-
【数仓】大数据开发全流程 - 实习总结
工作了快一个月了,今天简单说一下大数据开发的整个流程。假设就以自己这个公众号为例,这样不会抽象,比较直观。
1.数据源
前端会对用户行为进行埋点,并上报后端服务器。埋点会记录一些信息,比如:
- 用户 id:标记一个用户,后面可以根据这个算一段时间的 UV(独立访客),也就是
selecct count(distinct uid) from table_name where date >= t1 and date <= t2,比如我的公众号阅读人数就是 UV,次数是 PV。
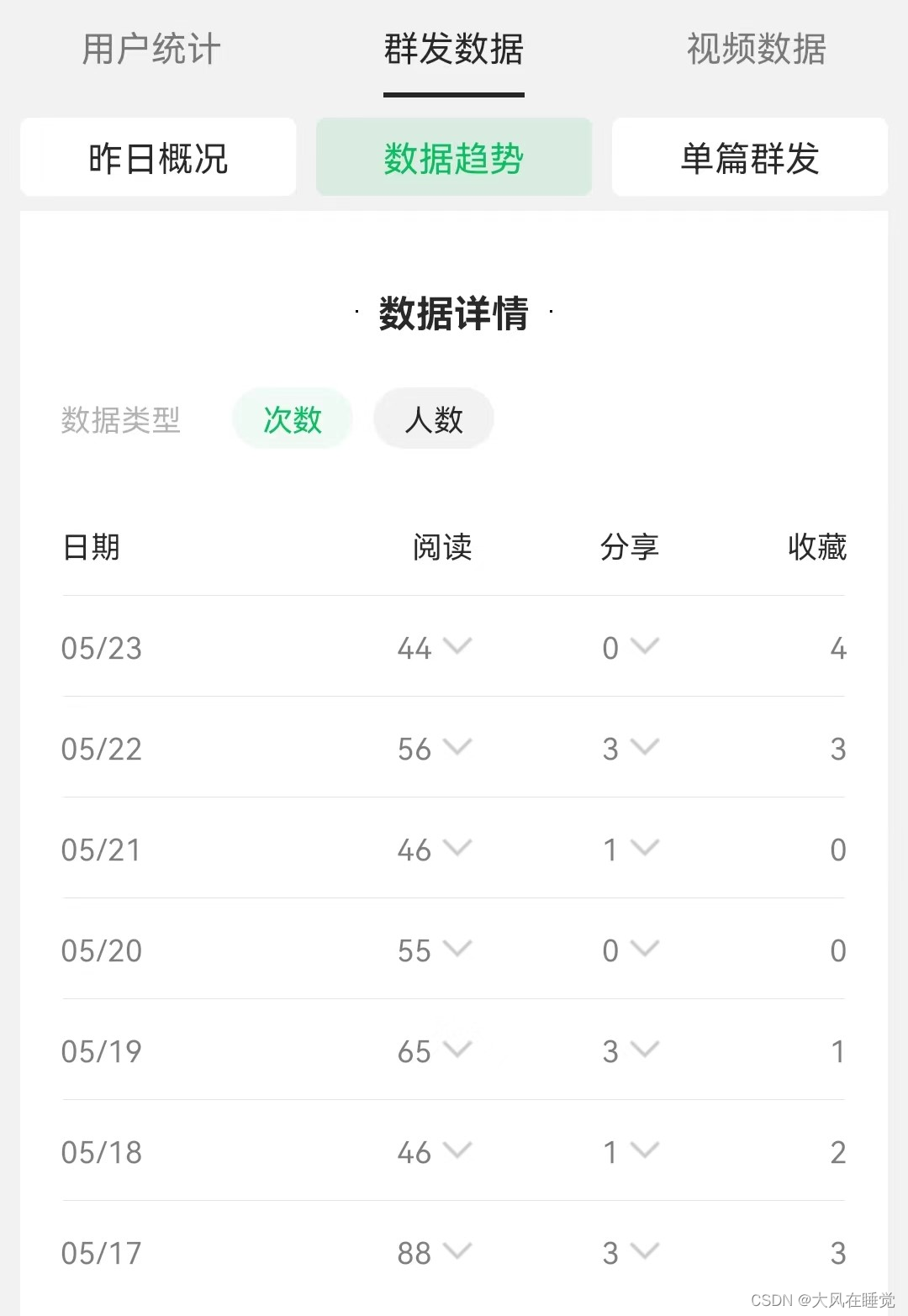
- 渠道来源、用户入口等信息:记录来源可以分析各个渠道的用户数或阅读数,可能广告比较关注,比如别人付费了,想要知道我付费之后从这个付费渠道来源有多少人,比如我在墨迹天气投了广告,用户点击跳转到淘宝的宝贝,这个来源也是会记录的。或者我写公众号,在别的地方贴了二维码,多少人是扫码关注的?又有多少人是通过别人分享关注的?
