-
机器学习理论之(13):感知机 Perceptron;多层感知机(神经网络)
表示学习 (representation Learning)
- 表示学习是神经网络的一个常见应用
- 例如图像相关的任务,数据的特征维度太高(通常在几十万上百万的维度,因为图像的每个像素点都是一个特征)
- 深度学习中常用 embedding 来对高维度数据进行处理,将其重新编码成维度较低的特征。
- 深度网络可以通过学习 embedding 后的特征来完成各种任务

生物神经元 V.S. 人造神经元

- 输入信号,输出信号,各方输入信号加权取平均,如果超过某一个阈值就将信号传向下一个神经元

- x ⃗ i = < x i 1 , x i 2 , . . . , x i n > \vec{x}_i=<x_{i1},x_{i2},..., x_{in}> xi=<xi1,xi2,...,xin> 代表各方的输入组成的输入向量, b b b 是常数偏置项bias,对这些量进行加权求和(参数的权重同样是一个向量 w ⃗ = < w 1 , . . . , w n > ∈ R n \vec{w}=<w_1,...,w_n>\in \mathbb{R^n} w=<w1,...,wn>∈Rn)然后通过一个激活函数 activation function f f f 这也是个可选的超参数,可以为神经元选用不同的激活函数,激活后的值是一个标量 y i ∈ R n y_i\in \mathbb{R^n} yi∈Rn继续传入下一个神经元;
