-
Credit-based Flow Control的前世今生

撰文 | 乔晶、姚迟
1
OneFlow 中的流控
OneFlow 团队此前发布的《仅此一文让您掌握OneFlow框架的系统设计》介绍了 OneFlow 是通过背压机制解决流控问题的。文中给出了两张流水线的示意图:

图:当训练是瓶颈时的时间线

图:当数据加载是瓶颈时的时间线
如上面两张图所示,虽然 DataLoading 的时间很短,但并不会无节制加载数据,而是当它的两个Regst被填满之后就会等待。
-
当 Training 是瓶颈时,Batch 3的数据在训练时,DataLoading 提前准备了 Batch 7 和 Batch 8 的数据,然后就等着。
-
当 Preprocessing 是瓶颈时,DataLoading 永远都比 Preprocessing 提前处理了两个 Batch 的数据。
这两张图简单地说明了,在去中心化、异步执行设计的 OneFlow 系统中,通过背压机制,系统会自动地照顾好处理速度最慢的那个单元,使得各个执行单元(我们称之为 Actor),都能够随之调节好运行节奏。
仔细思考一下,你会发现,这里的背压机制,似乎和大家熟知的 TCP 滑动窗口有异曲同工之妙。
确实,背压(Backpressure)机制,又叫 Credit-based Flow Control,是网络通信中解决流控问题的一种经典方案,它的前身就源于 TCP 滑动窗口。
这个思路特别简洁有效,后面我们会看到,基于相同原理,这个思路适用于任何流量控制方案,在很多硬件系统和软件系统的设计中,都有它的身影。
但是,你可能想象不到,这个简洁思路背后却有着不简单的身世。甚至,还引发过一场激烈的学术论战,并且在论战中还输了。虽然输了,Credit-based Flow Control 思想却在论战中得到了完善,后来在多个领域大放异彩。
今天,我们就来讲一讲它背后的原理,以及其跌宕起伏的故事。
2
什么是流控
网络流控(Network Flow Control)是网络中的一个基本功能,其目的是防止网络在拥塞的情况下出现丢帧。

在上面这张图中,假设在一对网络通信节点之间:
-
Sender 生产数据的速率是 2MB/s,Receiver 消费数据的速率是 1MB/s,数据在网络中传输的速率是 2MB/s。
-
两个节点各有一个数据缓冲区(Send Buffer/Receive Buffer),大小均为 5MB。
可以推演出,由于 Sender 生产数据的速度比 Receiver 消费数据的速度快, 5s 后 Receive Buffer 就被装满了,这时会面临两种情况:
-
如果 Receive Buffer 是有界的,那么新到达的数据就只能被丢弃掉了。
-
如果 Receive Buffer 是无界的,那么 Receive Buffer 会持续扩张,最终会导致 Receiver 端内存耗尽。
简单总结一下,所谓流控,就是解决端到端的发送方和接收方速度不匹配的问题。或者更明确一点,就是解决 “Fast Sender Slow Receiver ” 的问题。
那么,流控方案有哪些?所谓流控方案,就是提供一套速度匹配措施,通过遏制 Sender 较快的发送速率,与 Receiver 较慢的读取速率相适应。
问题就转换成了,以怎样的方式遏制 Sender 的发送速率呢?常见的解决思路有两种。
思路一:简单粗暴地限速
Sender 以预先确定的速率发送数据。比如在 Sender 端实现一个限速器,将 Sender 的发送速率降到 1MB/s ,这样的话, Sender 端的发送速率跟 Receiver 端的处理速率就可以匹配起来了。
思路二:授权发送
Sender 不能直接发送,除非它已经从 Receiver 接收到一个关于可接受通信量的指示。这种量化方案保护了 Receiver 端不会内存溢出。
注意,这里的可接受通信量,常常被称为授权(Credit),它到底是什么呢?又和我们所说的 Credit-based Flow Control 有什么关系呢?
先卖一个关子。接下来我们将按照时间顺序,讲述 Credit-based Flow Control 的身世。实际上,这两种思路,正是我们将要看到的一场论战中冲突对战的两派。问题的答案,也将在故事中揭晓。
2
Credit-based Flow Control 的故事
TCP 滑动窗口
1974年,TCP/IP 协议的设计者,被称作互联网之父之一的 Vinton G. Cerf,发表了 TCP/IP 协议的奠基论文,《A protocol for packet network intercommunication》,在这篇论文中,提出了基于滑动窗口的流控方案。
同年12月,滑动窗口的概念被正式加入到 RFC675(https://www.hjp.at/doc/rfc/rfc675.html) 中。随着时间的推移,TCP/IP 协议做了许多改进,各种错误和不一致的地方逐渐被修复,滑动窗口的思路却一直保留了下来。这个思路后来被发扬光大,发展出了网络流控中各种场景下的"窗口",进而被提炼成为 Credit-based Flow Control 。
下面,我们来看看 TCP 滑动窗口的工作流程。

