-
【JAVA SE】JAVA中的集合的基础知识
大家好呀,我是crisp制药呀💊,今天来给大家讲解JAVA中集合的相关的知识,万字长文希望大家可以收藏起来慢慢看,作为初学者我也是写来方便日后的复习,制药和大家一起学习一起加油!😀
✨如果喜欢的话,欢迎大家关注,点赞,评论,收藏!
🌟本人博客的首页:crisp制药
😺本人是一个JAVA初学者,分享一下自己的所学,如果有错误,希望大家能告知,谢谢!
文章目录
一、集合与数组
1. 集合与数组存储数据概述:
集合、数组都是对多个数据进行存储操作的结构,简称Java容器。 说明:此时的存储,主要指的是内存层面的存储,不涉及到持久化的存储(.txt,.jpg,.avi,数据库中)
2. 数组存储的特点:
一旦初始化以后,其长度就确定了。 数组一旦定义好,其元素的类型也就确定了。我们也就只能操作指定类型的数据了。
比如:
String[] arr、int[] arr1、Object[] arr23. 数组存储的弊端:
- 一旦初始化以后,其长度就不可修改。
- 数组中提供的方法非常限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。
- 获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用
- 数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足。
4. 集合存储的优点:
解决数组存储数据方面的弊端。
5. 集合的分类
Java集合可分为Collection和Map两种体系
- Collection接口:单列数据,定义了存取一组对象的方法的集合
- List:元素有序、可重复的集合
- Set:元素无序、不可重复的集
- Map接口:双列数据,保存具有映射关系“key-value对”的集合
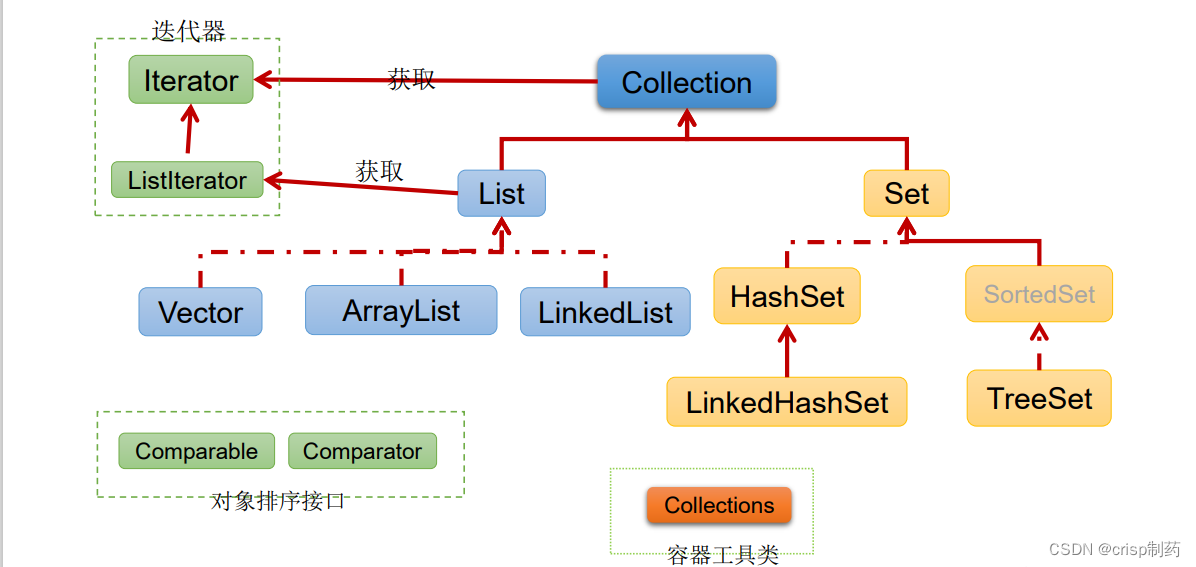
6. 集合的框架结构
|----Collection接口:单列集合,用来存储一个一个的对象 |----List接口:存储有序的、可重复的数据。 -->“动态”数组 |----ArrayList:作为List接口的主要实现类,线程不安全的,效率高;底层采用Object[] elementData数组存储 |----LinkedList:对于频繁的插入删除操作,使用此类效率比ArrayList效率高底层采用双向链表存储 |----Vector:作为List的古老实现类,线程安全的,效率低;底层采用Object[]数组存储 |----Set接口:存储无序的、不可重复的数据 -->数学概念上的“集合” |----HashSet:作为Set接口主要实现类;线程不安全;可以存null值 |----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加顺序遍历;对于频繁的遍历操作,LinkedHashSet效率高于HashSet. |----TreeSet:可以按照添加对象的指定属性,进行排序。 |----Map:双列数据,存储key-value对的数据 ---类似于高中的函数:y = f(x) |----HashMap:作为Map的主要实现类;线程不安全的,效率高;存储null的key和value |----LinkedHashMap:保证在遍历map元素时,可以照添加的顺序实现遍历。 原因:在原的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。 对于频繁的遍历操作,此类执行效率高于HashMap。 |----TreeMap:保证照添加的key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序 底层使用红黑树 |----Hashtable:作为古老的实现类;线程安全的,效率低;不能存储null的key和value |----Properties:常用来处理配置文件。key和value都是String类型- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
二、Collection接口
-
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和 Queue集合。
-
JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List)实现。
-
在JDK 5.0之前,Java集合会丢失容器中所有对象的数据类型,把所有对象都当成 Object类型处理;从JDK 5.0增加了泛型以后,Java集合可以记住容器中对象的数据类型。
-
- 单列集合框架结构
|----Collection接口:单列集合,用来存储一个一个的对象 |----List接口:存储有序的、可重复的数据。 -->“动态”数组 |----ArrayList:作为List接口的主要实现类,线程不安全的,效率高;底层采用Object[] elementData数组存储 |----LinkedList:对于频繁的插入删除操作,使用此类效率比ArrayList效率高底层采用双向链表存储 |----Vector:作为List的古老实现类,线程安全的,效率低;底层采用Object[]数组存储 |----Set接口:存储无序的、不可重复的数据 -->数学概念上的“集合” |----HashSet:作为Set接口主要实现类;线程不安全;可以存null值 |----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加顺序遍历;对于频繁的遍历操作,LinkedHashSet效率高于HashSet. |----TreeSet:可以按照添加对象的指定属性,进行排序。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
图示:
2. Collection接口常用方法:
- 添加
add(Object obj)addAll(Collection coll)
- 获取有效元素个数
int size()
- 清空集合
void clear()
- 是否为空集合
boolean isEmpty()
- 是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否是同一个对象boolean containsAll(Collection c):也是调用元素的equals方法来比较的。用两个两个集合的元素逐一比较
- 删除
boolean remove(Object obj):通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素boolean removeAll(Collection coll):取当前集合的差集
- 取两个集合的交集
boolean retainAll(Collection c):把交集的结果存在当前的集合中,不影响c
- 集合是否相等
boolean equals(Object obj)
- 转换成对象数组
Object [] toArray()
- 获取集合对象的哈希值
- `hashCode()`- 1
- 遍历
- `iterator()`:返回迭代器对象,用于集合遍历- 1
- 2
- 3
代码示例:
@Test public void test1() { Collection collection = new ArrayList(); //1.add(Object e):将元素添加到集合中 collection.add("ZZ"); collection.add("AA"); collection.add("BB"); collection.add(123); collection.add(new Date()); //2.size():获取添加元素的个数 System.out.println(collection.size());//5 //3.addAll(Collection coll1):将coll1集合中的元素添加到当前集合中 Collection collection1 = new ArrayList(); collection1.add("CC"); collection1.add(213); collection.addAll(collection1); System.out.println(collection.size());//9 //调用collection1中的toString()方法输出 System.out.println(collection);//[ZZ, AA, BB, 123, Tue Apr 28 09:22:34 CST 2020, 213, 213] //4.clear():清空集合元素 collection1.clear(); System.out.println(collection1.size());//0 System.out.println(collection1);//[] //5.isEmpty():判断当前集合是否为空 System.out.println(collection1.isEmpty());//true } @Test public void test2() { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person("Tom", 23)); coll.add(new Person("Jarry", 34)); coll.add(false); //6.contains(Object obj):判断当前集合中是否包含obj //判断时需要调用obj对象所在类的equals()方法 System.out.println(coll.contains(123));//true System.out.println(coll.contains(new Person("Tom", 23)));//true System.out.println(coll.contains(new Person("Jarry", 23)));//false //7.containsAll(Collection coll1):判断形参coll1中的元素是否都存在当前集合中 Collection coll1 = Arrays.asList(123, 4566); System.out.println(coll.containsAll(coll1));//flase //8.remove(Object obj):从当前集合中移除obj元素 coll.remove(123); System.out.println(coll);//[456, Person{name='Tom', age=23}, Person{name='Jarry', age=34}, false] //9.removeAll(Collection coll1):差集:从当前集合中和coll1中所有的元素 Collection coll2 = Arrays.asList(123, 456, false); coll.removeAll(coll2); System.out.println(coll);//[Person{name='Tom', age=23}, Person{name='Jarry', age=34}] } @Test public void test3() { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person("Tom", 23)); coll.add(new Person("Jarry", 34)); coll.add(false); //10.retainAll(Collection coll1):交集:获取当前集合和coll1集合的交集,并返回给当前集合 Collection coll1 = Arrays.asList(123, 345, 456); boolean b = coll.retainAll(coll1); System.out.println(b);//true System.out.println(coll);//[123, 456] //11.equals(Object obj):返回true需要当前集合和形参集合的元素相同 Collection coll2 = new ArrayList(); coll2.add(123); coll2.add(456); System.out.println(coll.equals(coll2));//true //12.hashCode():返回当前对象的哈希值 System.out.println(coll.hashCode());//5230 //13.集合--->数组:toArray() Object[] array = coll.toArray(); for (Object obj : array) { System.out.println(obj); } //14.数组--->集合:调用Arrays类的静态方法asList() List<int[]> ints = Arrays.asList(new int[]{123, 345}); System.out.println(ints.size());//1 List<String> strings = Arrays.asList("AA", "BB", "CC"); System.out.println(strings);//[AA, BB, CC] //15.iteratoriterator():返回Iterator接口的实例,用于遍历集合元素。 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