- 这个过程中的超参数是 f f f 激活函数,需要学习的参数是 w ⃗ \vec{w} w 和 b ( b ≡ w 0 ) b(b\equiv w_0) b(b≡w0)
- 形式化的数学表示为:
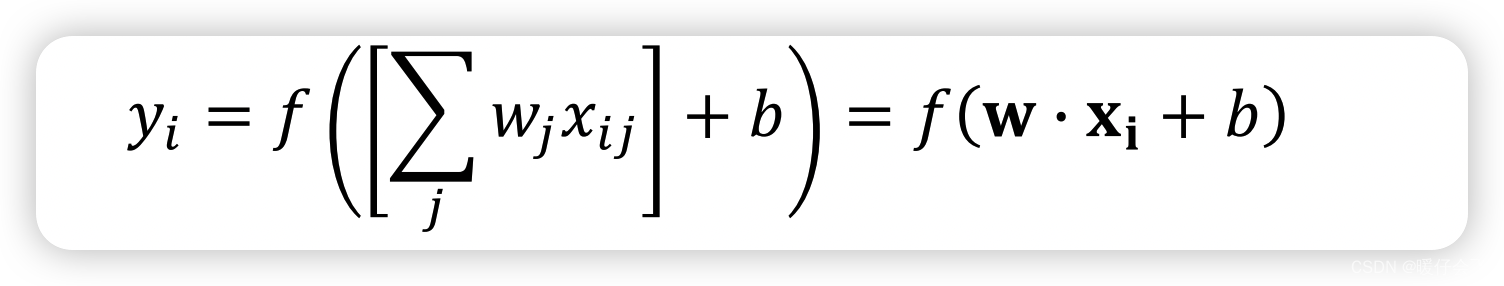
感知机 (Perceptron)
- 感知机本质上就是只有单个神经元的神经网络
- 一个感知机就是一个二元的线性分类器,形式化表示如下:
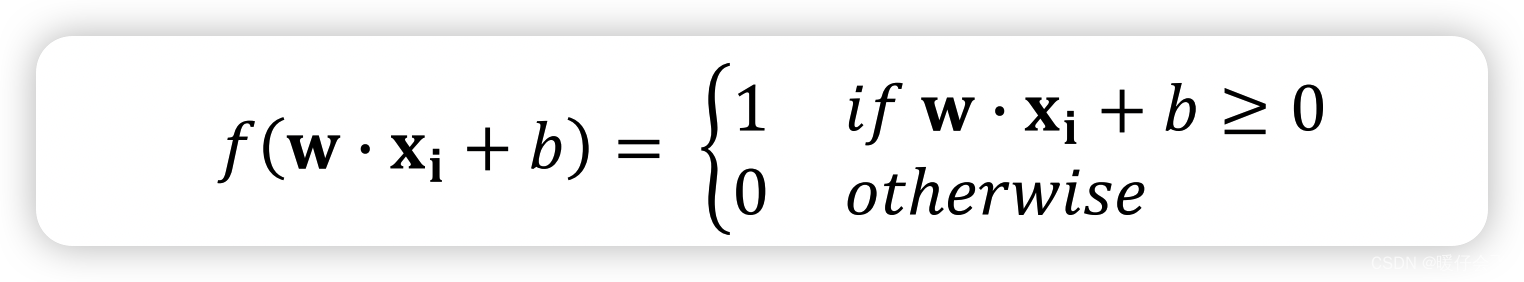
- 这里的阈值是 0,也就是说只要 input 的加权和 >=0 那么感知机就输出 1
训练感知机(Training Perceptron)
- 训练感知机是试图求算最佳的参数向量 w ⃗ \vec{w} w 通过最小化训练误差
- 常用的方法是通过迭代(iterative)的方式对训练集上进行反复训练
- 具体的算法可以如下表示:

- 基本思想就是对于每一个训练样本 ( x i , y i ) (x_i,y_i) (xi,yi) 得到它的预测值和实际值之间的误差,并通过这个样本的误差和优化算法来更新所有的需要求算的参数 w j w_j wj ;因为每个样本 x i x_i xi 的特征维度是 j j j 因此,整个模型一共会有 j j j 个参数。
- 参数迭代的方式是梯度下降,图中使用的损失函数是: y i 2 − y ^ i 2 \sqrt{y^2_i-\hat{y}^2_i} yi2−y^i2,因此它的 梯度 是图中下标红线的部分
