-
通用场景图像分割
通用场景图像分割
图像分割
所谓图像分割指的是根据灰度、颜色、纹理和形状等特征把图像划分成若干互不交迭的区域,并使这些特征在同一区域内呈现出相似性,“而在不同区域间呈现出明显的差异性。1 Pascal VOC数据集
视觉识别类竞赛的鼻祖,是包含了物体分类、目标检测、图像分割等任务。后续的ImageNet 竞赛的任务设置就基本沿用了它的设定。给定自然图片, 从中识别出特定物体,待识别的物体有20类∶
person,bird, cat, cow, dog, horse, sheep,aeroplane, bicycle, boat, bus, car, motorbike, train,bottle, chair, dining table, potted plant, sofa, tv/monitor2 语义分割
2.1 什么是语义分割
目标:从像素水平上,理解、识别图片的内容;根据语义信息分割。
输入:图片
输出:同尺寸的分割标记(像素水平);每个像素会被识别为一个类别。

2.2 语义分割的用处
机器人视觉和场景理解;
辅助、自动驾驶;
医学X光

2.3 算法研究阶段
2015之前∶手工特征+图模型(CRF)
2015开始∶深度神经网模型
思路∶改进CNN,并使用预训练CNN层的参数
传统CNN的问题:后半段网络无空间信息;输入图片尺寸固定
全卷积网络(Fully Convolutional Networks):所有层都是卷积层;解决降采样后的低分辨率问题2.4 全卷积网络
全卷积化:将所有全连接层转换成卷积层;适应任意尺寸输入,输出低分辨率分割图片
反卷积:将低分辨率图片进行上采样,输出同分辨率分割图片
跳层结构:精化分割图片
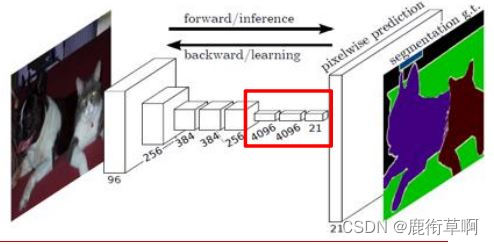
3 FCN-卷积化
基础CNN网络:AlexNet,VGG16,GooLeNet
卷积化后的核尺寸(通道数,宽,高):
FC6—>(1x1,4096)
FC7—>(1x1,4096)
FC8—>(1x1,类别N)
分辨率降低32倍:5个卷积层;每层降2倍3.1 FCN-卷积化的降维问题
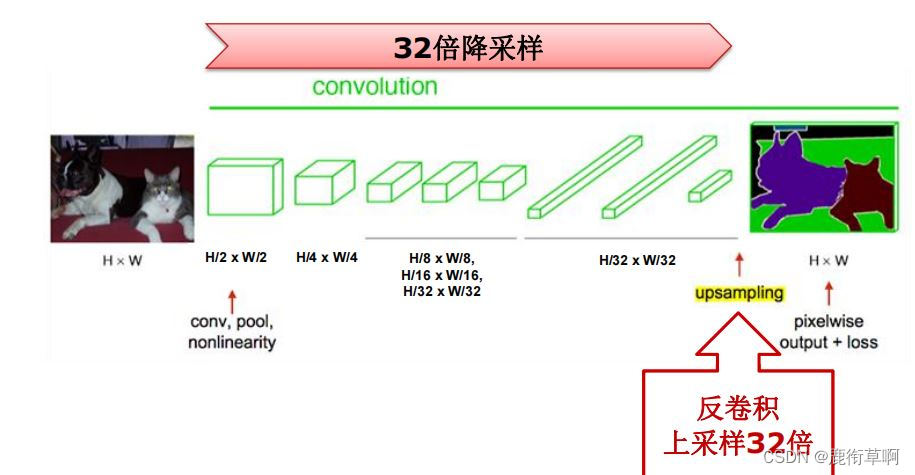
3.2 FCN-反卷积
卷积的逆操作:小数步长1/f;卷积核尺寸不变。
前向和后向传播:对应于卷积操作的后向和前向传播,优化上做颠倒;反卷积核是卷积核的转置,学习率为0。
也叫转置卷积。
可以拟合出双线性插值
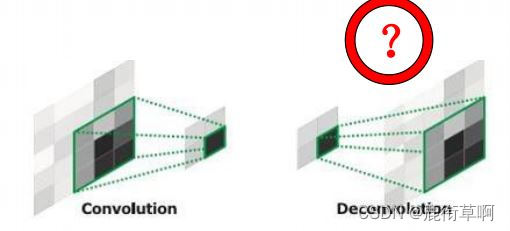