3. Collection集合与数组间的转换
//集合 --->数组:toArray() Object[] arr = coll.toArray(); for(int i = 0;i < arr.length;i++){ System.out.println(arr[i]); } //拓展:数组 --->集合:调用Arrays类的静态方法asList(T ... t) List<String> list = Arrays.asList(new String[]{"AA", "BB", "CC"}); System.out.println(list); List arr1 = Arrays.asList(new int[]{123, 456}); System.out.println(arr1.size());//1 List arr2 = Arrays.asList(new Integer[]{123, 456}); System.out.println(arr2.size());//2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
使用 Collection 集合存储对象,要求对象所属的类满足:
向 Collection 接口的实现类的对象中添加数据 obj 时,要求 obj 所在类要重写
equals()。三、Iterator接口与foreach循环
1. 遍历Collection的两种方式:
① 使用迭代器Iterator
② foreach循环(或增强for循环)
2. java.utils包下定义的迭代器接口:Iterator
2.1说明:
Iterator对象称为迭代器(设计模式的一种),主要用于遍历 Collection 集合中的元素。 GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生。
2.2作用:
遍历集合Collectiton元素
2.3如何获取实例:
coll.iterator()返回一个迭代器实例2.4遍历的代码实现:
Iterator iterator = coll.iterator(); //hasNext():判断是否还下一个元素 while(iterator.hasNext()){ //next():①指针下移 ②将下移以后集合位置上的元素返回 System.out.println(iterator.next()); }- 1
- 2
- 3
- 4
- 5
- 6

2.6 iterator中remove()方法的使用:
- 测试Iterator中的
remove() - 如果还未调用
next()或在上一次调用next()方法之后已经调用了remove()方法,再调用 remove 都会报IllegalStateException。 - 内部定义了
remove(),可以在遍历的时候,删除集合中的元素。此方法不同于集合直接调用remove()
代码示例:
@Test public void test3(){ Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person("Jerry",20)); coll.add("Tom" ); coll.add(false); //删除集合中"Tom" Iterator iterator = coll.iterator(); while (iterator.hasNext()){ // iterator.remove(); Object obj = iterator.next(); if("Tom".equals(obj)){ iterator.remove(); // iterator.remove(); } } //将指针重新放到头部,遍历集合 iterator = coll.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
3. JDK 5.0新特性–增强for循环:(foreach循环)
3.1 遍历集合举例:
@Test public void test1(){ Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person("Jerry",20)); coll.add(new String("Tom")); coll.add(false); //for(集合元素的类型 局部变量 : 集合对象) for(Object obj : coll){ System.out.println(obj); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
说明:内部仍然调用了迭代器。
3.2. 遍历数组举例:
@Test public void test2(){ int[] arr = new int[]{1,2,3,4,5,6}; //for(数组元素的类型 局部变量 : 数组对象) for(int i : arr){ System.out.println(i); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
四、Collection子接口:List接口
1. 存储的数据特点:
存储序有序的、可重复的数据。
- 鉴于Java中数组用来存储数据的局限性,我们通常使用List替代数组
- List集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引。
- List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
- JDK AP中List接口的实现类常用的有:ArrayList、LinkedList和 Vector.
2. 常用方法:
List除了从 Collection集合继承的方法外,List集合里添加了一些根据索引来操作集合元素的方法。
void add(int index, Object ele):在index位置插入ele元素boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来Object get(int index):获取指定index位置的元素int indexOf(Object obj):返回obj在集合中首次出现的位置int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置Object remove(int index):移除指定index位置的元素,并返回此元素Object set(int index, Object ele):设置指定index位置的元素为eleList subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
总结:
- 增:
add(Object obj) - 删:
remove(int index)/remove(Object obj) - 改:
set(int index, Object ele) - 查:
get(int index) - 插:
add(int index, Object ele) - 长度:
size() - 遍历: ① Iterator迭代器方式 ② foreach(增强for循环) ③ 普通的循环
代码示例:
@Test public void test2(){ ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); list.add(new Person("Tom",12)); list.add(456); //int indexOf(Object obj):返回obj在集合中首次出现的位置。如果不存在,返回-1. int index = list.indexOf(4567); System.out.println(index); //int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置。如果不存在,返回-1. System.out.println(list.lastIndexOf(456)); //Object remove(int index):移除指定index位置的元素,并返回此元素 Object obj = list.remove(0); System.out.println(obj); System.out.println(list); //Object set(int index, Object ele):设置指定index位置的元素为ele list.set(1,"CC"); System.out.println(list); //List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的左闭右开区间的子集合 List subList = list.subList(2, 4); System.out.println(subList); System.out.println(list); } @Test public void test1(){ ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); list.add(new Person("Tom",12)); list.add(456); System.out.println(list); //void add(int index, Object ele):在index位置插入ele元素 list.add(1,"BB"); System.out.println(list); //boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来 List list1 = Arrays.asList(1, 2, 3); list.addAll(list1); // list.add(list1); System.out.println(list.size());//9 //Object get(int index):获取指定index位置的元素 System.out.println(list.get(0)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
3. 常用实现类:
3. 常用实现类: |----Collection接口:单列集合,用来存储一个一个的对象 |----List接口:存储序的、可重复的数据。 -->“动态”数组,替换原的数组 |----ArrayList:作为List接口的主要实现类;线程不安全的,效率高;底层使用Object[] elementData存储 |----LinkedList:对于频繁的插入、删除操作,使用此类效率比ArrayList高;底层使用双向链表存储 |----Vector:作为List接口的古老实现类;线程安全的,效率低;底层使用Object[] elementData存储- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.1 ArrayList
- ArrayList是List接口的典型实现类、主要实现类
- 本质上,ArrayList是对象引用的一个”变长”数组
- Array Listi的JDK 1.8之前与之后的实现区别?