- λ \lambda λ 是学习率,是所有参数共有的控制梯度下降速度的参数,对于每个 w j w_j wj, λ \lambda λ 都是一样的
- 在红线下标的式子的最后一项 x i j x_{ij} xij 是这个特征自身的值,如果 y i − y ^ i y_i-\hat{y}_i yi−y^i 是个负数,那么 w j w_j wj 就会向更小的方向更新,同时如果 x i j x_{ij} xij 较大,那么这个特征梯度下降的速度就会很快。
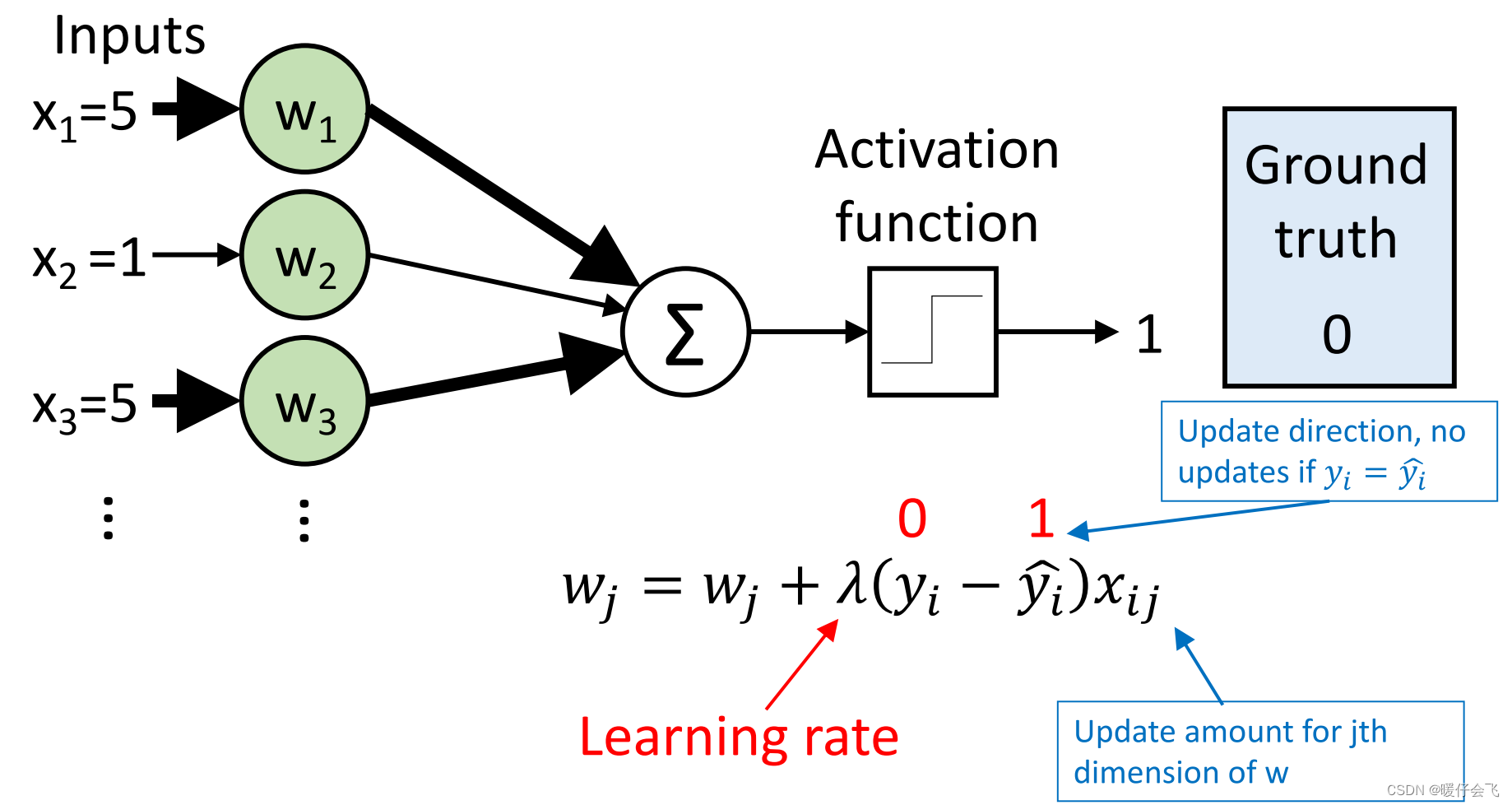
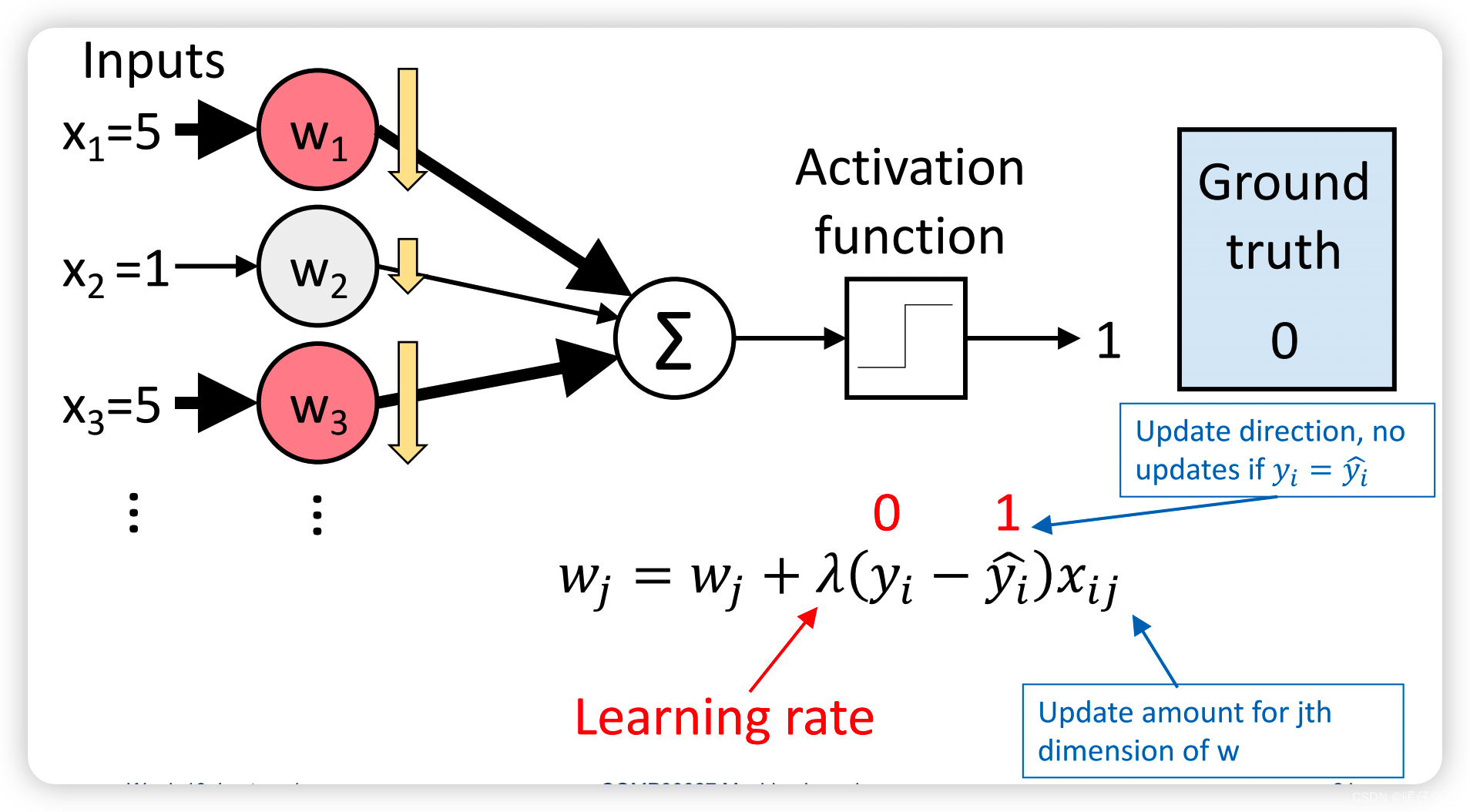
- 这里的每个 x 1 , x 2 . . . x_1,x_2... x1,x2... 应该写成 x i 1 , x i 2 x_{i1},x_{i2} xi1,xi2 也就是表示的特征的值,而不是样本的值。
- 根据计算, w 1 , w 3 w_1,w_3 w1,w3 下降的幅度比 w 2 w_2 w2 大很多,因为他们的 特征值 x i j x_{ij} xij 比较大
- 下面给出一个梯度更新的动态例子:
- 一共有四个训练样本 i = 1...4 i=1...4 i=1...4,每个训练样本的特征数量是 j = 1 , 2 j=1,2 j=1,2 两个
