,bp神经网络建模步骤
面试官:说一说CyclicBarrier的妙用!我:这个没用过
Python数据分析与挖掘————图像的处理
typescript实现一个简单的区块链
wireshark——解密加密报文
crontab的配置参数和基础使用教程
STC15W单片机防丢语音报警GPS北斗定位测距双机LORA无线手持可充电
- 原文地址:https://blog.csdn.net/qq_39578545/article/details/124159860