上面的动图,演示了 TCP 滑动窗口的工作流程:
-
假定初始化时,发送 Window 大小为3(后续会随发送情况动态调整),接收 Window 大小为5(固定)。且发送方发送数据包的速率,是接收方消费数据速率的三倍。
-
Sender 发送 1~3 号数据包,Receiver 接收 1~3 号包,并放置在缓冲区。
-
接收方消费1号数据包。
-
接收方回复发送方 Ack=4,即表示发送方接着可以从4号包发送起,Window 大小为3(总大小为5,但是有2个未来得及被消费的数据包);接收方收到该消息后,将滑动窗口移动到4,发送窗口大小为3。
-
Sender 发送 4~6 号数据包,Receiver 接收 4~6 号包,并放置在缓冲区。
-
接收方消费2号数据包。
-
接收方回复发送方 Ack=7,即表示发送方接着可以从7号包发送起,Window 大小为1;接收方收到该消息后,将滑动窗口移动到8,同时将窗口大小调整为1,也就是将发送速率降为了原来的1/3。
-
Sender 发送 7 号包,Receiver 接收 7 号包。此时接收方的缓冲区已经满了。
-
假设接收方消费数据出现问题,一直没有消费数据,而此时接收窗口又满了,那么接收方就会回复 ACK=8, Windows 大小为 0。接收方收到该消息后,会讲发送窗口大小调整为 0,即停止发送。
-
假设接收方恢复了消费数据,那么会重复以上类似 3~5 的过程。
Credit-based Flow Control 概念的提出
1981年,Pouzin, Louis 在《Methods, Tools, and Observations on Flow Control in Packet-Switched Data Networks》中,总结了当时已有的一些网络流控方案,提出了Credit-based Flow Control 的概念,他将 Credit 定义为:
credit (or token): which gives permission for message flow.
他还指出,基于窗口机制的流控方案是 Credit-based Flow Control 的一种实例,称之为 Self-Correcting Credit Scheme。

图:《Methods, Tools, and Observations on Flow Control in Packet-Switched Data Networks》
关于 Credit-based Flow Control 的激烈论战
这场论战起始于 90 年代初,那时,曾经一度被人们看好的 ATM 网络,正在如火如荼地进行着标准的起草和制定。
ATM(Asynchronous Transfer Mode) 网络是一种为了多种业务而设计的面向连接的通用传输模式。它具有实时性好、灵活性强、服务质量优秀等优点,在当时被很多人寄予厚望,认为是未来网络技术发展的趋势。因此,关于 ATM 网络中相关技术选型的讨论也是异常激烈。
1993年 ,华人教授 H.T. Kung(孔祥重)向 ATM Forum 提交了ATM网络 Credit-based Flow Control 的提案。