- 计算 y ^ i \hat{y}_i y^i 的公式在左下角,通过参数和样本向量的加权求和,通过激活函数后得到
- 通过 y i , y ^ i y_i, \hat{y}_i yi,y^i 我们可以计算出误差,并通过梯度下降公式来计算每个特征的参数应该如何更新
- 对于 偏置 b b b ,我们始终把它看成是参数向量 w ⃗ \vec{w} w 中的第一个参数 w 0 w_0 w0,统一进行梯度更新求算;我们规定 x i 0 x_{i0} xi0 始终为 1.
- 在进行迭代之前需要给出一个初始化的参数向量,即 w ⃗ = { b , w 1 , w 2 } = { 0 , 0 , 0 } \vec{w}=\{b,w_1,w_2\}=\{0,0,0\} w={b,w1,w2}={0,0,0}
- 第一个 epoch 中:

- 前两个样本的预测值和实际值相同,因此不需要梯度更新
- 第三个样本产生了误差,因此根据梯度更新公式,参数的值被更新成 w ⃗ = { b , w 1 , w 2 } = { − 1 , 0 , 0 } \vec{w}=\{b,w_1,w_2\}=\{-1,0,0\} w={b,w1,w2}={−1,0,0}
- 根据更新后的参数我们计算最后一个样本,发现没有误差,第一个 epoch 中所有的样本都执行了一遍,因此第一个 epoch 结束:

- 第二个 epoch

