-
导师详解:多比特信号的CDC处理方式之异步FIFO
导师详解:多比特信号的CDC处理方式之异步FIFO

\\\插播一条:
自己在今年整理一套单片机单片机相关论文800余篇
论文制作思维导图
原理图+源代码+开题报告+正文+外文资料
想要的同学私信找我。
异步FIFO是处理多比特信号跨时钟域的最常用方法,简单来说,异步FIFO是双口RAM的一个封装而已,其存储容器本质上还是一个RAM,只不过对其添加了某些控制,使其能够实现先进先出的功能,由于这个功能十分的实用,因此得以广泛应用。真双口RAM可以实现在一端存储,另一端读取的功能,两端的时钟可以不同,将数据存入一个容器,再取出来,这个过程在双口RAM的两端完全不存在亚稳态的问题。由于异步FIFO的实现中也存在数据的存取问题,和双口RAM类似,再加上空满信号的控制,存在跨时钟域的问题,因此只要处理好,空满信号的判断中的跨时钟域问题,就可以使用FIFO解决多比特信号的跨时钟域问题。下面从多个方面来了解一下,异步FIFO的内容,最后会给出异步FIFO的一种普遍的实现方式及其仿真,让我们一起进入今天的内容吧。
异步FIFO的概念
异步FIFO的实现方式有很多种,这里说的实现方式可以理解为实现异步FIFO的技术方式,也可以指使用异步FIFO的选择方式,因为都有很多种!拿实现异步FIFO的技术方式来说,其重难点在于其空满信号的判断,它涉及到内部跨时钟域细节的实现、格雷码的转换以及空满信号的比较等。这里面的实现技术就各有不同了,但殊途同归,只能能巧妙地判断空满就可以凑合着用。下面给出一张异步FIFO的实现架构框图仅供参考:
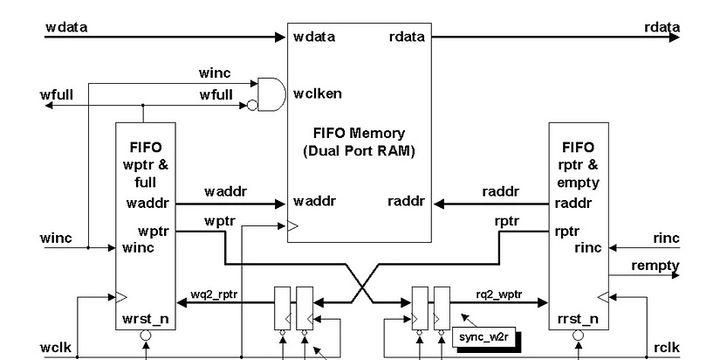
另外,因为异步FIFO的应用已经太成熟了,手动设计起来破费一番功夫,所以FPGA各大厂家大都提供了专业的IP核供使用,功能齐全且性能良好,鲁棒性强,不用自己设计,在工程应用中,也基本都用IP核,除非想不开或者其他原因?
