-
车牌识别平台开源(支持蓝牌、绿牌,准确率高达96%)
效果:
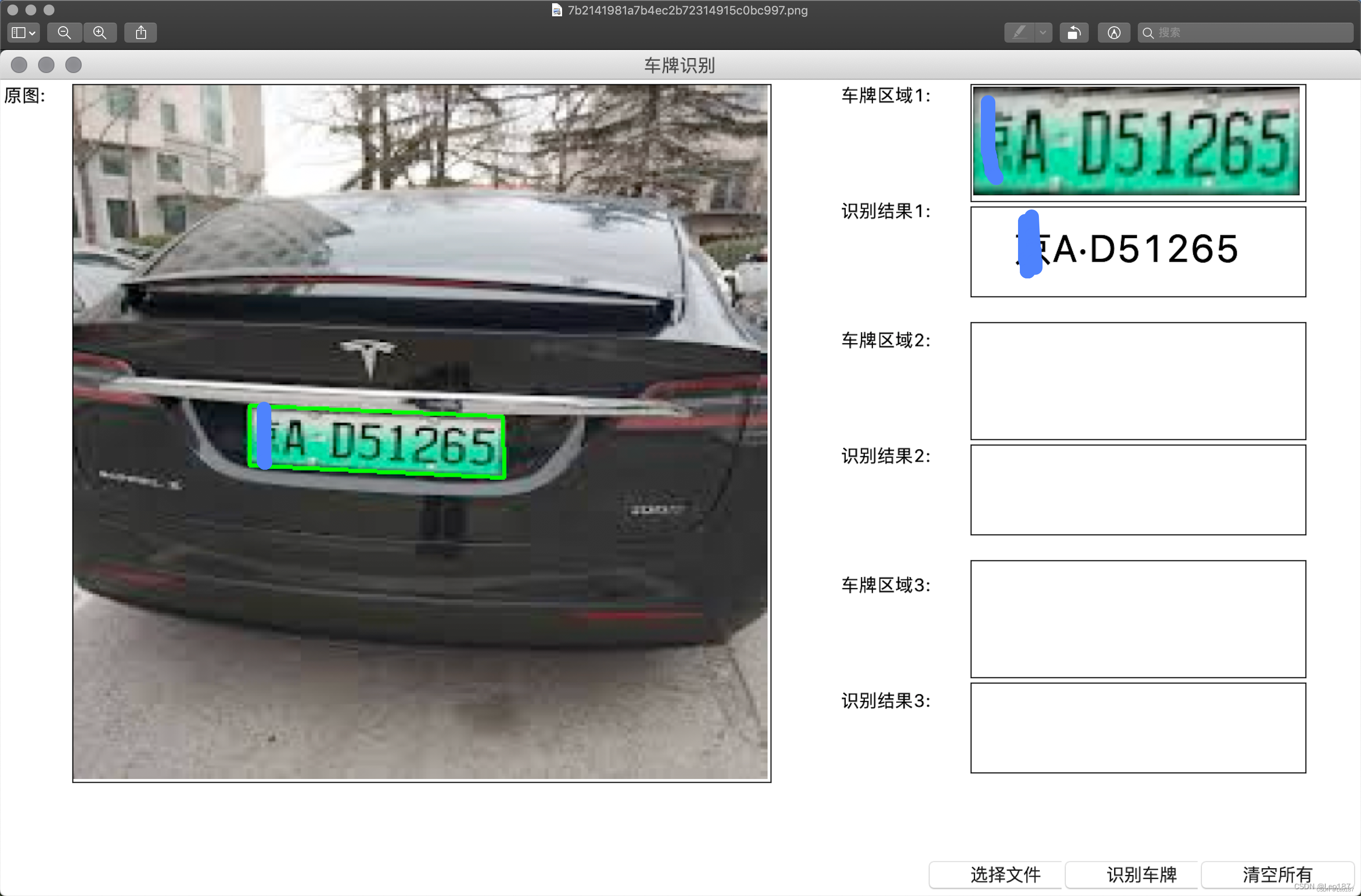

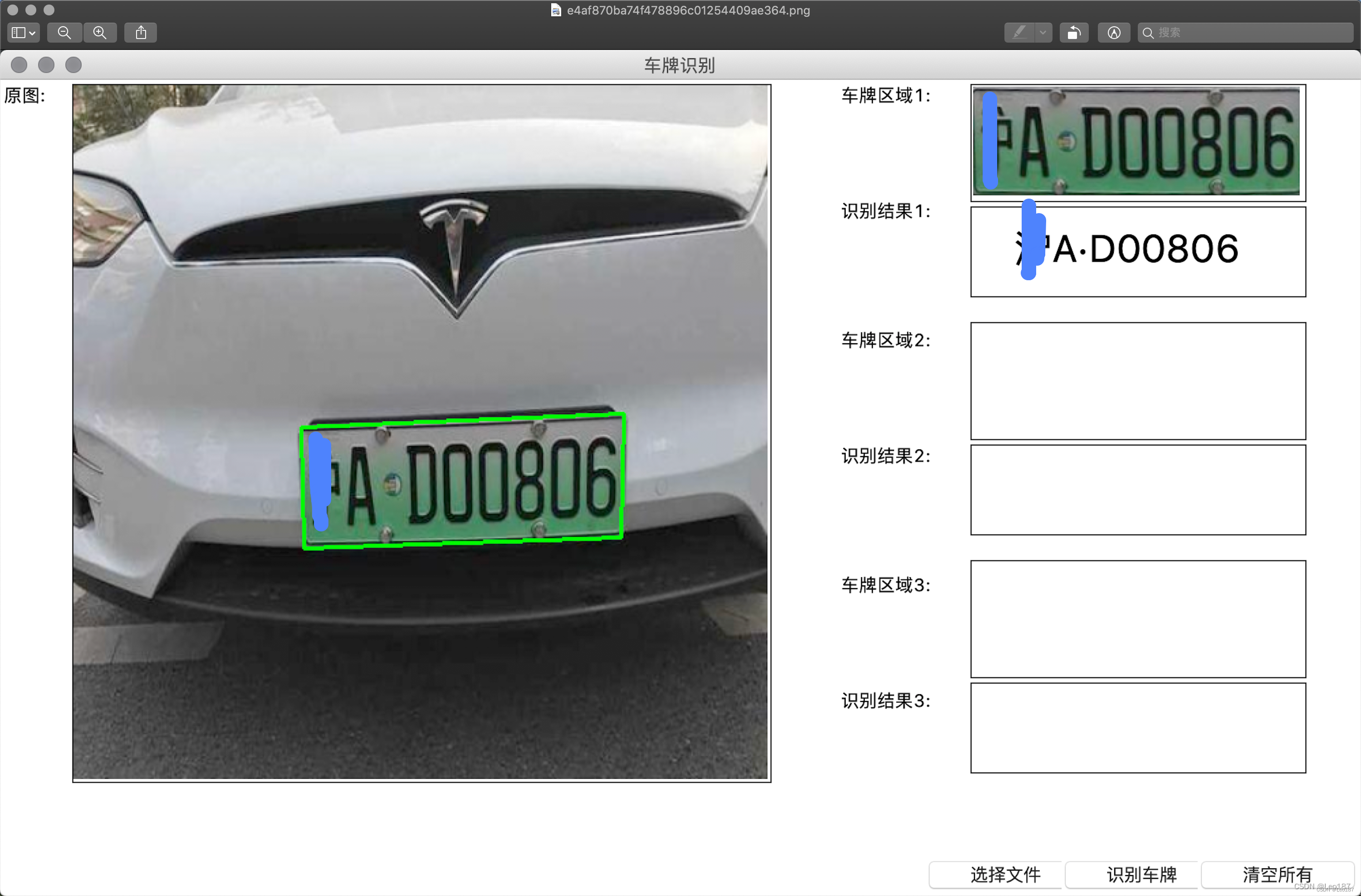
此项目在基于u-net,cv2以及cnn的中文车牌定位,矫正和端到端识别软件_不啻逍遥然的博客-CSDN博客的基础上增强了绿牌识别,绿牌训练数据近10万。结合博主开源的蓝牌模型,目前完美匹配蓝、绿牌识别场景。识别准确率达96%以上。
用了什么技术,原理是什么?
技术架构
- Python:轻量框架,搭建简单,更专注于业务功能
- opencv:跨平台计算机视觉库,用作图像处理
- Tensorflow: 机器学习的框架,用作大量数据需要处理,或是深度学习
- cnn: 卷积神经网络(Convolutional Neural Network,简称CNN),是一种前馈神经网络,人工神经元可以响应周围单元,可以进行大型图像处理。卷积神经网络包括卷积层和池化层
- unet: 对图像中的每个像素点分类,即像素级别的分类任务
识别出一个车牌,计算机做了哪些工作?