- 第一个样本就需要进行梯度更新, w j = w j + x i j w_j=w_j+x_{ij} wj=wj+xij 所以 w ⃗ \vec{w} w 被更新成 { − 1 + 1 , 0 + 1 , 0 + 1 } = { 0 , 1 , 1 } \{-1+1, 0+1, 0+1\} = \{0,1,1\} {−1+1,0+1,0+1}={0,1,1}
- 第二个样本是正确的,不需要更新
- 第三个样本又产生了误差,需要梯度更新 w j = w j − x i j w_j=w_j-x_{ij} wj=wj−xij w ⃗ \vec{w} w 被更新成 { 0 − 1 , 1 − 0 , 1 − 0 } = { − 1 , 1 , 1 } \{0-1, 1-0, 1-0\} = \{-1,1,1\} {0−1,1−0,1−0}={−1,1,1}
- 第四个样本不需要梯度更新
- epoch2 结束
- 第三个 epoch:

- 所有样本都没有发生梯度更新,这个模型已经收敛,因此不需要进行新的 epoch。迭代结束。
激活函数(Activation Function)

-
激活函数的作用一方面将加权求和后的信号进行归一化到 [ 0 , 1 ] [0,1] [0,1] 之间,另外一方面可以帮助 多层的感知机模型 获得非线性分类的能力。
-
对于感知机自身的激活函数:
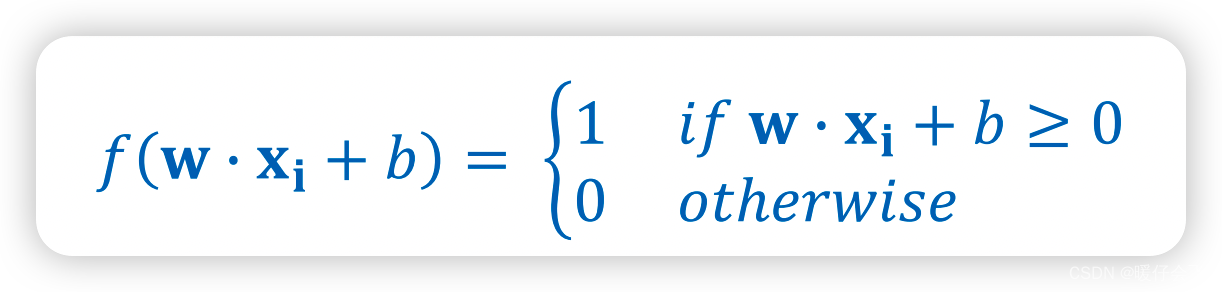
-
这只能对线性可分的数据有一个较好的拟合结果,因为他本身基于的是线性假设,求解的总是一个 w ⃗ ⋅ x i ⃗ + b \vec{w}\cdot \vec{x_i}+b w⋅xi+b 的线性方程。