这个提案给出了在 ATM 网络中实现 Credit-based Flow Control 的具体算法,并进行了详细的可用性分析。该方案一经提出,就受到了业界重视。
然而到了1994年底, ATM Forum 投票选出了另外一种称为 Rate-based 流控的方案,拒绝了 Credit-based Flow Control 方案。
还记得我们在前言部分中提到的两种流控方案吗?实际上,Rate-based 流控对应上面提到的简单粗暴的限速,Credit-based Flow Control 对应上面提到的授权发送。
这里简单介绍一下 Rate-based 流控。
Rate-based 流控的思路是,Sender 事先对所需资源下的速率要求进行评估,以预先确定的速率发送数据。
该方案的一个典型应用是外设I/O设备,其工作的速度是固定的。比如,像字符终端这样的设备,通常来说,作为Reciever 时, 它无法主动控制 Sender 向发送数据的速率。所以为了保障它能够正常运作,唯一的方法,就是使 Sender 按照它的节奏给它提供数据。Sender 以固定速率发送数据的另一个典型应用,是CPU设计中的如流水线技术,流水线中固定的全局时钟频率,决定了每个部件都是以相同速率在工作。
回到我们刚才的故事,93-94这中间一年多的时间里,发生了什么呢?
从96年的总结文章,《Congestion control and traffic management in ATM networks: Recent advances and a survey》中,可以对当时两种方案争论的激烈程度窥见一二。
这场时间长达一年多的争论,可以说相当”宗教化”,因为每种方法的信徒心目中的目标相当不同,而且不愿意妥协。为了实现他们的目标,他们愿意做出对方不能接受的权衡。
Credit-based 一方说:《Credit where credit is due》,另一方 Rate-based 就说 :《The benefits of rate-based flow control for ABR service》。
Rate-based 一方攻击:《Limitations of credit based flow control 》, Credit-based 一方就回应:《The realities of flow control for ABR service》
显然, Credit-based Flow Control 派 对ATM Forum的选择很不满意,他们坚定地认为 Credit-based Flow Control 是更好的方案,在接下来的几年时间里,还不断的有学者进行这方面的研究。
比如,孔教授本人,又连续发了三篇文章,对 Credit-based Flow Control 方案最初提出的算法做了一系列相应改进,比如支持动态Credit。