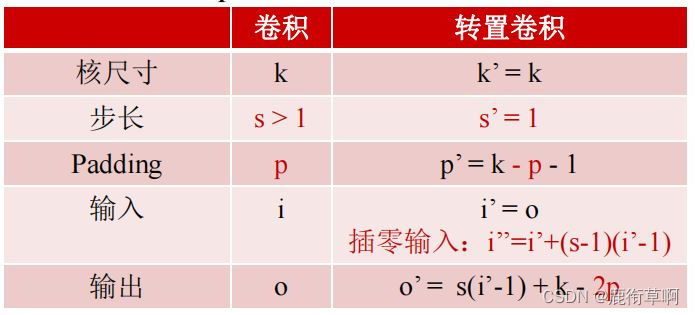
3.3 FCN-卷积/转置卷积的参数关系
步长:1;padding;0
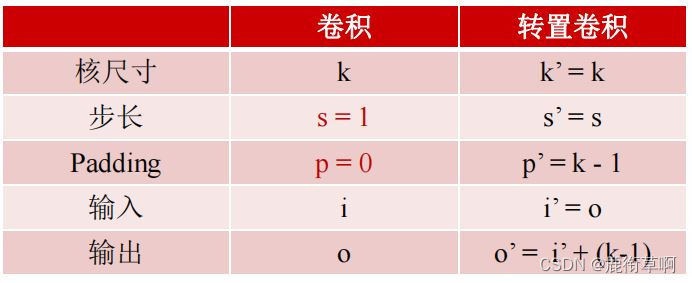
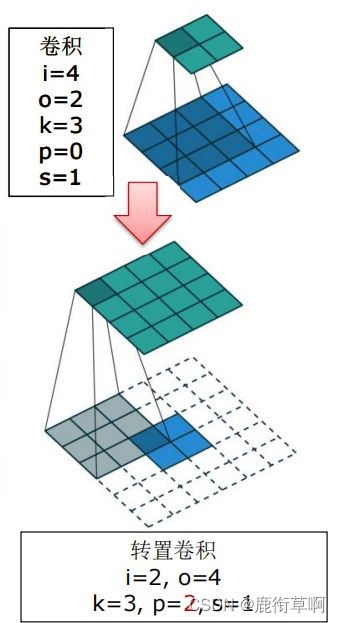
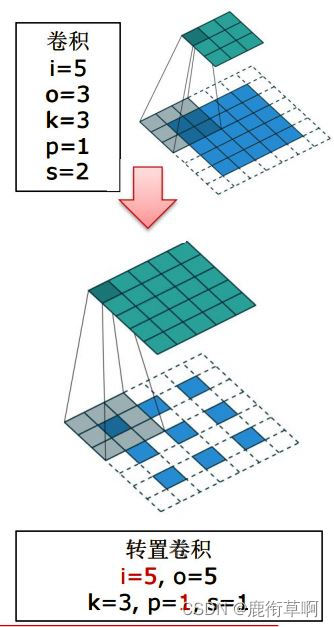
步长>1;padding>0;a=i+2p-k整除s
3.4 上采样的三种实现
双线性插值∶特点是不需要进行学习,运行速度快,操作简单。反卷积∶是为了还原原有特征图,类似消除原有卷积的某种效果,所以叫反卷积
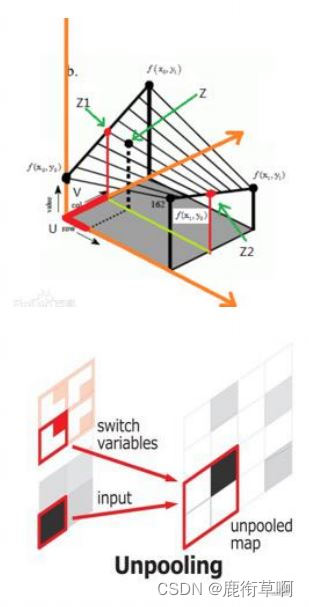
反池化∶在池化过程中,记录下池化后元素在对应kernel中的坐标,作为反池化的索引。
4 反池化
4.1 反池化操作
记录池化时的位置
形成“池化索引”
将输入特征按记录位置摆放回去
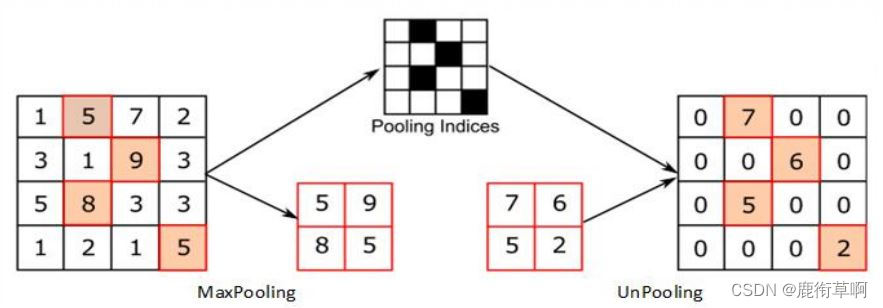
4.2 反卷积与反池化
反卷积与反池化之间最大的区别在于反卷积过程是有参数要进行学习的。理论上反卷积可以实现反池化,只要卷积核的参数设置的合理。