不妨打开Xilinx的FIFO定制页面:FIFO Generator来看:
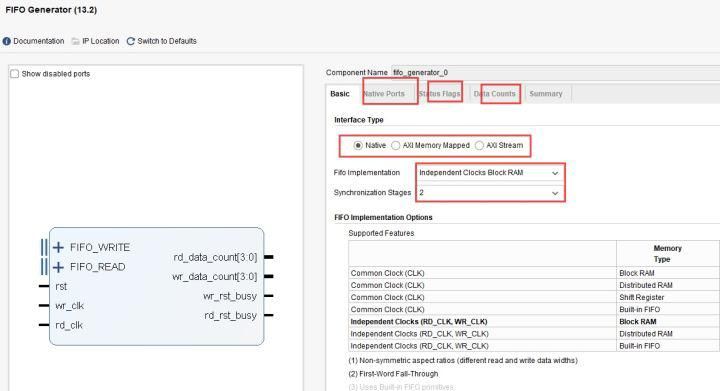
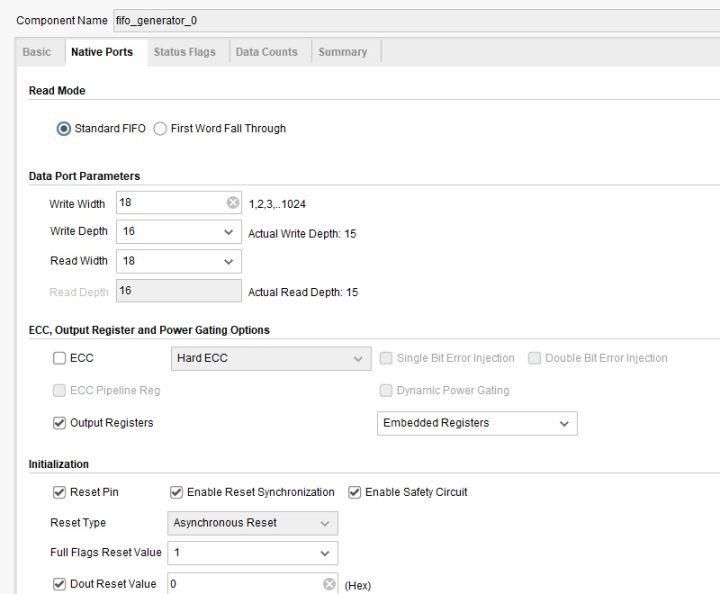
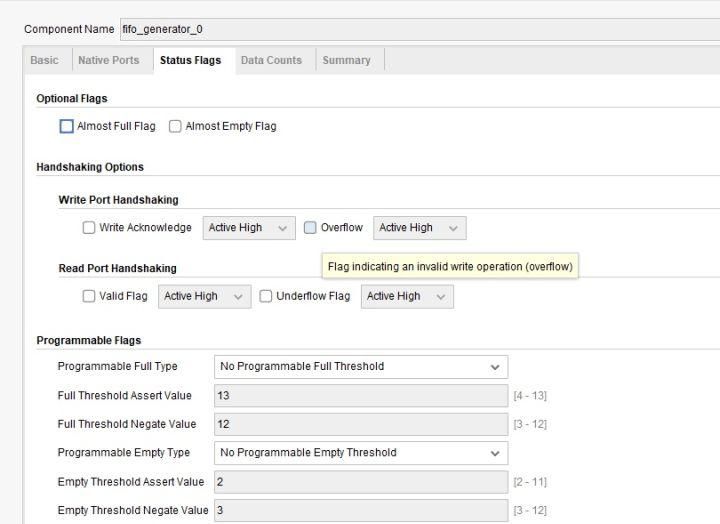
可供定制的页面确实及其丰富,各种类型的空满信号、实现的资源选择应有尽有,手动实现这些可是要费大功夫的,没有资本的推动,恐怕很难有人去做这件事吧。
异步FIFO为什么可以解决CDC问题?
异步FIFO的接口如下:

再看其资源使用情况:
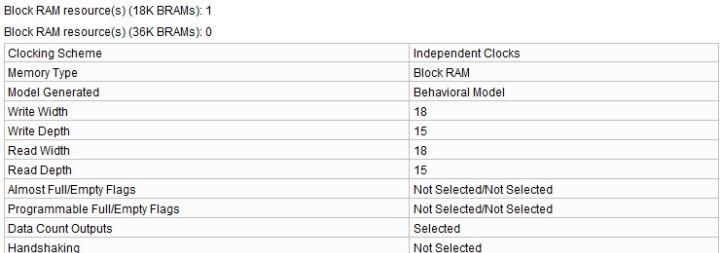
以上这两张图片显示的是Xilinx的异步FIFO IP的一种定制情况,可以看到FIFO就是在RAM的基础上的一个产物,通过处理RAM的读写端口来做成先进先出的存储器,实现FIFO的功能。
对于FIFO的读写有独立的时钟,说明读写可以是不同的时钟,因此可以实现不同时钟域数据的传输。
这好像只是说明了一个结论,异步FIFO可以作为处理跨时钟域处理的方法或载体,但是异步FIFO为什么可以用来处理跨时钟域传输问题呢?这和异步FIFO的具体实现有关!下面一起来看异步FIFO的实现!