另外,他还在哈佛组织了一个团队,与BNR联合开发了一个基于Credit-based Flow Control 的 ATM 交换机,并在其上做了更多的实验,证明了该算法的有效性,见这里:https://www.nap.edu/read/5769/chapter/6#19
孔教授在《Credit-based Flow Control for ATM Networks》中提到了他做这些努力的原因:
We hope thereby to speed the evolution of ATM flow control, and minimize the risk of standardizing inadequate solutions. This article avoids political and short-term pragmatic issues, such as migration paths and interoperability, noting that flow control mechanisms adopted now may be in use long after such issues are forgotten.
Credit-based Flow Control 的直观理解
接下来,我们从类比的、启发式的角度,探索一下 Credit-based Flow Control 的核心原理,会发现这个思路非常精妙、简洁,符合设计的 Less is More 美学。
在用于数据传输的网络中,我们常常能看到一些缓冲区(Buffer)。比如我们在前言例子中看到的 Send Buffer 和 Receive Buffer。
这些 Buffer 有什么作用呢?
类比生活中,我们沿着河流建造串联大坝的场景,如下图所示。
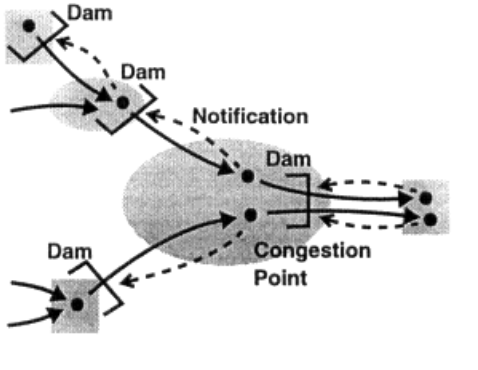
图:https://www.nap.edu/read/5769/chapter/4#12
大坝的好处是什么呢?我们可以开放地思考一下:
首要好处是有“缓冲”的作用:大坝的存在为大坝附近居民用水提供了便利,如果没有大坝,短时间突然增加用水量时,就只能等待“远水救近火”了。
其次,大坝有“反馈式”的防洪作用。每当一个下游大坝充满时,它的上游大坝就会被通知截流。那么,当发生洪水时,每个上游大坝都可以帮助缓解下游拥堵点的洪水,每座大坝的容量都得到了有效利用。
传输数据的网络中,一开始设计 Buffer 的目的,主要用于处理因为各种原因而产生的设备性能波动,导致设备之间效率不协调的问题。这就像我们生活中的大坝能够调节用水量波动一样。
那么,能不能模仿大坝防洪的原理 ,为网络中的 Buffer 也提供一套反馈机制,从而动态调节数据流量呢?
当然可以,Credit-based Flow Control 的思路就是如此。
在大坝防洪的例子中,每当一个大坝充满时,它的上游大坝就会被通知截流。也就是说,下游大坝向上游大坝反馈的是它的蓄水量信息。
类似地,在 Credit-based Flow Control 中,Receiver(下游节点)可以将自己 Buffer 占用情况的信息反馈给 Sender(上游节点),从而调节 Sender 的数据发送量。这里,我们将这个需要反馈的信息称为 Credit,如下图所示。
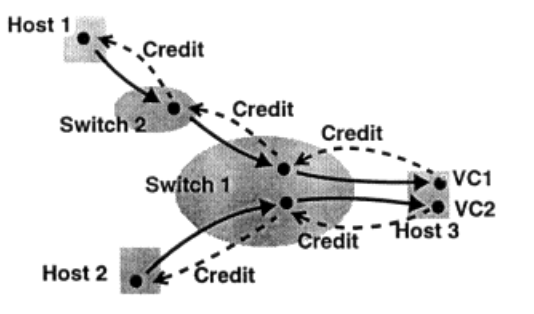
图:https://www.nap.edu/read/5769/chapter/4#12
关于 Credit 内容的选取,以及 Sender 收到 Credit 后的处理方式,可以根据具体场景确定。比如,在孔教授1993年 ATM 网络的 Credit-based Flow Control 提案中,就给出了三种 Credit 值的选取方式,不同方式应对不同场景。
这里我们不做展开,只要明确一点,Credit 的值反应了 Sender Buffer 的占用情况,Sender 根据收到的 Credit 值,确定发送多少数据。
可以很明显看到,在 Credit-based Flow Control 中,发送速率或者说流量,是由 Receiver 控制的,Sender 始终是被迫调整至与 Receiver 同步。
所以,Credit-based Flow Control 也常常被称为基于背压机制的流控 ,反映了由下游控制上游的核心思想。
总结一下,Credit-based Flow Control 的优点是:
-
理论上,Receiver Buffer 永远不会溢出。
-
流量控制是动态的,可以让 Receiver 一直工作(Keep Receiver Very Busy)。
在实际应用中,Credit-based Flow Control 也有一些需要考虑的具体问题,比如:
-
如果 Credit 丢了怎么办?
-
传输 Credit 有一定的开销,具体的系统是否能够接受?
回到1994年那个 ATM Forum 为流控方案投票的日子,ATM Forum 宣布:
Credit-based Flow Control 被认为对于大量的 Credits 来说是不可扩展的,考虑到一些大型交换机将支持数百万个VC(Credit-based Flow Control 是基于每个VC有一套Credit,VC 指 Virtual Channel,在 ATM 网络中,一条物理信道上可以有多条虚通路),这将导致交换机实现的有巨大复杂性。——《Congestion control and traffic management in ATM networks: Recent advances and a survey》
Credit-based Flow Control 在其它领域的绽放
随着技术的发展,在越来越多领域涌现的新技术中,我们可以看到这样一个趋势,数据的传输方式越来越向"多连接、分布式"的方向发展。因此,很多问题都被抽象成网络问题,流控也随之成为这些技术方案中重要的一环。
Credit-based Flow Control 的思路是简洁而明确的,这个思路适用于任何流量控制方案。实际上,各种软硬件系统,都有类似的机制,只不过名称不同。
比如,从硬件中的新型总线技术PCI Express、Intel QPI,到新型网络协议RDMA,再到流式计算系统Flink,都能看到 Credit-based Flow Control 的身影。
接下来,我们来一起看看,Credit-based Flow Control 如何在这些场景大显身手。
PCIe
PCIe 是 PCI-Express (Peripheral Component Interconnect Express) 的简称,是一种高速串行计算机扩展总线标准,由英特尔在2001年提出的,目前已经替代旧的PCI,PCI-X和AGP,成为最流行的总线标准。
PCIe 里数据连接称为 Lane,实际的数据通道上可以由多条 Lane 合在一起提供了更高的带宽,这有点像 ATM 网络中虚通道的概念。对于这种多通道通信情景的流控,需要小心处理因接收端缓冲区不足导致数据包的丢弃和重发的问题,Credit-based Flow Control 在这里派上了用场。
为了能够知道接收端还有多少可用的缓冲区,接收端需要通过DLLP (Data Link Layer Packet)随时汇报可用的缓冲区,这里的DLLP,就是 Credit 在PCIe 中的具体实现。
Intel QPI
Intel 的 QuickPath Interconnect(QPI) 技术,译为快速通道互联,用来实现芯片之间的直接互联,替代了传统的 FSB(前端总线)。在传统的 FSB(前端总线)中,所有数据的通信是通过单一总线完成的,这称为Single-Shared Bus Approach,如下图所示。