-
感知机也不能保证分类数据有最大的决策边界(那是 svm 模型的任务)
-
感知机更不能够保证对非线性可分(non-linearly separable)数据拟合的很好。
-
感知机本质上是基于线性假设,如果把激活函数改成 sigmoid 函数,那么感知机就可以成为一个逻辑回归模型
一层感知机
- 我们上面说的概念对应的是一个感知机,对应的是一个神经元结点,那么如果有多个神经元结点,就能用他们来组成一层感知机

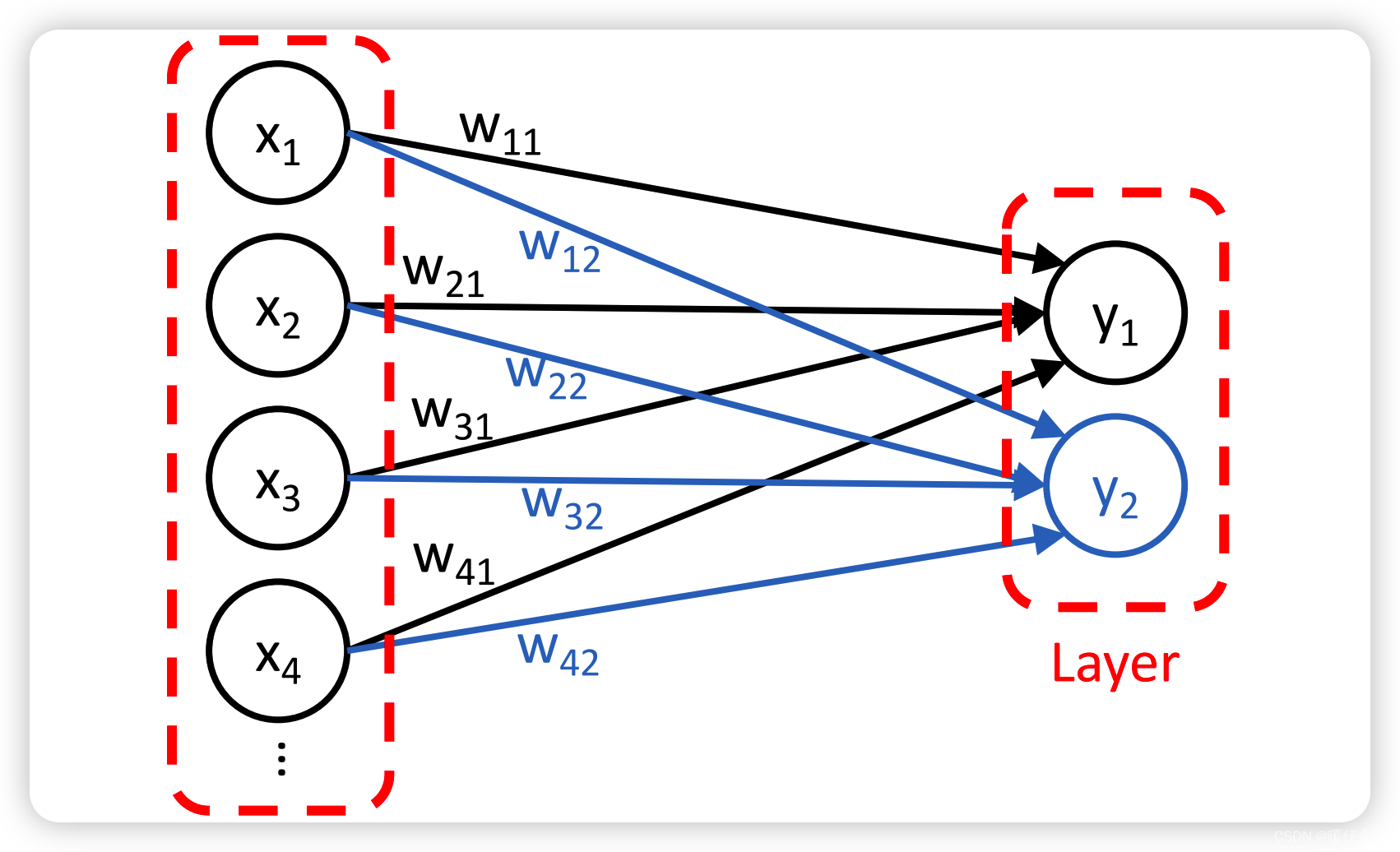
- 那么为什么要把 layer 的概念引入感知机呢?因为同一层内的所有感知机接受的是同样的输入,通过训练可以形成不同的参数,例如第一个节点 y 1 y_1 y1 相关的参数是 w ⃗ i 1 = { w 11 , w 21 . . . } \vec{w}_{i1}=\{w_{11},w_{21}...\} wi1={w11,w21...} 但第二个感知机 y 2 y_2 y2 的相关参数是 w ⃗ i 2 \vec{w}_{i2} wi2。这样的一层感知机对于同一个输入最后就可以给出多个输出的结果,如果再结合 softmax 激活函数,就可以进行多分类任务。当然这个是后面神经网络的内容,我们在这里只是通过这种方式来认识什么是一层感知机。
- 有了一层感知机的概念,就可以扩展到多层感知机。
多层感知机
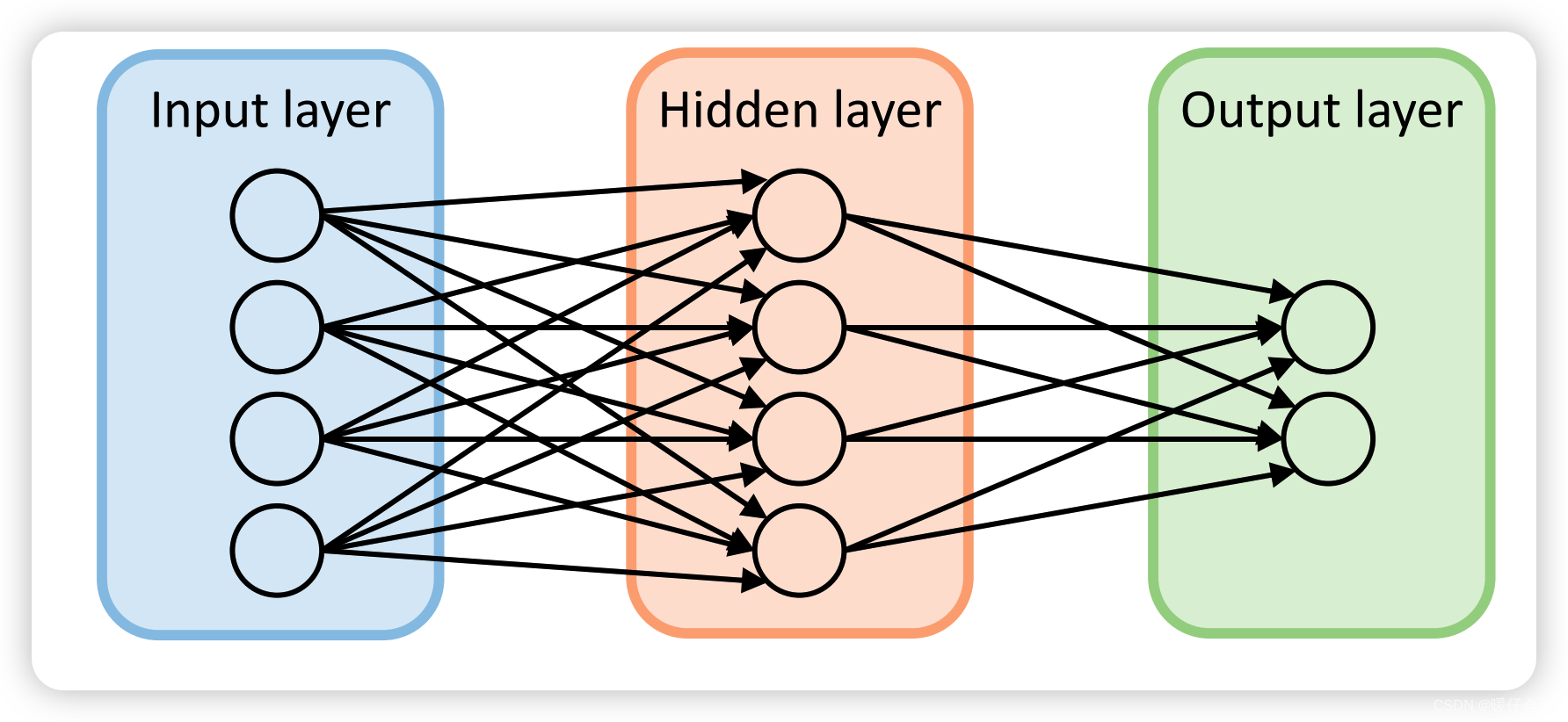