异步FIFO的RTL实现
通过RTL实现异步FIFO之前,需要明白异步FIFO的几个重要的参数,也是我们设计的重点:
·FIFO的深度:通俗地说,就是异步FIFO可以存多少个数据的意思!
·FIFO的宽度:上面说异步FIFO的深度是表示能存放多少数据的概念,那宽度便是每个数据有多少位,也就是我们通常所说的数据有多宽!
·FIFO空:表示FIFO里面数据被读完了;
·FIFO满:表示FIFO里面填满了数据;
·FIFO写指针:总是指向下一个将要被写入的单元,复位时,指向第1个单元(编号为0);
·FIFO读指针:总是指向当前要被读出的数据,复位时,指向第1个单元(编号为0);
·FIFO读时钟:表示读取数据使用的时钟,一般设计时钟的上升沿为有效沿,有效沿读取数据;
·FIFO写时钟:表示写入数据时使用的时钟,一般上升沿为有效沿,当然也可以设计下降沿为有效沿。
明白了如上的FIFO参数的概念,我们也该具体聊聊FIFO的关键细节了,例如最重要的空满判断条件:上面也说了,FIFO空的意思是FIFO中没有了数据,可以思考,什么情况下FIFO中数据空了,其实FIFO类似一个容器,就水桶吧,倒进去的水,又全部倒了出来,水桶就是空的。FIFO也是如此,写进去的数据,又全部读了出来,表示FIFO空了。如下图:
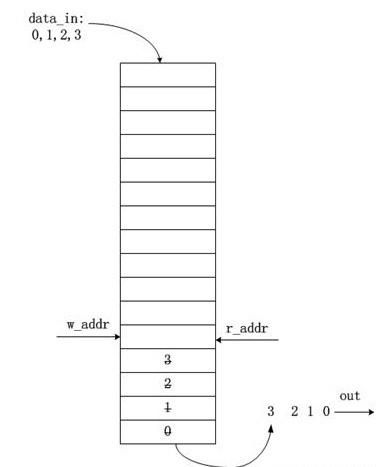
写进FIFO4个数据,又读出了4个数据,读写指针指向了同一个地方,也就是读写指针相等了,FIFO就空了。这是最简单的情况,我们其往下看:还是用上面的图片,如果继续往FIFO内写数据,写指针不断增加,写到尽头了,指针就会从0继续增加,直到写指针回到了最初的位置,再次与读指针处于同一个位置,这时候读写指针再次相等,但是你能说FIFO还是空的吗?如下图:
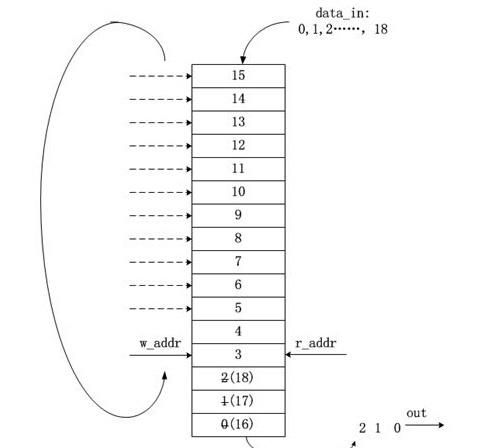
恰恰相反,此时FIFO是满的!这就带来了我们今天异步FIFO设计的第一个问题,就是读写指针与空满条件的判断之间的关系问题?
也不是没有解决办法,最直观的便是多增加一位表示读写指针,例如FIFO的深度为8,我们原来用3位表示读写指针即可,但是我们增加到4位,这样只要读写指针的最高位不相等,即便二者剩下的其他位相等也不能表示指针相等,也就是不能说FIFO为空,相反FIFO为满。
有人可能会有这样的疑问?还是上面的一幅图,如果FIFO满了之后,继续写数据,再来一圈,FIFO的读写指针不就又完全相等了吗?其实,这很好办,我们在设计FIFO的时候,判断FIFO为空的话就规定不能再读了,如果FIFO为满的话,就不能再继续写了,这就解决了这个疑问!