- JDK 1.7:ArrayList像饿汉式,直接创建一个初始容量为10的数组
- JDK 1.8:ArrayList像懒汉式,一开始创建一个长度为0的数组,当添加第一个元素时再创建一个始容量为10的数组
Arrays.asList(...)方法返回的List集合,既不是 ArrayList实例,也不是Vector实例。Arrays.asList(...)返回值是一个固定长度的List集合
代码示例:
@Test public void test1() { Collection coll = new ArrayList(); coll.add(123); coll.add(345); coll.add(new User("Tom", 34)); coll.add(new User("Tom")); coll.add(false); //iterator()遍历ArrayList集合 Iterator iterator = coll.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.2 linkedList
-
对与对于频繁的插入和删除元素操作,建议使用LinkedList类,效率更高
-
新增方法:
void addFirst(Object obj)void addLast(Object obj)Object getFirst()Object getlast)()Object removeFirst()Object removeLast()
-
Linkedlist:双向链表,内部没有声明数组,而是定义了Node类型的frst和last,用于记录首末元素。同时,定义内部类Node,作为 Linkedlist中保存数据的基本结构。Node除了保存数据,还定义了两个变量:
- prev:变量记录前一个元素的位置
- next:变量记录下一个元素的位置
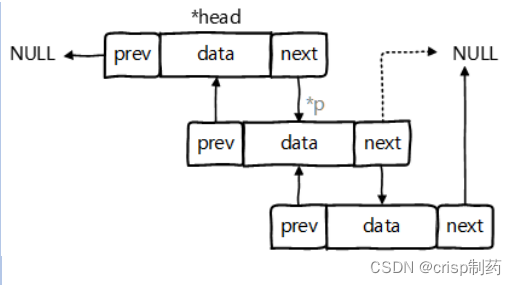
代码示例:
@Test public void test3(){ LinkedList linkedList = new LinkedList(); linkedList.add(123); linkedList.add(345); linkedList.add(2342); linkedList.add("DDD"); linkedList.add("AAA"); Iterator iterator = linkedList.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4. 源码分析(难点)
4.1 ArrayList的源码分析:
4.1.1 JDK 7.0情况下
ArrayList list = new ArrayList();//底层创建了长度是10的Object[]数组elementData list.add(123);//elementData[0] = new Integer(123); ... list.add(11);//如果此次的添加导致底层elementData数组容量不够,则扩容。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中。
- 结论:建议开发中使用带参的构造器:
ArrayList list = new ArrayList(int capacity)
4.1.2 JDK 8.0中ArrayList的变化:
ArrayList list = new ArrayList();//底层Object[] elementData初始化为{}.并没创建长度为10的数组 list.add(123);//第一次调用add()时,底层才创建了长度10的数组,并将数据123添加到elementData[0] ...- 1
- 2
- 3
- 4
- 5
- 6
后续的添加和扩容操作与JDK 7.0 无异。
4.1.3 小结:
JDK 7.0中的ArrayList的对象的创建类似于单例的饿汉式,而JDK 8.0中的ArrayList的对象的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
4.2 LinkedList的源码分析:
LinkedList list = new LinkedList(); //内部声明了Node类型的first和last属性,默认值为null list.add(123);//将123封装到Node中,创建了Node对象。 //其中,Node定义为:体现了LinkedList的双向链表的说法 private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.3 Vector的源码分析:
- Vector是一个古老的集合,JDK 1.0就有了。大多数操作与ArrayList相同,区别在于Vector是线程安全的
- 在各种list中,最好把ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList;Vector总是比ArrayList慢,所以尽量避免选择使用。
- JDK 7.0和JDK 8.0中通过Vector()构造器创建对象时,底层都创建了长度为10的数组。
- 在扩容方面,默认扩容为原来的数组长度的2倍。
5. 存储的元素的要求:
添加的对象,所在的类要重写equals()方法
6. 面试题
请问 ArrayList/LinkedList/Vector的异同?谈谈你的理解?ArrayList底层是什么?扩容机制? Vector和 ArrayList的最大区别?
-
ArrayList和 Linkedlist的异同:
二者都线程不安全,相比线程安全的 Vector,ArrayList执行效率高。 此外,ArrayList是实现了基于动态数组的数据结构,Linkedlist基于链表的数据结构。对于随机访问get和set,ArrayList觉得优于Linkedlist,因为Linkedlist要移动指针。对于新增和删除操作add(特指插入)和 remove,Linkedlist比较占优势,因为 ArrayList要移动数据。
-
ArrayList和 Vector的区别:
Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized),属于强同步类。因此开销就比 ArrayList要大,访问要慢。正常情况下,大多数的Java程序员使用ArrayList而不是Vector,因为同步完全可以由程序员自己来控制。Vector每次扩容请求其大小的2倍空间,而ArrayList是1.5倍。Vector还有一个子类Stack.
五、Collection子接口:Set接口概述
- Set接口是Collection的子接口,set接口没有提供额外的方法
- Set集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set集合中,则添加操作失败。(多用于过滤操作,去掉重复数据)
- Set判断两个对象是否相同不是使用==运算符,而是根据equals()方法
1.存储的数据特点:
用于存放无序的、不可重复的元素
以HashSet为例说明:
- 无序性:不等于随机性。存储的数据在底层数组中并非照数组索引的顺序添加,而是根据数据的哈希值决定的。
- 不可重复性:保证添加的元素照equals()判断时,不能返回true.即:相同的元素只能添加一个。
2. 元素添加过程:(以HashSet为例)
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),判断
数组此位置上是否已经有元素:
- 如果此位置上没有其他元素,则元素a添加成功。 —>情况1
- 如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
- 如果hash值不相同,则元素a添加成功。—>情况2
- 如果hash值相同,进而需要调用元素a所在类的equals()方法:
- equals()返回true,元素a添加失败
- equals()返回false,则元素a添加成功。—>情况3
对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
JDK 7.0 :元素a放到数组中,指向原来的元素。
JDK 8.0 :原来的元素在数组中,指向元素a
总结:七上八下
HashSet底层:数组+链表的结构。(JDK 7.0以前)
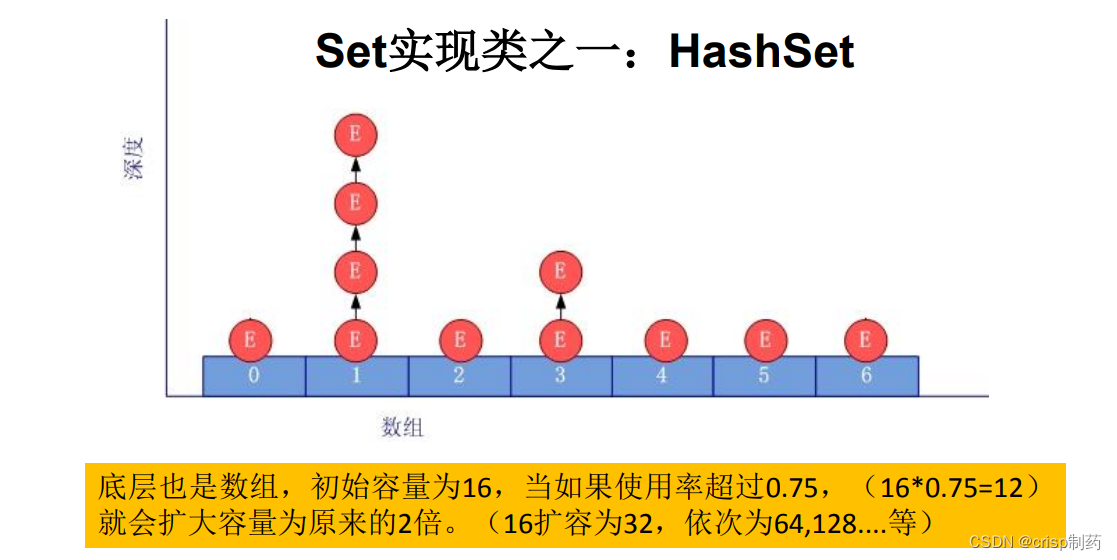
3. 常用方法
Set接口中没额外定义新的方法,使用的都是Collection中声明过的方法。
3.1 重写hashCode()的基本方法
- 在程序运行时,同一个对象多次调用
hashCode()方法应该返回相同的值。 - 当两个对象的
equals()方法比较返回true时,这两个对象的hashCode()方法的返回值也应相等。 - 对象中用作
equals()方法比较的Field,都应该用来计算hashCode值。
3.2 重写
equals()方法基本原则- 以自定义的 Customer类为例,何时需要重写
equals()? - 当一个类有自己特有的“逻辑相等”概念,当改写equals()的时候,总是要改写
hash Code(),根据一个类的 equals方法(改写后),两个截然不同的实例有可能在逻辑上是相等的,但是,根据Object.hashCode()方法,它们仅仅是两个对象。 - 因此,违反了相等的对象必须具有相等的散列码.