-
多层感知机有三个部分组成:
- 输入层
- 隐藏层
- 输出层
-
输入层的神经元的数量取决于输入样本的特征数
-
输出层的神经元数量取决于分类任务或者是回归任务。
- 在多分类任务中输出层的神经元数量与分类的类别数量一致 + softmax 激活函数
- 二分类任务中,输出层一个神经元 + 阶跃函数作为激活函数
- 回归任务中输出层只有一个神经元 + sigmoid 激活函数

-
隐藏层可以有很多层,图中只画了一层。每个隐藏层存在的意义都是对输入进行重新编码,编码成抽象的向量,然后输出给后面的层。
隐藏层神经元数量选择
- 取决于具体的任务的复杂程度,没有一个特定的参考

hidden layer 如何学习参数
- 通过后向传播算法 backpropagation
- 输出层的预测值和真实标签产生的误差的梯度可以通过 链式法则 传播到任意一个隐藏层,从而根据感知机更新参数的方式来更新每一个神经元的参数。这个过程是借助随机梯度下降的方式来完成的。
- 因此和单个感知机一样,也需要设置一个学习率
λ
\lambda
λ

多层感知机的性质
- 通用逼近定理(Universal approximation theorem) 具有一个 hidden layer 的神经网络可以逼近任意的连续函数。
- 这意味着多层感知机(神经网络)可以拟合任何线性或者非线性的函数(不同于 逻辑回归或者 SVM 只能基于线性可分数据集)
- 上述的复杂的拟合任务必须要借助非线性!
