-
机器学习笔记 - 图解对象检测任务(2)
一、使用 CNN 进行对象类别检测
1、分类CNN回顾
(1)ImageNet图像分类挑战

(2)AlexNet

(3)VGG-16

(4)ResNet

(5)Squeeze & Excitation

(6)总结

二、CNN用于对象检测的直觉
现代分类架构,如 ResNet 或 Inception,自始至终都使用卷积层
最后一层没有全连接层
减少参数数量
通过空间池化获得特征向量

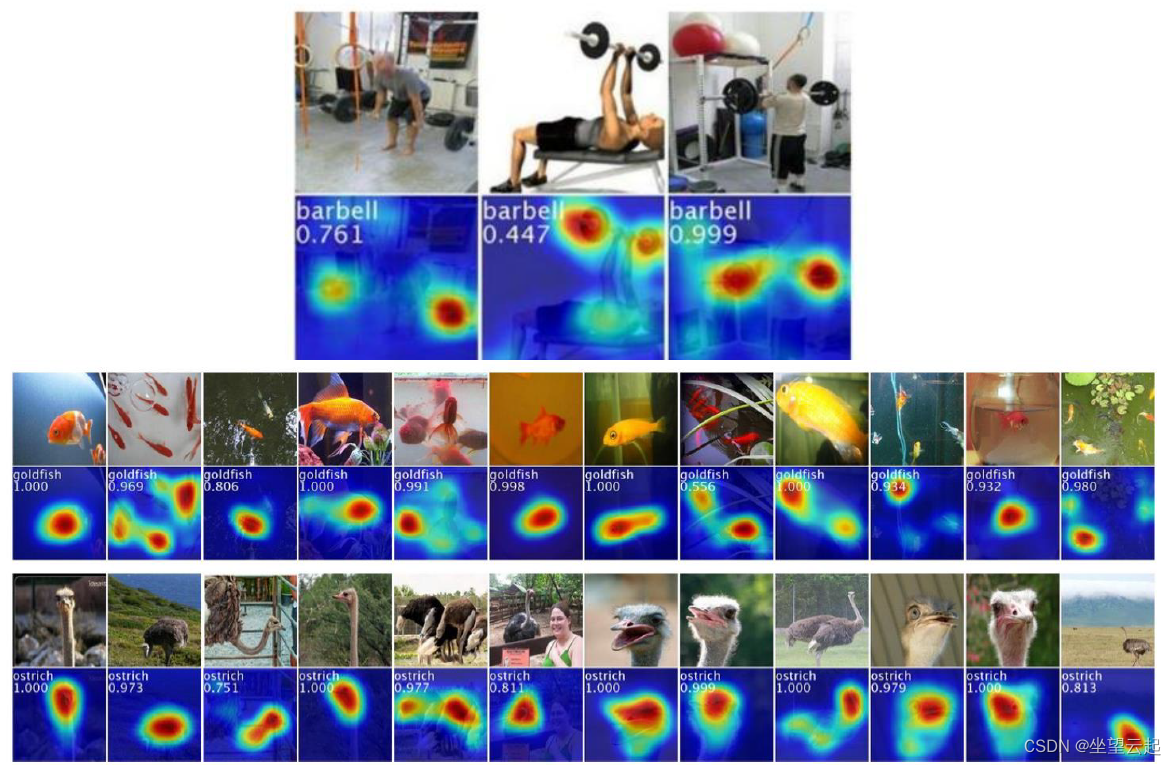
三、两阶段对象检测网络
经典对象检测器使用两个阶段:
1、在图像中提出类不可知区域;2、将区域分类为对象类或背景
Examples: Faster R-CNN, R-FCN, Mask-RCNN
1、Faster R-CNN
第一阶段:区域提议网络(RPN)
第二阶段:对区域进行分类/回归
基础网络:VGG16


2、RPN: Region Proposal Network
(1)Region Proposal Network
在特征图上滑动一个小窗口
滑动窗口的位置提供参考图像的定位信息
框回归参考这个滑动窗口提供了更精细的定位信息