图:https://www.intel.com/content/www/us/en/io/quickpath-technology/quick-path-interconnect-introduction-paper.html
QPI 的一个亮点就是支持多条系统总线连接,如下图所示。系统总线将会被分成多条连接,并且频率不再是单一固定的。根据系统各个子系统对数据吞吐量的需求,每条系统总线连接的速度也可不同。这种由单一总线走向多总线,是近年来 CPU 提高数据传输性能的一个主要发展方向。

这看起来就像个小型的网络拓扑,有趣的是,它的数据通信协议也设计得像计算机网络的分层模型。

其中,链路层(Link Layer)传输的数据包称为 Flit,代表 Flow Control unit。每个Flit中都包含了一个 Flow Control 流,这个流的作用就是将Rx (Receiver)的缓冲区空余量反馈给 Tx (Transmitter)。这里即是使用 Credit-based 方案实现流量控制,以防止接收方的缓冲区发生溢出的例子。
RDMA
RDMA(Remote Direct Memory Access),即远程直接数据存取,是为了解决网络传输中服务器端数据处理的延迟而产生的,非常适合在大规模并行计算机集群中使用,近年来开始在数据中心得到普及。
目前,大致有三类 RDMA 网络,分别是Infiniband、RoCE(RoCE 和Roce v2)、iWARP。其中,Infiniband是一种专为RDMA设计的网络,从硬件级别保证可靠传输 ,而 RoCE 和 iWARP 都是基于以太网的RDMA技术。
仔细分析一下会发现,这三类 RDMA 网络的流控方案,全部都是基于 Credit-b
ased Flow Control 的思路。
InfiniBand
《InfiniBand Credit-based Link-Layer Flow-Control》 里,提到了在InfiniBand 在链路层实现了Credit-based Flow Control 。其链路层的Flow Control Packet, 就是 Credit 在 InfiniBand 中的具体实现。
RoCE
在RoCE中,流量控制算法是PFC(Priority-based Flow Control)。这个文章《Revisiting network support for RDMA》描述PFC的算法是, 当队列超过某个特定的配置阈值时,交换机会向上游实体发送暂停帧。
由下游控制上游,这是 Credit-based Flow Control 的思路。
iWARP
直接通过 TCP 来进行流量控制,而 TCP 就是Credit-based Flow Control 的思路。
Flink
互联网大数据时代,对数据实时性的要求越来越高,越来越多分布式计算引擎开始采用流式抽象。Apache Flink 为流式计算而生,用于对数据流进行有状态的计算,被称为在大数据时代继 Hadoop、Pig/Hive、Spark/Storm 之后的第四代计算引擎。
在介绍 Flink 的文章《How Apache Flink™ handles backpressure》中,标题就出现了 Backpressure 这个词,应该就是Credit-based Flow Control 。