- 结论:复写equals方法的时候一般都需要同时复写 hashCode 方法。通常参与计算 hashCode的对象的属性也应该参与到
equals()中进行计算。
3.3 Eclipse/IDEA工具里hashCode()重写
以Eclipse/DEA为例,在自定义类中可以调用工具自动重写
equals()和hashCode()问题:为什么用 Eclipse/IDEA复写 hash Code方法,有31这个数字?
- 选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突)
- 并且31只占用5bits,相乘造成数据溢出的概率较小。
- 31可以由i*31==(<<5)-1来表示,现在很多虚拟机里面都有做相关优化。(提高算法效率)
- 31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有1来整除!(减少冲突)
代码示例:
@Override public boolean equals(Object o) { System.out.println("User equals()...."); if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; User user = (User) o; if (age != user.age) return false; return name != null ? name.equals(user.name) : user.name == null; } @Override public int hashCode() { //return name.hashCode() + age; int result = name != null ? name.hashCode() : 0; result = 31 * result + age; return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4. 常用实现类:
|----Collection接口:单列集合,用来存储一个一个的对象 |----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合” |----HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值 |----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历,对于频繁的遍历操作,LinkedHashSet效率高于HashSet. |----TreeSet:可以按照添加对象的指定属性,进行排序。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.1 HashSet
- Hashset是Set接口的典型实现,大多数时候使用Set集合时都使用这个实现类。
- HashSet按Hash算法来存储集合中的元素,因此具有很好的存取、查找、删除性能。
- HashSet具有以下特点:
- 不能保证元素的排列顺序
- HashSet不是线程安全的
- 集合元素可以是nul
- HashSet集合判断两个元素相等的标准:两个对象通过hashCode()方法比较相等,并且两个对象的equals()方法返回值也相等。
- 对于存放在Set容器中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”
代码示例:
@Test //HashSet使用 public void test1(){ Set set = new HashSet(); set.add(454); set.add(213); set.add(111); set.add(123); set.add(23); set.add("AAA"); set.add("EEE"); set.add(new User("Tom",34)); set.add(new User("Jarry",74)); Iterator iterator = set.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
4.2 LinkedHashSet
- LinkedhashSet是HashSet的子类
- LinkedhashSet根据元素的hashCode值来决定元素的存储位置但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
- LinkedhashSet插入性能略低于HashSet,但在迭代访问Set里的全部元素时有很好的性能。
- LinkedhashSet不允许集合元素重复。
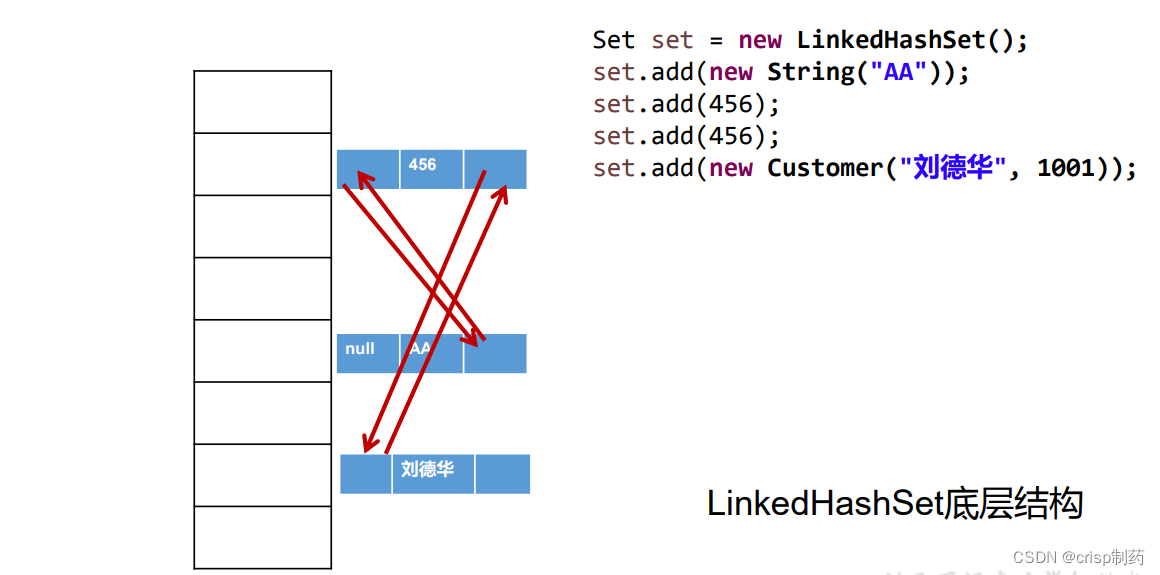
代码示例:
@Test //LinkedHashSet使用 public void test2(){ Set set = new LinkedHashSet(); set.add(454); set.add(213); set.add(111); set.add(123); set.add(23); set.add("AAA"); set.add("EEE"); set.add(new User("Tom",34)); set.add(new User("Jarry",74)); Iterator iterator = set.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4.3 TreeSet
- Treeset是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。
- TreeSet底层使用红黑树结构存储数据
- 新增的方法如下:(了解)
Comparator comparator()Object first()Object last()Object lower(object e)Object higher(object e)SortedSet subSet(fromElement, toElement)SortedSet headSet(toElement)SortedSet tailSet(fromElement)
- TreeSet两种排序方法:自然排序和定制排序。默认情况下,TreeSet采用自然排序。
- 红黑树的特点:有序,查询效率比List快
代码示例:
@Test public void test1(){ Set treeSet = new TreeSet(); treeSet.add(new User("Tom",34)); treeSet.add(new User("Jarry",23)); treeSet.add(new User("mars",38)); treeSet.add(new User("Jane",56)); treeSet.add(new User("Jane",60)); treeSet.add(new User("Bruce",58)); Iterator iterator = treeSet.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
5. 存储对象所在类的要求:
5.1HashSet/LinkedHashSet:
- 要求:向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()
- 要求:重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
重写两个方法的小技巧:对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
5.2 TreeSet:
- 自然排序中,比较两个对象是否相同的标准为:
compareTo()返回0.不再是equals() - 定制排序中,比较两个对象是否相同的标准为:
compare()返回0.不再是equals()
6. TreeSet的使用
6.1 使用说明:
- 向TreeSet中添加的数据,要求是相同类的对象。
- 两种排序方式:自然排序(实现Comparable接口 和 定制排序(Comparator)
6.2 常用的排序方式:
方式一:自然排序
- 自然排序:TreeSet会调用集合元素的
compareTo(object obj)方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列 - 如果试图把一个对象添加到Treeset时,则该对象的类必须实现Comparable接口。
- 实现Comparable的类必须实现