(2)Anchors:预定义的候选区域
在每个位置使用多尺度/尺寸锚点:3 个比例
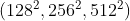 和 3 个纵横比 (2:1, 1:1, 1:2) 产生 9 个锚点
和 3 个纵横比 (2:1, 1:1, 1:2) 产生 9 个锚点每个anchor都有自己的预测功能
单尺度特征,多尺度预测

(3)Detection process







正负训练区域

3、The Spatial Pooling (SP) layer
空间池化层 (SP) 最大池化给定区域中的卷积特征响应
这可用于通过重用相同的卷积特征来提取许多特定于区域的特征向量。

改进:RoIAlign 操作(针对每个提案)

特定分类和回归

4、示例和应用
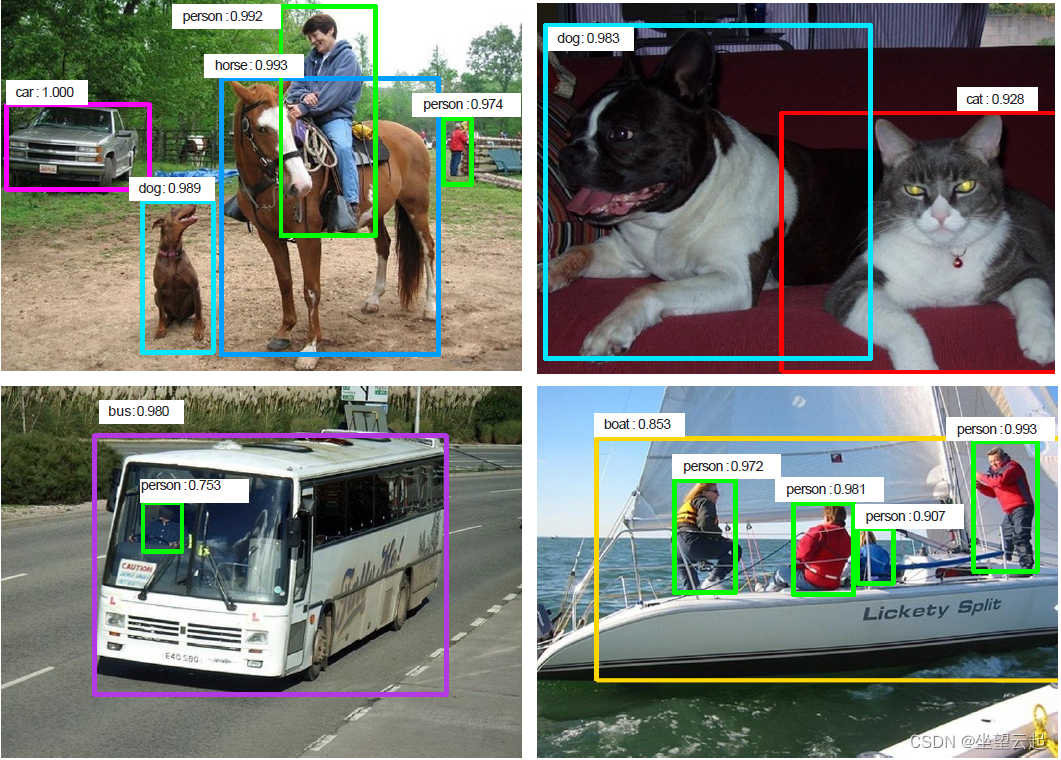
VGG16 在 ImageNet 上预训练
在 WIDER 人脸数据集上训练:12,880 张图像和 159,424 张人脸
四、一阶段对象检测网络
区域内置于架构中(卷积层),即没有独立的 RPN
基于锚,例如 YOLO、SSD、RetinaNet、EfficientDet
基于点,例如 CornerNet , CenterNet , FCOS
1、Single Shot MultiBox Detector (SSD)