接着还需要讨论一个问题,如FIFO实现的框图:
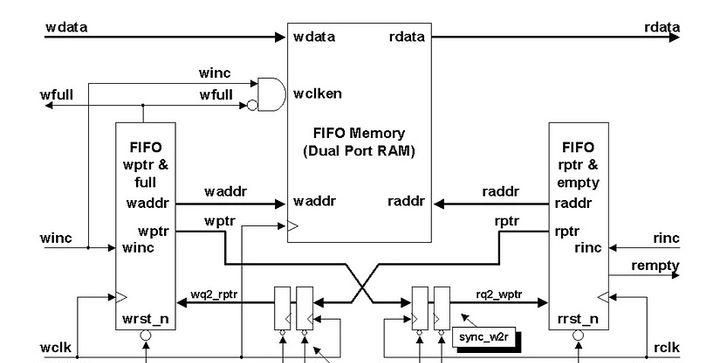
如上图,判断FIFO的空满,需要读写指针跨时钟域传输,之后对比读写指针的大小,这就存在一个问题,那就是我们所说的跨时钟域问题,在这里具体来说便是读写指针的跨时钟域问题?怎么处理呢?由于读写指针有多位,对于多比特数据的CDC问题,我们一般不会直接两级同步过去,两级同步适用于单比特变化的数据!但是如上图的实现方式,好像还就是两级同步,这是什么原因呢?
如果非要使用两级寄存器同步的方式,我们就要控制每次只有1比特数据发生变化,如何实现呢?很容易,使用格雷码对读写指针计数值进行编码即可。
如下图:
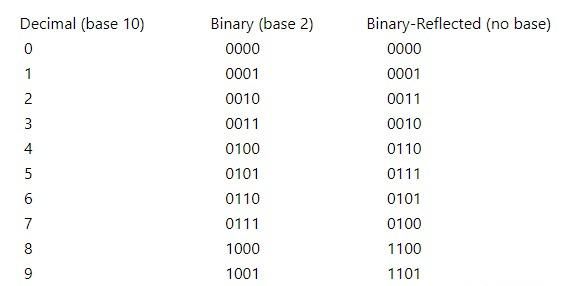
可见,格雷码的每一次叠加只会发生1比特数据的变化。在异步FIFO的实现中,读写指针的变化,我们仍然使用二进制加,之后将变化后的二进制通过组合逻辑转换为格雷码即可。二进制转换为格雷码以及格雷码转换为二进制的方法,我们可以参考我以前的博文:二进制与格雷码之间的转换的Verilog实现(更多一点的讨论),这篇文章还顺便提到了generate for以及for语句的区别,推荐阅读。
这里为了后面的RTL编码铺垫,给出二进制编码与格雷码之间的转换示意图,避免翻阅的麻烦:
·二进制转换为格雷码的方法:
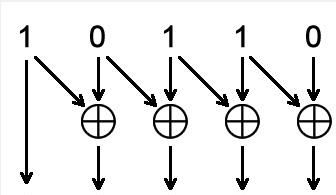
伪代码描述为:
assign gray_value = binary_value ^ (binary_value>>1);
·格雷码转换为二进制码的方法:
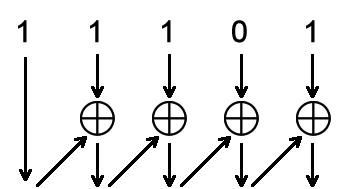
如上图,可以看出,可以从高位入手,格雷码的最高位即是二进制码的最高位,之后的二进制码的实现便是它本身的高1位与该位的格雷码进行异或,如下伪代码描述:
assign bin[N-1] = gray[N-1];
genvar i;
generate
for(i = N-2; i >= 0; i = i - 1) begin: gray_2_bin
assign bin[i] = bin[i + 1] ^ gray[i];
end
endgenerate
OK,解决了二进制码向格雷码的转换问题,我们继续分析:二进制码转换成了格雷码并跨时钟域到了另一个时钟域,那接下来就是读写指针的格雷码形式的对比了,二进制的对比很简单,就是如果二者所有的位全部相等,则表示空;如果二者最高位不同,但其他位相同,则表示满。上述判断方法为二进制判断空满的方法,那么格雷码呢?我们分情况讨论:
·对于空的判断:这就很简单,二进制完全相同,难道格雷码不完全相等吗?对的,同样完全相同表示空。
·对于满的判断:从上面的格雷码与二进制码之间的转换可以确定一点,就是二者的最高位一致,因此当二进制码的最高位不等的时候,格雷码也一定不等,这一点毋庸置疑;同样由二者转换的原理图看出,由于二进制码时,二者的最高位不同,其余为相同,如下图:
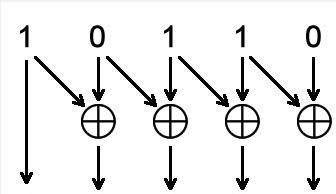
二进制转换为格雷码的时候,次高位的格雷码和最高位相关,因此,二者的次高位一定不同,由于二进制码的次高位相同,因此次次高位相同,以此类推,剩余的更低位在二进制编码以及格雷码中完全相同。这就得出了结论,在格雷码编码中确定满的条件是最高位,次高位都不同,但是其余位相同。
如下图:
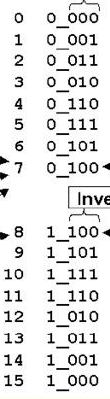
0和8,1和9等,由于其二进制码的最高位不同,其余位相同,但是格雷码确是最高位和次高位都不同,其余位相同。这个问题到此就当做解决了。
难题都已经解决,下面就是异步FIFO的RTL实现工作了。
如果你读懂了上述的分析过程,那么本设计就十分清晰明了了,下面给出RTL设计:
module asyn_fifo#(
parameter DATA_WIDTH = 8,
parameter DATA_DEPTH = 32
)(
//write ports
input wr_clk,
input wr_rst,
input wr_en,