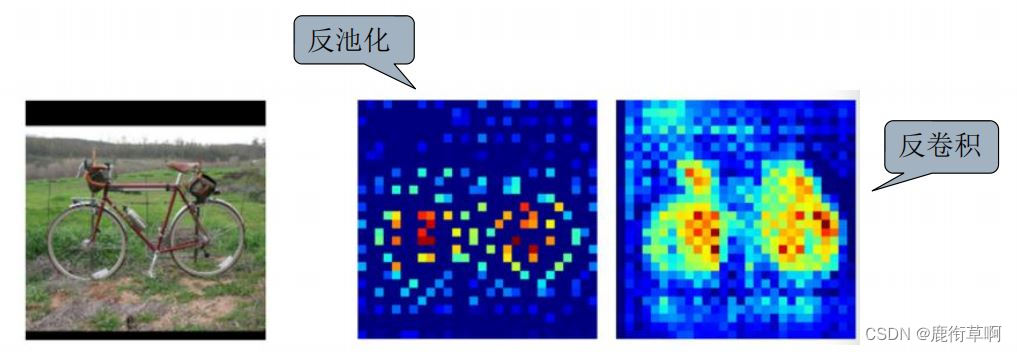
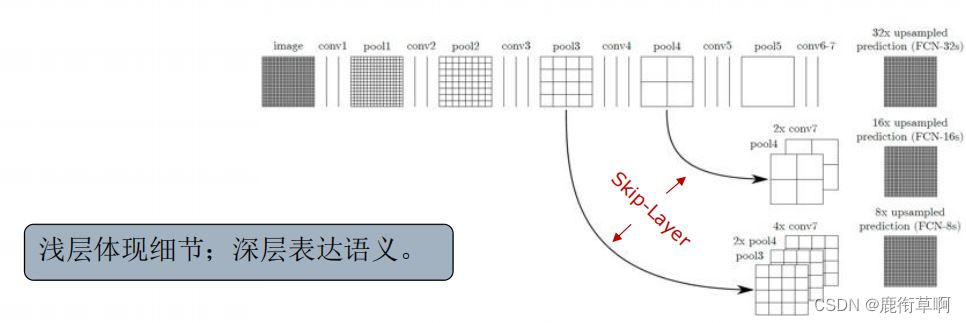
5 FCN-跳层结构
原因:直接使用32倍反卷积得到的分割结果粗糙。
使用前2个卷积层的输出做融合
跳层:Pool4和Pool3后会增加一个1x1卷积层做预测
较浅网络的结果精细,较深网络的结果鲁棒
5.1 FCN构架图例
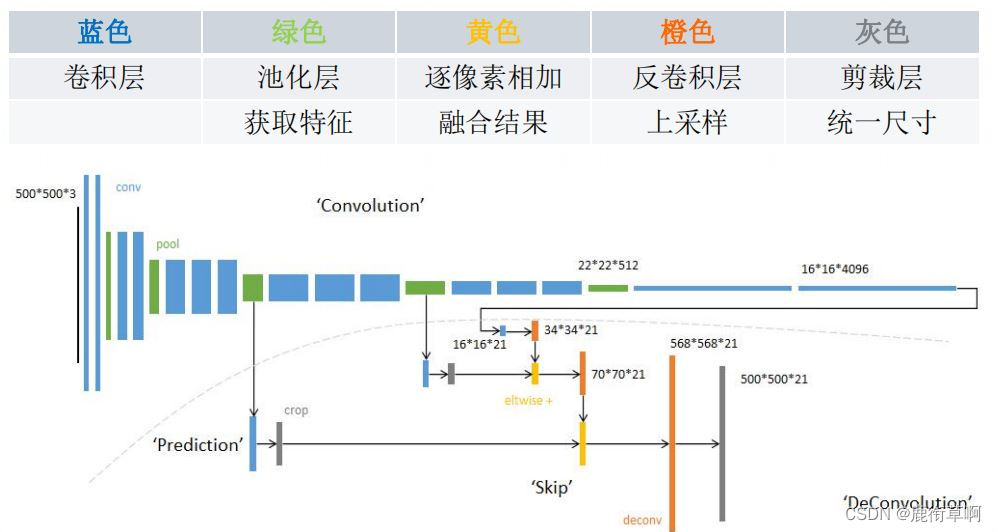
5.2 使用AlexNet构建FCN
第一步:
使用AlexNet作为初始网络,保留参数
舍弃全连接层

第二步:
替换为两个同深度的卷积层(4096,1,1)
追加一个预测卷积层(21,1,1)
追加一个步长为32的双线性插值反卷积层
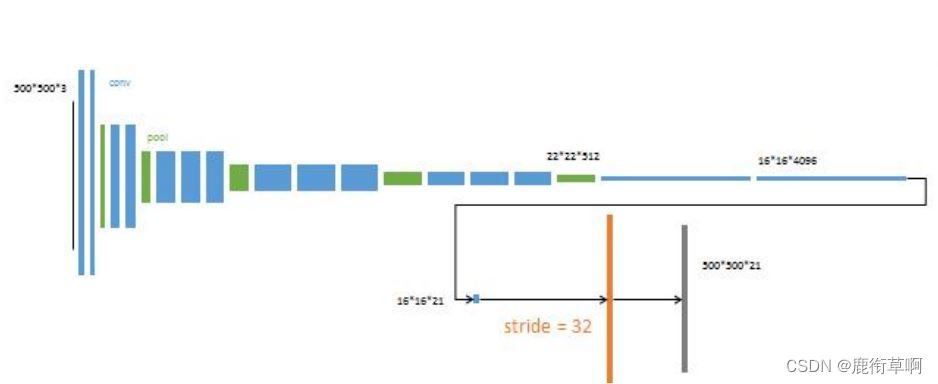
第三步:
对最终层Conv7结果2倍上采样
提趣Pool4输出,追加预测卷积层(21,1,1)、
相加融合
追加一个步长为16的双线性插值反卷积层
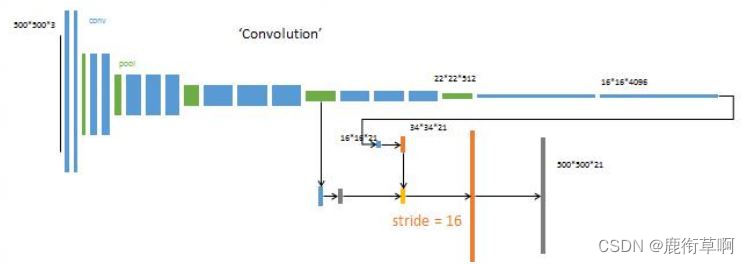
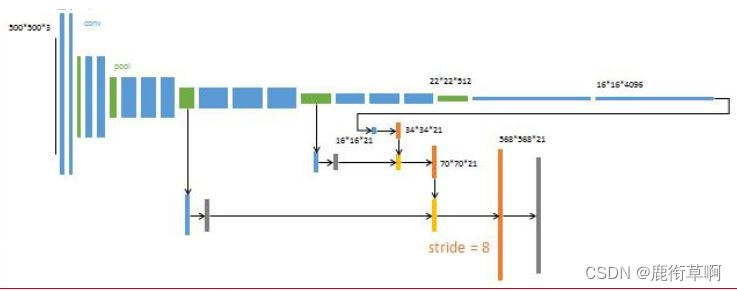