上面只是简单举例,前端埋点的字段还有很多。
这里可以看大数据之路对应的章节。
2.ods 层
刚刚提到的埋点日志数据,以及数据库中的业务数据到 Hive 中成为 ods 层。即:
- MySQL → ods
- 日志 → ods
用到的同步技术很多,这里可以看大数据之路对应的章节。
3.公共层
公共层一般是可以复用的指标,构建 dwd 和 dws 层。存一些各种用户都需要用到的明细指标和聚合指标。
用到的技术主要是 Hive 和 Spark SQL。可以看大数据之路对应的章节。
4.应用层
应用层主要是 dm、app 层,这里的表格主要存不同用户关心的数据不同,是一些不太通用的个性化指标。数据的用户可能是公司的分析师,分析公司的经营状况。也可能是客户,比如我上面截图的微信公众号后台,就是给用户看的。
5.OLAP
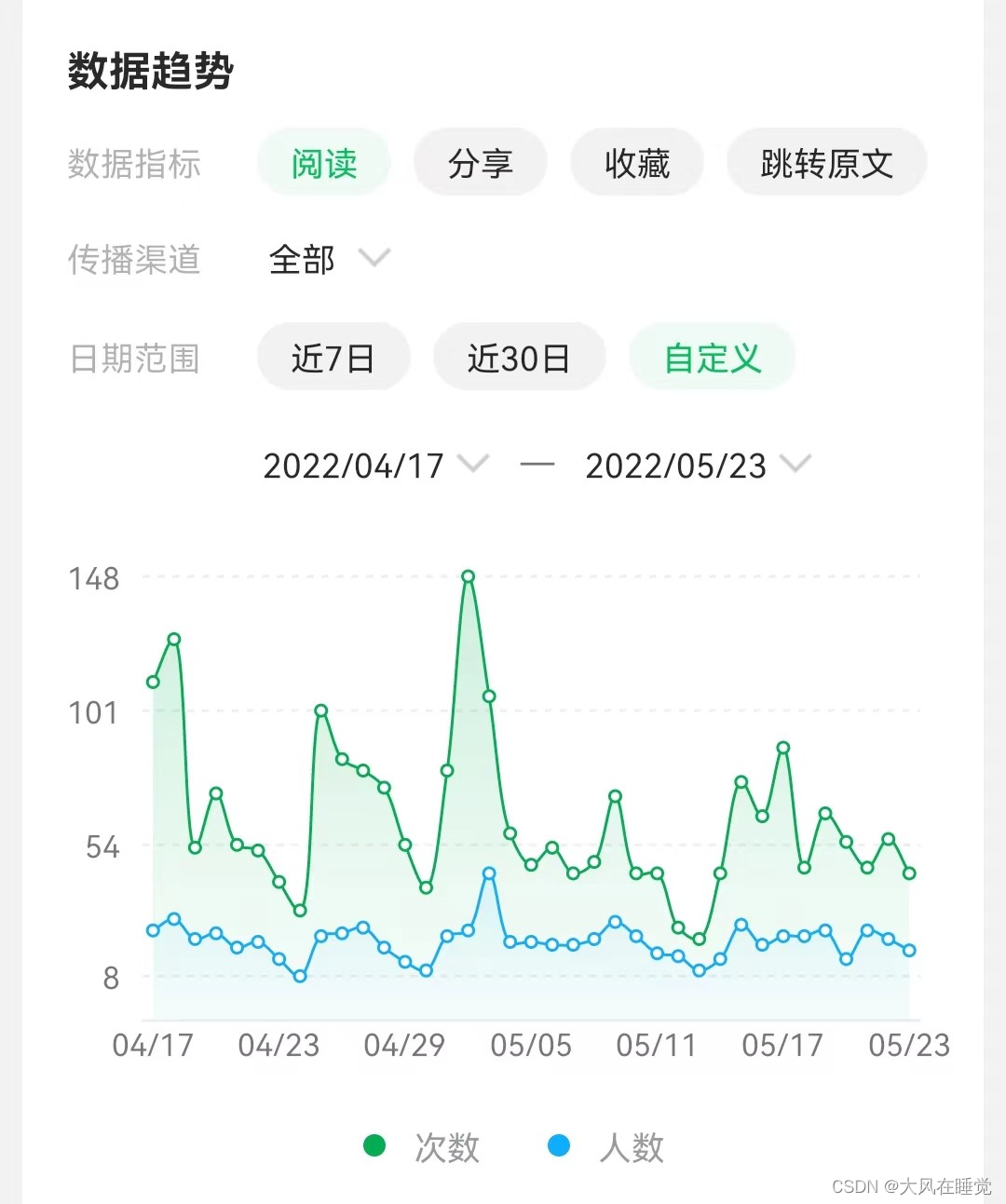
刚刚说了应用层的数据主要是客户关心的数据,聚合了一些最近 7 天、最近 30 天的数据。但是 Hive 表查询很慢,用户从前端页面请求取数,请求发到后端,后端是不会直接到 Hive 表中查询的,这样太慢了。说以 Hive 产出的 app 层数据会推送到 Elasticsearch 中,后端去查 ES,直接从 ES 中拿到数据计算的结果,这样速度会很快。这里可以看 ES 的文章。
还有一种情况,用户选择的不是直接计算好的结果,比如最近 7 天或最近 30 天,而是自定义时间区间,如下图所示。显然,每一个时间组合计算出一张表数据量太大,是不可承受的。这样就要用到即席查询。用户选择了时间再去计算,所以点击下面的自定义会比较卡,过了几秒钟才出现结果。这里就需要即席查询,可能是 ClickHouse 等工具。
当然不止 Elasticsearch 和 ClickHouse,还有其他如 Kylin、presto、Impala 等工具。后面将进行学习。
以上就是大数据开发的全流程。再次推荐大家阅读阿里的《大数据之路》。关注下方公众号回复 802 获取 pdf。
《大数据之路》 - 用户 id:标记一个用户,后面可以根据这个算一段时间的 UV(独立访客),也就是
-
相关阅读:
Java模拟电影院购票系统
C++中栈与堆数据存取情况
安卓截屏;前台服务
小明回家 题解 BFS
图解快速排序算法
python日期工具datedays
【23-24 秋学期】NNDL 作业8 卷积 导数 反向传播
整形和浮点型是如何在内存中的存储
通过JS生成蜂巢背景图(六边形背景图)
springboot之二:整合junit进行单元测试+整合redis(本机、远程)+整合mybatis
- 原文地址:https://blog.csdn.net/weixin_45545090/article/details/124954787