具体来看看,文章中画出的这张示意图,图中 Task1,Task2 的黑色长条代表了缓冲区。果然,文章中说到了,“如果没有可用的缓冲区,则会中断从 TCP 连接读取数据”,这明显就是 Credit-based Flow Control 的思路。
3
再回首 OneFlow 的流控设计
首先,回顾一下 OneFlow 的设计特点。
OneFlow 会把用户的逻辑计算图,自动编译为分布式系统上的物理计算图,物理计算图由 OneFlow 运行时执行。物理计算图的执行单元是 Actor,输入数据像水流一样,流过各个 Actor 执行单元,完成运算。
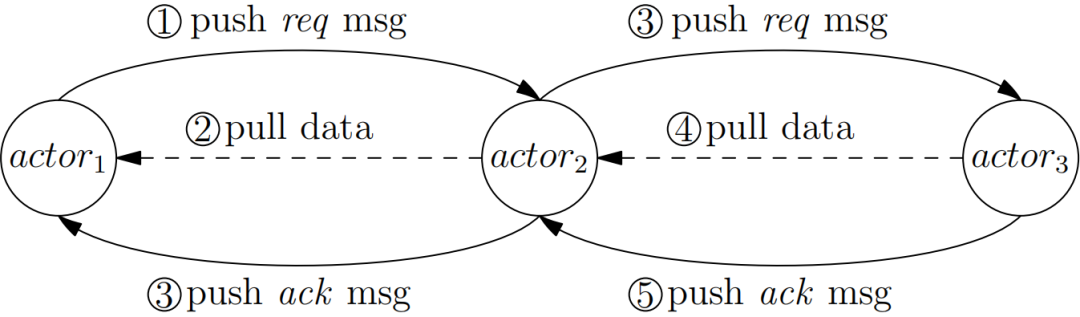
OneFlow 中由 Actor 构成的计算图,与其它框架由 OP 构成的计算图相比,有两个独特的地方:
-
没有中心的调度节点。
-
每个 Actor 都是以异步的方式执行的。
也就是说,每个Actor,发现上游有数据可读,且下游有空间可写,那它就可以工作,不需要知道其它 Actor 的状态。
这两个独特设计带来的好处是:
-
去中心化的设计,轻松解决了超大规模的分布式训练场景下中心调度方式的单点性能瓶颈问题。
-
异步执行的设计,使流水并行称为可能,理论上,可以最充分地利用硬件资源。
看到这里,你可以停下来思考一下,对于这样一个流式的分布式系统,应该如何做流控呢?
读完了上面的故事,建设大坝(Regst),利用背压控制流量,会是你心中的第一选择吗?
P.S.:提高题
利用背压流控的思路有了,那么接下来的问题是,具体施工时,大坝的容量(Regst的大小)如何选择呢?
比如,在文章最开始的例子中,我们设置 Regst = 2,这是最优选择吗?
欢迎添加OneFlow小助手微信,在开发者社群给出你的思考,对于靠谱的回答,我们将送出 OneFlow 的纪念品。想知道 OneFlow 的新奇做法,欢迎点击“阅读原文”去 OneFlow 代码中寻找答案,也欢迎持续关注,或许我们后续会再安排一期解读文章。
题图源自geralt, Pixabay
其他人都在看
欢迎下载体验OneFlow新一代开源深度学习框架:https://github.com/Oneflow-Inc/oneflow

-
-
相关阅读:
Web3 世界的名片
Oracle-Ogg集成模式降级为经典模式步骤
2-3-4树【数据结构与算法java】
51单片机应用从零开始(五)·加减乘除运算
mysql 删除表中重复数据并保留一条
ubuntu16.04安装驱动记录
mysql中binlog日志
查看jar包版本
Linux调试器-gdb使用
java正则表达式
- 原文地址:https://blog.csdn.net/OneFlow_Official/article/details/121434150