compareTo(Object obj)方法,两个对象即通过compareTo(Object obj)方法的返回值来比较大小
- 实现Comparable的类必须实现
- Comparable的典型实现:
- BigDecimal、BigInteger以及所有的数值型对应的包装类:按它们对应的数值大小进行比较
- Character:按字符的unic!ode值来进行比较
- Boolean:true对应的包装类实例大于fase对应的包装类实例
- String:按字符串中字符的unicode值进行比较
- Date、Time:后边的时间、日期比前面的时间、日期大
- 向TreeSet中添加元素时,只有第一个元素无须比较
compareTo()方法,后面添加的所有元素都会调用compareTo()方法进行比较。 - 因为只有相同类的两个实例才会比较大小,所以向 TreeSet中添加的应该是同一个类的对象。 对于TreeSet集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过
compareTo(Object obj)方法比较返回值。 - 当需要把一个对象放入TreeSet中,重写该对象对应的equals()方法时,应保证该方法与
compareTo(Object obj)方法有一致的结果:如果两个对象通过equals()方法比较返回true,则通过compareTo(object ob)方法比较应返回0。否则,让人难以理解。
@Test public void test1(){ TreeSet set = new TreeSet(); //失败:不能添加不同类的对象 // set.add(123); // set.add(456); // set.add("AA"); // set.add(new User("Tom",12)); //举例一: // set.add(34); // set.add(-34); // set.add(43); // set.add(11); // set.add(8); //举例二: set.add(new User("Tom",12)); set.add(new User("Jerry",32)); set.add(new User("Jim",2)); set.add(new User("Mike",65)); set.add(new User("Jack",33)); set.add(new User("Jack",56)); Iterator iterator = set.iterator(); while(iterator.hasNext()){ System.out.println(iterator.next()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
方式二:定制排序
- TreeSet的自然排序要求元素所属的类实现Comparable接口,如果元素所属的类没有实现 Comparable接口,或不希望按照升序(默认情况)的方式排列元素或希望按照其它属性大小进行排序,则考虑使用定制排序。定制排序,通过 Comparator接口来实现。需要重写 compare(T o1,T o2)方法。
- 利用
int compare(T o1,T o2)方法,比较o1和o2的大小:如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2。 - 要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器。
- 此时,仍然只能向Treeset中添加类型相同的对象。否则发生
ClassCastException异常 - 使用定制排序判断两个元素相等的标准是:通过 Comparator比较两个元素返回了0
@Test public void test2(){ Comparator com = new Comparator() { //照年龄从小到大排列 @Override public int compare(Object o1, Object o2) { if(o1 instanceof User && o2 instanceof User){ User u1 = (User)o1; User u2 = (User)o2; return Integer.compare(u1.getAge(),u2.getAge()); }else{ throw new RuntimeException("输入的数据类型不匹配"); } } }; TreeSet set = new TreeSet(com); set.add(new User("Tom",12)); set.add(new User("Jerry",32)); set.add(new User("Jim",2)); set.add(new User("Mike",65)); set.add(new User("Mary",33)); set.add(new User("Jack",33)); set.add(new User("Jack",56)); Iterator iterator = set.iterator(); while(iterator.hasNext()){ System.out.println(iterator.next()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
六、Map接口
- Map与Collection并列存在。用于保存具有映射关系的数据:key-value
- Map中的key和value都可以是任何引用类型的数据
- Map中的key用set来存放,不允许重复,即同一个Map对象所对应的类,须重写
hashCode()和equals()方法 - 常用 String类作为Map的“键”
- key和value之间存在单向一对一关系,即通过指定的key总能找到唯一的、确定的value
- Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中,HashMap是Map接口使用频率最高的实现类
1. 常见实现类结构
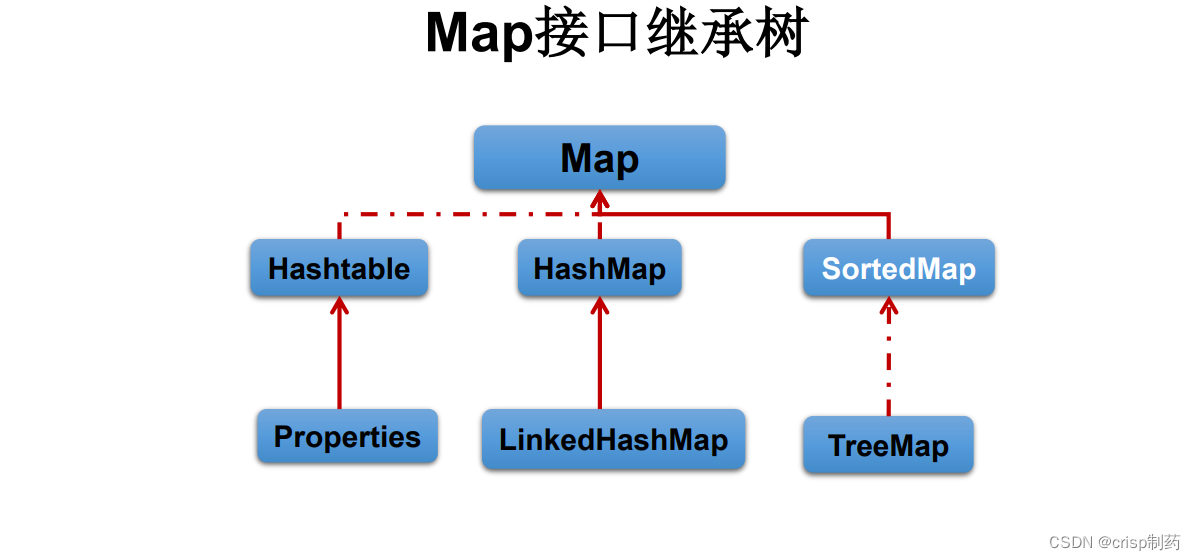
|----Map:双列数据,存储key-value对的数据 —类似于高中的函数:y = f(x)
|----HashMap:作为Map的主要实现类;线程不安全的,效率高;存储null的key和value
|----LinkedHashMap:保证在遍历map元素时,可以照添加的顺序实现遍历。
原因:在原的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。
对于频繁的遍历操作,此类执行效率高于HashMap。
|----TreeMap:保证照添加的key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序
底层使用红黑树
|----Hashtable:作为古老的实现类;线程安全的,效率低;不能存储null的key和value
|----Properties:常用来处理配置文件。key和value都是String类型HashMap的底层: 数组+链表 (JDK 7.0及之前)
数组+链表+红黑树 (JDK 8.0以后)1.1 HashMap
- HashMap是Map接口使用频率最高的实现类。
- 允许使用null键和null值,与 HashSet一样,不保证映射的顺序。
- 所有的key构成的集合是set:无序的、不可重复的。所以,key所在的类要重写equals()和 hashCode()
- 所有的value构成的集合是Collection:无序的、可以重复的。所以,value所在的类要重写:equals()
- 一个key-value构成一个entry
- 所有的entry构成的集合是Set:无序的、不可重复的
- HashMap判断两个key相等的标准是:两个key通过
equals()方法返回true,hashCode值也相等。 - HashMap判断两个value相等的标准是:两个value通过
equals()方法返回true.
代码示例:
@Test public void test1(){ Map map = new HashMap(); map.put(null,123); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.2 LinkedHashMap
- LinkedHashMap底层使用的结构与HashMap相同,因为LinkedHashMap继承于HashMap.
- 区别就在于:LinkedHashMap内部提供了Entry,替换HashMap中的Node.