多层感知机如何具备非线性能力
-
例如我们具有一个三层的感知机:一个输入层,一个输出层和一个隐藏层,三个层的参数矩阵我们分别用 w L 0 , w L 1 , w L 2 \textbf{w}_{L_0}, \textbf{w}_{L_1}, \textbf{w}_{L_2} wL0,wL1,wL2 表示。那么一个输入 x i x_i xi 经过整个网络的过程可以表示成:
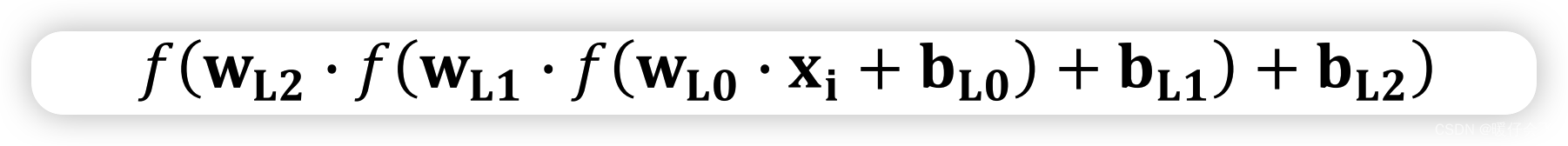
-
其中 f f f 都是非线性的激活函数
-
非常清楚,这个式子可以拟合一个复杂的非线性函数。
-
作为对比,如果不采用任何非线性函数,只是使用上述的三层感知机,那么这个过程可以表示成:
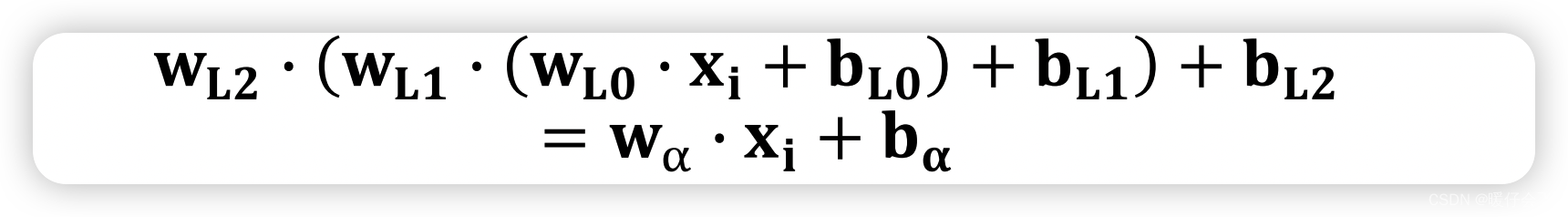
-
通过最后的化简,这还是一个线性的函数,换句话说,还是只能处理线性可分的数据集。
-
因此我们说多层感知机必须搭配非线性的激活函数才能具有强大的非线性拟合能力。
思考
-
因为多层感知机有拟合复杂数据的能力,那么他就一定比线性模型的表现更好么?
- 答案是否定的,因为对于很多简单的数据集,仅用线性假设就可以很好解决, 如果采用太复杂的模型,很容易过拟合。
-
因为神经网络可以在隐藏层学习到他们自己的表示(representation)因此,他们不需要任何特征工程。
- 这个答案也是错的,如果不进行任何特征工程,那么很多噪声数据或者特征就容易给模型的拟合带来不利影响,garbage in garbage out。所以特征工程在很多时候都是需要的。

- 这个答案也是错的,如果不进行任何特征工程,那么很多噪声数据或者特征就容易给模型的拟合带来不利影响,garbage in garbage out。所以特征工程在很多时候都是需要的。
优缺点
- 可以适用多种任务:分类和回归任务
- 通用性很好,可以拟合多种分布
- hidden layer 可以学习到自己的特征表示
- 参数量太大,需要消耗很多的内存资源;
- 训练速度太慢,而且以为模型复杂容易过拟合
- 随机梯度下降不能保证每次都能收敛到同一结果
-
相关阅读:
Matlab高效编程:向量化(vectorization)、矩阵化、变量预定义
#循循渐进学51单片机#点亮你的LED#not.2
葡聚糖修饰的Hrps共价三聚肽(三种Hrps多肽和葡聚糖通过共价修饰形成共价三聚肽,其结构通式为:(3Hrps)(CHO))
js-判断android,ios,pc三端环境
使用dd命令来构造测试文件
3-网络架构和Netty系列-Java NIO三件套Buffer、Selector、Channel
什么是绩效管理?
线性代数的本质(三)
vue2+vite+vue-cli5 实现vite开发webpack打包
Python海龟turtle基础知识大全与画图集合
- 原文地址:https://blog.csdn.net/qq_42902997/article/details/124945172