机器识图的过程:机器识别图像并不是一下子将一个复杂的图片完整识别出来,而是将一个完整的图片分割成许多个小部分,把每个小部分里具有的特征提取出来(也就是识别每个小部分),再将这些小部分具有的特征汇总到一起,就可以完成机器识别图像的过程了
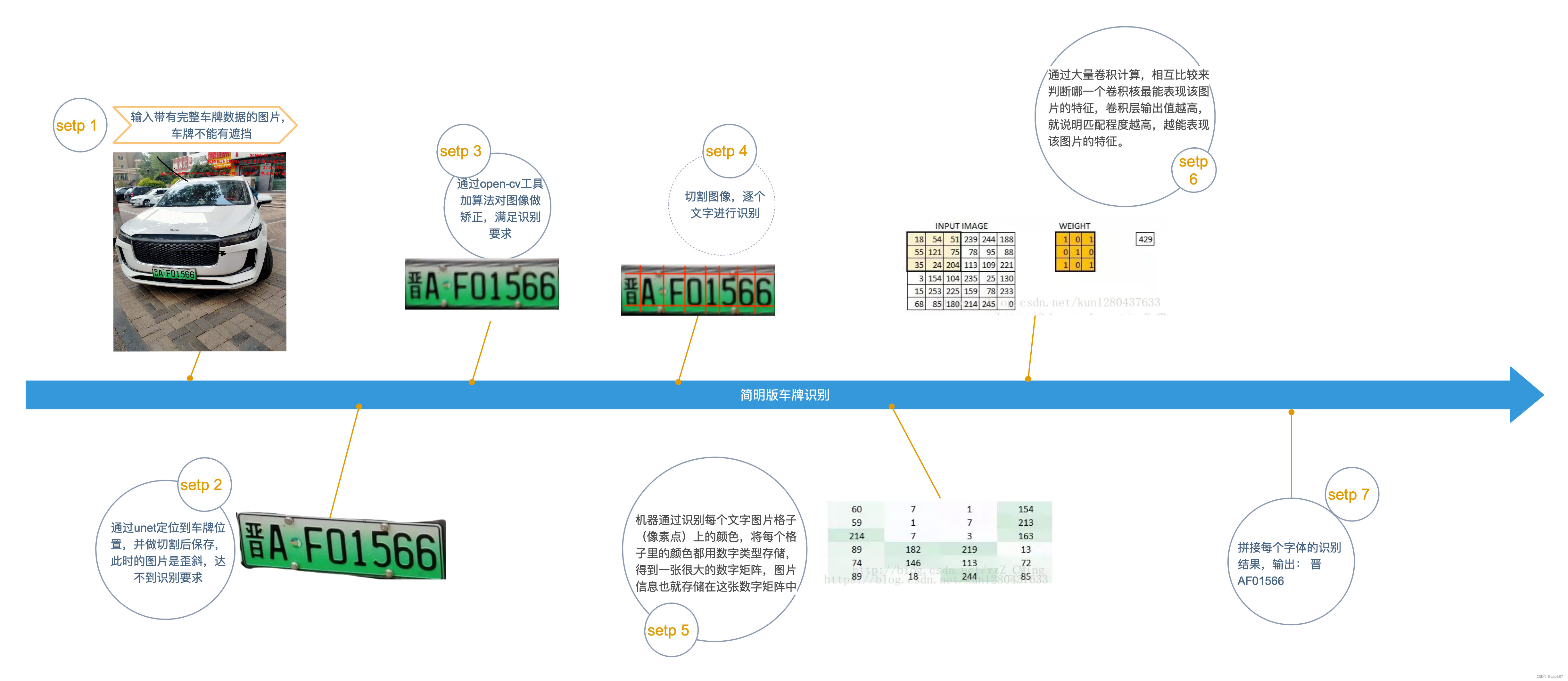
怎么做一个车牌识别应用?
- 拟定题目
- 寻找并可视化数据,发现规律,开发程序
- 为机器学习算法准备数据
- 选择模型,进行训练
- 测试模型,发现问题并微调模型
- docker部署、持续更新训练
简单分为两个阶段,第一阶段是训练模型,第二阶段是使用模型做识别。难点主要在模型的训练,训练又分为unet和cnn两个模块,最终会得到两个相应的模型,一个用作定位,一个用作识别。车牌识别属于Supervised Learning(监督学习),下面会讲到机器学习的分类。
unet训练
我们可以通过图像分割算法对一张输入图片进行分割,分割后的图形其实是对原图中的区域进行的分类标注,例如这里我们可以将原图标注为2类,一类就是车牌区域,还有一类就是无关的背景区域使用,用于训练unet模型。u-net部分的数据集我一共标注了1500多张,最终效果很棒,达到了定位的效果。
cnn训练
cnn训练我准备了10万张左右的有效牌照数据。每张图片都是统一的宽240,高80的车牌图片,要实现车牌的端到端识别,显然是多标签分类问题,每张输入图片有8个标签(8个字符),模型输出前的结构都是可以共享的,只需将输出修改为8个即可,8个输出对应了8个loss,总loss就是8个loss的和,使用keras可以很方便地实现。
最终,训练集上准确率acc1(即车牌省份字符)为95%,其余字符均为99%左右,本地测试集准确率为95%,识别效果较佳。

训练、优化不再赘述了,重点说下使用方式:
1.修改配置

2.启动应用

训练不易,如有帮助请帮忙点赞,多谢!
-
相关阅读:
Hystrix源码分析-依赖关系
UI自动化---Wechat批量表情包轰炸
c++ 模板template
淘宝分布式文件存储系统(一) -TFS
Web-其他功能
AD18原理图转Candence SPB17.4
win10 sourcetree打开一闪就退出
npm install一直卡着不动
react 笔记
工业视觉——打光
- 原文地址:https://blog.csdn.net/leo187/article/details/124936827