- 与Linkedhash Set类似,LinkedHashMap可以维护Map的迭代顺序:迭代顺序与Key-value对的插入顺序一致
代码示例:
@Test public void test2(){ Map map = new LinkedHashMap(); map.put(123,"AA"); map.put(345,"BB"); map.put(12,"CC"); System.out.println(map); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.3 TreeMap
- TreeMap存储Key-Value对时,需要根据key-value对进行排序。TreeMap可以保证所有的 Key-Value对处于有序状态。
- TreeSet底层使用红黑树结构存储数据
- TreeMap的Key的排序:
- 自然排序: TreeMap的所有的Key必须实现Comparable接口,而且所有的Key应该是同一个类的对象,否则将会抛出ClasssCastEXception()
- 定制排序:创建 TreeMap时,传入一个 Comparator对象,该对象负责对TreeMap中的所有key进行排序。此时不需要Map的Key实现Comparable接口
- TreeMap判断两个key相等的标准:两个key通过 compareTo()方法或者compare()方法返回0.
1.4 Hashtable
- Hashtable是个古老的Map实现类,JDK1.0就提供了。不同于 HashMap,Hashtable是线程安全的.
- Hashtable实现原理和HashMap相同,功能相同。底层都使用哈希表结构,查询速度快,很多情况下可以互用
- 与HashMap.不同,Hashtable不允许使用null作为key和value.
- 与HashMap一样,Hashtable也不能保证其中Key-value对的顺序.
- Hashtable判断两个key相等、两个value相等的标准,与HashMap-致.
1.5 Properties
- Properties类是Hashtable的子类,该对象用于处理属性文件
- 由于属性文件里的key、value都是字符串类型,所以Properties里的key和value都是字符串类型
- 存取数据时,建议使用
setProperty(String key,String value)方法和getProperty(String key)方法
代码示例:
//Properties:常用来处理配置文件。key和value都是String类型 public static void main(String[] args) { FileInputStream fis = null; try { Properties pros = new Properties(); fis = new FileInputStream("jdbc.properties"); pros.load(fis);//加载流对应的文件 String name = pros.getProperty("name"); String password = pros.getProperty("password"); System.out.println("name = " + name + ", password = " + password); } catch (IOException e) { e.printStackTrace(); } finally { if(fis != null){ try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } } } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2. 存储结构的理解:
- Map中的key:无序的、不可重复的,使用Set存储所的key —> key所在的类要重写equals()和hashCode() (以HashMap为例)
- Map中的value:无序的、可重复的,使用Collection存储所的value —>value所在的类要重写equals()
- 一个键值对:key-value构成了一个Entry对象。
- Map中的entry:无序的、不可重复的,使用Set存储所的entry.
-
3. 常用方法
3.1添加、删除、修改操作:
Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中void putAll(Map m):将m中的所有key-value对存放到当前map中Object remove(Object key):移除指定key的key-value对,并返回valuevoid clear():清空当前map中的所有数据
代码示例:
@Test public void test1() { Map map = new HashMap(); //Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中 map.put("AA",123); map.put("ZZ",251); map.put("CC",110); map.put("RR",124); map.put("FF",662); System.out.println(map);//{AA=123, ZZ=251, CC=110, RR=124, FF=662} //Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中 map.put("ZZ",261); System.out.println(map);//{AA=123, ZZ=261, CC=110, RR=124, FF=662} //void putAll(Map m):将m中的所有key-value对存放到当前map中 HashMap map1 = new HashMap(); map1.put("GG",435); map1.put("DD",156); map.putAll(map1); System.out.println(map);//{AA=123, ZZ=261, CC=110, RR=124, FF=662, GG=435, DD=156} //Object remove(Object key):移除指定key的key-value对,并返回value Object value = map.remove("GG"); System.out.println(value);//435 System.out.println(map);//{AA=123, ZZ=261, CC=110, RR=124, FF=662, DD=156} //void clear():清空当前map中的所有数据 map.clear(); System.out.println(map.size());//0 与map = null操作不同 System.out.println(map);//{} } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
3.2元素查询的操作:
Object get(Object key):获取指定key对应的valueboolean containsKey(Object key):是否包含指定的keyboolean containsValue(Object value):是否包含指定的valueint size():返回map中key-value对的个数boolean isEmpty():判断当前map是否为空boolean equals(Object obj):判断当前map和参数对象obj是否相等
代码示例:
@Test public void test2() { Map map = new HashMap(); map.put("AA", 123); map.put("ZZ", 251); map.put("CC", 110); map.put("RR", 124); map.put("FF", 662); System.out.println(map);//{AA=123, ZZ=251, CC=110, RR=124, FF=662} //Object get(Object key):获取指定key对应的value System.out.println(map.get("AA"));//123 //boolean containsKey(Object key):是否包含指定的key System.out.println(map.containsKey("ZZ"));//true //boolean containsValue(Object value):是否包含指定的value System.out.println(map.containsValue(123));//true //int size():返回map中key-value对的个数 System.out.println(map.size());//5 //boolean isEmpty():判断当前map是否为空 System.out.println(map.isEmpty());//false //boolean equals(Object obj):判断当前map和参数对象obj是否相等 Map map1 = new HashMap(); map1.put("AA", 123); map1.put("ZZ", 251); map1.put("CC", 110); map1.put("RR", 124); map1.put("FF", 662); System.out.println(map.equals(map1));//true } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
3.3 元视图操作的方法:
Set keySet():返回所有key构成的Set集合Collection values():返回所有value构成的Collection集合Set entrySet():返回所有key-value对构成的Set集合
代码示例:
@Test public void test3() { Map map = new HashMap(); map.put("AA", 123); map.put("ZZ", 251); map.put("CC", 110); map.put("RR", 124); map.put("FF", 662); System.out.println(map);//{AA=123, ZZ=251, CC=110, RR=124, FF=662} //遍历所有的key集:Set keySet():返回所有key构成的Set集合 Set set = map.keySet(); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } System.out.println("--------------"); //遍历所有的value集:Collection values():返回所有value构成的Collection集合 Collection values = map.values(); for (Object obj : values) { System.out.println(obj); } System.out.println("---------------"); //Set entrySet():返回所有key-value对构成的Set集合 Set entrySet = map.entrySet(); Iterator iterator1 = entrySet.iterator(); //方式一: while (iterator1.hasNext()) { Object obj = iterator1.next(); //entrySet集合中的元素都是entry Map.Entry entry = (Map.Entry) obj; System.out.println(entry.getKey() + "-->" + entry.getValue()); } System.out.println("--------------"); //方式二: Set keySet = map.keySet(); Iterator iterator2 = keySet.iterator(); while (iterator2.hasNext()) { Object key = iterator2.next(); Object value = map.get(key); System.out.println(key + "==" + value); } } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
总结:常用方法:
- 添加:
put(Object key,Object value) - 删除:
remove(Object key) - 修改:
put(Object key,Object value) - 查询:
get(Object key) - 长度:
size() - 遍历:
keySet()/values()/entrySet()
4. 内存结构说明:(难点)
4.1 HashMap在JDK 7.0中实现原理:
4.1.1 HashMap的存储结构:
JDK 7.0及以前的版本:HashMap是数组+链表结构(地址链表法)
JDK 8.0版本以后:HashMap是数组+链表+红黑树实现
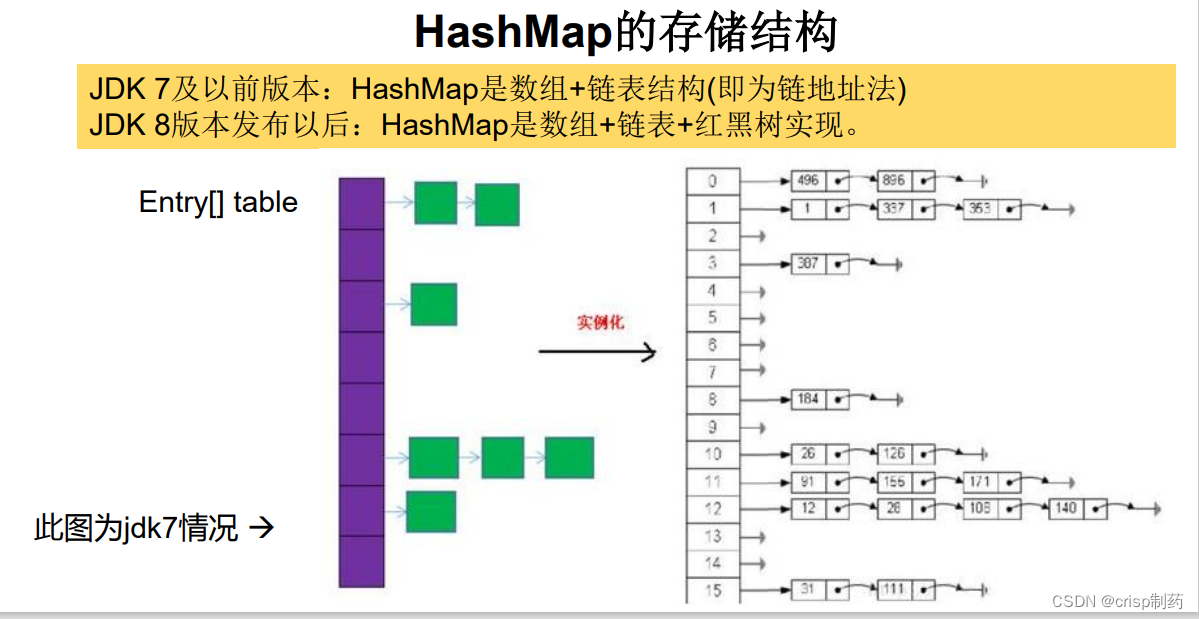
4.1.2 对象创建和添加过程:HashMap map = new HashMap():在实例化以后,底层创建了长度是16的一维数组
Entry[] table。…可能已经执行过多次put…
map.put(key1,value1):- 首先,调用key1所在类的
hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。 - 如果此位置上的数据为空,此时的key1-value1添加成功。 ----情况1
- 如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据的哈希值:
- 如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。----情况2
- 如果key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2)方法,比较:
- 如果
equals()返回false:此时key1-value1添加成功。----情况3 - 如果
equals()返回true:使用value1替换value2。
- 如果
补充:关于情况2和情况3:此时key1-value1和原来的数据以链表的方式存储。
在不断的添加过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
4.1.3 HashMap的扩容
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对 HashMap的数组进行扩容,而在HashMap数组扩容之后,原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是 resize。
4.1.4 HashMap扩容时机
当HashMap中的元素个数超过数组大小(数组总大小 length,不是数组中个数)* loadFactor时,就会进行数组扩容,loadFactor的默认值(
DEFAULT_LOAD_ FACTOR)为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小(DEFAULT INITIAL CAPACITY)为16,那么当 HashMap中元素个数超过16 * 0.75=12(这个值就是代码中的 threshold值,也叫做临界值)的时候,就把数组的大小扩展为2 * 16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知 HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。4.2 HashMap在JDK 8.0底层实现原理:
4.2.1 HashMap的存储结构:
HashMap的内部存储结构其实是数组+链表+红黑树的组合。
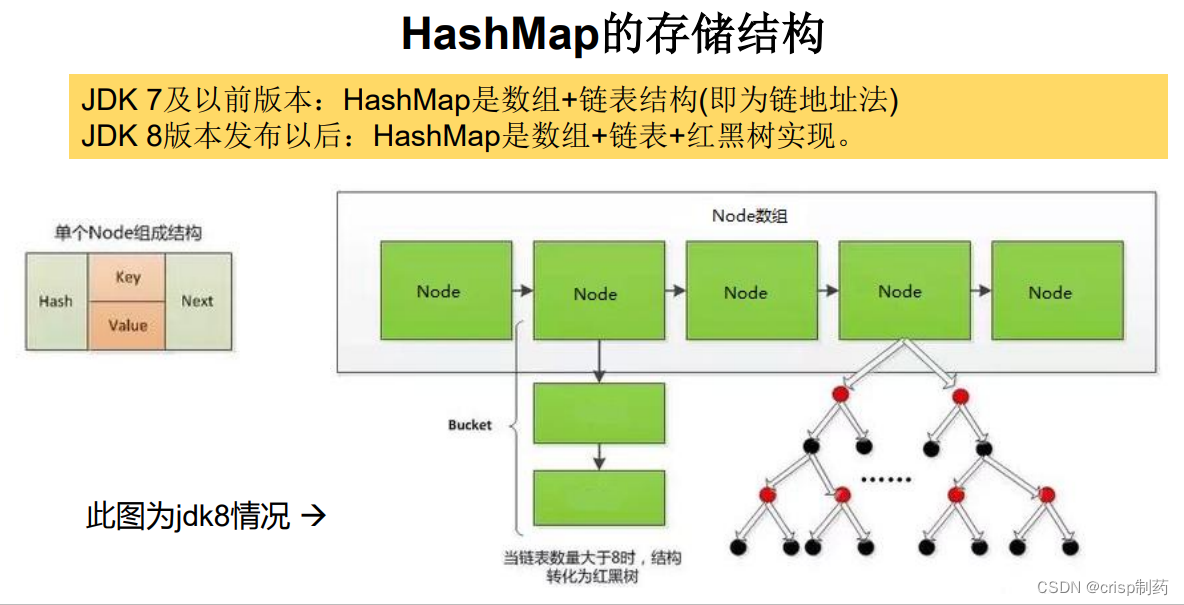
4.2.2 HashMap添加元素的过程:当实例化一个HashMap时,会初始化 initialCapacity和loadFactor,在put第一对映射关系时,系统会创建一个长度为 initialCapacity的Node数组,这个长度在哈希表中被称为容量(Capacity),在这个数组中可以存放元素的位置我们称之为“桶”( bucket),每个bucket都有自己的索引,系统可以根据索引快速的查找bucket中的元素。
每个 bucket中存储一个元素,即一个Node对象,但每一个Noe对象可以带个引用变量next,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Node链。也可能是一个一个 TreeNode对象,每一个Tree node对象可以有两个叶子结点left和right,因此,在一个桶中,就有可能生成一个TreeNode树。而新添加的元素作为链表的last,或树的叶子结点。
4.2.3 HashMap的扩容机制:
- 当HashMapl中的其中一个链的对象个数没有达到8个和JDK 7.0以前的扩容方式一样。
- 当HashMapl中的其中一个链的对象个数如果达到了8个,此时如果 capacity没有达到64,那么HashMap会先扩容解决,如果已经达到了64,那么这个链会变成树,结点类型由Node变成 Tree Node类型。当然,如果当映射关系被移除后,下次resize方法时判断树的结点个数低于6个,也会把树再转为链表。
4.2.4 JDK 8.0与JDK 7.0中HashMap底层的变化:
new HashMap():底层没有创建一个长度为16的数组- JDK 8.0底层的数组是:
Node[],而非Entry[] - 首次调用put()方法时,底层创建长度为16的数组
- JDK 7.0底层结构只有:数组+链表。JDK 8.0中底层结构:数组+链表+红黑树。
- 形成链表时,七上八下(jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素)
- 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。
4.3 HashMap底层典型属性的属性的说明:
DEFAULT_INITIAL_CAPACITY: HashMap的默认容量,16DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75threshold:扩容的临界值,= 容量*填充因子:16 * 0.75 => 12TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:JDK 8.0引入MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
4.4 LinkedHashMap的底层实现原理
- LinkedHashMap底层使用的结构与HashMap相同,因为LinkedHashMap继承于HashMap.
- 区别就在于:LinkedHashMap内部提供了Entry,替换HashMap中的Node.