input [DATA_WIDTH - 1 : 0] wr_data,
output reg full,
//read ports
input rd_clk,
input rd_rst,
input rd_en,
output reg [DATA_WIDTH - 1 : 0] rd_data,
output reg empty
);
// define FIFO buffer
reg [DATA_WIDTH - 1 : 0] fifo_buffer[0 : DATA_DEPTH - 1];
//define the write and read pointer and
//pay attention to the size of pointer which should be greater one to normal
reg [$clog2(DATA_DEPTH) : 0] wr_pointer = 0, rd_pointer = 0;
//write data to fifo buffer and wr_pointer control
always@(posedge wr_clk) begin
if(wr_rst) begin
wr_pointer
end
else if(wr_en) begin
wr_pointer
fifo_buffer[wr_pointer]
end
end
//read data from fifo buffer and rd_pointer control
always@(posedge rd_clk) begin
if(rd_rst) begin
rd_pointer
end
else if(rd_en) begin
rd_pointer
rd_data
end
end
//wr_pointer and rd_pointer translate into gray code
wire [$clog2(DATA_DEPTH) : 0] wr_ptr_g, rd_ptr_g;
assign wr_ptr_g = wr_pointer ^ (wr_pointer >>> 1);
assign rd_ptr_g = rd_pointer ^ (rd_pointer >>> 1);
//wr_pointer after gray coding synchronize into read clock region
reg [$clog2(DATA_DEPTH) : 0] wr_ptr_gr, wr_ptr_grr, rd_ptr_gr, rd_ptr_grr;
always@(rd_clk) begin
if(rd_rst) begin
wr_ptr_gr
wr_ptr_grr
end
else begin
wr_ptr_gr
wr_ptr_grr
end
end
//rd_pointer after gray coding synchronize into write clock region
always@(wr_clk) begin
if(wr_rst) begin
rd_ptr_gr
rd_ptr_grr
end
else begin
rd_ptr_gr
rd_ptr_grr
end
end
// judge full or empty
always@(posedge rd_clk) begin
if(rd_rst) empty
else if(wr_ptr_grr == rd_ptr_g) begin
empty
end
else empty
end
always@(posedge wr_clk) begin
if(wr_rst) full
else if( (rd_ptr_grr[$clog2(DATA_DEPTH) - 2 : 0] == wr_ptr_g[$clog2(DATA_DEPTH) - 2 : 0])
&& ( rd_ptr_grr[$clog2(DATA_DEPTH)] != wr_ptr_g[$clog2(DATA_DEPTH)] ) && ( rd_ptr_grr[$clog2(DATA_DEPTH) - 1] != wr_ptr_g[$clog2(DATA_DEPTH) - 1] ) ) begin