第四步:
对上次融合结果2倍上采样
提取Pool3输出,追加预测卷积层(21,1,1)
相加融合
追加一个步长为8的双线性插值反卷积层
5.3 FCN训练
卷积层:前5个卷积层使用初始CNN网络的参数;剩余第6和第7卷积层初始化为0
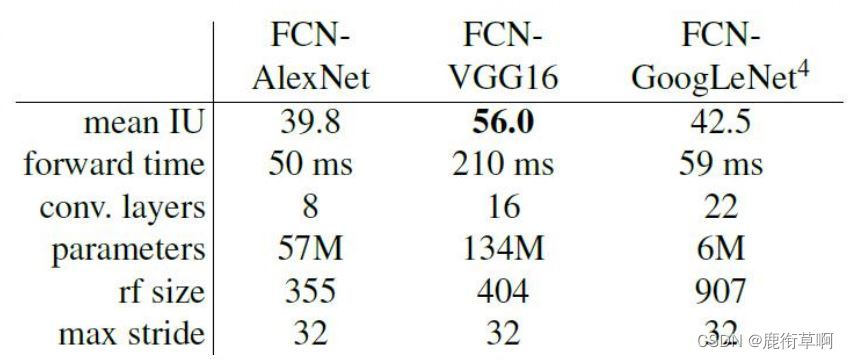
反卷积层:最后一层反卷积层固定为双线性插值,不做学习;剩余反卷积层初始化为双线性插值,做学习5.4 FCN的基础网络性能
-
相关阅读:
【算法】【递归与动态规划模块】矩阵的最小路径和
围绕防汛抗旱抓落实 国稻种芯-荔波县:抓指导统筹粮食增产
(免费领源码) Asp.Net#SQL Server校园在线投票系统10557-计算机毕业设计项目选题推荐
ProcessState实例化过程讲解
GDB之指令基础参数
所有社区工作者!能救一个是一个
EaselJS 源码分析系列--第四篇
netty-reacter写一个http服务器
2023.10.10 关于 线程安全 问题
mysql -测试和优化
- 原文地址:https://blog.csdn.net/weixin_45649258/article/details/124830356