- 与Linkedhash Set类似,LinkedHashMap可以维护Map的迭代顺序:迭代顺序与Key-value对的插入顺序一致
HashMap中内部类Node源码:
static class Node<K,V> implements Map.Entry<K,V>{ final int hash; final K key; V value; Node<K,V> next; } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
LinkedHashM中内部类Entry源码:
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after;//能够记录添加的元素的先后顺序 Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5. TreeMap的使用
向TreeMap中添加key-value,要求key必须是由同一个类创建的对象 要照key进行排序:自然排序 、定制排序
代码示例:
//自然排序 @Test public void test() { TreeMap map = new TreeMap(); User u1 = new User("Tom", 23); User u2 = new User("Jarry", 18); User u3 = new User("Bruce", 56); User u4 = new User("Davie", 23); map.put(u1, 98); map.put(u2, 16); map.put(u3, 92); map.put(u4, 100); Set entrySet = map.entrySet(); Iterator iterator = entrySet.iterator(); while (iterator.hasNext()) { Object obj = iterator.next(); Map.Entry entry = (Map.Entry) obj; System.out.println(entry.getKey() + "=" + entry.getValue()); } } //定制排序:按照年龄大小排 @Test public void test2() { TreeMap map = new TreeMap(new Comparator() { @Override public int compare(Object o1, Object o2) { if (o1 instanceof User && o2 instanceof User) { User u1 = (User) o1; User u2 = (User) o2; return Integer.compare(u1.getAge(), u2.getAge()); } throw new RuntimeException("输入数据类型错误"); } }); User u1 = new User("Tom", 23); User u2 = new User("Jarry", 18); User u3 = new User("Bruce", 56); User u4 = new User("Davie", 23); map.put(u1, 98); map.put(u2, 16); map.put(u3, 92); map.put(u4, 100); Set entrySet = map.entrySet(); Iterator iterator = entrySet.iterator(); while (iterator.hasNext()) { Object obj = iterator.next(); Map.Entry entry = (Map.Entry) obj; System.out.println(entry.getKey() + "=" + entry.getValue()); } } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
6.使用Properties读取配置文件
properties类是hashtable的子类
代码示例:
//Properties:常用来处理配置文件。key和value都是String类型 public static void main(String[] args) { FileInputStream fis = null; try { Properties pros = new Properties(); fis = new FileInputStream("jdbc.properties"); pros.load(fis);//加载流对应的文件 String name = pros.getProperty("name"); String password = pros.getProperty("password"); System.out.println("name = " + name + ", password = " + password); } catch (IOException e) { e.printStackTrace(); } finally { if(fis != null){ try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } } } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
7.面试题
- HashMap的底层实现原理?
- HashMap 和 Hashtable的异同?
- CurrentHashMap 与 Hashtable的异同?
- 负载因子值的大小,对HashMap的影响?
- 负载因子的大小决定了HashMap的数据密度。
- 负载因子越大密度越大,发生碰撞的几率越高,数组中的链表越容易长,造成査询或插入时的比较次数增多,性能会下降
- 负载因子越小,就越容易触发扩容,数据密度也越小,意味着发生碰撞的几率越小,数组中的链表也就越短,查询和插入时比较的次数也越小,性能会更高。但是会浪费一定的内容空间。而且经常扩容也会影响性能,建议初始化预设大一点的空间
- 按照其他语言的参考及研究经验,会考虑将负载因子设置为0.7~0.75,此时平均检索长度接近于常数。
七、Collection工具类的使用
1.作用:
Collections是一个操作Set、Lit和Map等集合的工具类
Collections中提供了一系列静态的方法对集合元素进行排序、査询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法
2.常用方法:
2.1排序操作
reverse(List):反转 List 中元素的顺序shuffle(List):对 List 集合元素进行随机排序sort(List):根据元素的自然顺序对指定 List 集合元素升序排序sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
代码示例:
@Test public void test1() { List list = new ArrayList(); list.add(123); list.add(43); list.add(765); list.add(-97); list.add(0); System.out.println(list);//[123, 43, 765, -97, 0] //reverse(List):反转 List 中元素的顺序 Collections.reverse(list); System.out.println(list);//[0, -97, 765, 43, 123] //shuffle(List):对 List 集合元素进行随机排序 Collections.shuffle(list); System.out.println(list);//[765, -97, 123, 0, 43] //sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序 Collections.sort(list); System.out.println(list);//[-97, 0, 43, 123, 765] //swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换 Collections.swap(list,1,4); System.out.println(list);//[-97, 765, 43, 123, 0] } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2.2查找、替换
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素Object min(Collection)Object min(Collection,Comparator)int frequency(Collection,Object):返回指定集合中指定元素的出现次数void copy(List dest,List src):将src中的内容复制到dest中boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所旧值
代码示例:
@Test public void test2(){ List list = new ArrayList(); list.add(123); list.add(123); list.add(123); list.add(43); list.add(765); list.add(-97); list.add(0); System.out.println(list);//[123, 43, 765, -97, 0] //Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素 Comparable max = Collections.max(list); System.out.println(max);//765 //Object min(Collection) Comparable min = Collections.min(list); System.out.println(min);//-97 //int frequency(Collection,Object):返回指定集合中指定元素的出现次数 int frequency = Collections.frequency(list,123); System.out.println(frequency);//3 //void copy(List dest,List src):将src中的内容复制到dest中 List dest = Arrays.asList(new Object[list.size()]); System.out.println(dest.size());//7 Collections.copy(dest,list); System.out.println(dest);//[123, 123, 123, 43, 765, -97, 0] //boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值 } 复制代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2.3 同步控制
Collections 类中提供了多个
synchronizedXxx()方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题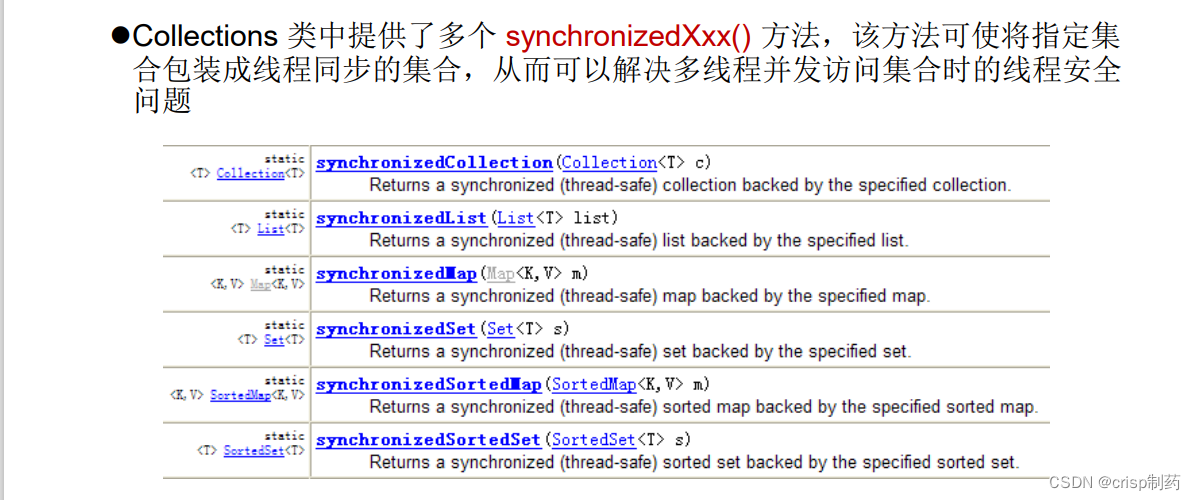
总结:今天讲了整个java中集合的一些基础部分,喜欢的话可以三连支持一下~
-
相关阅读:
02 【常用类型(上)】
logback--进阶--03--日志打印步骤
iOS 开发代码规范
875. 快速幂
中秋《乡村振兴战略下传统村落文化旅游设计》许少辉八月新书——2023学生思乡季辉少许
AQS核心原理分析《下》
在华为和比亚迪干了5年测试,月薪25K,熬夜总结出来的划水经验.....
ArcGIS Pro SDK (三)Addin控件 1 按钮类
nginx降权及匹配php
etcdctl-管理操作etcd集群
- 原文地址:https://blog.csdn.net/crisp0530/article/details/124975148