full
end
else full
end
//对写满的限制
always@(posedge wr_clk or posedge wr_rst) begin
if(wr_rst) begin
wr_pointer
end
else if(wr_en) begin
if(!((rd_ptr_grr[$clog2(DATA_DEPTH) - 2 : 0] == wr_ptr_g[$clog2(DATA_DEPTH) - 2 : 0])
&& ( rd_ptr_grr[$clog2(DATA_DEPTH)] != wr_ptr_g[$clog2(DATA_DEPTH)] ) && ( rd_ptr_grr[$clog2(DATA_DEPTH) - 1] != wr_ptr_g[$clog2(DATA_DEPTH) - 1] ))) begin
wr_pointer
end
else begin
wr_pointer
end
end
else begin
wr_pointer
end
end
//对读空的限制
always@(posedge rd_clk or posedge rd_rst) begin
if(rd_rst) begin
rd_pointer
end
else if(rd_en) begin
if(wr_ptr_grr != rd_ptr_g) begin
rd_pointer
end
else begin
rd_pointer
end
end
else begin
rd_pointer
end
end
endmodule
这个程序唯一需要注意的是,最后对空满以后,读写指针的处理,例如:
//对读空的限制
always@(posedge rd_clk or posedge rd_rst) begin
if(rd_rst) begin
rd_pointer
end
else if(rd_en) begin
if(wr_ptr_grr != rd_ptr_g) begin
rd_pointer
end
else begin
rd_pointer
end
end
else begin
rd_pointer
end
end
读空了以后,读指针就不会再增加了。
//对写满的限制
always@(posedge wr_clk or posedge wr_rst) begin
if(wr_rst) begin
wr_pointer
end
else if(wr_en) begin
if(!((rd_ptr_grr[$clog2(DATA_DEPTH) - 2 : 0] == wr_ptr_g[$clog2(DATA_DEPTH) - 2 : 0])
&& ( rd_ptr_grr[$clog2(DATA_DEPTH)] != wr_ptr_g[$clog2(DATA_DEPTH)] ) && ( rd_ptr_grr[$clog2(DATA_DEPTH) - 1] != wr_ptr_g[$clog2(DATA_DEPTH) - 1] ))) begin
wr_pointer
end
else begin
wr_pointer
end
end
else begin
wr_pointer
end
end
-
相关阅读:
MySQL安全性策略:用户认证与数据加密
【Rust】使用HashMap解决官方文档中的闭包限制
【OpenCV图像处理15】人脸识别项目
【Spring Cloud】深入探索 Nacos 注册中心的原理,服务的注册与发现,服务分层模型,负载均衡策略,微服务的权重设置,环境隔离
【WiFI问题自助】解决WiFi能连上但是没有网的问题
AB包中的Lua文件应该怎么require
容器云资源数据关联与数据联动的难点和解决思路
通过逻辑回归和随机梯度下降法对乳腺癌数据集breastCancer和鸢尾花数据集iris进行线性分类
查询 (Tcode)跳转ID方法:(SET PARAMETER ID)
Spring BeanFactory支持的Bean生命周期接口和整套初始化方法顺序
- 原文地址:https://blog.csdn.net/danpianji777/article/details/124970552