2、重大改进
特征金字塔网络 (FPN)
Focal Loss
复制和粘贴增强训练
无锚网络

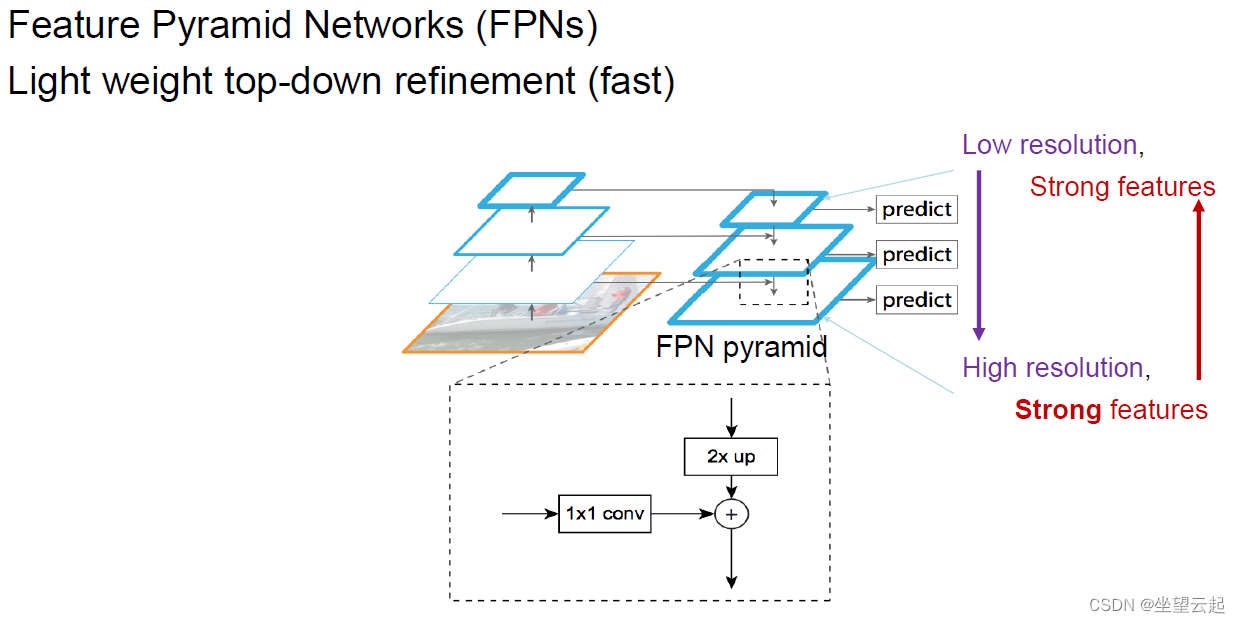
3、特征金字塔网络 (FPN)
目标检测器必须在广泛的范围内进行分类和定位



4、Focal Loss

5、单级检测器示例:RetinaNet
带有 FPN + 类特定锚点的骨干网(最终检测)
训练有焦点损失


6、DetectorRS

7、Anchorless Single Stage Detector:CornerNet
将对象检测为配对关键点
避免需要许多锚点才能与真实检测重叠的问题

将对象检测为配对关键点




8、Single Stage Detector: CenterNet-1

9、Single Stage Detector: “CenterNet-2” Objects as Points

10、Single Stage Detector: FCOS: Fully Convolutional One-Stage Object Detection
密集监督,相似分割

在特征金字塔中以适当的比例分配边界框
 11、复制粘贴的数据增强
11、复制粘贴的数据增强
12、DETR: End to end object detection using transformer


五、 Evaluation: Microsoft COCO







-
相关阅读:
川西旅游网系统-前后端分离(前台vue 后台element UI,后端servlet)
golang gin ShouldBindHeader绑定请求头数据:`header:“Referer“ binding:“required“`
TMC5160问题,插上步进电机、步进电机一转或步进电机带负载转瞬间,TMC5160就无输出
R语言caTools包进行数据划分、scale函数进行数据缩放、class包的knn函数构建K近邻分类器
基于webrtc浏览器截图
腾讯云、阿里云、华为云便宜云服务器活动整理汇总
字符串对齐
Linux 关闭对应端口号进程
Unity WebGL 编译 报错: emcc2: error: ‘*‘ failed: [WinError 2] ϵͳ�Ҳ���ָ�����ļ���解决办法
【附源码】计算机毕业设计SSM社区新冠疫苗接种管理系统
- 原文地址:https://blog.csdn.net/bashendixie5/article/details/124997116